![]()
在物联网技术日新月异的今天,数据指数级增长、数据类型愈发多样,场景日益复杂且变化迅速。一款真正好用的数据库必须具备强大的适应能力和不断进化的能力,从架构设计到性能优化,全方位提升自身能力,以适应物联网时代的数据管理需求。
今天,KaiwuDB V3.0 全新发布,将高性能时序数据处理、多模融合、分布式、安全特性、AI 等诸多能力集于一体,为企业提供高性能、高可靠、低成本且易运维的一站式数据管理解决方案,帮助企业有效应对物联网时代海量、实时、多模数据的管理挑战,实现降本增效和数据驱动业务创新的双重目标。
![KaiwuDB V3.0 产品特性全景图]()
KaiwuDB V3.0 产品特性全景图
划重点 | KaiwuDB 3.0 七大新特性
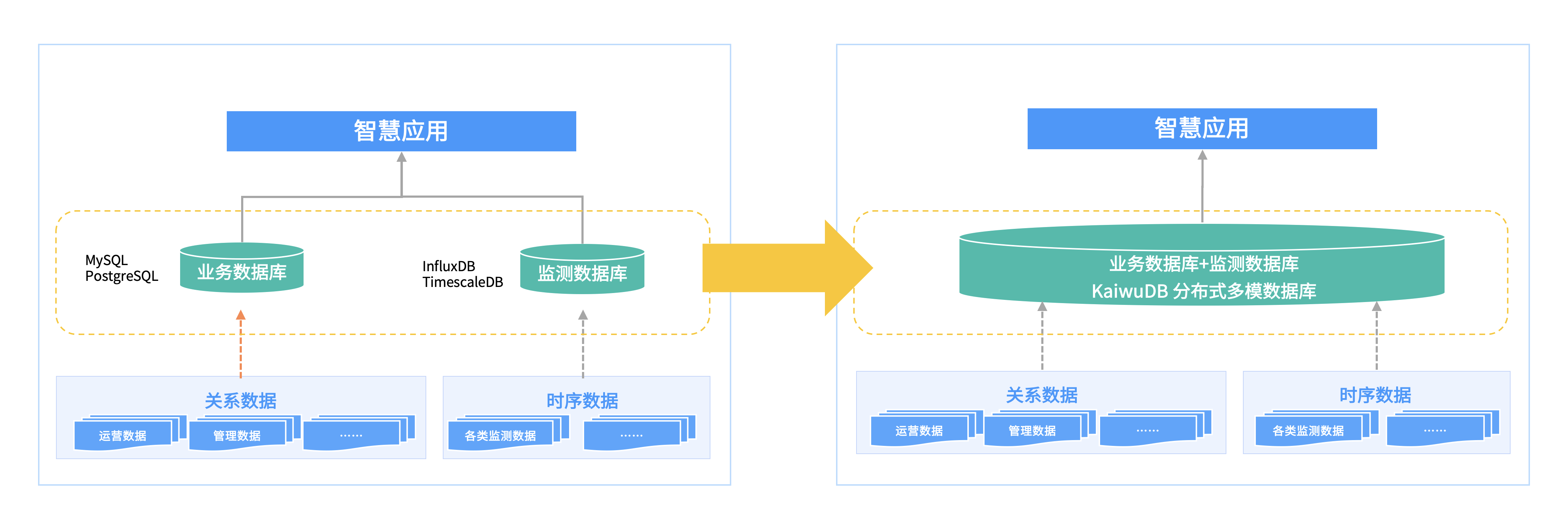
01 多模架构增强
