阿里通义实验室发布并开源了首个支持影视级多场景配音的多模态大模型 Fun-CineForge。并配套开放了高质量数据集的构建方法。公告称,“通过“数据 + 模型”的一体化设计,Fun-CineForge 正尝试解决影视级 AI 配音长期面临的关键问题。”
本次开源内容核心包含两部分:
- 模型侧:面向复杂影视场景的多模态配音大模型;
- 数据侧:大规模多模态配音数据集构建流程(CineDub)。
根据介绍,在数据基础之上,Fun-CineForge 基于 CosyVoice3 强大的语音合成底层能力,构建了一个面向复杂影视场景的配音大模型,完成视频 + 文本 → 语音的任务。输入包括:
- 无声视频片段
- 配音文本
- 角色属性和情感线索
- 时间信息
- 参考语音
模型即可以参考语音的音色来合成与时间和视频信息高度对齐的语音。
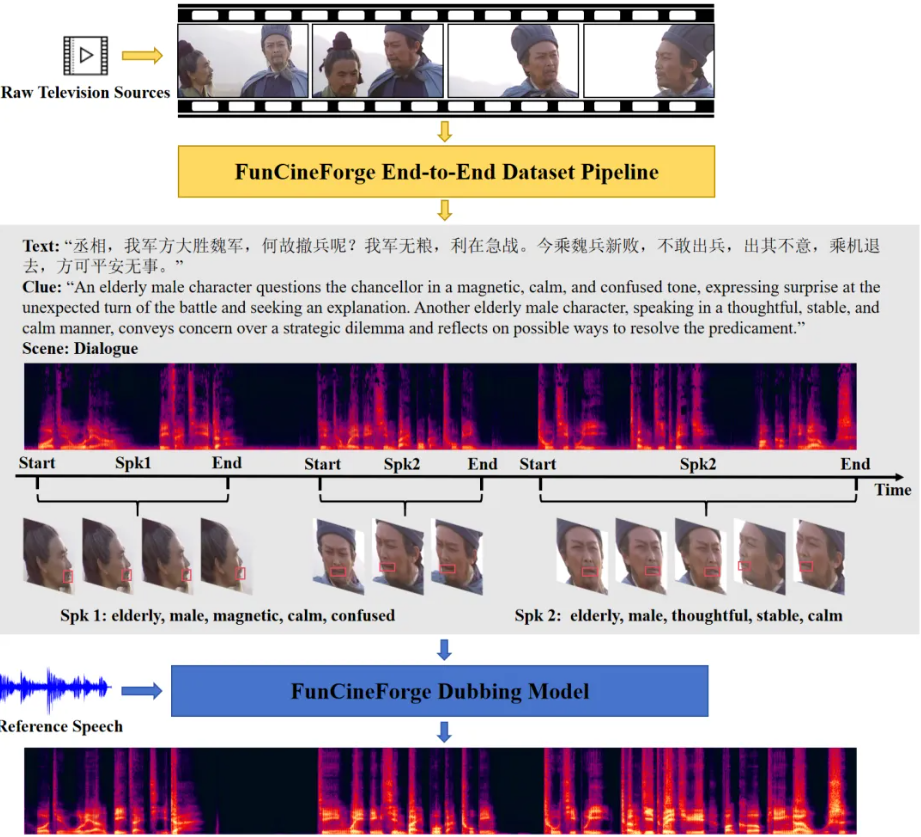
Fun-CineForge 首先构建了一套自动化的数据集生产流程,可以将原始影视素材转化为结构化多模态数据。
该流程包括人声分离、文本转录、长视频分段、音视频联合说话人分离等,其中,基于通用大模型思维链的双向矫正机制,大幅降低了转录文本和说话人分离结果的错误率。
