美团 LongCat 团队宣布正式推出基于 N-gram 的全新模型 LongCat-Flash-Lite,拥有 685 亿参数,每次推理仅激活29亿~45亿参数的轻量化 MoE 模型。目前,已全面开源模型权重及技术细节。
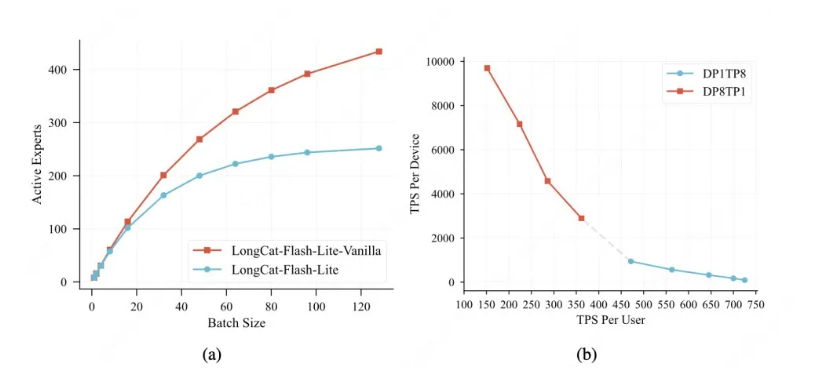
根据介绍,通过将超过 300 亿参数高效用于嵌入层,LongCat-Flash-Lite 不仅超越了参数量等效的 MoE 基线模型,还在与同规模现有模型的对比中展现出卓越的竞争力,尤其在智能体与代码领域表现突出,并依托 YARN 技术可支持最长 256 K上下文,能高效处理长文档、大规模代码分析等场景。
同时,该模型基于嵌入扩展的应用与系统级优化,让模型推理效率大幅提升,在输入 4K,输出 1k 的典型负载下,LongCat API 可提供 500-700 token/s 的生成速度。
通过参数重分配奠定稀疏基础、专用缓存与内核优化消除系统开销、与推测解码策略深度协同,LongCat-Flash-Lite 实现了从模型结构到运行时系统的垂直优化,最终将 N-gram 嵌入带来的理论优势,有效转化为高吞吐、低延迟的实际推理性能。
![]()
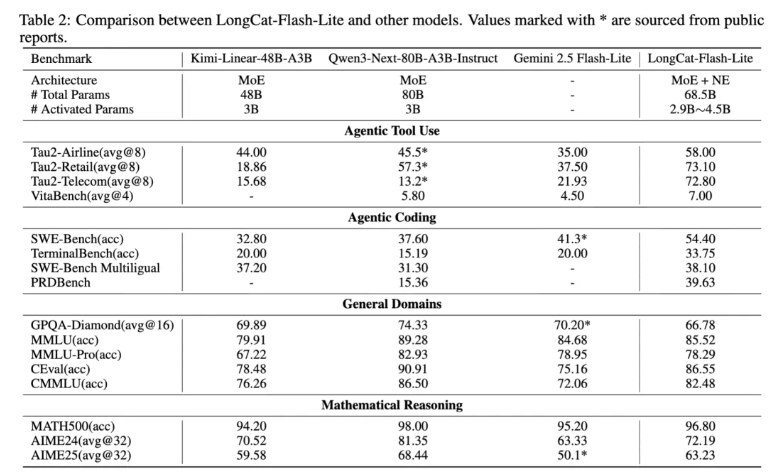
测评结果显示,LongCat-Flash-Lite 在智能体工具使用与编程任务上均展现出领先性能:τ²-Bench 三大行业场景高分领先,编程领域覆盖全链路能力,在代码修复、终端执行、多语言开发等任务上表现优异。
![]()
智能体任务表现
在评估复杂工具使用与工作流执行的基准上,模型表现突出:
- τ²-Bench行业场景:在电信(72.8分)、零售(73.1分)、航空(58.0分)三大子场景中均取得最高分,表明其能有效理解并执行涉及专业工具的复杂指令。
- VitaBench通用场景:以7.0分领先于对比模型,验证了其在多样化现实任务中的实用工具调用能力。
代码任务表现
在衡量编程实用技能的基准上,模型展现出强劲的问题解决能力:
- 代码修复(SWE-Bench):54.4%的准确率显著领先于同规模对比模型,证明其处理真实软件工程问题(如修复bug、实现特性)的有效性。
- 终端命令执行(TerminalBench):33.75分的表现远超对比模型所处的15-20分区间,体现了对开发者工作流中命令行操作的高精度理解。
- 多语言代码生成(SWE-Bench Multilingual):38.10%的准确率展现了跨编程语言与软件生态的较好泛化能力。
通用知识及推理能力
模型在综合评估中保持了与规模相匹配的均衡性能:
- 综合知识(MMLU):85.52分,与Gemini 2.5 Flash-Lite(84.68)相当。
- 中文理解(C-Eval & CMMLU):分别取得86.55分与82.48分,在中文评估中具备一定优势。
- 复杂推理(MMLU-Pro, GPQA-Diamond):78.29分与66.78分的表现,显示了处理高阶、多学科问题的能力。
- 数学推理(MATH500, AIME):在基础(96.80%)与竞赛级数学问题(AIME24:72.19; AIME25:63.23)上均表现稳健,擅长多步推演。