KaiwuDB 多模架构通过单一数据库系统统一管理时序数据和关系数据 ,可简化技术架构,降低开发和运维复杂度及成本。V3.0 支持高效跨模连接算子 与时序算子并行处理,相较于 V2.2 跨模查询性能提升 5-10 倍,打破了不同数据模型间的壁垒,为物联网中多源异构数据的融合分析提供了可能。
![]()
多模架构,一库多用
02 时序性能增强
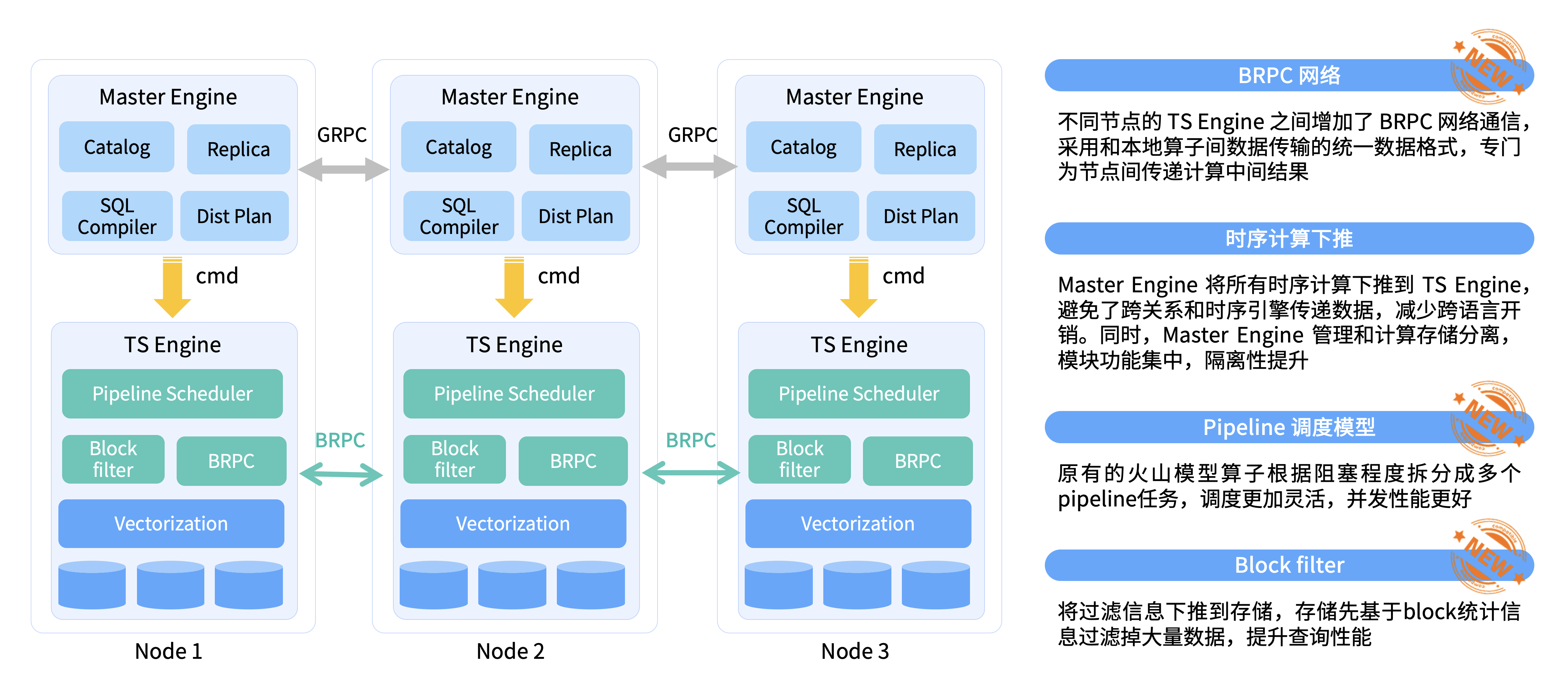
KaiwuDB V3.0 通过追加写的方式,充分发挥磁盘顺序写的高带宽特性。相较于 V2.2 ,KaiwuDB V3.0 单机写入性能提升 40%-216%,分布式写入性能提升 20%-50% 。智能计算下推 技术将时序算子全部下推至数据存储节点,避免了大量数据在网络中往返传输带来的延迟和带宽占用;同时内置读缓存 ,专门存储每张表的最新设备数据,帮助用户快速了解设备当前状态。相较于 V2.2 ,V3.0 平均查询性能提升 50%,最高提升 600%。
