本文由 B 站技术团队比奇堡、Xd、三木森分享,有修订和重新排版。
1、引言
本文要分享的是 B 站 IM 消息系统的新架构升级实践总结,内容包括原架构的问题分析,新架构的整体设计以及具体的升级实现等。
B 站技术团队的其它技术文章:
- B 站千万级长连接实时消息系统的架构设计与实践
- B 站实时视频直播技术实践和音视频知识入门
- B 站基于微服务的 API 网关从 0 到 1 的演进之路
2、消息系统业务解读
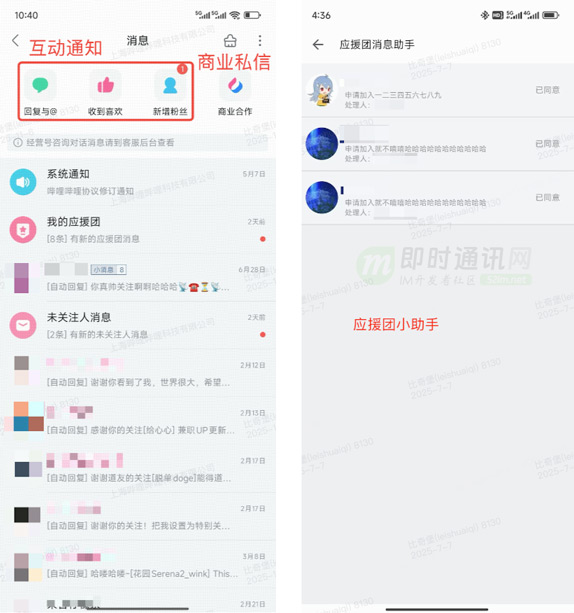
![1和2]()
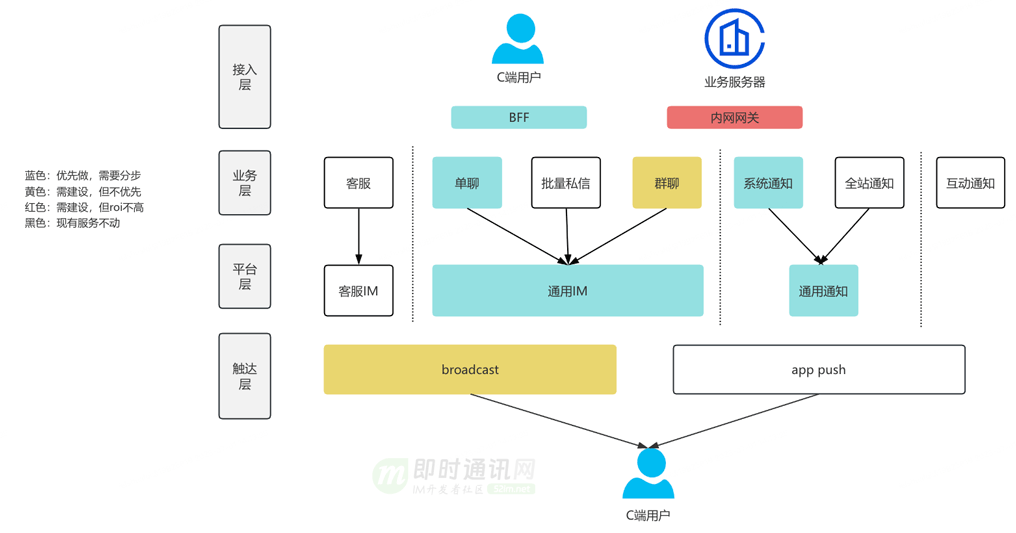
按业务全域现状,在服务端角度分成客服系统、系统通知、互动通知和私信 4 个业务线,每个业务线内按现状标识了服务分层。私信内分为用户单聊、bToC 的批量私信、群聊和应援团小助手四类,这四类细分私信没有技术解耦,单聊和批量私信比较接近系统天花板。
![2]()
私信单聊发送到触达的 pv 转化和 uv 转化不足 10%,有明显通过业务优化提升触达率的潜力。
3、消息系统中的私信业务
私信域内的几个概念解释:
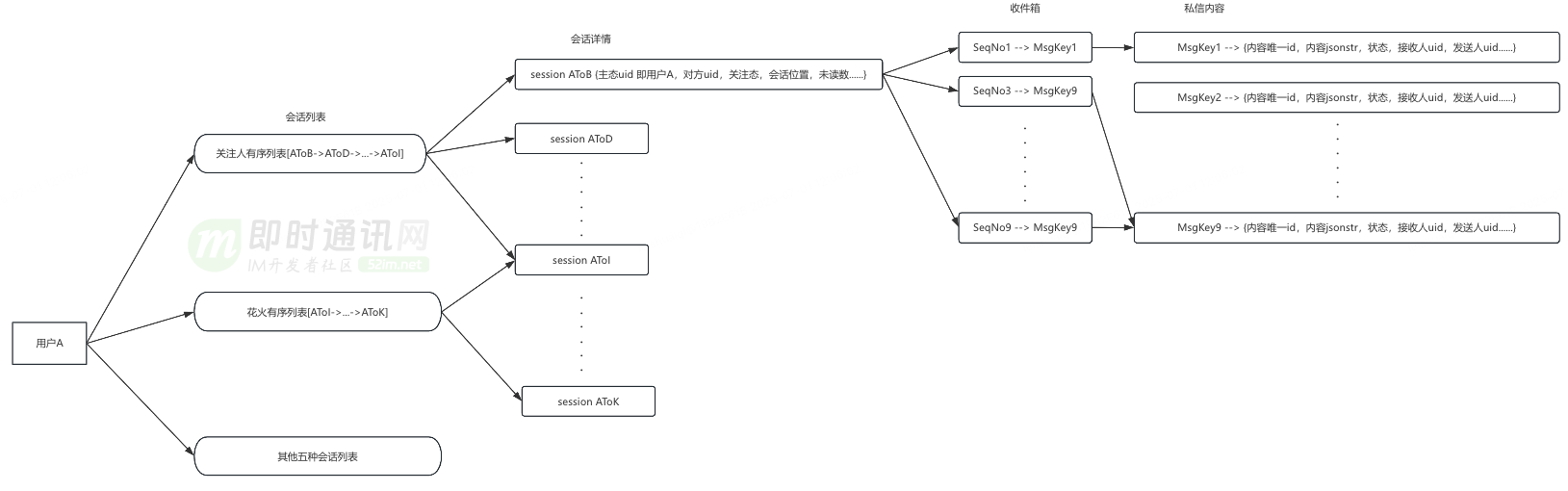
1)会话列表:按聊天人排序的列表。即 B 站首页右上角信封一跳后看到的历史聊天人列表,以及点击未关注人等折叠会话看到的同属一类的聊天人列表。传达对方账号、最新私信和未读数的信息。点击一个会话后看到的是对聊历史,也称会话历史。
2)会话详情:描述和一个聊天人会话状态的原子概念,包括接收人 uid、发送人 uid、未读数、会话状态、会话排序位置等。
3)会话历史:按时间线对发送内容排序的列表。一份单聊会话历史既属于自己,也属于另一个和自己的聊天的人。群聊的会话历史属于该群,不属于某个成员。会话历史是收件箱和消息内容合并后的结果。
4)收件箱:将一次发送的时序位置映射到发送内容唯一 id 的 kv 存储,可以让服务端按时间序读取一批发送内容唯一 id。
5)私信内容:一个包括发送内容唯一 id、原始输入内容、消息状态的原子概念。批量私信把同一个发送内容唯一 id 写入每个收信人的收件箱里。
