作者:来自 Elastic Alex Salgado
![]()
了解如何使用Elasticsearch和 LangGraph 构建多 — agent LLM 系统,并实现反射模式,使 agent 能通过混合搜索和 ELSER embeddings 实现自我纠错。
Agent Builder 现在作为技术预览版提供。开始使用Elastic Cloud 试用版,并在此查看 Agent Builder 文档。
介绍
在生产级 LLM 系统中编排多个 AI agents 是当前的挑战。就像乐队需要指挥来协调音乐家,多 agents 系统需要智能编排来确保专门的 agent 协作一致、从错误中学习并持续改进。
我们将构建一个实现反射模式的多 agents 系统,这是一种新兴模式,使 agent 在结构化反馈循环中协作以迭代改进响应质量。完成后,我们将构建一个演示,用于分析 IT 事件,对日志执行语义搜索,生成根本原因分析,并通过自我纠错直到达到定义的质量阈值。
该架构结合了三种互补技术。
- LangGraph 编排循环工作流,使 agent 能够批判和改进自己的输出,这是传统基于 DAG(Directed Acyclic Graphs)引擎不可能实现的。
- Elasticsearch 作为数据骨干,通过 ELSER 模型提供混合搜索(结合语义和关键字),存储长期记忆以实现持续学习。
- Ollama 为开发提供本地 LLM 模型,但该系统设计可适用于通过 API 暴露模型的主要提供商(OpenAI、Anthropic 等)。
前提条件
要按照此教程并运行演示,你需要:
软件和工具:
设置 Python 环境:
安装后,验证其运行并下载模型:
# Check Ollama is active
ollama list
# Download the required model (~4.7 GB)
ollama pull llama3.1:8b
所有代码都在下面的 GitHub 仓库中提供:
git clone https://github.com/salgado/blog-elastic-orchestration.git
cd blog-elastic-orchestration
我们建议使用虚拟环境来避免依赖冲突:
# Create virtual environment
python3 -m venv venv
# Activate virtual environment
source venv/bin/activate # Linux/Mac
# venv\Scripts\\activate # Windows
# Install dependencies
pip install langgraph langchain langchain-ollama elasticsearch python-dotenv
配置环境变量(.env):
在项目根目录创建一个 .env 文件,并加入以下变量:
# Required
ELASTIC_ENDPOINT=https://your-deployment.es.region.gcp.elastic-cloud.com:443
ELASTIC_API_KEY=your-base64-api-key
OLLAMA_MODEL=llama3.1:8b
# Optional (with default values - adjust if necessary)
ELASTIC_INDEX_LOGS=incident-logs
ELASTIC_INDEX_MEMORY=agent-memory
MAX_REFLECTION_ITERATIONS=3
QUALITY_THRESHOLD=0.8
如何获取 Elasticsearch 凭据:
- 访问 Elastic Cloud 控制台
- 创建 Deployment 或 Project
- 对于serverless模型,创建 Project(可使用免费试用)
- 对于 managed 模型,创建 Deployment
- 复制 Endpoint(例如 https://xxx.es.region.gcp.elastic-cloud.com:443)
- 在 Security → API Keys 中创建 API Key
在 Kibana 中部署 ELSER
在 Kibana 中部署 ELSER 模型
在运行 Python 脚本之前,你需要在 Kibana 中手动部署 ELSER 模型:
步骤 1:访问 Trained Models
- 打开 Kibana
- 导航到:Menu(☰)→ Machine Learning → Trained Models
步骤 2:查找并部署 ELSER
- 搜索 .elser_model_2_linux-x86_64 或 .elser_model_2
- 点击 “Deploy”(或 “Start deployment”)
步骤 3:配置部署
- Deployment name:保持默认或使用 “elser-incident-analysis”
- Optimize for:选择 “Search”(重要!)
- Number of allocations:1(开发环境足够)
- Threads per allocation:1
- 点击 “Start”
步骤 4:等待部署
部署大约需要 2–3 分钟。监控状态:
- downloading → starting → started
步骤 4:等待部署
部署大约需要 2–3 分钟。监控状态:
- downloading → starting → started
python setup_elser.py
预期输出:
======================================================================
ELSER SETUP FOR ELASTICSEARCH
======================================================================
INFO:__main__:Connected to Elasticsearch
INFO:__main__:==========================================================
INFO:__main__:STEP 1: Creating Inference Endpoint
INFO:__main__:==========================================================
....
....
======================================================================
SETUP COMPLETE!
