openGemini 发布 v1.5 版本更新。带来了众多新功能,以及在读写性能方面实现了显著提升
一、数据模型:TSBS cpu-only
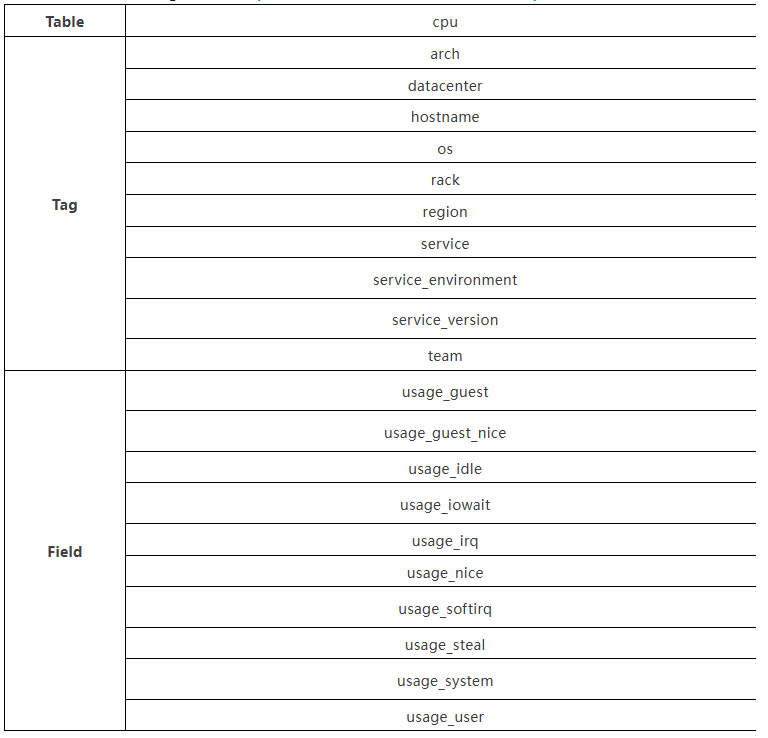
为了确保测试的公平性和可比性,项目团队就采用了业界广泛使用的 TSBS (cpu-only) 基准测试工具,模拟了典型的时间序列数据模型。
- 测试环境:3节点集群
- 节点配置:8核32G内
- 时间线数:30万条
- 测试机型:c3.2xlarge.4,https://www.huaweicloud.com/product/ecs.html
![]()
二、写入性能测试:速度提升,资源更省
![]()
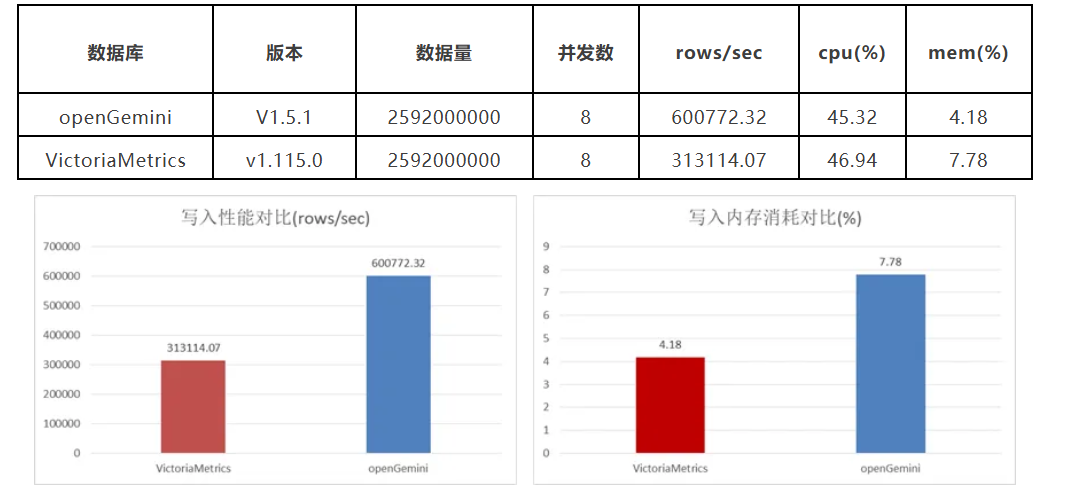
在TSBS cpu-only 模型下,openGemini 写入性能约为 VM 的2 倍,内存占用仅为 VM 的1/2,CPU使用率则与 VM 相当。
三、查询性能测试:简单更快,复杂更稳
![]()
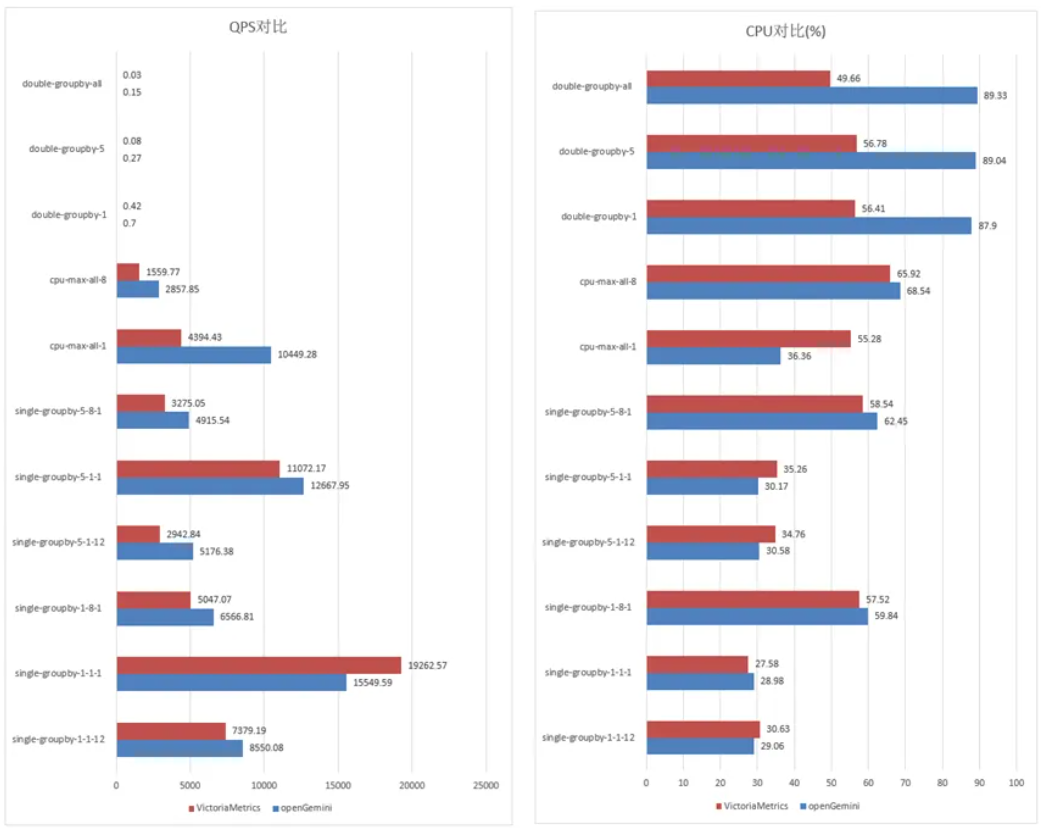
可以从结果看出来,openGemini在资源差不多的情况下,总共11个场景的10个场景查询性能优于VictoriaMetrics(简称 VM),查询模型single-groupby和查询模型cpu-max-all:openGemini查询性能约为 VM查询性能的1.2-2.4倍;查询模型double-groupby-5、double-groupby-all:openGemini查询性能约为VM查询性能的1-3倍。在single-groupby-1-1-1 场景下,VM依然表现出色。其设计理念是“极致简洁”,不做过多的计算下推,因此在最简单的查询场景中具有天然优势。