- 中文字错率从 4.53% 降至 0.94%;
- 英文词错率从 9.35% 降至 2.12%;
- 说话人分离错误率从 8.38% 降至 1.20%。
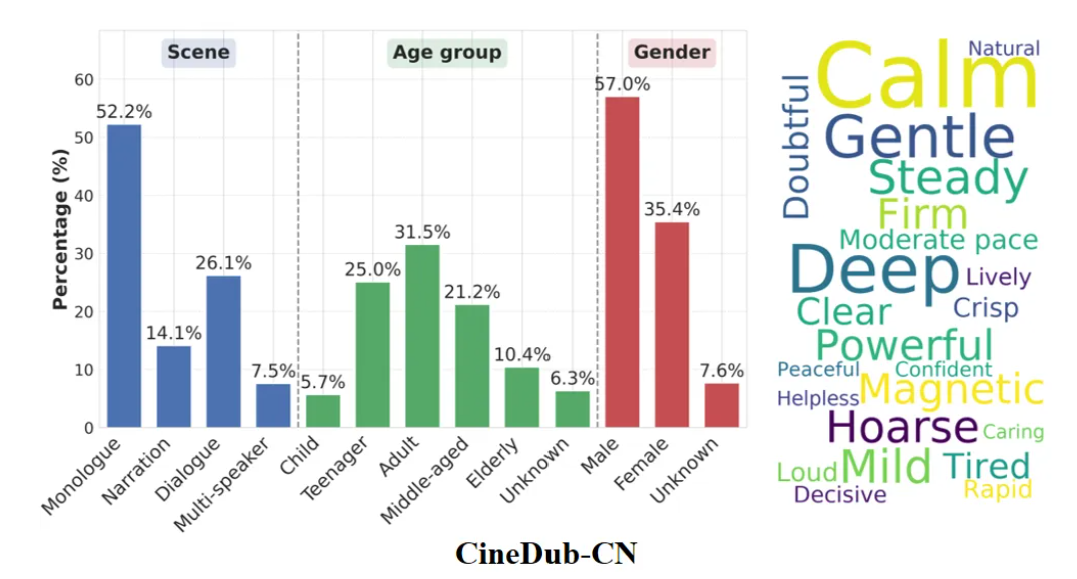
数据覆盖独白、旁白、对话、多说话人等多种典型场景。每条数据都包含转录台词、帧级人脸唇部数据、角色属性情感线索、毫秒级时间戳及干净人声轨道。这些相互补充、相辅相成的多模态信息为训练大模型的专业配音能力提供了坚实基础。
![]()
Fun-CineForge 最重要的技术创新,是在配音模型中首次引入“时间模态”。传统 TTS 模型通常只关注文本内容、声音特征或视觉信息,但影视配音中还有一个关键维度:时间。
例如:
- 什么时候开始说话
- 什么时候结束说话
- 哪个角色在该时间区域内说话
这些信息能够直接帮助模型深入理解“在什么时间段内,哪个角色在说什么。”,在视觉模态“看不到”说话人的时候,时间模态作为一种强监督目标,使语音出现在该出现的时间区域内。这一点使模型具备了在复杂场景下的配音能力。
Fun-CineForge 模型同时利用四类信息,它们相互补充、相辅相成。
