作者:vivo 互联网存储团队 - Lin Haiwen、Xu Xingbao
本文从一次生产环境业务服务报错,逐步对问题进行定位,深入分析之后发现导致问题的原因,给出相应的优化方法,提升业务可用性。
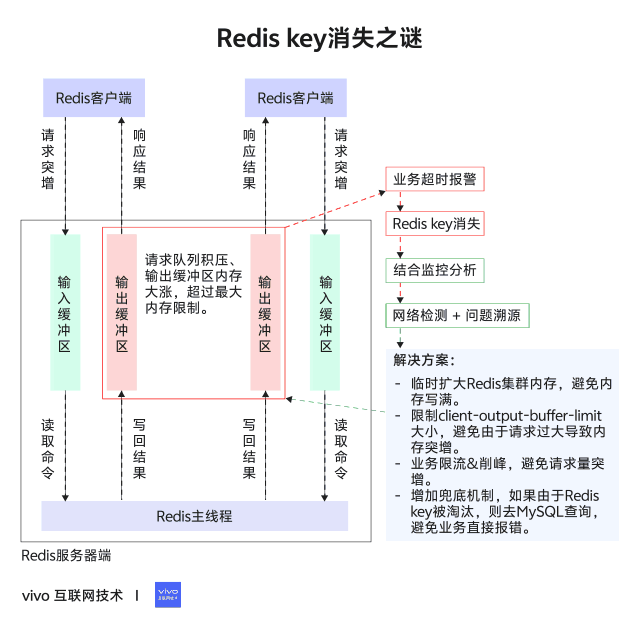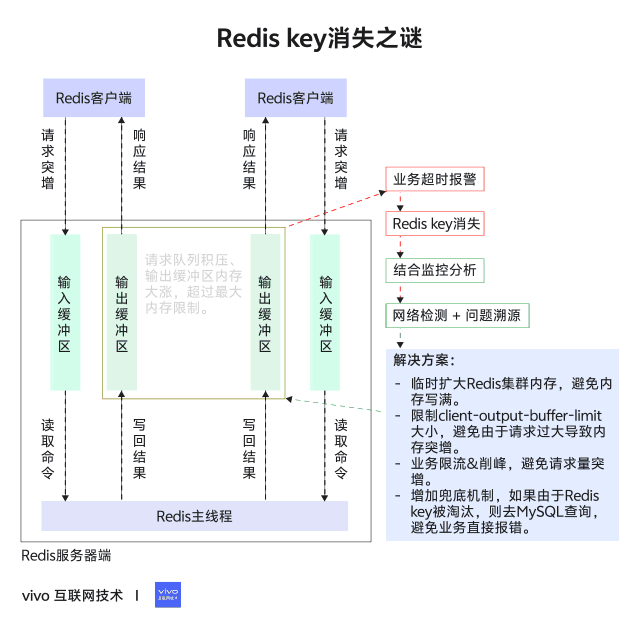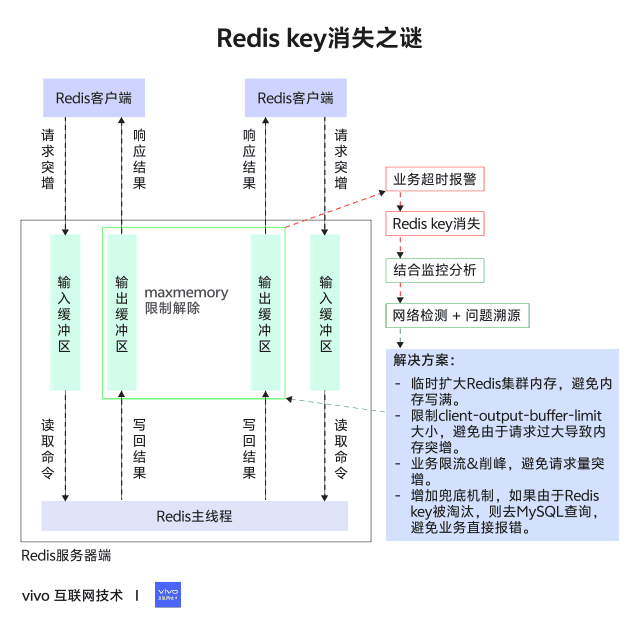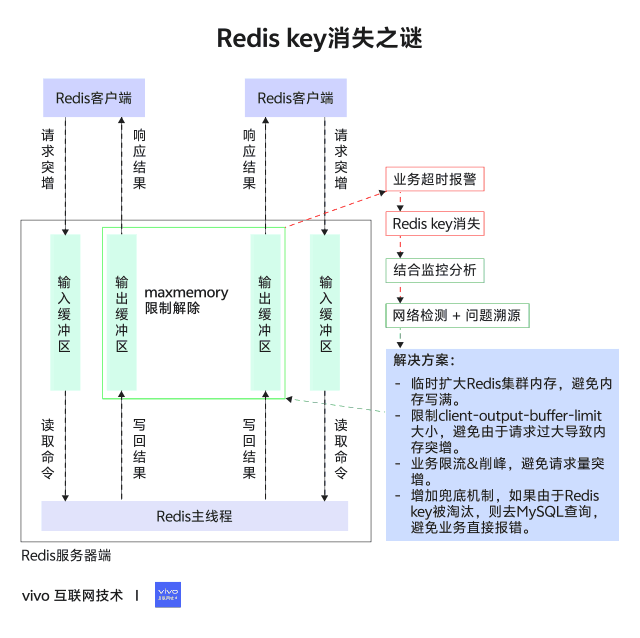
1分钟看图掌握核心观点👇
![图片]()
一、问题描述
1.1 报错信息
应用服务报错,通过监控日志发现凌晨2点的时候,应用报错获取不到Redis key。
1.2 告警与监控信息
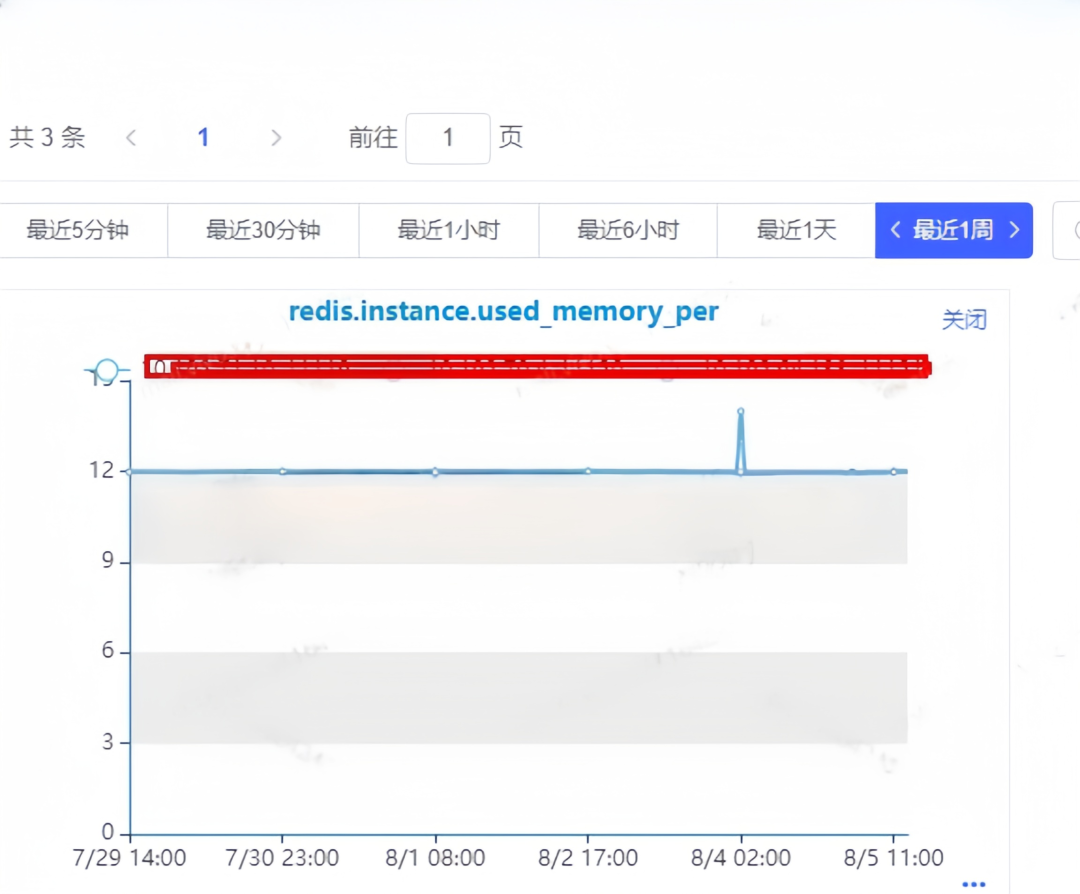
首先想到是否由于内存满导致的key淘汰,生产的所有Redis都有设置内存告警,但没有收到内存告警信息;(内存告警需要每隔10秒,连续3次触发才会告警。)
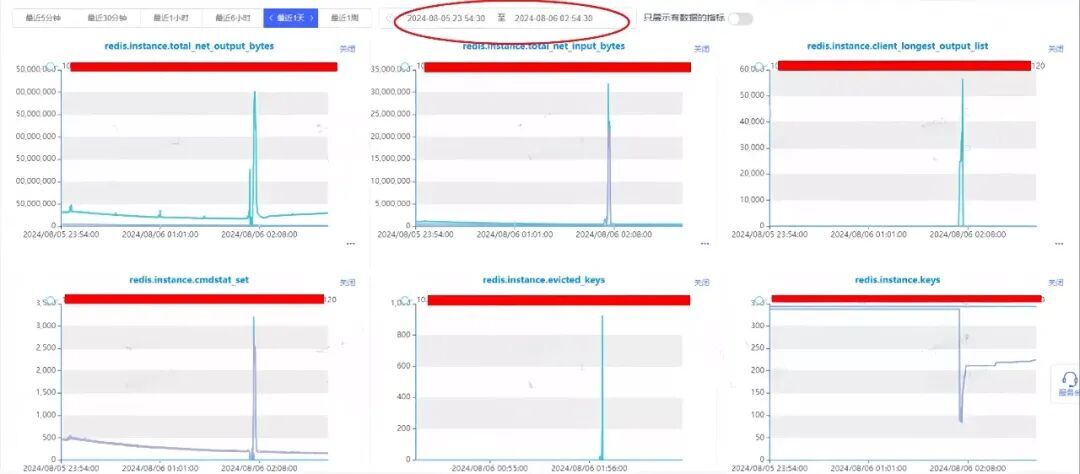