======================================================================
What was configured:
1. Inference Endpoint: 'elser-incident-analysis'
2. Index: 'incident-logs' with semantic_text field
3. Sample data: 15 incident logs
4. Semantic search: Tested and working
5. Hybrid search: Tested and working
Next steps:
→ Run the POC: python elastic_reflection_poc.py
======================================================================
本教程采用渐进式设计。我们先解释为什么需要 多agents系统,然后详细介绍反射模式及其在 LangGraph 中的编排,探索 Elasticsearch 提供的关键数据功能,最后逐步执行 POC,并详细解释输出结果。
架构概览
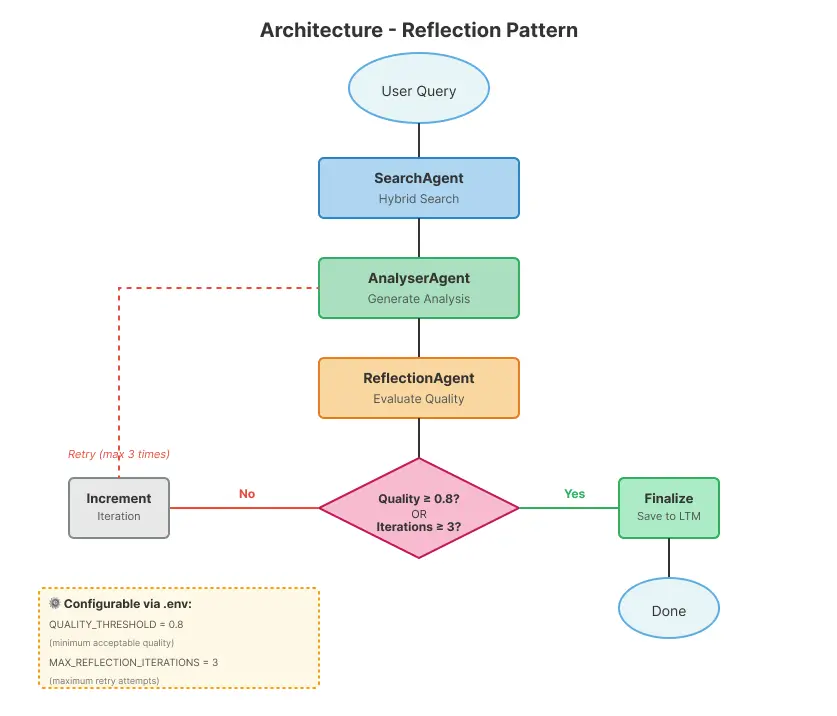
在深入实现细节之前,理解各组件的连接方式很重要。下图展示了完整的系统流程,从初始用户查询到最终完成并保存到长期记忆。
![]()
该工作流实现了一个循环模式,对输出质量进行持续评估。流程从用户查询开始,依次经过 SearchAgent(在 Elasticsearch 中进行混合搜索)、AnalyserAgent(生成分析结果)和 ReflectionAgent(质量评估)。关键在于 Router:如果质量达到 0.8 阈值,系统将完成并保存结果;否则,迭代计数器增加,流程返回 AnalyserAgent,这次会结合上一次反射的反馈。该循环会重复,直到质量满意或达到最大迭代次数(默认 3 次)。
系统中的 agent 专长:
- SearchAgent:使用混合搜索(语义 + 关键字)查询 Elasticsearch
- AnalyserAgent:分析日志并生成根本原因分析
- ReflectionAgent:评估输出质量并提供反馈
为什么设置为 3 次迭代?这一限制基于开发该演示时的观察,作为合理标准:
- 防止当模型无法改进时陷入无限循环
- 我们很少在 3 次尝试后看到显著改进
- 你可以通过 LangGraph 使用的 MAX_REFLECTION_ITERATIONS 环境变量进行调整
Elasticsearch 作为数据骨干,不仅为 SearchAgent 提供混合搜索,还存储长期记忆(agent-memory 索引)。LangGraph管理编排,确保 agent 之间正确共享状态,并使循环流程确定性运行。现在让我们详细探索每个组件。
1)为什么需要 多 agents?
单一 LLM 调用的问题
对于简单任务,单次 API 调用 LLM 已经很强大,但在复杂工作流中会失败。我们来看两个真实场景:
场景 1:根本原因分析(RCA)
Task: Analyze 10,000+ log entries across 50 microservices to discover why the database is timing out
单一 LLM 的局限性:
- 上下文窗口太小(无法容纳所有日志)
- 无工具访问能力(无法查询、无法从 Elasticsearch 获取日志、查询 CPU/内存使用情况、检查服务状态)
- 无质量控制(可能产生虚构原因)
- 无记忆(如果事件再次发生,会重复分析)
场景 2:安全事件分流
Task: Correlate 50+ Indicators of Compromise (IOCs) across firewalls, IDS, endpoint agents
单一 LLM 的局限性:
- 无法搜索威胁情报数据库
- 无结构化调查工作流
- 无审计记录(合规要求)
- 不会从过去事件中学习
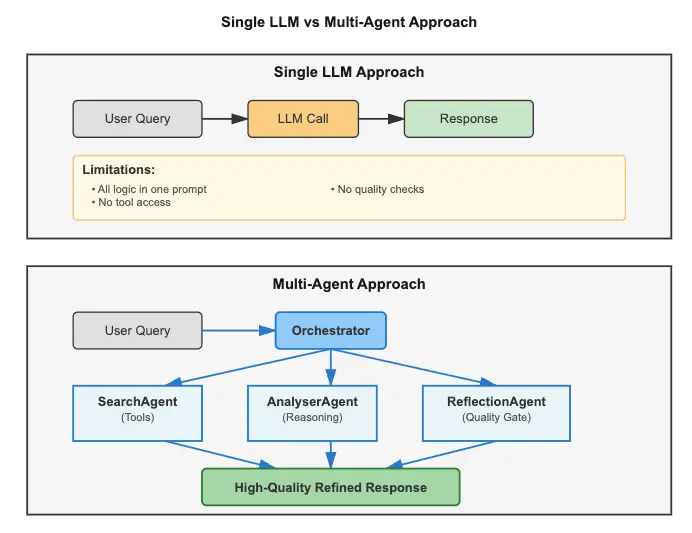
单一 LLM 调用的核心限制:虽然现代 LLM 可以通过函数调用和工具访问外部数据,但单次请求 — 响应交互无法编排复杂的多步骤工作流并形成反馈循环,也无法在会话间维持长期记忆,更无法协调专门的 agent 相互批判和改进输出。
多 agents 系统:专长与协调
多 agents 架构通过划分职责解决这些问题。不是单一 LLM 尝试做所有事情,每个 agent 专注于特定任务:一个 agent 在外部源中搜索数据(解决上下文窗口限制),另一个进行分析和推理,第三个验证质量(消除虚构)。agent 之间的共享状态保存在数据库中,形成可在多次执行间持续的长期记忆。