![]()
时序执行引擎优化
03 数据分发
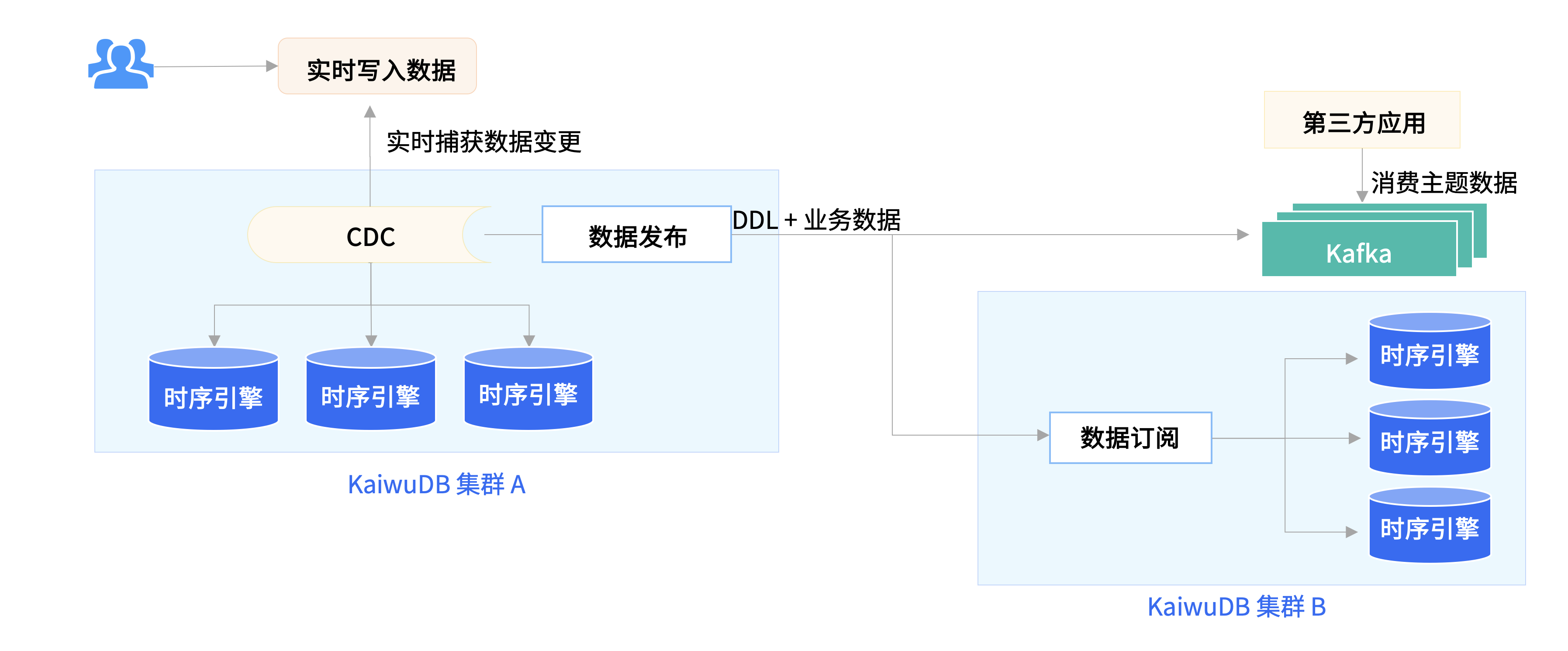
KaiwuDB 数据分发功能包含数据推送 和数据订阅发布 ,允许将一个库、一张表、甚至是特定条件下的数据发布至 Kafka 或另外一个 KaiwuDB 实例,实现细粒度的数据流转与同步。V3.0 的数据分发功能支持按需订阅、断点续传、元数据智能映射,可大幅降低系统资源消耗、提升实时决策能力,增强业务灵活性。
![]()
数据分发流程图
04 流计算
KaiwuDB 流计算功能使用变更数据捕获 (Change Data Capture, CDC) 机制实时捕获写入的时序数据,并使用 SQL 语句定义实时流变换。通过流计算,KaiwuDB V3.0 可实时捕获数据的细微变更,并迅速按照预先设定好的规则对数据进行预处理与分析,提升数据质量,节省存储计算资源,并支持秒级至毫秒级的业务决策。
