快手宣布正式发布新一代旗舰多模态模型 Keye-VL-671B-A37B,并同步开放代码。公告称,该模型具备“善看会想”,并在在通用视觉理解、视频分析、数学推理等多项核心benchmark中全面领跑。
在保持基础模型强大通用能力的前提下,Keye-VL-671B-A37B 对视觉感知、跨模态对齐与复杂推理链路进行了系统升级,实现了多模态理解和复杂推理的全方位性能跃升:更会“看”、更会“想”、也更会“答”。无论是日常场景还是高难任务,都能给出更准确、更稳健的回应。
Keye-VL-671B-A37B采用DeepSeek-V3-Terminus作为大语言模型基座初始化,具备更强的文本推理能力,视觉模型采KeyeViT初始化,来自KeyeVL1.5,二者通过MLP层进行桥接。
Keye-VL-671B-A37B的预训练涵盖三个阶段,系统化构建模型的多模态理解与推理能力。模型复用Keye-VL-1.5的视觉编码器,该编码器已经通过8B大小的模型在1T token的多模态预训练数据上对齐,具备强大的基础感知能力。
结合严格筛选的约300B高质量数据预训练数据,以有限计算资源高效构建模型的核心感知基础,确保视觉理解能力扎实且计算成本可控。具体训练流程如下:
- 第一阶段:冻结ViT和LLM,只训练随机初始化的Projector,保证视觉、语言特征能初步做对齐。
- 第二阶段:打开全部参数进行预训练。
- 第三阶段:在更高质量的数据上做退火训练,提升模型的细粒度感知能力。