![]()
架构模式说明:本教程聚焦于反射模式,但生产环境中的多 agents 系统通常结合多种模式:
- 规划 agent:将复杂任务拆分为可执行子任务(参考 RAG 获取计划模板)
- 工具使用 agent:执行实际操作(重启服务、部署等)
- 反射 agent:评估质量并提供反馈(我们的重点)
我们选择反射模式,因为它是确保质量和可靠性最关键的模式。通过实现循环再评估机制,输出持续被批判和优化,该模式显著减少虚构并提高响应准确性。
编排:agent 如何协调
拥有多个专长 agent 解决了职责问题,但产生了新的挑战:谁来协调执行?这就是编排的作用。
编排是协调多个 agent 共同朝着共同目标工作的过程。可以把它想象成指挥带领乐队:每个音乐家(agent)演奏自己的乐器(特定任务),但指挥决定何时演奏以及各部分如何连接。
在我们的系统中,LangGraph 扮演指挥角色,协调执行流程:
User Query
↓
SearchAgent (searches logs in Elasticsearch)
↓
AnalyserAgent (generates analysis based on logs)
↓
ReflectionAgent (evaluates analysis quality)
↓
Router (conditional decision)
↓
├─→ Quality ≥ 0.8? → Finalize (saves to memory)
└─→ Quality < 0.8? → Retry (returns to AnalyserAgent with feedback)
LangGraph 如何进行编排:
- 管理共享状态(Agent-to-Agent 通信):每个 agent 读写包含 query、search_results、analysis、quality_score 等内容的 IncidentState 对象。此通信确保所有 agent 使用相同数据而不会产生冲突。
- 控制执行流程:定义 agent 被调用的顺序(在本例中为 SearchAgent → AnalyserAgent → ReflectionAgent),并实现条件路由。Router 根据 quality_score 决定下一步。
- 支持反馈循环:允许工作流多次返回 AnalyserAgent,这在仅支持线性流程(DAG)的传统引擎中是不可能的。
- 确保无冲突协调:每个 agent 依次执行,接收更新状态,并将结果确定性地传递下去。
没有编排,我们将只有 3 个孤立的 agent,无法协作。有了 LangGraph,我们拥有一个协调的 多 agents 系统,每个 agent 都为最终目标做出贡献:生成高质量的事件分析。
这种方法的好处:
- 每个 agent 专注于特定职责,允许单独优化
- agent 可以独立替换,便于维护和升级
- 通过专门的反射进行质量控制,确保输出可靠
- 系统通过存储在长期记忆中的过去决策逐步改进
持久存储的作用:
多 agents 系统需要三种类型的记忆:
在本教程中,我们使用 Elasticsearch 作为长期记忆,因为它提供语义搜索(ELSER)、混合查询,并能自然地与日志/指标集成。
2)编排:循环反射模式(LangGraph)
在上一节中,我们看到系统有 3 个专长 agent,并且 LangGraph 协调它们的执行。现在,让我们理解为什么需要专门的编排工具,以及它如何实现反射模式。
AI agent 编排有传统工具无法满足的独特需求:
- 反馈循环:agent 需要根据质量评估重复任务
- 条件路由:下一步操作依赖于上一步结果(而非固定流程)
- 可变共享状态:多个 agent 读取并修改相同上下文
- 持久性:系统需要在故障后继续执行并从中断处恢复
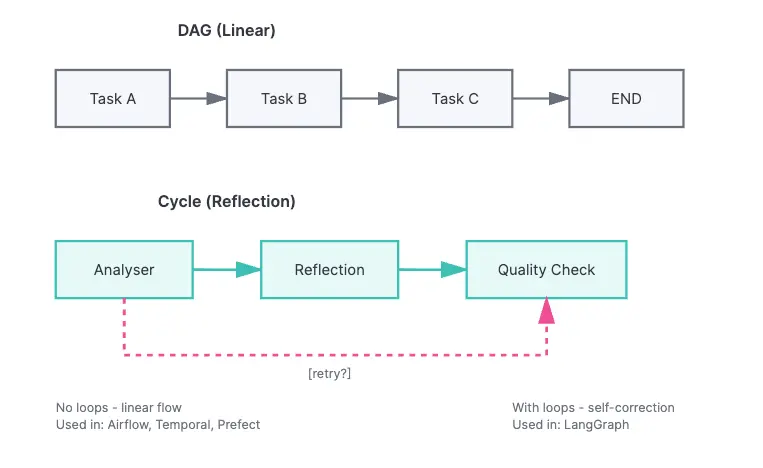
与 DAG(Directed Acyclic Graphs - 有向无环图)——仅支持线性流程、不支持循环不同,AI agent 需要循环来实现反射(agent 批判自己的输出)、带反馈的重试以及多轮推理。
使用 LangGraph 管理工作流
LangGraph(来自 LangChain)专为 agent 工作流设计,提供原生循环流程、基于 agent 输出的条件路由,以及内置状态管理。
![]()
反射模式:自我纠错循环
没有质量控制,LLMs 可能产生不完整或虚构的输出:
User: "Analyze this database timeout"
AnalyserAgent (without reflection):
"The database timed out. You should check the logs."
