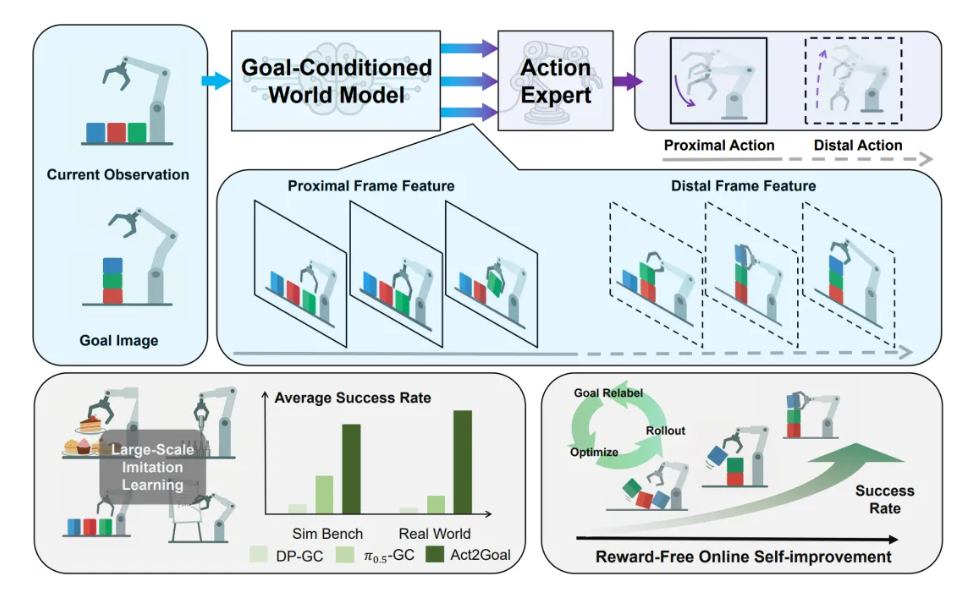
智元机器人宣布发布 Act2Goal 方案 —— 这不仅仅是一个新的操作算法,更是一种让机器人“以终为始”的全新思维方式。
根据介绍,不同于传统机器人机械地执行死板指令,Act2Goal引入了“目标条件世界模型”。这意味着,机器人不再只是“看一步走一步”,而是拥有了预见未来的能力——在真正动手之前,它已经在大脑中构建了从现状通往目标的完整因果链条。这种将视觉推理与动作控制合二为一的端到端架构,让Act2Goal能够在从未见过的环境和物体面前,展现出惊人的零样本泛化能力。
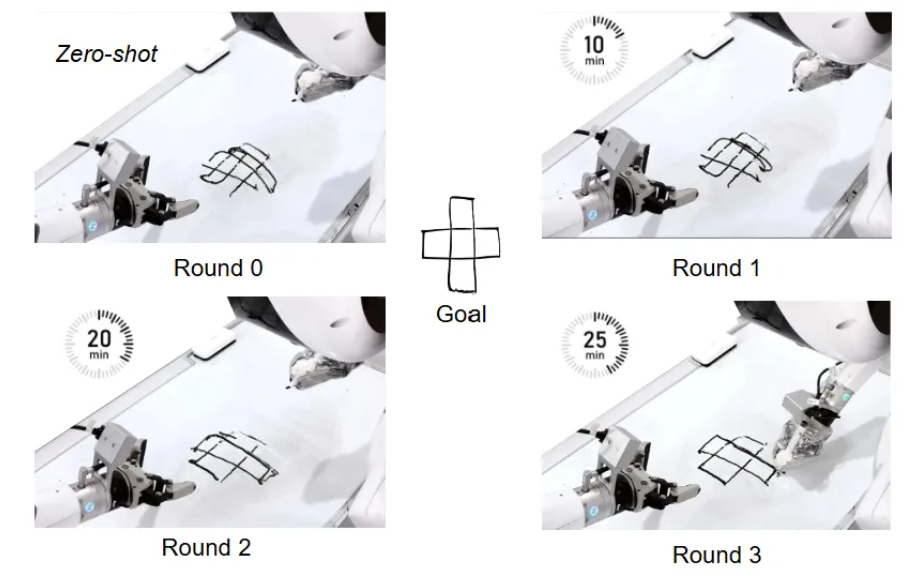
且Act2Goal具备“自我进化”的本能。 它不需要人类手把手教(无奖励信号),就能在真实世界的交互中,快速“复盘”自己的行为轨迹。实验数据显示,面对高难度的陌生任务,Act2Goal仅需数分钟的在线自我磨练,成功率就能从30%提升至90%。
“所见即所向,让机器人的每一次行动,都精准地通往目标。”
![]()
Act2Goal的核心在于将目标条件世界模型与动作生成策略统一于端到端框架,实现对任务演化过程的结构化理解。在每次操作前,系统不仅感知当前状态和目标状态,还通过世界模型预测从当前到目标的未来视觉轨迹,为动作专家提供连续、多尺度的规划依据。通过这种方式,目标不再是静态终点,而是一条可感知、可跟随的演化路径,从而显著提升长时序操作的稳定性与泛化能力。这一范式带来了两个关键优势:
- 长时序任务中保持高精度与全局对齐:端到端设计结合多尺度时间规划,使机器人既能精确执行短期动作,又能保持整体目标方向一致。
- 零样本泛化与快速适应新场景:系统能够在未见过的物体、目标配置或复杂环境中稳定执行,并通过在线自我提升机制快速适应新任务,进一步增强鲁棒性和可扩展性。
为了在长时序任务中同时处理精细动作和全局规划,Act2Goal引入了多尺度时域哈希(Multi-Scale Temporal Hashing, MSTH)机制。系统将规划过程划分为:
