
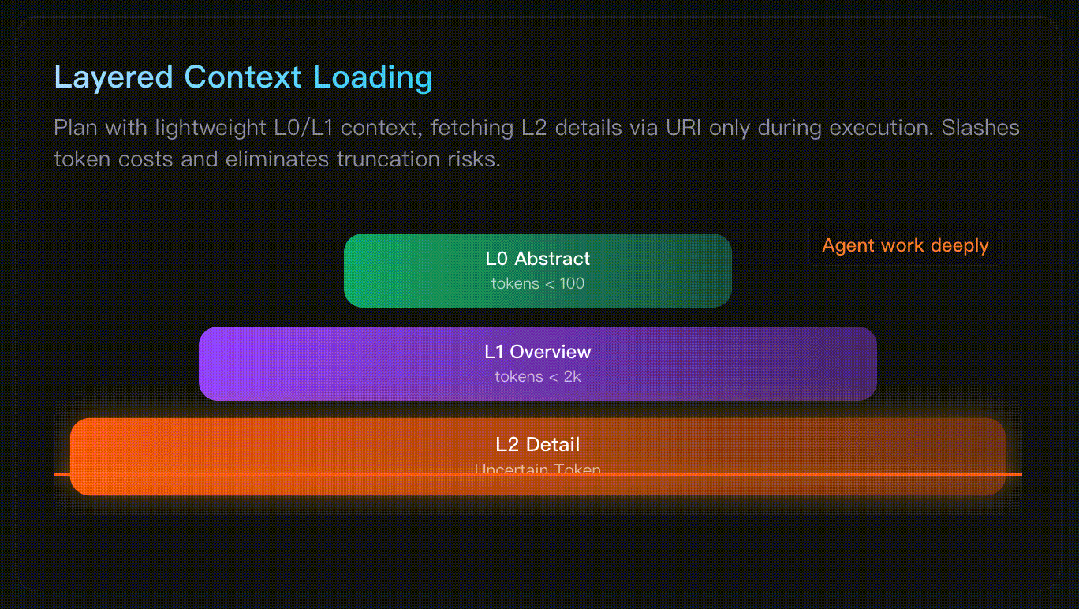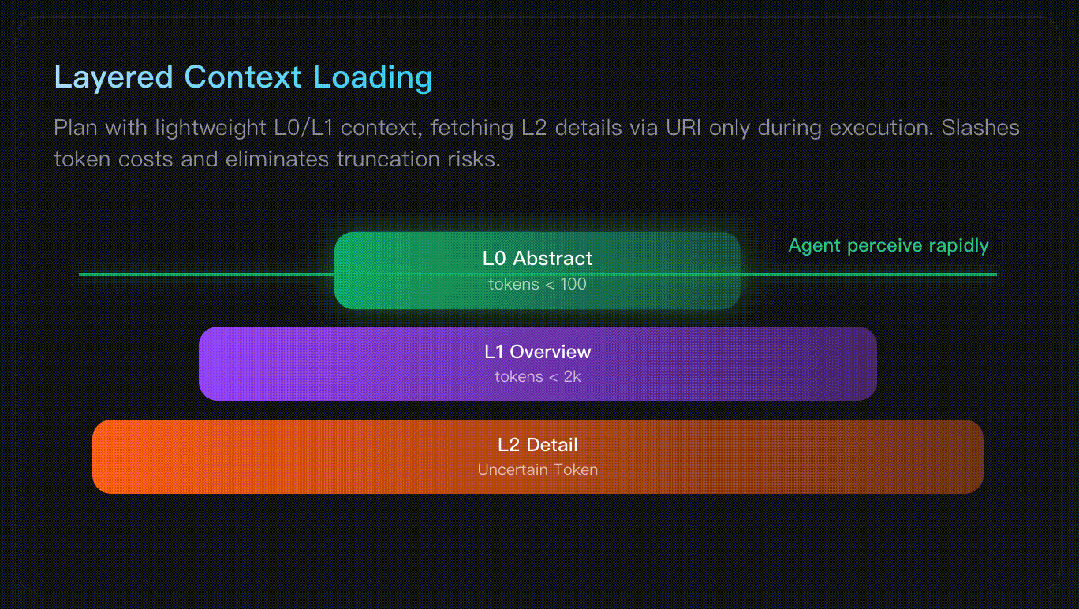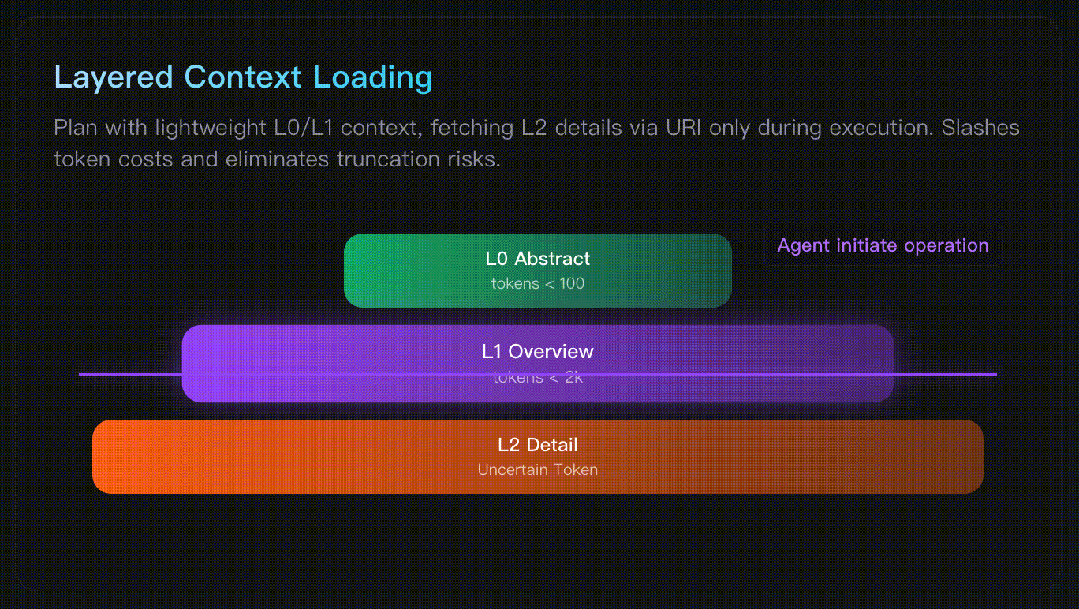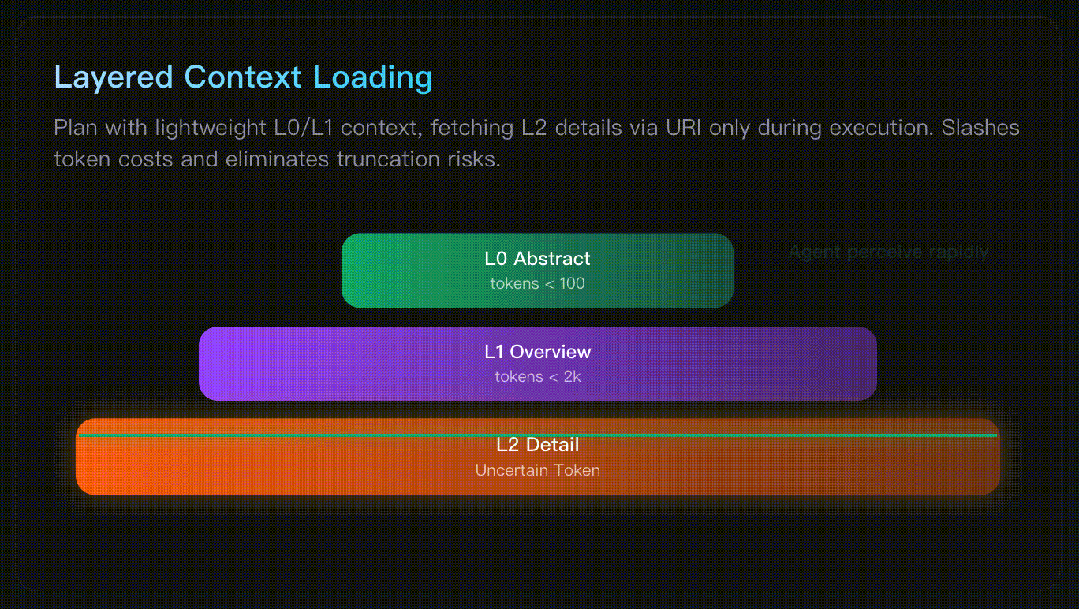



Qwen3-Coder-Next 开源:小而强
阿里千问宣布开源 Qwen3-Coder-Next,一款专为编程智能体打造的高效混合专家(MoE)模型;总参数80B,激活参数仅3B。目前已正式开源Qwen3-Coder-Next(Base)与Qwen3-Coder-Next(Instruct)两个版本,全面支持研究、评测及商业应用。 公告称,Qwen3-Coder-Next 在权威基准 SWE-Bench Verified 上实现了超70%的问题解决率,性能直逼激活规模大10–20倍的稠密模型。其在实际开发中不仅能理解需求、编写代码,还能与环境交互、完成任务——从生成可玩的网页游戏,到部署服务并自动测试,全程无需人工干预。 Qwen3-Coder-Next 训练过程主要包括: 持续预训练:在以代码与智能体为中心的大规模数据上进行。 监督微调:基于高质量的智能体交互轨迹,优化模型的行为。 领域专家训练:针对软件工程、问答、Web/UX 等特定领域,精细化专家能力。 专家知识蒸馏:最终将27个专家的能力融合至一个轻量的、可部署的单一模型。 这套“配方&...