问题:
-
- 未识别根本原因
- 未量化影响
- 建议模糊
- 无实际日志证据
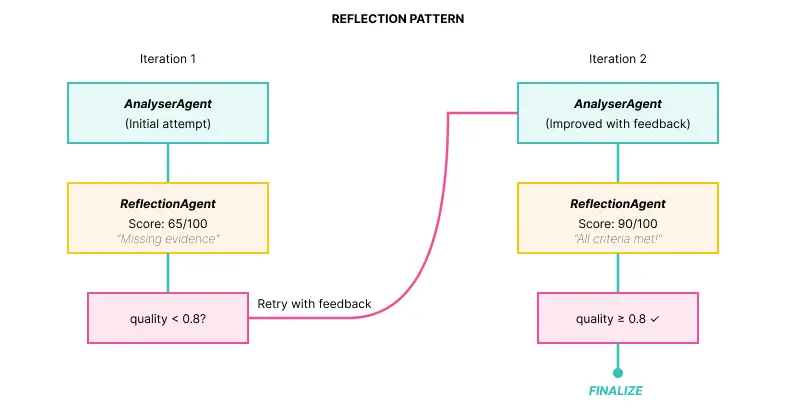
解决方案是增加一个反射循环,由专门的 agent 评估输出质量:
![]()
实现:三个组件
ReflectionAgent:批判并评分
def reflection_agent(state: IncidentState) -> IncidentState:
"""
ReflectionAgent: Evaluates analysis quality
Quality Criteria:
- Completeness (all aspects covered?)
- Evidence (based on data?)
- Actionability (clear actions?)
- Precision (logical conclusions?)
Score: 0.0 to 1.0
"""
logger.info(f"ReflectionAgent (iteration {state['iteration']})")
analysis = state["analysis"]
llm = get_llm(temperature=0.2)
prompt = f"""You are a technical analysis critic.
**Analysis to evaluate:**
{analysis}
**Task:**
Evaluate the analysis quality using these criteria:
1. **Completeness**: Does it cover root cause, impact, actions? (0-25 points)
2. **Evidence**: Is it based on concrete data from logs? (0-25 points)
3. **Actionability**: Are recommended actions clear and specific? (0-25 points)
4. **Precision**: Are conclusions logical and well-founded? (0-25 points)
**Response format (IMPORTANT - follow exactly):**
SCORE: 80
FEEDBACK: [your detailed critique and improvement suggestions]
The SCORE must be a single number between 0-100 on the same line as "SCORE:".
Do NOT use markdown formatting in the SCORE line (no asterisks, bold, etc.).
Example: "SCORE: 75" or "SCORE: 75/100" are acceptable.
Example of WRONG format: "**SCORE:** 75" or "SCORE: **75**"
Be critical but constructive.
"""
messages = [
SystemMessage(content="You are a rigorous technical critic."),
HumanMessage(content=prompt)
]
response = llm.invoke(messages)
reflection_text = response.content
# Parse score
try:
score_line = [line for line in reflection_text.split('\n') if 'SCORE:' in line][0]
score_str = score_line.split(':')[1].strip()
# Remove markdown formatting (**, *, etc.) and extra spaces
score_str = re.sub(r'\*+', '', score_str) # Remove asterisks
score_str = score_str.strip()
# Extract first number found (handles cases like "80/100", "80", "** 80", etc.)
numbers = re.findall(r'\d+', score_str)
if not numbers:
raise ValueError("No number found in score")
score_value = int(numbers[0])
# If format is "80/100", use the denominator; otherwise assume out of 100
if '/' in score_str and len(numbers) > 1:
score = score_value / int(numbers[1])
else:
# If number > 1, assume it's already 0-100 scale; if <= 1, assume 0-1 scale
score = score_value / 100.0 if score_value > 1 else score_value
# Ensure score is in valid range [0, 1]
score = max(0.0, min(1.0, score))
logger.info(f"Parsed score: {score:.2f} from line: {score_line}")
except Exception as e:
logger.warning(f"Failed to parse score: {e}")
logger.warning(f"Reflection text (first 200 chars): {reflection_text[:200]}")
logger.warning(f"Defaulting to 0.5")
score = 0.5 # Default if parsing fails
# Update state
state["reflection"] = reflection_text
state["quality_score"] = score
state["messages"].append(AIMessage(content=f"[ReflectionAgent] Score: {score:.2f}\n{reflection_text}"))
logger.info(f"Reflection completed (score: {score:.2f})")
return state
Router:条件逻辑
def decisor_router(state: IncidentState) -> Literal["increment", "finalize"]:
"""
Decisor Router: Defines next step in Reflection cycle
Logic:
- quality_score >= QUALITY_THRESHOLD -> finalize (success)
- iteration >= max_iterations -> finalize (limit reached)
- otherwise -> increment -> analyser (new iteration)
QUALITY_THRESHOLD comes from environment variable (default: 0.8)
"""
quality = state["quality_score"]
iteration = state["iteration"]
max_iter = state["max_iterations"]
logger.info(f"Router: quality={quality:.2f}, iteration={iteration}/{max_iter}")
# Check quality threshold
if quality >= float(os.getenv("QUALITY_THRESHOLD", "0.8")):
logger.info("Quality threshold met -> finalize")
return "finalize"
# Check max iterations
if iteration >= max_iter:
logger.info("Max iterations reached -> finalize")
return "finalize"
# Continue reflection loop
logger.info("Quality below threshold -> retry")
return "increment"
LangGraph:循环流程
def create_reflection_graph() -> StateGraph:
"""
Creates StateGraph with Reflection Pattern
Flow:
START → search → analyser → reflection → decisor_router
↑ │
│ [increment]
└───── increment ─────────┘
│
[finalize]
↓
finalize → END
Note: SearchAgent runs ONCE at the start.
Reflection loop iterates only on analyser → reflection.
