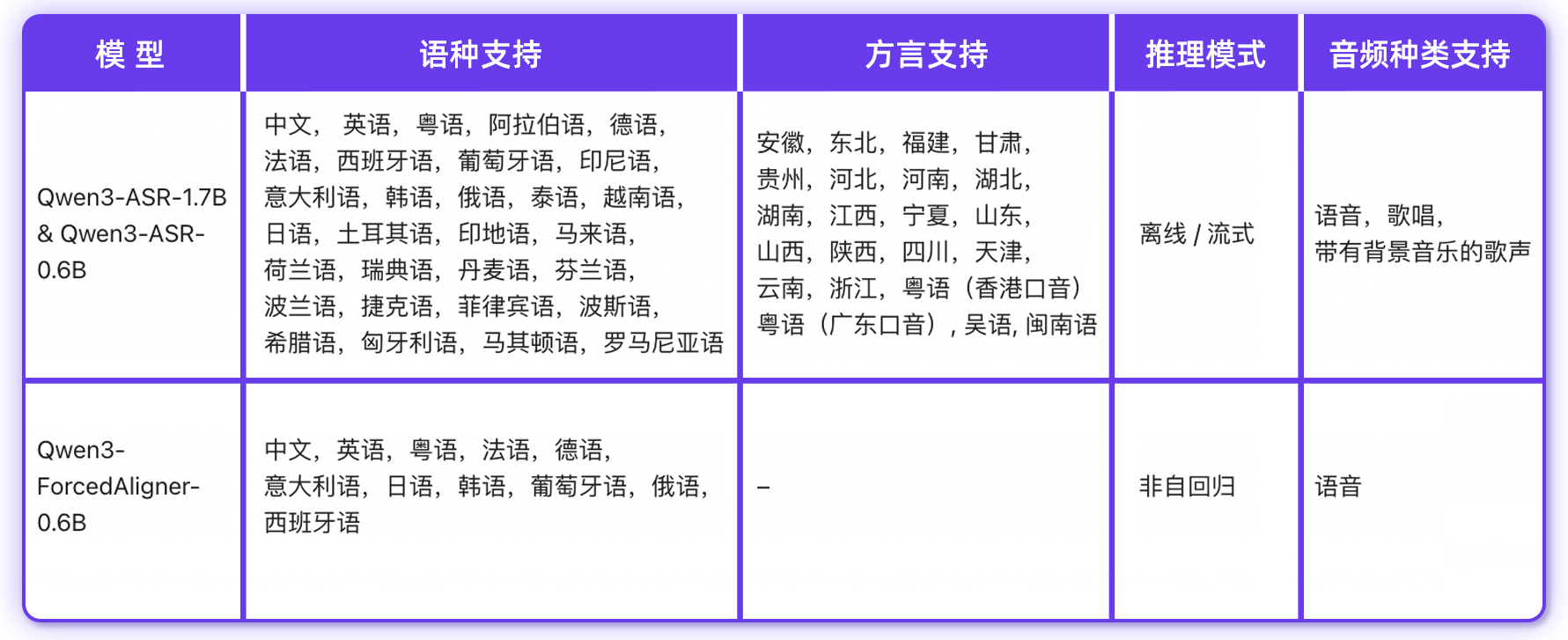
阿里通义 Qwen 正式开源 Qwen3-ASR 系列语音识别模型,包括两个强大且全面的语音识别模型 Qwen3-ASR-1.7B 与 Qwen3-ASR-0.6B,以及一个创新的语音强制对齐模型 Qwen3-ForcedAligner-0.6B。Qwen3-ASR 系列的语音识别模型支持 52 个语种与方言的语种识别与语音识别。
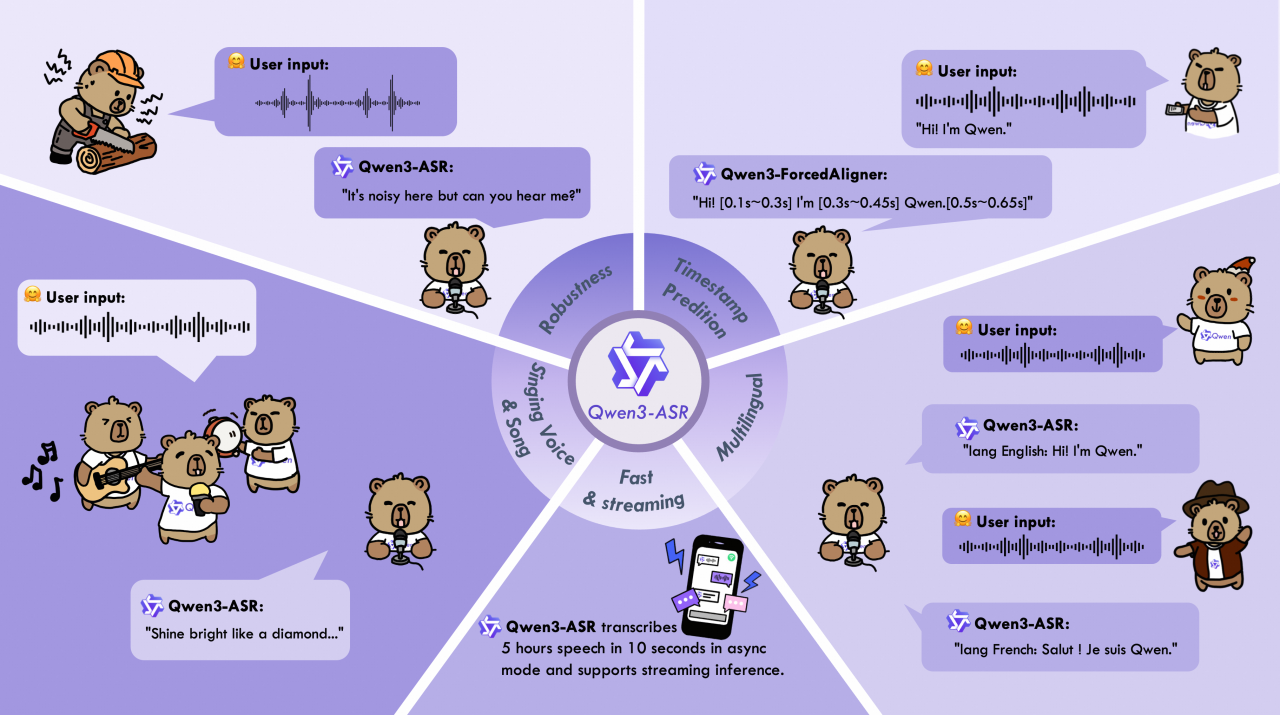
Qwen3-ASR核心特性
-
All-in-one: Qwen3-ASR-1.7B 与 Qwen3-ASR-0.6B 均通过单一模型支持 30 个语种的语种识别与语音识别、22 个中文口音与方言语音识别、多个国家与地区的英文口音识别。
-
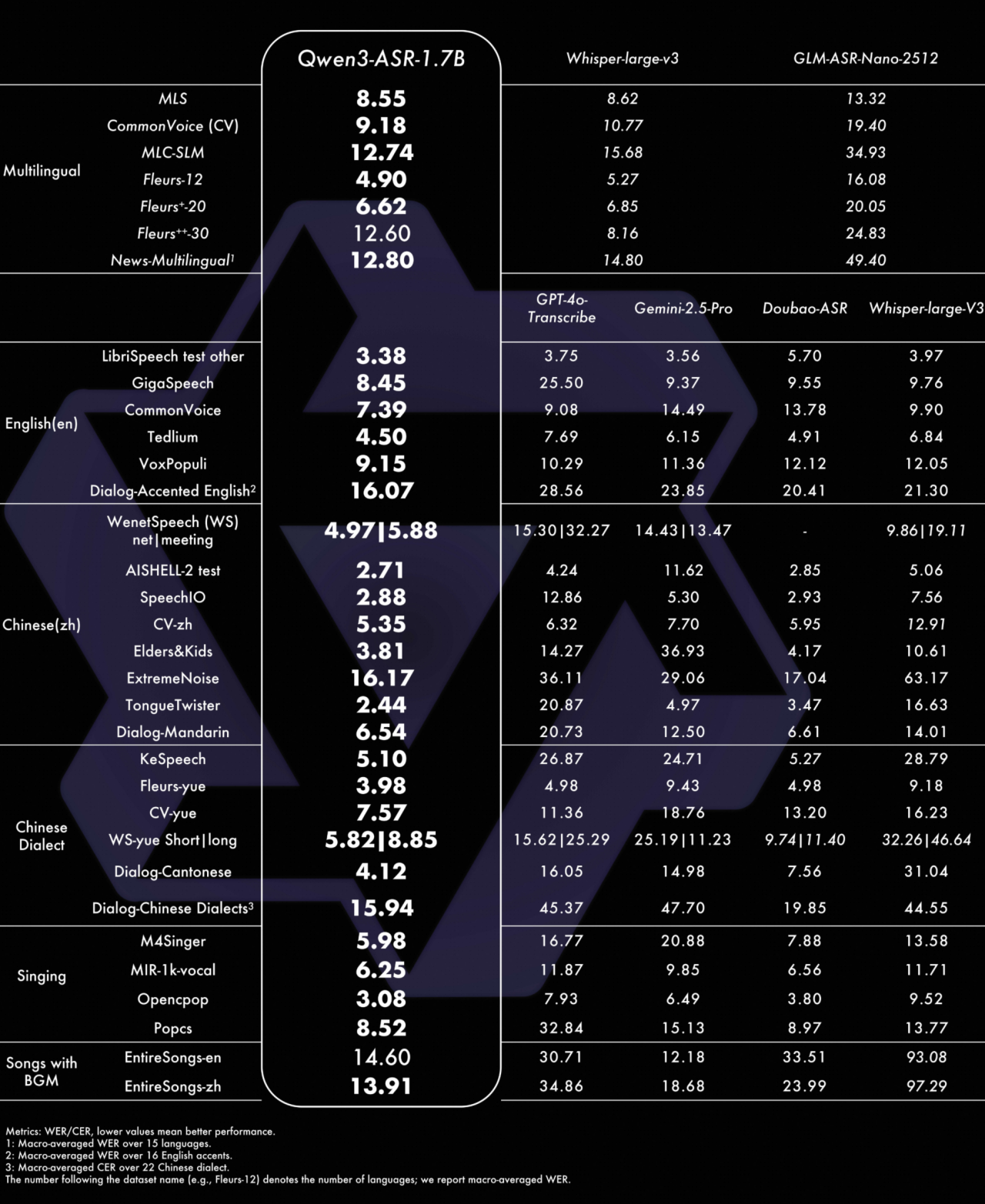