6)timeline 模型:时间轴的抽象模型,模型包括消息体、已读位点、最大位点、生产者、消费者等基本模块,可以用于基于时间轴的数据同步、存储和索引。私信涉及 timeline 模型的包括会话列表和会话历史。
7)读扩散:pull 模式。群聊每条私信只往群收件箱写一次,让成百上千的群成员在自己的设备都看到,是典型的读扩散。
8)写扩散:push 模式。单聊每条私信既更新接收人会话也更新发送人会话,是轻微的写扩散,无系统压力。群聊有另一个不一样的特点,就是当群成员发送消息后,需要通过长链接通知其他群成员的在线设备,以及发送人其他的在线设备,这是一个写扩散的技术模型,但是这个写扩散是通知后即时销毁的,并且具有过期时间,所以仅临时占用资源,并不对存储造成压力,且能有较好的并发量。
私信核心概念关系表达:
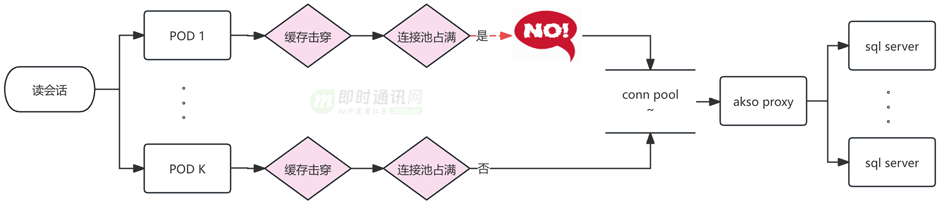
4、消息系统问题 1:会话慢查询
当会话缓存过期时,Mysql 是唯一回源,Mysql 能承载的瞬时 QPS 受当时应用总连接数和 sql 平均响应速度的影响,连接数打满时会给前端返回空会话列表。虽然可以增加 POD 数量、增大 akso proxy 连接数、优化 sql 和索引来作为短线方案,来提升瞬时请求 Mysql 容量,但是这种短线方案无法加快单次响应速度,mysql 响应越来越慢的的问题依然在。另外增加 POD 数量也会降低发版速度。
![4]()
会话 Mysql 使用用户 uid%1000/100 分库,用户 uid%100 分表,table 总量是 1000。
单表会话量在 1kw-3.2kw。单个大 up 的会话积累了 10W 条以上,会话量最大的用户有 0.2 亿条会话。单个 Up 的会话会落到一张表中,每张表都有比较严重的数据倾斜。如果考虑增加分库分表的方案,sql 查找条件依然需要用户 uid,所以相当于倾斜数据要转移到新的单表,问题没有解决。另外,重新分库分表过程中新旧 table 增量同步和迁移业务读写流量的复杂度也很大,有比较大的业务风险。
Mysql 的规格是 48C 128G 和 32C 64G。由于会话数据量大,Mysql buffer_pool 有限,数据比较容易从内存淘汰,然后 mysql 需要进行磁盘扫描并将需要的数据加载到内存进行运算,加之比较多的磁盘扫描数据,这时的响应一般在秒级别,接口会给前端返回超时错误,会话列表页空白。