- 短时精细段(Proximal):连续高频采样,用于精确控制机械臂动作;
- 长时粗粒段(Distal):自适应采样,用于全局路径规划和目标对齐。
这种设计使机器人在复杂操作中能够兼顾局部动作精度与整体目标方向,有效防止误差累积和目标偏离。
MSTH可同时应用于世界模型的视觉规划与动作专家模块的动作规划。
![]()
为了让Act2Goal具备强大的泛化能力,系统首先通过大规模离线模仿学习进行训练。系统微调预训练的世界模型,使其能够生成从当前状态到目标状态的多视角、多尺度视觉轨迹,并遵循MSTH规则。动作生成模块与世界模型联合训练,通过参考轨迹预测生成可执行动作。
这种联合训练保证了视觉轨迹预测不仅真实可信,而且能够有效指导动作生成,为动作规划奠定基础。系统对整个端到端模型进行行为克隆微调,使从视觉感知到动作生成形成完整闭环。通过以上训练,Act2Goal学会根据当前状态和目标状态预测未来轨迹,并生成可执行动作,从而具备良好的泛化能力和长期操作稳定性。
![]()
尽管离线训练使系统具备较强的泛化能力,但在真实环境中面对新任务、未知物体或复杂操作链时,机器人仍可能遇到性能下降。为此,Act2Goal引入在线自我提升机制,利用回顾性经验重放(HER)实现自主性能优化。
在执行过程中,机器人会自动收集每一步的状态、动作及执行结果,并将轨迹重新标注为新的目标示例,存入回放缓冲区。无论任务是否成功完成,系统都能利用这些数据进行端到端微调,仅更新新增的LoRA层参数,基础模型保持冻结。通过这一机制,机器人能够在未见过的环境和目标中快速适应,实现零样本泛化与长期稳定操作,为复杂任务提供强大的鲁棒性和可扩展性。
![]()
Act2Goal的核心贡献在于重新审视了目标条件操作中的一个基本问题:从当前状态到目标状态之间,机器人是否真正理解过程?通过在策略中显式引入目标条件世界模型,并结合多尺度时间建模与深度融合机制,项目团队目标条件机器人操作提供了一种新的建模范式。“我们相信,这种“先理解世界如何变化,再决定如何行动”的思路,将为更通用、更可靠的机器人系统提供重要支撑。”