"""
# Initialize graph
workflow = StateGraph(IncidentState)
# Add nodes (3 specialized agents + utility nodes)
workflow.add_node("search", search_agent) # Hybrid search
workflow.add_node("analyser", analyser_agent) # LLM analysis
workflow.add_node("reflection", reflection_agent) # Quality evaluation
workflow.add_node("increment", increment_iteration)
workflow.add_node("finalize", finalize_output)
# Add edges
workflow.set_entry_point("search") # Start with search
workflow.add_edge("search", "analyser") # search → analyser
workflow.add_edge("analyser", "reflection")
workflow.add_edge("increment", "analyser") # Loop back to analyser (NOT search)
# Conditional edge (reflection → increment OR finalize)
workflow.add_conditional_edges(
"reflection",
decisor_router,
{
"increment": "increment", # Retry (increment first)
"finalize": "finalize" # Approved
}
)
workflow.add_edge("finalize", END)
return workflow
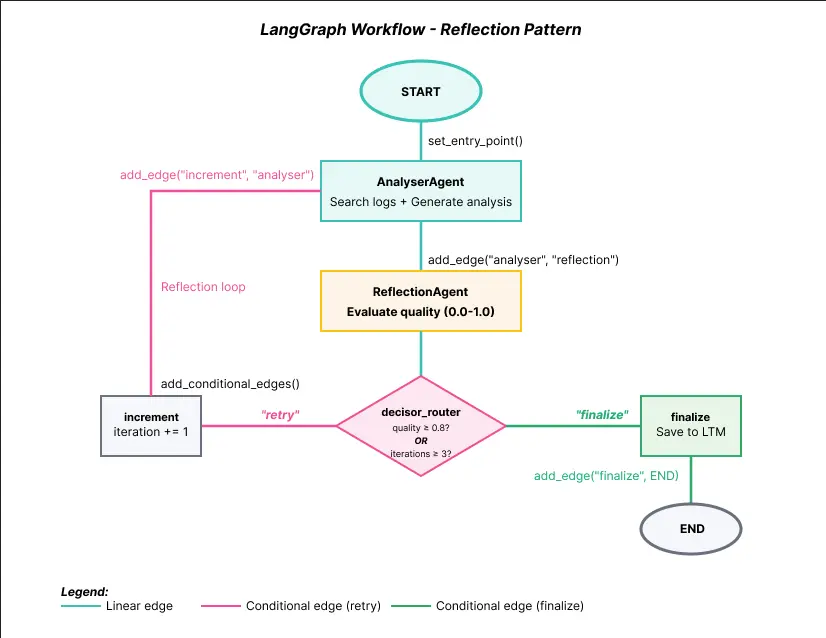
工作流可视化:
![]()
上图展示了完整的 LangGraph 工作流结构。注意关键元素:
- START → AnalyserAgent:通过 set_entry_point() 定义入口
- AnalyserAgent → ReflectionAgent:通过 add_edge() 创建线性边
- ReflectionAgent → decisor_router:条件决策
- decisor_router → increment:当 quality < 0.8 时(增加计数器并重试)
- increment → AnalyserAgent:闭合反射循环(图中用粉色标记的反馈边)
- decisor_router → finalize:当 quality ≥ 0.8 或达到最大迭代次数
- finalize → END:工作流结束
该反馈边(图中粉色标记)创建了反射循环,使此模式区别于传统 DAG。
结果:迭代中的质量提升
执行示例:
ITERATION 1
******
AnalyserAgent:
"Database timeout detected in logs."
ReflectionAgent:
SCORE: 65/100
FEEDBACK:
- Missing root cause (WHY timeout?)
- No impact quantification
- No specific actions
Router: 0.65 < 0.8 → RETRY │
****
ITERATION 2 (with feedback)
AnalyserAgent (improved):
"Root Cause: Connection pool exhausted
Evidence: 32 'pool timeout' errors
Impact: 32 failed requests (10 min)
Actions:
1. Restart db-worker
2. Increase pool size to 50
3. Add monitoring at 80%"
ReflectionAgent:
SCORE: 90/100
FEEDBACK: All criteria met!
Router: 0.90 >= 0.8 → FINALIZE
3)数据层:Elasticsearch 作为长期记忆和 RAG
多 — agent 系统需要持久存储,用于两个场景:
- 长期记忆(LTM):存储过去的决策和学习
- 检索增强生成(RAG):上下文数据(日志、文档)
在本节中,我们将使用 Elasticsearch 实现这些功能。
系统的两个索引
系统在 Elasticsearch 中使用两个不同的索引,每个索引有特定用途:
![]()
让我们详细探索每个索引,从数据源开始。
长期记忆:从过去决策中学习
没有持久记忆,系统会重复从头处理相同事件:
# Day 1: Agent solves incident
AnalyserAgent: "Root cause: Connection pool exhausted"
# Day 30: Similar incident occurs
AnalyserAgent: "Let me analyze from scratch..."