准确而快速的语音识别能力:在复杂的声学环境与文本模式的场景下,Qwen3-ASR 系列模型均能保持稳定鲁棒的语音识别能力,包括歌唱识别等。Qwen3-ASR-1.7B 实现了语音识别准确率的全面领先,在开源与闭源自建评测上较主流开源模型与众多商用 API 上更优。0.6B 模型则实现了性能与效率的均衡,在异步推理模式下,128 并发的该模型能够达到 2000 倍的吞吐,处理 5 个小时的音频仅需要 10 秒。 Qwen3-ASR-1.7B 与 Qwen3-ASR-0.6B 均支持流式/非流式一体化推理,最长一次性处理 20 分钟的音频。
-
独创且强大的强制对齐模型:我们推出 Qwen3-ForcedAligner-0.6B,一个支持 11 个语种在 5 分钟之内语音的任意单元的时间戳预测,经评测其时间戳精度超越了一众基于传统端到端方案的强制对齐模型,其非自回归的推理逻辑保证了推理的高效性。
-
全面且易用的推理与微调工具:除了 Qwen3-ASR 系列模型的结构与权重开源,我们一次性推出强大且全面的推理框架,支持基于 vLLM 的 batch 推理、异步服务、流式推理 、时间戳预测功能 等。
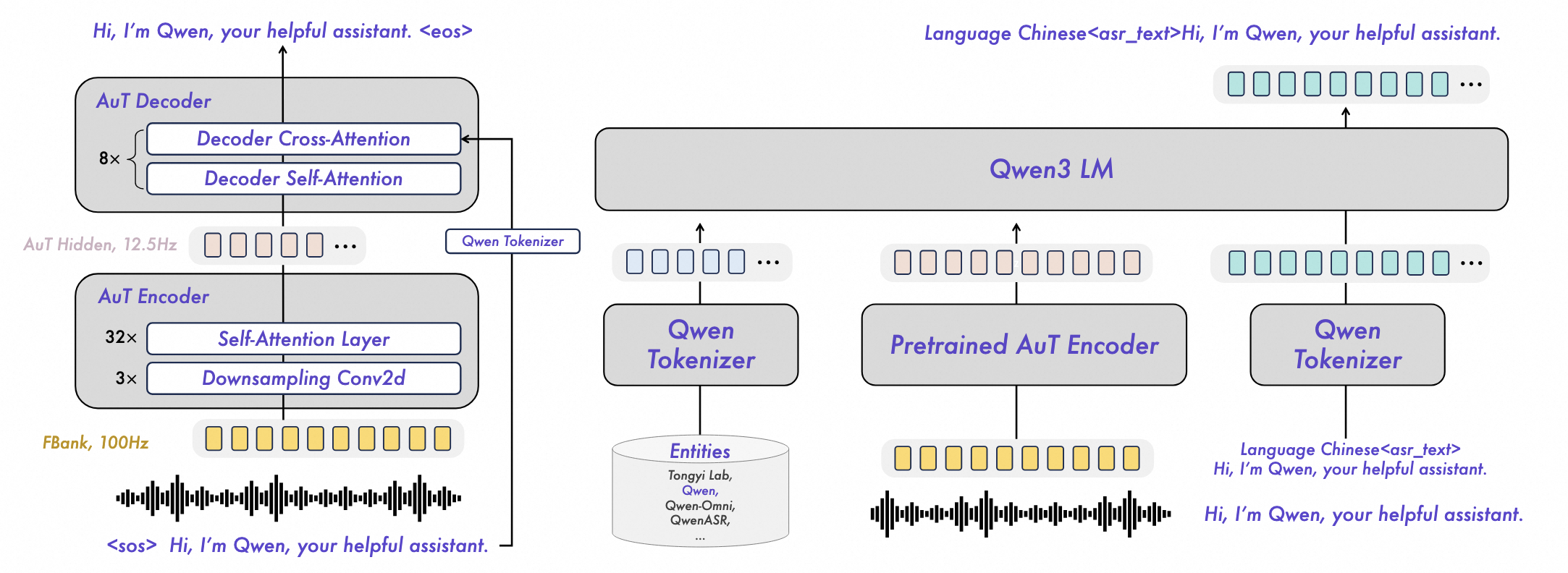
据官方介绍,依托创新的预训练 AuT 语音编码器与 Qwen3-Omni 基座模型的强大多模态能力,Qwen3-ASR 实现了精准与稳定的语音识别,其 1.7B 模型在中文、英文、中文口音与歌唱识别等场景下达到 SOTA,具有复杂文本识别能力以及强噪声下的稳定性;0.6B 模型在性能与效率上实现了均衡,在保证语音识别准确率的情况下,128 并发异步服务推理能够达到 2000 倍吞吐,即 10 秒钟处理五个小时以上的音频。
Github: https://github.com/QwenLM/Qwen3-ASR
HuggingFace: https://huggingface.co/collections/Qwen/qwen3-asr
ModelScope:https://www.modelscope.cn/collections/Qwen/Qwen3-ASR
Huggingface Demo:https://huggingface.co/spaces/Qwen/Qwen3-ASR
ModelScope Demo: https://modelscope.cn/studios/Qwen/Qwen3-ASR
论文: https://github.com/QwenLM/Qwen3-ASR/blob/main/assets/Qwen3_ASR.pdf
阿里云百炼API:https://help.aliyun.com/zh/model-studio/qwen-real-time-speech-recognition