从监控图中,可以看到Redis内存稍有增长,但使用率一直偏低,并没有达到使用率告警。
![图片]()
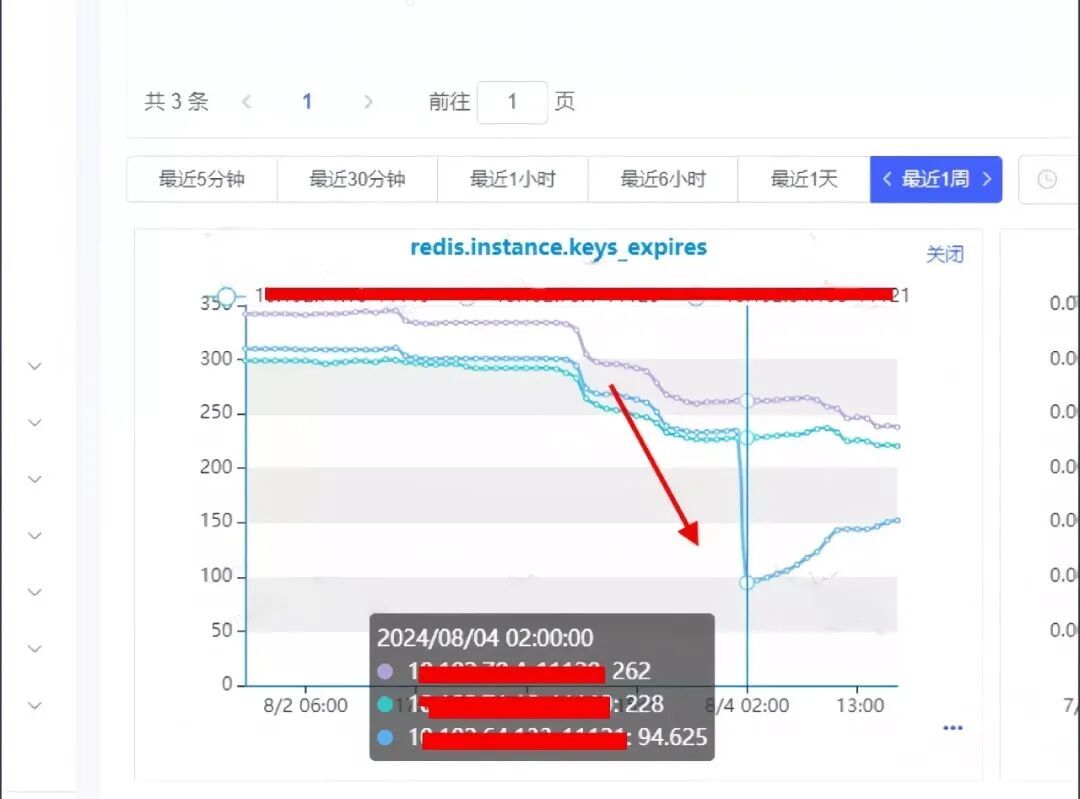
查看监控信息:在问题时间点,发生了大量的key过期,初步怀疑是由于key批量设置了过期时间,正好到期了导致大量key失效。
![图片]()
查看Redis错误日志,没有发现异常。
二、问题定位
但是业务反馈不是由于设置过期时间导致;并且第二天问题复现,因此继续深入定位。
2.1 key是否过期
初步判断确实不是因为key过期导致的大量淘汰,这里TTL接近5天,但是连着2天出现问题,因此不应该是过期时间到了导致。
xxx:xxx> config get'maxmemory-policy'
1)"maxmemory-policy"
2)"volatile-lru"
xxx:xxx> ttl finance:xxxx_cms_version_10000
-> Redirected to slot [9229] located at xxx:xxx
(integer)387585
xxx:xxx> ttl finance:xxxcms_basic_data_10423