为了适配业务发展,Mysql 会话表 已经添加了 9 个非聚集索引,如果通过增加索引使用业务需要,需要更大的 Mysql 资源,且解决不了冷数据慢查询的问题。增加更多索引也会让 Mysql 写入更慢。
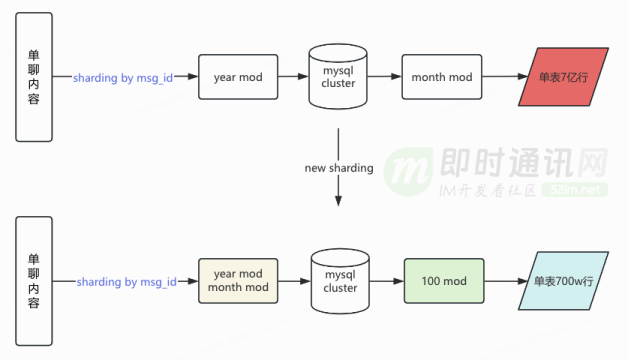
5、消息系统问题 2:私信内容单表空间和写性能接近天花板
每条私信内容都绑定私信自己的发号器生成的 msgkey,即私信内容唯一 id,该 msgkey 包含私信发送时的时间戳(消息 ID 生成可参阅读《微信的海量 IM 聊天消息序列号生成实践》)。读写私信内容 Mysql 之前先从 msgkey 解析出时间,用这个时间路由分库分表。
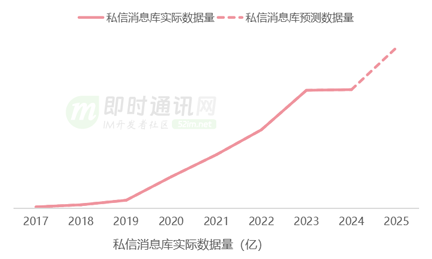
私信内容库按季度分库,分库内按月度分表,单表数据量数亿,数据量最大的用户日增私信 351.9W 条。按照曲率预测,25 年全年数据量有近百亿,如果继续按照月度分表,分表规则不适应增长。
当前该 Mysql 最大写 qps 790,特别活动时写 qps 峰值预计是 20k,但是为了保障 Mysql 服务整体的可靠,单库写流量我们需要控制在 3000qps 以下,无法满足写入量峰值时的需要。
![5]()
此外,消息内容表结构包含了群聊、单聊和应援团小助手全部的属性,增加业务使用难度。绝大部分私信内容是单聊的。
6、消息系统问题 3:服务端代码耦合
B 站的四类私信包括:
- 1)单聊;
- 2)群聊;
- 3)B 端批量私信;
- 4)应援团小助手。
这些私信都需要实现发送和触达两条核心链路,四种私信核心链路的代码逻辑和存储耦合在一起,代码复杂度随着业务功能上线而不断增加,熵增需要得到控制。
从微服务这方面来说,实例和存储耦合会带来资源随机竞争,当一方流量上涨,可能给对方的业务性能带来不必要的影响,也会带来不必要的变更传导。
7、消息系统新架构的升级路径
基于对私信现状的论述,可以确定我们要优化的是一个数据密集型 >> 计算密集型,读多写少(首页未读数)、读少写多(会话)场景兼具的系统。
同时需要拥有热门 C 端产品的稳定性、扩展性和好的业务域解耦。针对读多写少和读少写多制定了针对的技术方案。
具体的实施情况请继续往下阅读。
