小米宣布面向全球推出三款大模型 MiMo-V2-Pro & Omni & TTS。
其中,Xiaomi MiMo-V2-Pro 是专为现实世界中高强度的 Agent 工作场景而打造。拥有超过 1T 的总参数量(42B 激活参数),采用创新的混合注意力架构,并支持 1M 超长上下文长度。
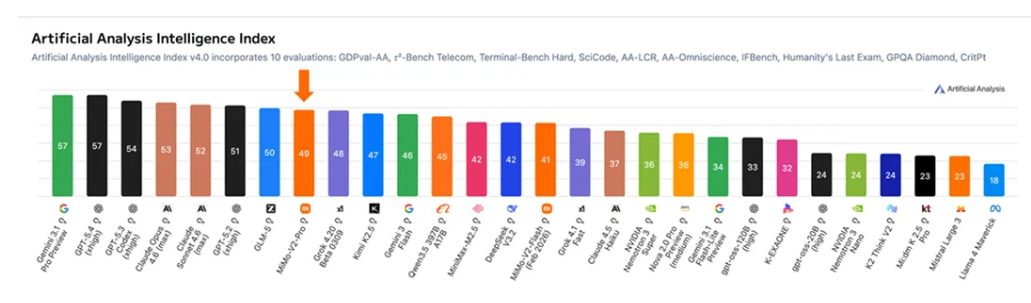
在全球权威大模型综合智能排行榜 Artificial Analysis 上,MiMo-V2-Pro 位列全球第八,国内第二。在 OpenClaw、Claude Code 等智能体框架中,MiMo-V2-Pro 展现出了优秀的端到端任务完成能力,能够在无人工干预的条件下完成复杂工作流编排、长程规划与精准工具调用,并持续可靠地交付最终结果。公告称,MiMo-V2-Pro 整体使用体感已超越 Claude Sonnet 4.6,逼近 Opus 4.6,但模型 API 定价仅为其 1/5。
![]()
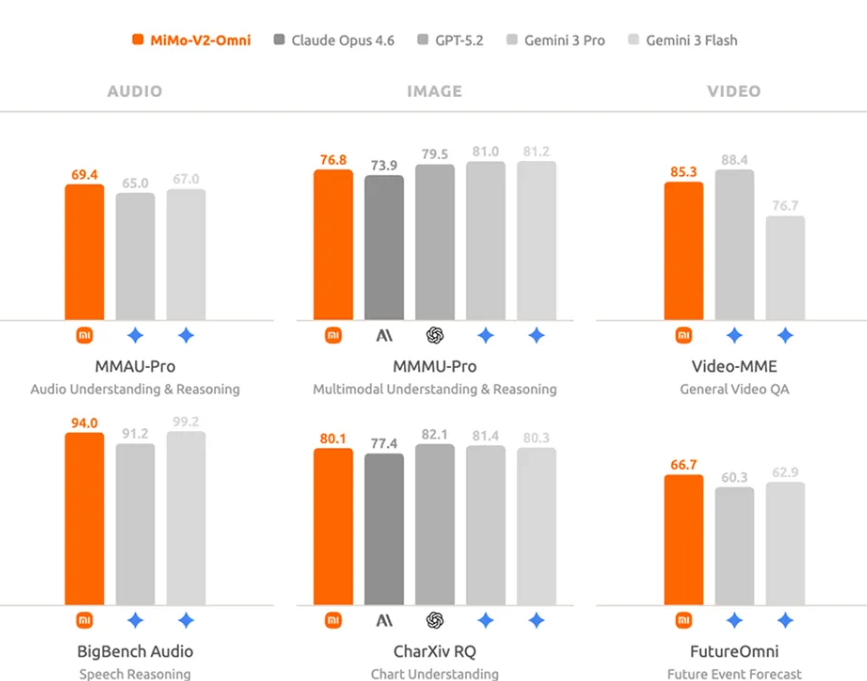
MiMo-V2-Omni 则是专为现实世界中复杂的多模态交互与执行场景而生。开发团队从底层构建了融合文本、视觉、语音的全模态基座,并以统一架构将“感知”与“行动”深度绑定。
MiMo-V2-Omni 可无缝接入各种 Agent 框架。,目前,MiMo-V2-Omni 模型已正式开放 API 服务,支持 256K 上下文长度,输入 $0.4 / 百万 tokens,输出 $2 / 百万 tokens。
此外,小米还认领了曾占领 OpenRouter 调用量榜单第一的模型 Hunter Alpha。
“在正式发布之前,我们将一个早期测试版本以「Healer Alpha」为代号匿名上架 OpenRouter,没有任何宣传,纯粹让模型能力说话。结果调用量自然攀升至平台前列,并在 OpenClaw 测评榜单 PinchBench 上拿下均分第一,用户和基准双双给出了同一个答案。”
![]()
Xiaomi MiMo-V2-TTS 是小米自主研发的语音合成大模型。基于自研 Audio Tokenizer 和多码本语音-文本联合建模架构,经过上亿小时语音数据的大规模预训练与多维度强化学习,实现了高度可控的多粒度语音风格控制。MiMo-V2-TTS 支持从整体风格定调到局部情绪表达的精准调节,能在同一句话内完成语气转折和情感递变;真实还原人类说话的自然韵律;在唱歌时,也能准确表达音高和节奏,自然且富有表现力。
在训练过程中,MiMo-V2-TTS 首先通过超大规模语音-文本混合预训练,在海量数据中习得了强大的跨模态对齐与理解生成的统一能力;在此基础上,通过少量高质量监督数据的微调,模型获得了可泛化的多粒度与多风格指令控制能力。
为进一步激发模型在大规模预训练中积累的高表现力语音生成潜力,团队引入了多维度强化学习,兼顾了稳定性与表现力。具体而言,MiMo-V2-TTS 在强化学习阶段,围绕更自然的韵律、更稳定的音质、更准确的字词表达、更高质量的音色克隆以及不同场景下恰当的语气和表达方式等多个维度持续优化。得益于多层码本建模架构,模型在高保真的离散 token 空间中对语音进行建模,充分保留了原始语音中的丰富信息,使强化学习阶段能够直接利用语音相关奖励信号对模型进行优化,从而让多维奖励信号更有效地作用于生成过程。