![]() 流计算流程图
流计算流程图
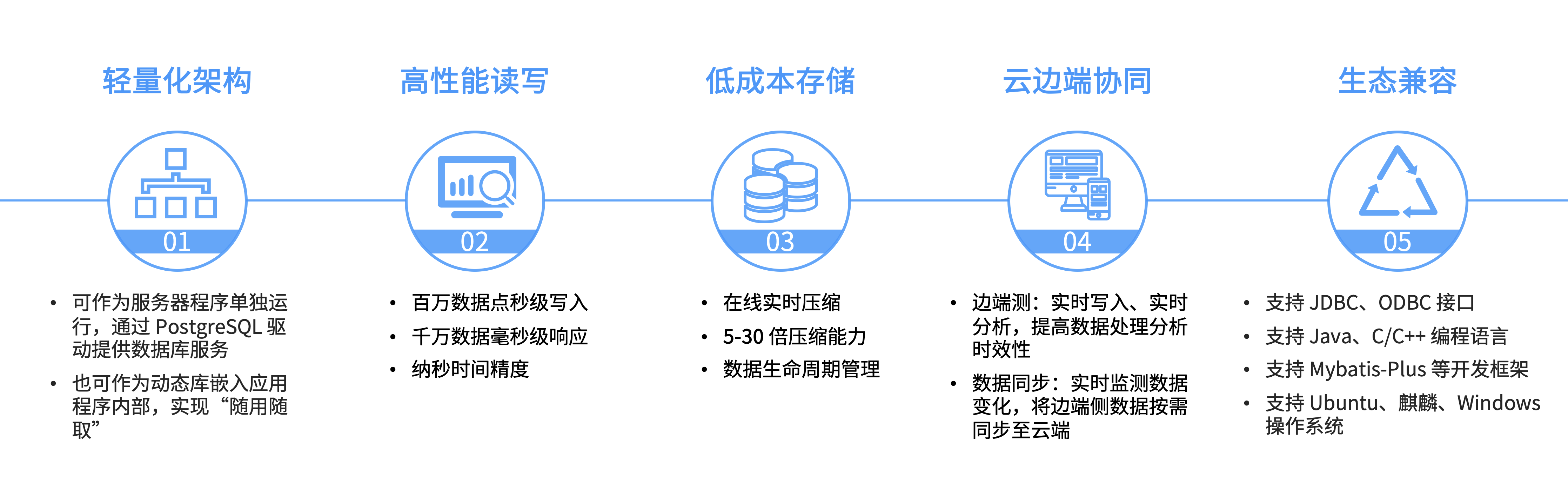
05 KaiwuDB Lite
KaiwuDB Lite 是一款专为边端物联网场景设计的轻量级时序数据库 。在低配资源下仍可实现百万数据点秒级写入、千万数据毫秒级响应、纳秒时间精度读写 等时序数据特色处理能力,适用于资源有限的边端设备、嵌入式系统、云边端协同等应用场景。
![]()
KaiwuDB Lite 功能特性
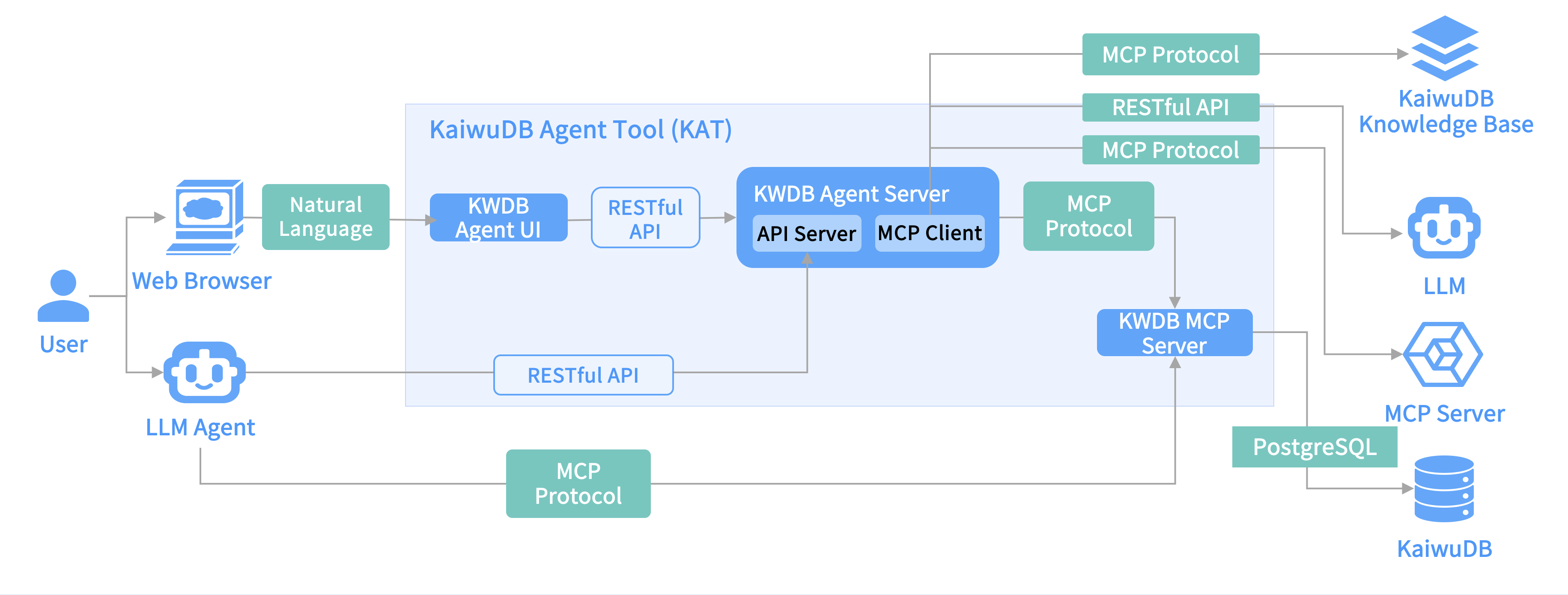
06 智能体工具 KAT
KAT (KaiwuDB Agent Tools ) 是基于 MCP (Model Context Protocol)协议构建的数据库智能体工具。