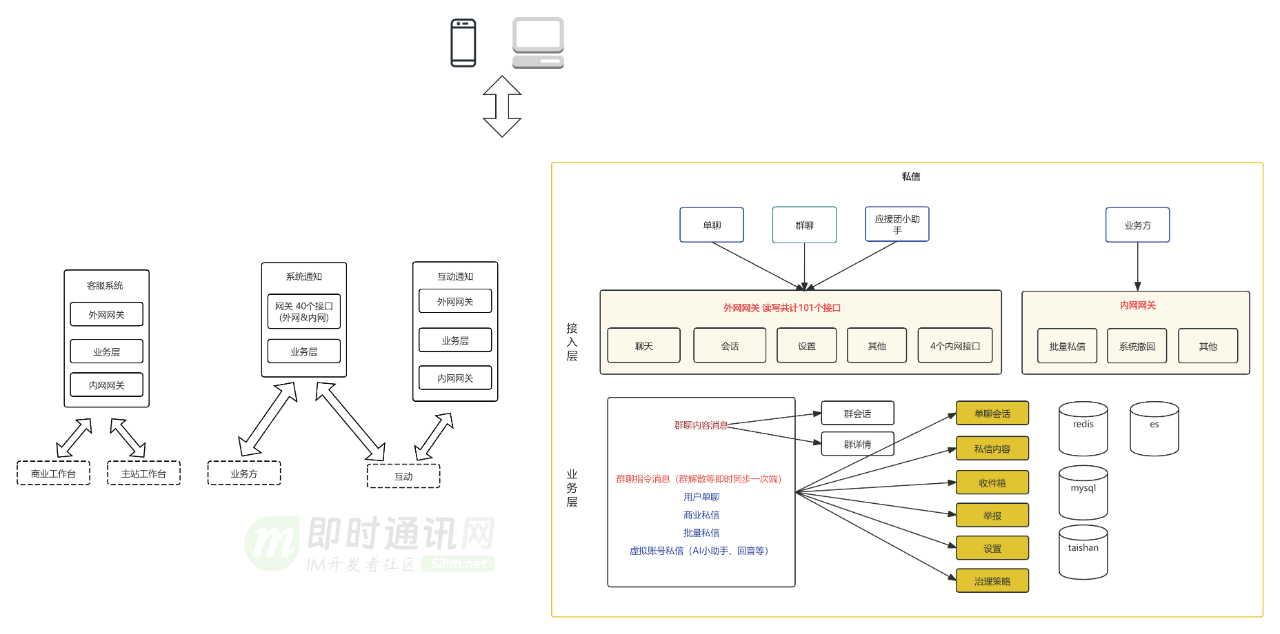
8、新架构的整体设计
结合 B 站业务现状,我觉得比较合理的架构:
![6]()
一个兼顾复杂列表查询架构和 IM 架构的消息域框架,整体分四层:
- 1)接入层:即 toC 的 BFF 和服务端网关;
- 2)业务层:按复杂查询设计系统,用于各种业务形态的支撑;
- 3)平台层:按 IM 架构设计系统,目标是实时、有序的触达用户,平台层可扩展;
- 4)触达层:对接长链和 push。
9、新架构具体升级 1:端上本地缓存降级
端上应该支持部分数据缓存,以确保极端情况下用户端可展示,可以是仅核心场景,比如支付小助手、官号通知,用户在任何情况下打开消息页都不应该白屏。
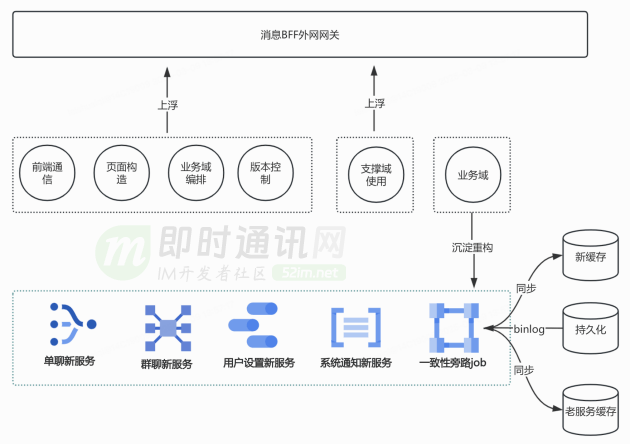
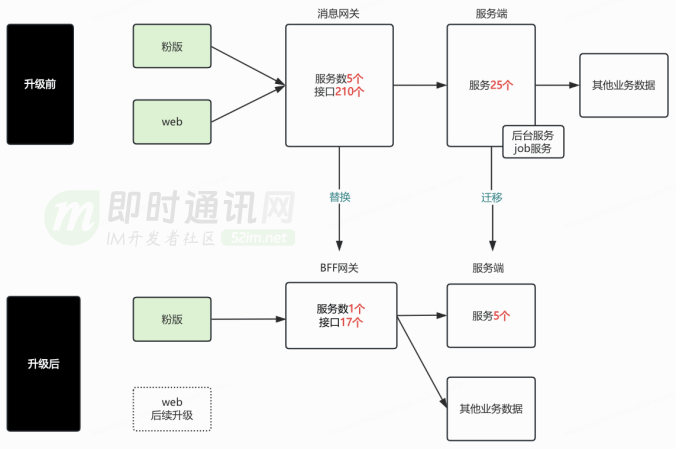
10、新架构具体升级 2:BFF 架构升级
BFF 网关吸收上浮的业务逻辑,控制需求向核心领域传导。服务端基于业务领域的能力边界,抽象出单聊、群聊、系统通知、互动通知和消息设置共五个新服务,提升微服务健康度。
![7]()
新服务剥离了历史包袱,也解决一些在老服务难解的功能 case,优化了用户体验,比如消息页不同类型消息的功能一致性;重新设计会话缓存结构和更新机制,优化 Mysql 索引,优化 Mysql 查询语句,减少了一个量级的慢查询。
11、新架构具体升级 3:服务端可用性升级
11.1 概述
服务端按四层拆分后,集中精力优化业务层和平台层。
业务层:按复杂查询设计系统,用于各种业务形态的支撑
- 1)冷热分离:多级缓存 redis (核心数据有过期)+taishan (有限明细数据)+mysql (全部数据);
- 2)读写分离:95% 以上复杂查询可以迁移到从库读。
平台层:按 IM 架构设计系统,目标是实时、有序的触达用户,平台层可扩展
- 1)Timeline 模型:依赖雪花发号器,成熟方案;
- 2)读写扩散:单聊 - 写扩散,群聊 - 读扩散。
11.2 单聊会话
1)缓存主动预热:
