Mistral AI 宣布开源 Mistral3 系列模型,包括3B、8B、14B 三个小型密集模型及迄今为止功能最强大的 Mistral Large3,一款稀疏混合专家模型,使用 410 亿个活跃参数和 6750 亿个总参数进行训练。所有模型均以 Apache 2.0 许可证发布,覆盖从边缘设备到企业级推理的全场景需求。
![]()
![]()
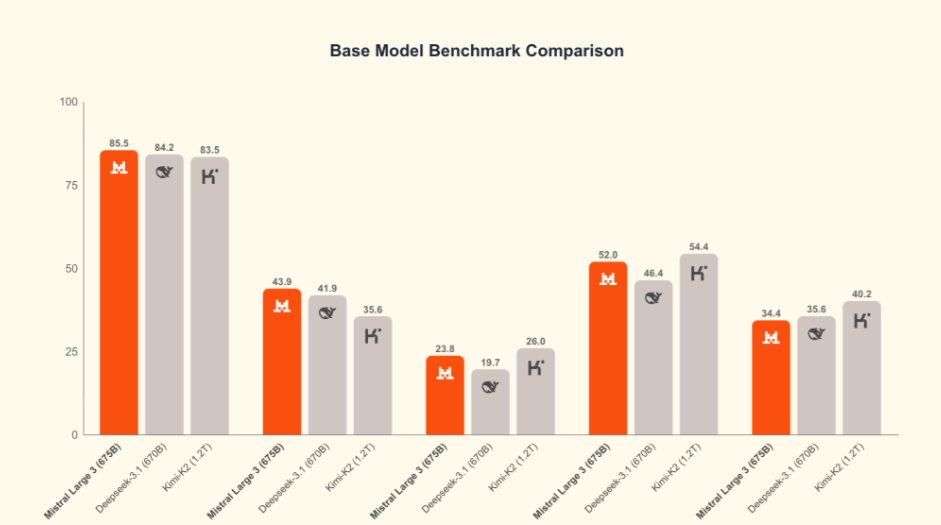
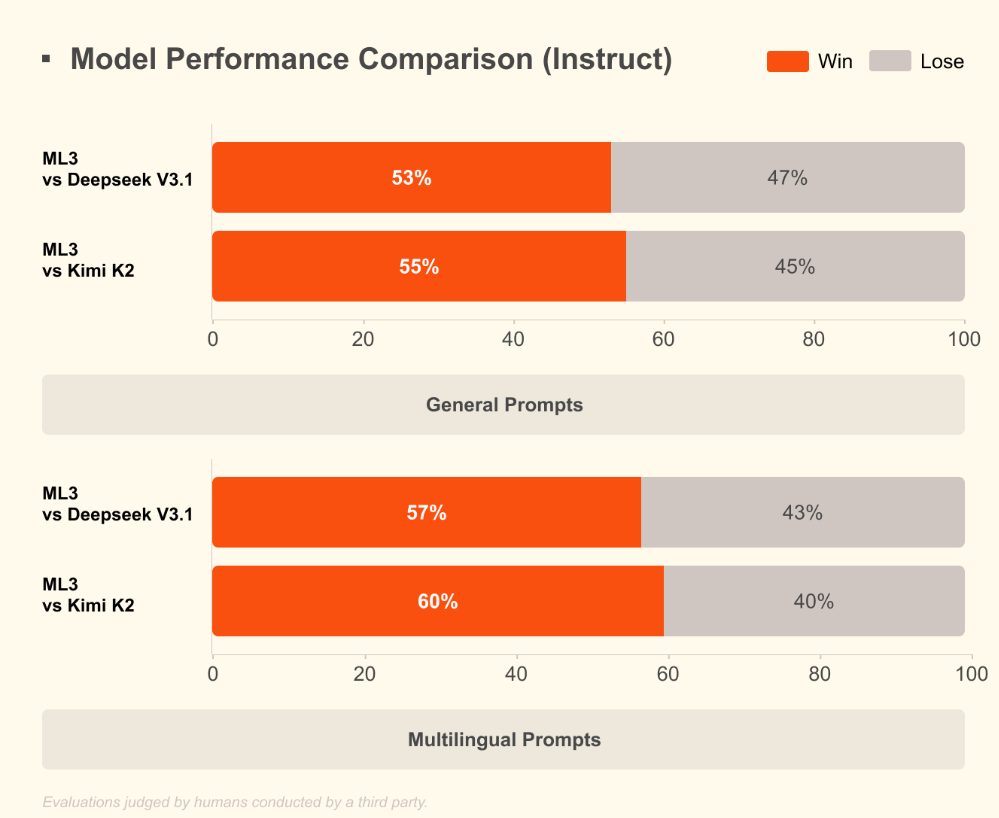
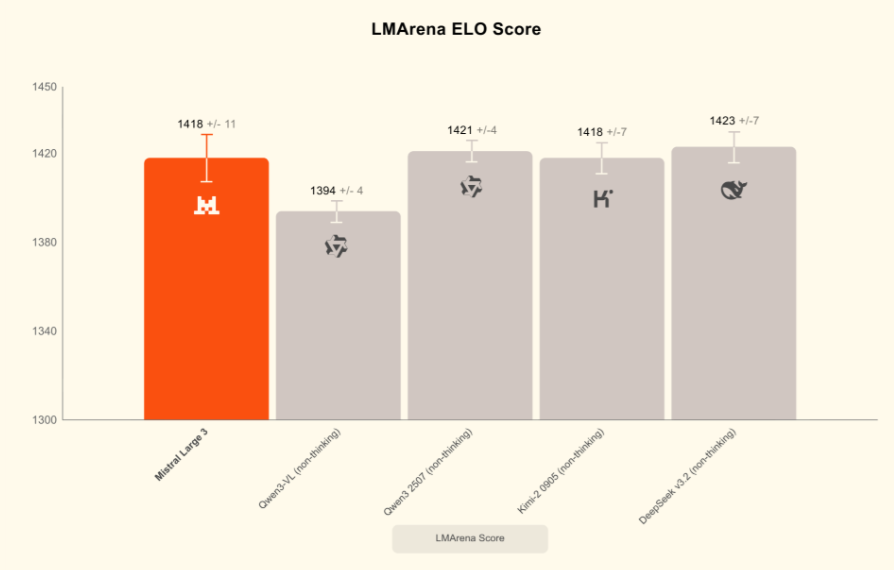
公告称,Mistral Large 3 是目前世界上最好的开放权重模型之一,它完全基于 NVIDIA 的 3000 个 H200 GPU 从零开始训练而成。Mistral Large 3 是 Mistral 自开创性的 Mixtral 系列以来推出的首个专家混合模型,代表了 Mistral 在预训练方面的重大进步。经过后训练,该模型在通用提示上的表现与市面上最好的指令调优开放权重模型不相上下,同时还展现出卓越的图像理解能力,并在多语言对话(例如,非英语/中文)方面取得了一流的性能。
![]()
Mistral Large 3 与 vLLM 和 Red Hat 协同工作,对开源社区非常友好。Mistral AI 发布了一个使用llm-compressor构建的 NVFP4 格式的 checkpoint。这个优化后的 checkpoint 使用户能够在 Blackwell NVL72 系统以及使用vLLM 的单个 8×A100 或 8×H100 节点上高效运行 Mistral Large 3 。