(integer)387574
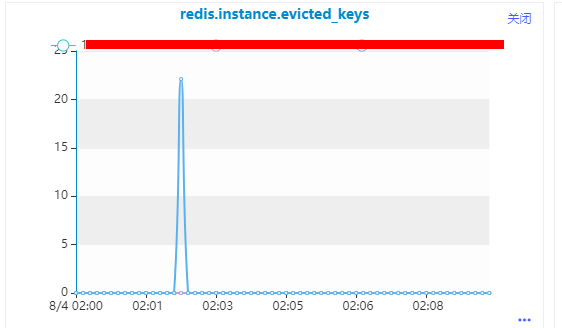
key是被删除还是淘汰?查看监控,发现存在key确实被淘汰,说明接下来需要考虑内存问题。
![图片]()
2.2 是否内存满了
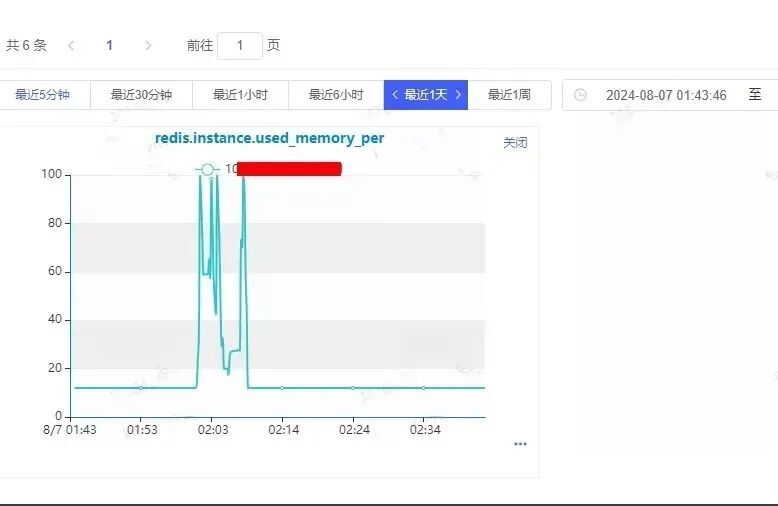
发现确实短时间内存写满了,一开始查看监控由于时间拉的比较长,查看增长趋势没发现内存写满情况,但是由于没有达到告警条件,没有满足连着3次触发阈值,故没有触发告警。
同时内存用满问题持续时间较短,约10分钟左右。
![图片]()
其他指标检查,发现出现问题时client_longest_output_list指标存在明显突刺,该指标非常可疑。
![图片]()
请求量的大涨,怀疑是请求堆积导致buffer增长使得内存写满。但是此时还有疑点:写入也上涨,是否是由于读请求积压导致,还是因为写入数据导致内存满?
2.3 找出内存涨的来源
设置定时任务,对出问题时间点前后20分钟这段时间进行抓包分析。
对比出问题前后几分钟的请求,对应时间点请求量飙升,并且请求量来源基本是get请求,set请求也少量增长。