用户在首页获取未读数是一个业务域内可以捕捉的事件,通过异步消费这个事件通知服务端创建会话缓存,提高用户查看会话的缓存命中率。鉴于大部分人打开 B 站并不会进私信,此处可以仅大 UP 预热。大 UP 的 uid 集合可以在数平离线分析会话数据后写入泰山表,这个泰山表更新时效是 T+1。
监控 UP 会话数量实时热点,触发突增阈值时,通过异步链路自动为热点用户主动预热会话列表缓存。
对预热成功率添加监控,并在数平离线任务失败或者预热失败时做出业务告警,及时排查原因,避免功能失效。
2)泰山和 Mysql 双持久化:
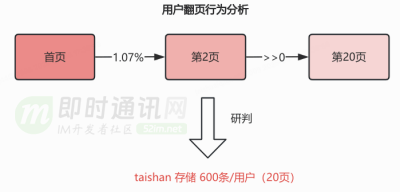
增加泰山存储用户有限会话明细,作为 redis 未命中后的第一回源选择,Mysql 作为泰山之后的次选。基于用户翻页长度分析后确定泰山存储的有限会话的量级。
![9]()
redis 存储 24 小时数据,taishan 存储 600 条 / 用户(20 页),预设到的极端情况才会回源 mysql 从库。
对于 ZSET 和 KV 两种数据结构,评估了各自读写性能的可靠性,符合业务预期。业务如果新增会话类型,可以跟本次新增泰山有限明细一样,基于会话类型的具体规则新增泰山 Key。
3)泰山长尾优化:
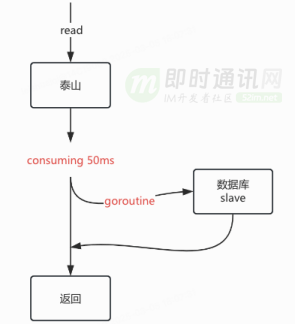
查询 redis 未命中时会优先回源泰山,考虑到泰山 99 分位线在 50ms 以下,而且 Mysql 多从实例都能承受来自 C 端的读请求,所以采用比泰山报错后降级 Mysql 稍微激进的对冲回源策略。
在泰山出现 “长尾” 请求时,取得比较好的耗时优化效果。可以使用大仓提供的 error group 结合 quit channel 实现该回源策略,同时能避免协程泄漏。整个处理过程在业务响应和资源开销中维持中间的平衡,等待泰山的时间可以灵活调整。
![11]()
泰山最初没有数据,可以在泰山未命中时进行被动加载,保证用户回访时能命中。
4)一致性保证:
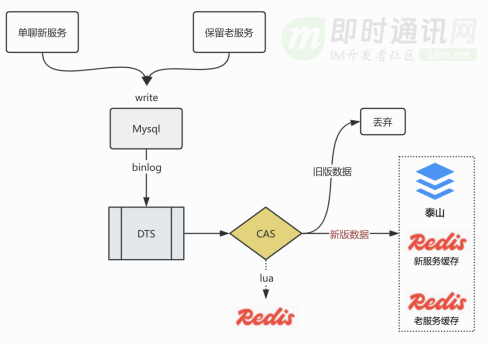
虽然我们重构了新服务,但是老服务也需要保留,用来处理未接入 BFF 的移动端老版本和 web 端请求,这些前端在更新会话时(比如 ACK)请求到了老服务,新服务需要通过订阅会话 Mysql binlog 异步更新本服务的 redis 和泰山。为了避免分区倾斜,订阅 binlog 的 dts 任务使用 id 分区,这样方便的是一条会话在 topic 的分区是固定的。