![]()
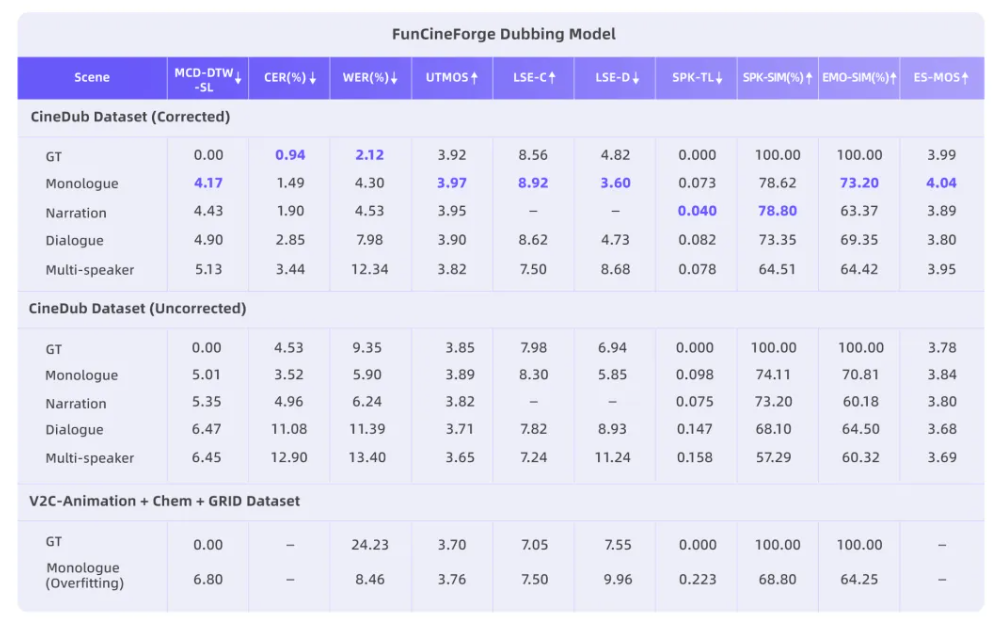
实验结果显示,在多个关键指标上,Fun-CineForge 配音模型都优于现有开源配音模型,包括:语音自然度、字错率、情感表达能力、音色相似度、唇形同步、时间对齐能力、。指令遵循能力
其中,Fun-CineForge 配音模型以独白和旁白两种单人配音场景效果最佳,首次支持双人对话与多人对话的场景,并能够实现准确的时间对齐、音画同步与音色一致。
项目团队在自建的CineDub 数据集上对 Fun-CineForge 进行了全面评估,覆盖独白、旁白、对话、多人场景等多种典型影视配音场景。结果显示,单人场景效果最优,独白和旁白的中文字错率仅 1.49% 和 1.90%,音画同步精准。
![]()
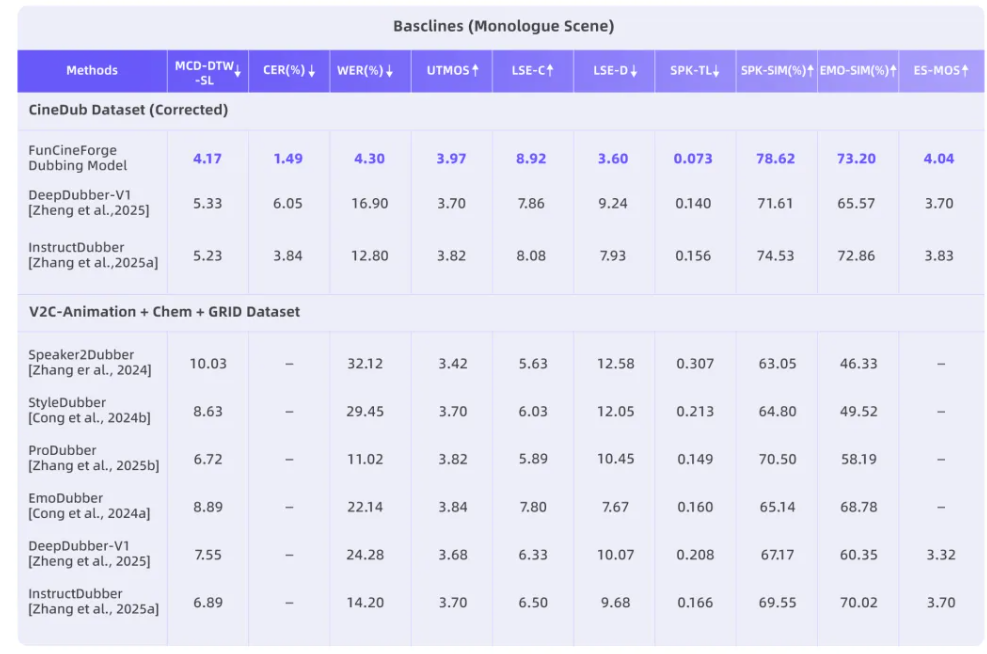
在独白场景下,将 Fun-CineForge 与 DeepDubber-V1 和 InstructDubber 进行了对比。结果显示,Fun-CineForge 在词错率、唇部同步、时间对齐、音色相似度等各项指标上均明显优于基线模型。
![]()