# No memory of past solution
解决方案是将成功的决策保存到 Elasticsearch,以便未来检索:
def save_to_long_term_memory(
es: Elasticsearch,
agent_name: str,
memory_type: str,
content: str,
success: bool,
metadata: dict = None
):
"""
Saves Long-Term Memory (LTM) to Elasticsearch
Types: "decision", "lesson", "pattern"
Used to improve agents over time
"""
config = get_elastic_config()
doc = {
"memory_id": f"{agent_name}_{datetime.now().timestamp()}",
"agent_name": agent_name,
"memory_type": memory_type,
"content": content,
"timestamp": datetime.now().isoformat(),
"success": success,
"metadata": metadata or {}
}
es.index(index=config.index_memory, body=doc)
logger.info(f"LTM saved: {agent_name} - {memory_type}")
影响:
Without LTM:
Week 1: Solve incident → Forget
Week 2: Same incident → Solve from scratch
Week 3: Same incident → Solve from scratch
With LTM:
Week 1: Solve incident → Save to memory
Week 2: Same incident → Retrieve past solution → 50% faster
Week 3: Similar incident → Pattern recognition → Proactive fix
混合搜索:语义(ELSER)+ 关键字(BM25)
混合搜索的重要性:混合搜索结合了关键字匹配的精确性和 ML 模型的语义理解,确保你既能找到精确匹配,又能找到纯语义搜索可能遗漏的概念相关内容。
Query: "database timeout problems"
# Keyword search (BM25):
- Finds: "ERROR: database timeout after 30s" (exact match)
- Misses: "ERROR: connection refused" (no "timeout")
# Semantic search (ELSER):
- Finds: "database timeout" + "connection refused" +
- "query execution slow" + "pool exhausted"
# Hybrid (both):
- Better ranking (combined scores)
- Higher recall (finds more relevant cases)
配置 ELSER(Elasticsearch 语义模型):
# Step 1: Create inference endpoint
es.inference.put(
inference_id="elser-incident-analysis",
task_type="sparse_embedding",
body={"service": "elser"}
)
# Step 2: Create index with semantic_text field
es.indices.create(
index="incident-logs",
body={
"mappings": {
"properties": {
"message": {"type": "text"},
"content": {"type": "text"},
# Special field: auto-generates ELSER embeddings
"semantic_content": {
"type": "semantic_text",
"inference_id": "elser-incident-analysis"
}
}
}
}
)
实现:
def hybrid_search(query, size=15):
"""Combines semantic (ELSER) + keyword (BM25) search"""
return es.search(
index="incident-logs",
body={
"query": {
"bool": {
"should": [
# Semantic search
{
"semantic": {
"field": "semantic_content",
"query": query
}
},
# Keyword search
{
"multi_match": {
"query": query,
"fields": ["message^2", "content"]
}
}
]
}
}
}
)
索引 1:incident-logs(RAG 的数据源)
这是系统分析事件日志的存储索引。它包含特殊的 semantic_text 字段,该字段会自动生成 ELSER embeddings:
# Index mapping
{
"mappings": {
"properties": {
"message": {
"type": "text"
},
"content": {
"type": "text"
},
"semantic_content": {
"type": "semantic_text",
"inference_id": "elser-incident-analysis"
},
"timestamp": {
"type": "date"
},
"severity": {
"type": "keyword"
}
}
}
}
索引 2:agent-memory(持续学习)
存储成功的分析结果以便未来检索(长期记忆)。每个文档都是系统可以查询的 “记忆”:
# Structure of a saved memory
{
"agent": "AnalyserAgent",
"content": "Root Cause: Connection pool exhausted...",
"quality_score": 0.9,
"timestamp": "2025-01-21T10:30:00Z",
"success": true,
"iteration_count": 2,
"logs_analyzed": 5
}
系统如何使用这些记忆:
- 对 content 字段进行语义搜索:即使用词不同,也能找到相似解决方案
- 按 quality_score >= 0.80 过滤:仅从高质量决策中学习
- 按 _score(相关性)+ 时间戳排序:优先考虑最新且相关的解决方案
- 将前 3 条注入 AnalyserAgent 的 prompt:使用过去解决方案作为模板,加速分析
结果:重复事件通常在 1 次迭代中即可解决。
语义搜索如何检索记忆:
当新事件到达时,系统通过比较概念而不仅是词汇来搜索相似记忆。
代码检索示例:
1)混合语义搜索
def retrieve_past_solutions(es: Elasticsearch, query: str, top_k: int = 3) -> List[dict]:
"""
Retrieves similar past solutions from Long-Term Memory using semantic search
Uses hybrid search (semantic + keyword) to find similar solutions even with different words.
Only retrieves solutions with quality_score >= QUALITY_THRESHOLD and success=True.
Uses QUALITY_THRESHOLD from environment (default: 0.8).
Example:
Query: "database timeout"
Finds: "connection pool exhaustion" (different words, same concept)
"""
config = get_elastic_config()
quality_threshold = float(os.getenv("QUALITY_THRESHOLD", "0.8"))
try:
result = es.search(
index=config.index_memory,
body={
"query": {
"bool": {
"should": [
# Semantic search (ELSER) - finds similar concepts
{
"semantic": {
"field": "semantic_content",
"query": query
}
},
# Keyword search (BM25) - finds exact word matches
{
"match": {
"content": {
"query": query,
"boost": 1.0
}
}
}
],
"minimum_should_match": 1, # At least one should match
"filter": [
{"term": {"success": True}},
{"range": {"metadata.quality_score": {"gte": quality_threshold}}}
]
}
},
"sort": [
{"_score": {"order": "desc"}},
{"timestamp": {"order": "desc"}}
],
"size": top_k
}
)
solutions = []
for hit in result["hits"]["hits"]:
source = hit["_source"]
solutions.append({
"content": source.get("content", ""),
"score": hit["_score"],
"quality_score": source.get("metadata", {}).get("quality_score", 0),
"timestamp": source.get("timestamp", ""),
"iterations": source.get("metadata", {}).get("iterations", 0)
})
logger.info(f"Retrieved {len(solutions)} past solutions (threshold: {quality_threshold})")
return solutions
except Exception as e:
logger.warning(f"Could not retrieve past solutions: {e}")
return []
2)调用位置(在 AnalyserAgent 内部)
# Retrieve past solutions from LTM
es = get_elastic_client()
past_solutions = retrieve_past_solutions(es, query, top_k=3)
# Format past solutions for prompt
past_context = ""
if past_solutions:
past_context = "\n\n**SIMILAR PAST INCIDENTS (for reference):**\n"
for i, sol in enumerate(past_solutions, 1):
past_context += f"\n{i}. (Quality: {sol['quality_score']:.2f}, Iterations: {sol['iterations']})\n"
past_context += f"{sol['content']}\n"
past_context += "\n(Use these as templates, but analyze current logs independently)\n"
3)在 prompt 中的使用方式
prompt = f"""You are an IT incident analysis expert.