所有的全新 Mistral 3 模型,从 Large 3 到 Ministral 3,均在 NVIDIA Hopper GPU 上进行训练,以充分利用高带宽 HBM3e 内存来处理前沿规模的工作负载。NVIDIA 工程师为整个 Mistral 3 系列模型启用了对TensorRT-LLM和SGLang 的高效推理支持,从而实现高效的低精度执行。
针对 Large 3 的稀疏 MoE 架构,NVIDIA 集成了最先进的 Blackwell 注意力机制和 MoE 内核,增加了对预填充/解码解耦服务的支持,并与 Mistral 合作开发了推测性解码,使开发者能够在 GB200 NVL72 及更高级别的设备上高效地处理长上下文、高吞吐量的工作负载。在边缘端,NVIDIA 提供了在DGX Spark、RTX PC 和笔记本电脑以及Jetson 设备上优化部署 Ministral 模型的方案,为开发者提供了一条从数据中心到机器人运行这些开放模型的一致且高性能的路径。
![]()
Mistral AI 声称,Ministral 3 在所有开源软件模型中实现了最佳的性价比。在实际应用场景中,生成的 token 数量和模型大小同样重要。Ministral 指令模型在性能上与同类模型持平甚至更胜一筹,同时生成的 token 数量通常却少一个数量级。
目前,Mistral Large3已在公司官方平台 Le Platforme 上线 API,定价为每百万 token 输入0.8美元、输出2.4美元,约为 GPT-4o 的一半,并支持微调与私有部署。
更多详情可查看官方公告:https://mistral.ai/news/mistral-3