KAT 将自然语言处理技术与 KaiwuDB 数据库的强大能力深度融合,用户通过简单的对话即可完成 KaiwuDB 安装部署、数据分析、未来预测等高级查询任务,获得直观易懂的结果,大幅降低数据库开发门槛。
![]()
KAT 架构图
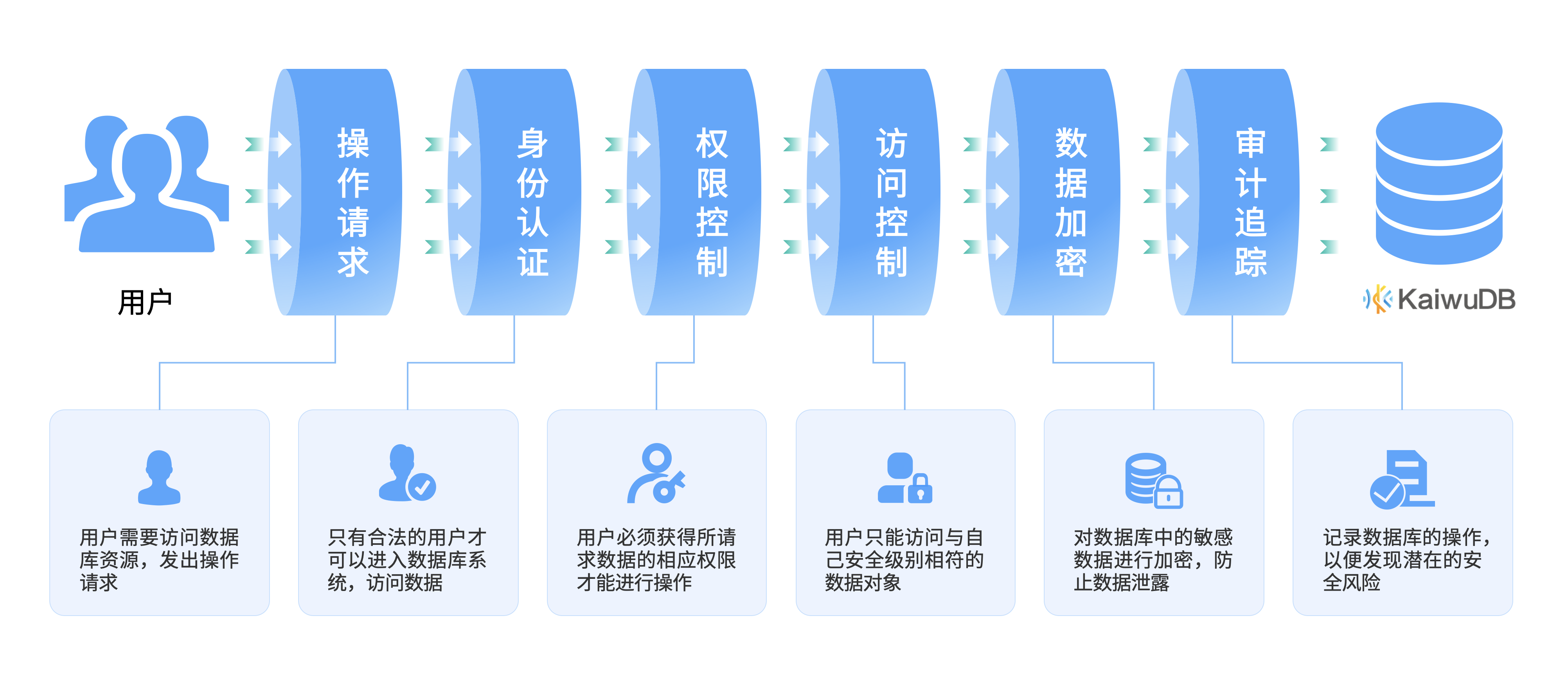
07 安全性能升级
KaiwuDB V3.0 在原有用户权限管理、三权分立、数据传输加密、数据存储加密、安全审计等特性基础上,新增强制访问控制、非透明存储加密、国密算法支持、GSSAPI 第三方认证 等多重安全机制。同时强化口令策略 及 SQL 防注入能力,全面提升数据库访问、存储与传输的安全性。
![]()
KaiwuDB 3.0 安全升级
强价值 | KaiwuDB V3.0 四大优势
KaiwuDB V3.0 凭借"简、优、智、省"四大核心优势,突破传统数据库瓶颈,以创新架构简化数据管理流程,以卓越性能和完备功能释放数据潜在价值,以智能技术实现高效运维与便捷交互,以成本优化为企业降本增效,持续拓宽物联网 AIoT 数字底座能力边界。