**User query:** {query}
**Logs found:**
{context}
{feedback_context}
{past_context}
**Task:**
Analyze the logs and provide:
1. Root cause
2. Impact
3. Recommended actions
Be specific and base your analysis only on the provided logs."""
可量化收益:在重复事件中,系统更快,通过使用过去解决方案作为模板,通常在 1 次迭代中解决,而不是 3 次。
Elasticsearch 在统一系统中提供两种能力(长期记忆 LTM 和 RAG)。混合搜索先使用关键字匹配(BM25)进行预过滤,减少搜索空间,然后在过滤结果上应用语义搜索(ELSER)—— 结合了速度与语义理解。对时间序列的优化允许高效管理工作流历史。与可观测性日志和指标的自然集成意味着可以在同一平台上统一 agent 与运维数据。最后,通过 ELSER 对所有数据进行语义索引,agent 本身可以使用自然语言查询日志和过去决策 —— 从而检索上下文相关信息。
4)运行演示
快速设置
如果还未设置环境,请参考文章开头的前置条件部分。
运行演示
运行分析:
确认 Ollama 正在运行且模型已下载后,执行:
python elastic_reflection_poc.py "database connection timeout"
实际输出(含注释):
INFO:__main__:======================================================================
INFO:__main__:MULTI-AGENT ORCHESTRATION - REFLECTION PATTERN
INFO:__main__:======================================================================
INFO:__main__:Starting analysis: 'database connection timeout'
INFO:__main__:
INFO:__main__:SearchAgent: Performing hybrid search
INFO:elastic_config:Connecting to Elasticsearch: https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443
INFO:elastic_transport.transport:HEAD https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/ [status:200 duration:0.744s]
INFO:elastic_transport.transport:GET https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/ [status:200 duration:0.148s]
INFO:elastic_config:Connected to Elasticsearch Cloud
INFO:elastic_config: Cluster: dc80c0ec021b46c996d59d9053745153
INFO:elastic_config: Version: 8.11.0
INFO:elastic_config: Status: N/A (Serverless - cluster.health not available)
INFO:elastic_config:Checking indices...
INFO:elastic_transport.transport:HEAD https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/incident-logs [status:200 duration:0.152s]
INFO:elastic_transport.transport:HEAD https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/agent-memory [status:200 duration:0.151s]
INFO:elastic_config:All indices ready
INFO:elastic_transport.transport:POST https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/incident-logs/_search [status:200 duration:0.309s]
INFO:__main__:Hybrid search found 15 results
INFO:__main__:Search completed: 15 logs found
INFO:__main__:AnalyserAgent (iteration 1)
INFO:elastic_transport.transport:POST https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/agent-memory/_search [status:200 duration:0.150s]
INFO:__main__:Retrieved 0 past solutions (threshold: 0.80)
INFO:__main__:Using Ollama model: llama3.1:8b
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:__main__:Analysis completed (15 logs analyzed)
INFO:__main__:ReflectionAgent (iteration 1)
INFO:__main__:Using Ollama model: llama3.1:8b
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:__main__:Parsed score: 0.65 from line: SCORE: 65
INFO:__main__:Reflection completed (score: 0.65)
INFO:__main__:Router: quality=0.65, iteration=1/4
INFO:__main__:Quality below threshold -> retry
INFO:__main__:Incrementing iteration to 2
INFO:__main__:AnalyserAgent (iteration 2)
INFO:elastic_transport.transport:POST https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/agent-memory/_search [status:200 duration:0.147s]
INFO:__main__:Retrieved 0 past solutions (threshold: 0.80)
INFO:__main__:Using Ollama model: llama3.1:8b
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:__main__:Analysis completed (15 logs analyzed)
INFO:__main__:ReflectionAgent (iteration 2)
INFO:__main__:Using Ollama model: llama3.1:8b
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:__main__:Parsed score: 0.85 from line: SCORE: 85
INFO:__main__:Reflection completed (score: 0.85)
INFO:__main__:Router: quality=0.85, iteration=2/4
INFO:__main__:Quality threshold met -> finalize
INFO:__main__:Finalizing output
INFO:elastic_transport.transport:POST https://serverless-oct-search-dc80c0.es.us-central1.gcp.elastic.cloud:443/agent-memory/_doc [status:201 duration:0.452s]
INFO:__main__:LTM saved: AnalyserAgent - decision
INFO:__main__:Output finalized (iterations: 2)
INFO:__main__:
INFO:__main__:======================================================================
INFO:__main__:ANALYSIS COMPLETE
INFO:__main__:======================================================================
INFO:__main__:Quality Score: 0.85
INFO:__main__:Iterations: 2
INFO:__main__:
======================================================================
RESULTS
======================================================================
**Incident Analysis Report**
**Root Cause:** The root cause of the incident is a missing index on the `orders.created_at` column in the PostgreSQL database, which caused sequential scans leading to 15s query times, resulting in connection pool exhaustion and subsequent cascading failures.
**Evidence:**
* Log entry [ERROR] 2025-10-31T09:26:25.446312+00:00 from service `reporting-service` indicates a slow query on the `orders` table with a missing index on `created_at`.
* Log entry [CRITICAL] 2025-10-31T09:41:25.446312+00:00 from service `monitoring` confirms that database connection pool exhaustion is due to slow queries on the unindexed `orders.created_at` column.
* Log entry [INFO] 2025-10-31T09:44:25.446312+00:00 from service `database-admin` confirms the root cause analysis and identifies the missing index as the primary cause.