为了避免两次请求分别命中泰山和 Mysql 时给用户返回的数据不一样,需要解决三大问题:
- a. 当出现分区 rebalance 需要避免重复消费;
- b. 当 Mysql 一条会话记录在短时间内(秒级)多次更新,要保证 binlog 处理器不会逆时间序消费同一个会话的 binlog,即跳过较早版本的 binlog;
- c. 保证泰山写入正确并且从 Mysql 低延迟同步。
这三个问题都要保证最终一致性,具体解决方案是用 redis lua 脚本实现 compare and swap,lua 脚本具有原生的原子性优势。dts 每同步一条 binlog 都会携带毫秒级 mtime,当 binlog 被采用时,mtime 被记入 redis10 分钟,如果下一条 binlog 的 mtime 大于 redis 记录的 mtime,这条 binlog 被采用,否则被丢弃。
这个过程可以考虑使用 gtid 代替 mtime,但这个存在的问题是每个从实例单独维护自己的 gtid,当特殊情况发生 mysql 主从切换,或者 dts 订阅的从节点发生变更,gtid 在 CAS 计算中变得不再可靠,所以我们选择了使用 mtime 作为 Mysql 会话记录的版本。
通过消费路线高性能设计保证泰山异步更新的延迟在 1 秒以内,并在特殊情况延迟突破 1s 时有效告警。高性能消费路线中,每个库的 binlog 分片到 50 个 partition,业务提供不低于 50 个消费 pod,单 pod 配置 100 并发数,按照写泰山 999 分位线 20ms 计算,每秒可以消费 50*100*(1000/20)=250000 条,大约线上峰值 8.3 倍,考虑 dts 本身的 max 延迟在 600~700 毫秒,同步泰山和 redis 的延迟会在 700 毫秒至 1 秒以内,符合业务预期。
![12]()
11.3 收件箱
BFF 已经从业务层和平台层将单聊读收件箱独立出来,本次升级主要是从存储做增量解耦 ,存量单聊收件箱的读流量可以访问旧表。 单聊新收件箱存储采用 redis + 泰山的模式,redis 提供热数据,泰山提供全部数据并采用 RANDOM 读模式,让主副本都能分担读流量。