Keye多模态的预训练数据构建,通过自动化数据管道实施严格的过滤、重采样与VQA数据增强,覆盖OCR、图表及表格等多种格式,端到端提升模型的感知质量与泛化能力;在退火阶段,使用DeepSeek-V3-Terminus合成思维链数据,使模型在深化感知训练的同时保持LLM原有的强大推理能力。
Keye-VL-671B-A37B的后训练由监督微调,冷启动和强化学习三个步骤组成,训练任务涵盖视觉问答、图表理解、富文本OCR、数学、代码、逻辑推理等。在SFT阶段,采用更多多模态和纯文本的长思维链数据,对模型的纯文本能力进行回火并增强多模态能力。在冷启动阶段,采用推理数据增强模型的推理能力,在强化学习阶段,采用复杂推理数据提升模型的think和no_think能力,并加入视频数据,增强模型的视频理解能力。
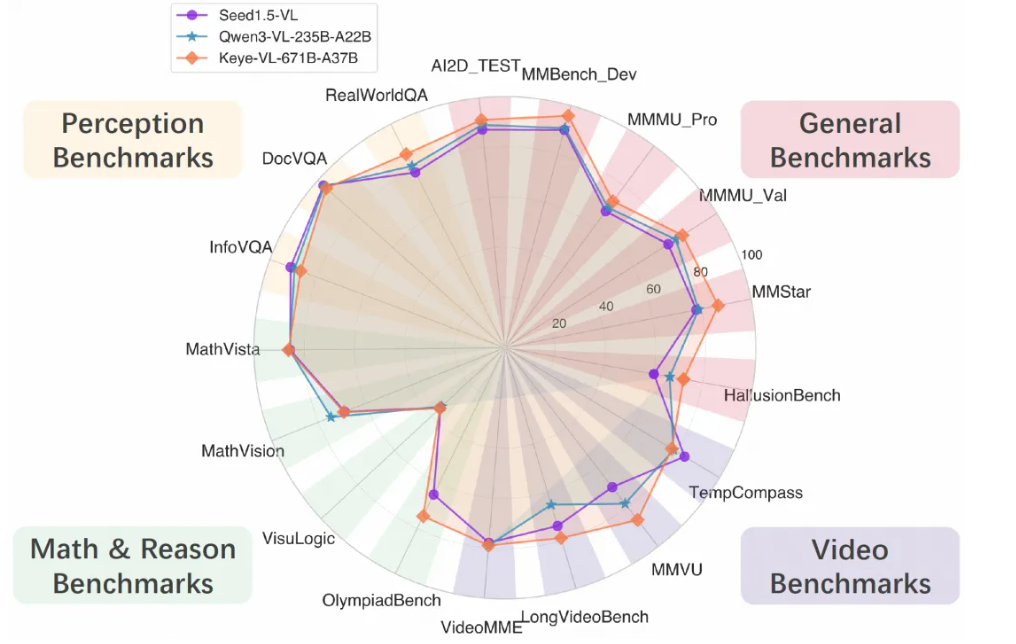
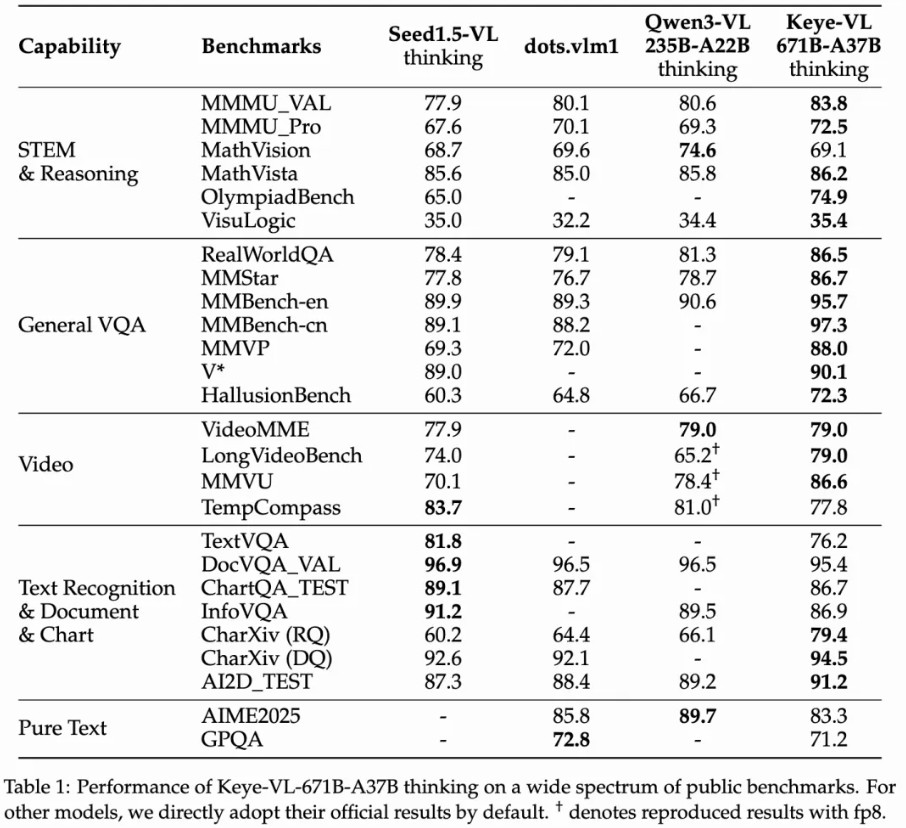
具体评测结果如下:
![]()
![]()
官方表示,面向未来,Keye-VL将在持续夯实基础模型能力的同时,进一步融合多模态Agent能力,走向更“会用工具、能解复杂问题”的智能形态。强化模型的多轮工具调用能力,让它能够在真实任务中自主调用外部工具,完成搜索、推理、整合;同时推进“think with image”、“think with video”等关键方向,使模型不仅能看懂图像与视频,还能围绕它们进行深度思考与链式推理,在复杂的视觉信号中发掘关键信息。
通过基础能力+Agent能力的双轮驱动,Keye-VL目标是不断拓展多模态智能的上限,向更通用、更可靠、更强推理的下一代多模态系统迈进。