**Impact:** The incident resulted in a 100% failure rate for payment processing, with an estimated revenue impact of $28,500 and approximately 1,200 affected users.
**Recommended Actions:**
1. **Recreate Index:** Recreate the index on `orders.created_at` to prevent sequential scans and improve query performance.
2. **Monitor Database Performance:** Monitor database performance metrics, such as query execution time, connection pool utilization, and slow query count, to detect potential issues before they escalate.
3. **Review Query Plans:** Review query plans for queries that access the `orders` table to identify opportunities for optimization and index creation.
4. **Implement Index Maintenance:** Implement a regular schedule for reviewing and maintaining database indexes to prevent similar issues in the future.
**Timeline:**
* The issue started on 2025-10-31T09:26:25.446312+00:00, when the first slow query was detected on the `orders` table.
* The connection pool exhaustion occurred around 2025-10-31T09:41:25.446312+00:00, causing cascading failures and business impact.
* The root cause was identified by 2025-10-31T09:44:25.446312+00:00.
**Context:** The missing index on `orders.created_at` was likely dropped during a migration or database maintenance operation, leading to the performance issues.
======================================================================
Quality: 85% | Iterations: 2 | Logs analyzed: 15
======================================================================
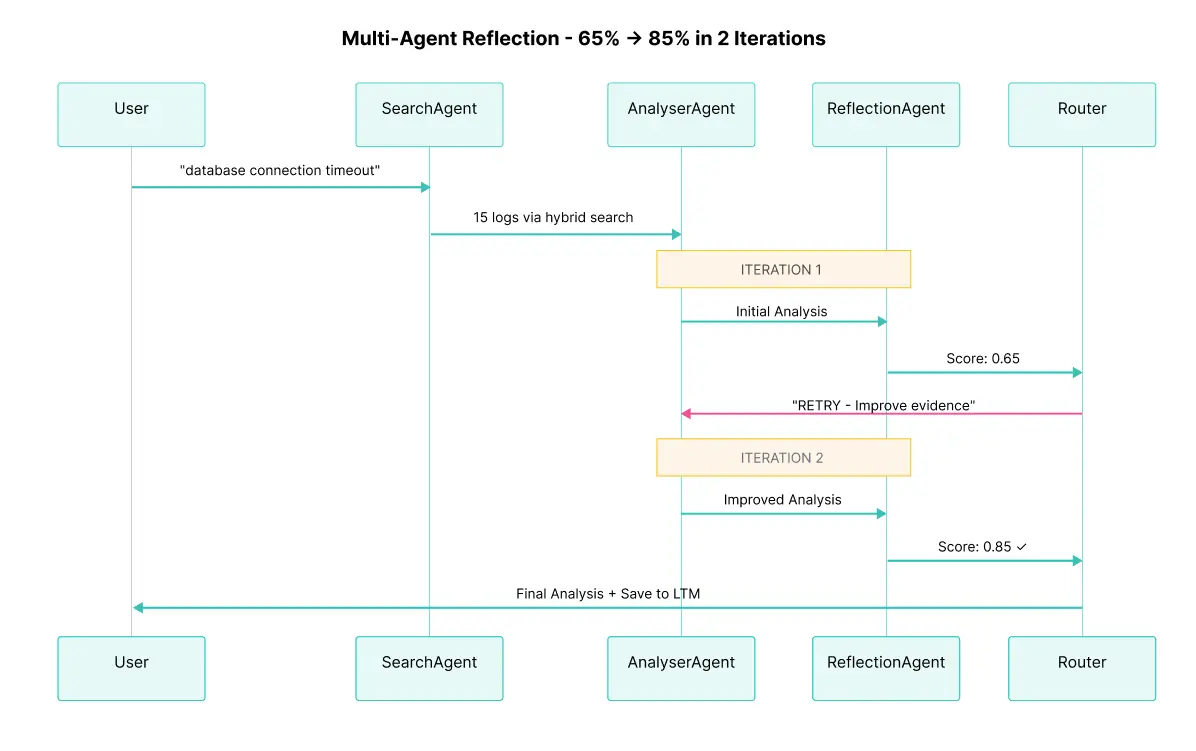
完整执行流程:
![]()
上图展示了用户、SearchAgent、AnalyserAgent、ReflectionAgent 与 Elasticsearch 在 2 次迭代中的交互。注意:
- SearchAgent 仅在工作流开始时查询 Elasticsearch(通过混合搜索找到 15 条日志)
- AnalyserAgent 重用这些日志并生成分析 2 次(根据反射反馈,迭代 1 到迭代 2 成功改进)
- ReflectionAgent 评估质量 2 次(迭代 1 提供关键反馈,迭代 2 批准)
- Router 在每次反射后决定执行 “increment”(重试)或 “finalize”
- 在迭代 2 中,质量分数(0.85)超过阈值(0.80),触发自动完成
- 最终高质量结果保存到 agent-memory 索引中作为长期记忆,使未来类似事件更快解决
结论
我们构建了一个自我纠错的多 — agent 系统,展示了 AI 应用设计的新方式。与依赖可能产生不一致输出的单次 LLM 调用不同,我们实现了反射模式,使专长 agent 协作、批判并迭代改进结果。
系统的支柱同样重要:
- 反射模式通过结构化反馈循环提供自我纠错机制
- LangGraph 编排循环工作流,突破传统 DAG 的限制
- Elasticsearch 统一语义搜索与长期记忆
完整代码可在 GitHub 获取。你可以用自己的数据进行实验,调整领域的质量标准,探索反射模式如何提升 AI 系统。
参考资料:
原文:https://www.elastic.co/search-labs/blog/multi-agent-system-llm-agents-elasticsearch-langgraph