11.4 私信内容
本次升级主要如下:
- 1)单聊增量数据独立存储,按照单聊业务设计表结构,和群聊、应援团小助手彻底解耦。
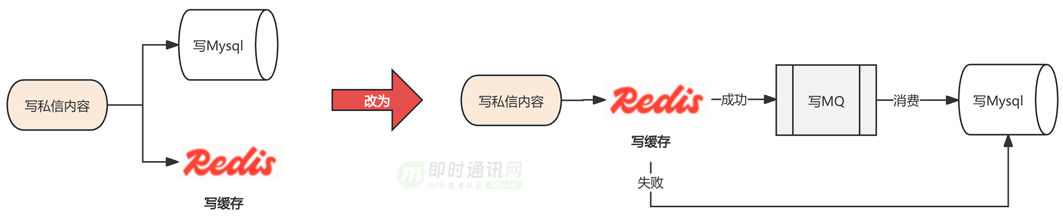
- 2)写 Mysql 升级为异步化操作,提高写性能天花板,这种异步写 Mysql 改造不会影响读消息内容的可用性和设计。
- 3)单聊分库规则升级为月度分库,单库内分表为 100 张。 群聊、应援团小助手和历史单聊依然使用旧的分库分表规则读写 Mysql。
业务需要对增量单聊私信路由分库分表时,先从 msgkey 先解析出时间戳,找到用时间戳对应的月份分库,然后用 msgkey 对 100 取余找到分表。这种方案能达到按时间纬度的冷热数据的分离,同时由于 msgkey 取余的结果具有随机性,平衡了每张表的读写流量。这样预计 2025 年单表数据量能从 9 亿下降到 900 万。
11.5 批量私信
日常通道:日常批量私信任务共用通道,共用配额。
高优通道:主要通过将链路上 topic partition 扩容、消费 POD 扩容、POD 内消费通道数扩容、缓存扩容、akso proxy 连接数扩容,把平均发送速度从 3500 人 / 秒提高到 30000 人 / 秒。这个通道可以特殊时期开给特殊业务使用。
12、本文小结
我们逐步发现技术升级不是一蹴而就的,它是一个逐步优化的过程。
设计技术方案前设立合适和有一些挑战的目标,但这个目标要控制成本,做好可行性。
设计技术方案的时候,需要清楚现有架构与理想架构的差距和具体差异点,做多个方案选型,并确定一个,这个更多从技术团队考虑。
其次要保证功能在新老架构平稳过渡,保证业务的稳定性。后面持续关注新老架构的技术数据,持续优化,老架构要持续关注它的收敛替换。
IM 系统是一个老生常谈的话题,也是融合众多有趣技术难点的地方,欢迎感兴趣的同行交流研讨。
13、参考资料
[1] 浅谈 IM 系统的架构设计
[2] 简述移动端 IM 开发的那些坑:架构设计、通信协议和客户端
[3] 一套海量在线用户的移动端 IM 架构设计实践分享 (含详细图文)
[4] 一套原创分布式即时通讯 (IM) 系统理论架构方案
[5] 从零到卓越:京东客服即时通讯系统的技术架构演进历程