简
• 简架构 ------ 原创多模架构,无需在多个数据库之间切换和同步数据,一库应对物联网多模数据管理分析难题
• 简开发 ------从此告别传统数据开发的复杂代码编写、数据转换和接口对接等工作;让开发人员更专注于业务逻辑的实现,大幅提升开发效率
优
• 性能卓越 ------支持高并发场景下的数据高速读写和查询响应,性能达到行业第一梯队水准
• 功能完备 ------提供从数据的采集、存储、处理到分析的全生命周期数据管理服务
• 安全稳定 ------以可信、可控的高标准、严要求实现数据库高可用性和容错能力
智
• 可插拔 AI ------为用户提供强大的 AI 预测分析能力,支持对模型进行导入、训练、预测、评估、更换全流程操作
• 智能运维 ------通过自动化感知、分析与决策,化被动为主动,实现运维效率指数级提升
• 无 SQL 门槛 ------用户无需掌握复杂的 SQL 语法,让数据查询和分析像日常对话一样简单
省
• 通过简化开发流程和提供丰富的开发工具,大幅降低数据开发成本
• 以高速、卓越的系统性能充分保障业务快速稳健开展,业务效率 得以有效提升
• 一套数据库代替多套数据库,数据全生命周期管理服务缩减数据管理投入,大量节省企业运营成本
• 智能运维及智能体工具的加持,大大减少 DBA 学习成本与工作量
KaiwuDB V3.0 是浪潮在构建"物联数字基座"里程上的一步重要升级,更优地满足了物联网场景下大规模数据处理与管理的严苛需求。未来,KaiwuDB 将持续进化,为更多物联网企业的数字化转型提供有力支持,共同开创更加智能、高效、安全的数字未来。


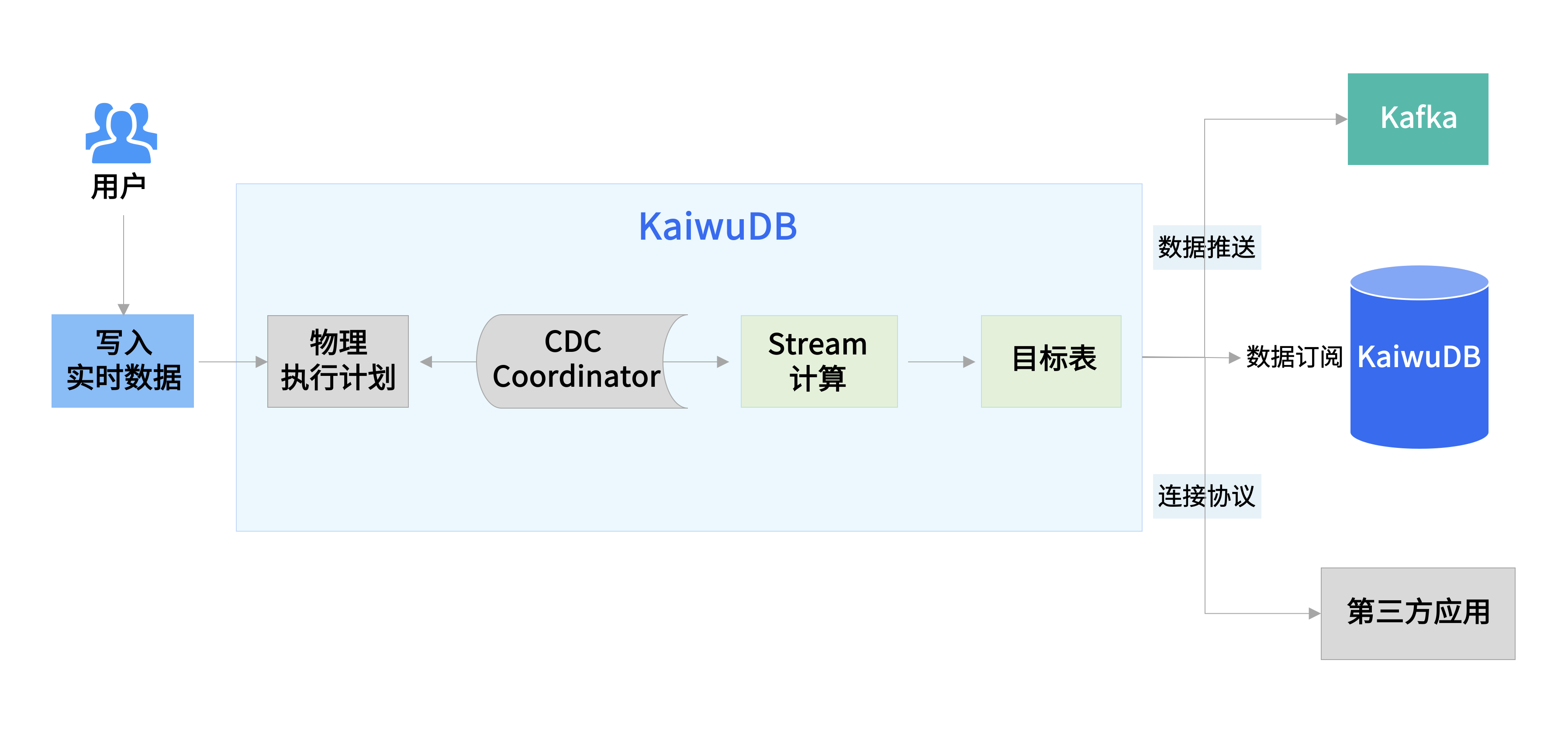 流计算流程图
流计算流程图