而 openGemini 在复杂聚合场景中表现更佳,主要得益于团队对计算下推的深度优。v1.5 做了多种计算下推的流程优化,使得在包含多个条件过滤、聚合和连接操作的复杂查询中,响应速度和性能表现显著优于简单查询场景。
当然,项目团队也意识到目前的实现方式在某些简单查询中存在“过度计算”的问题。在后续版本中计划引入更智能的下推策略,实现“既要又要”的目标:在简单查询中保持高效,在复杂查询中保持领先。
四、性能优化背后的“硬核技术点”
核心优化点解析:
1. 查询语句匹配机制
- 特征识别:基于车联网、实时监控等典型业务场景,提取高频查询语句特征。
- 高效匹配:通过预定义特征与执行链路的映射机制,使查询匹配成功后,执行器构建时延从毫秒级降至微秒级,极大提升响应速度。
2. 轻量化执行器设计
- 查询上下文简化:查询上下文更“轻”,网络传输编解码开销更小。
- 算子融合优化:持续优化扫描、过滤、聚合、投影四大核心算子,部分算子融合(如 scan/filter、agg/merge),减少冗余计算。
- 调用链路优化:采用 pull-based 与push-based混用模式,简化调用栈,降低函数调用开销。
- 数据传递优化:构建内存亲和与向量化数据格式,提升 CPU 缓存命中率,减少数据编解码开销。
3. 数据统一复用机制
- 统一数据结构:自底向上统一 Record 为数据载体,支持 Record到JSON的数据转换,避免中间格式转换。
- 高效内存复用:构建分层内存池机制,实现 Record 数据的编解码复用与执行器构建复用,有效降低系统 GC 压力。