[6] 蘑菇街即时通讯 / IM 服务器开发之架构选择
[7] 微信技术总监谈架构:微信之道 —— 大道至简 (演讲全文)
[8] 现代 IM 系统中聊天消息的同步和存储方案探讨
[9] 子弹短信光鲜的背后:网易云信首席架构师分享亿级 IM 平台的技术实践
[10] 一套高可用、易伸缩、高并发的 IM 群聊、单聊架构方案设计实践
[11] 从游击队到正规军 (一):马蜂窝旅游网的 IM 系统架构演进之路
[12] 瓜子 IM 智能客服系统的数据架构设计(整理自现场演讲,有配套 PPT)
[13] 阿里钉钉技术分享:企业级 IM 王者 —— 钉钉在后端架构上的过人之处
[14] 阿里技术分享:电商 IM 消息平台,在群聊、直播场景下的技术实践
[15] 一套亿级用户的 IM 架构技术干货 (上篇):整体架构、服务拆分等
[16] 从新手到专家:如何设计一套亿级消息量的分布式 IM 系统
[17] 企业微信的 IM 架构设计揭秘:消息模型、万人群、已读回执、消息撤回等
[18] 融云技术分享:全面揭秘亿级 IM 消息的可靠投递机制
[19] 阿里 IM 技术分享 (三):闲鱼亿级 IM 消息系统的架构演进之路
[20] 基于实践:一套百万消息量小规模 IM 系统技术要点总结
[21] 跟着源码学 IM (十):基于 Netty,搭建高性能 IM 集群(含技术思路 + 源码)
[22] 一套十万级 TPS 的 IM 综合消息系统的架构实践与思考
[23] 得物从 0 到 1 自研客服 IM 系统的技术实践之路
[24] 一套分布式 IM 即时通讯系统的技术选型和架构设计
[25] 微信团队分享:来看看微信十年前的 IM 消息收发架构,你做到了吗
[26] 转转平台 IM 系统架构设计与实践 (一):整体架构设计
[27] 支持百万人超大群聊的 Web 端 IM 架构设计与实践
[28] 转转客服 IM 聊天系统背后的技术挑战和实践分享
即时通讯技术学习:
- 移动端 IM 开发入门文章:《新手入门一篇就够:从零开发移动端 IM》
- 开源 IM 框架源码:https://github.com/JackJiang2011/MobileIMSDK(备用地址点此)
(本文已同步发布于:http://www.52im.net/thread-4886-1-1.html)