4860 get finance:xxxx__10122
4925 get finance:xxxx__10032
4945set finance:xxxx_data_10013-0
4947 get finance:xxxx_data_10013_cms_version_10000
4976 get finance:xxxx__10251
5054set finance:xxxx__undefined
5098 get finance:xxxx__10018
8729 get finance:xxxx_data_10415_cms_version_10000
9152 get finance:xxxx_data_10401_cms_version_10000
9553 get finance:xxxx_data_10228_cms_version_10000
9597 get finance:xxxx_data_10213_cms_version_10000
9622 get finance:xxxx_data_10032_cms_version_10000
9647 get finance:xxxx_data_10347_cms_version_10000
9674 get finance:xxxx_data_10182_cms_version_10000
9742 get finance:xxxx_data_10251_cms_version_10000
10085 get finance:xxxx_data_10019_cms_version_10000
23064 get finance:xxxx__10423
45176 get finance:xxxx_data_10423_cms_version_10000
[root@db-prd-xxx.v-bj-3.vivo.lan:/data/redis/scpdir]
# cat 0807.cap | grep '2024-08-07 01:59'|awk '{print $8,$10}'|sort |uniq -c |sort -k 1 -n
同时也对set的内容进行分析,发现set的数据并不足使内存写满;且上面监控可以看到,内存写满问题持续时间很短,因此应该不是数据增长导致。
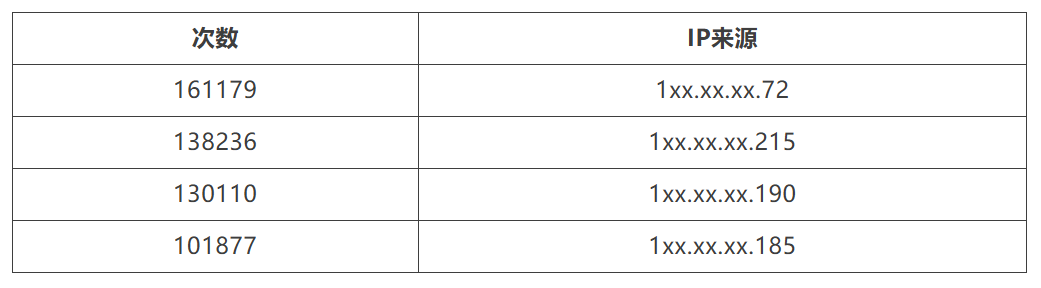
进一步对get请求来源分析:
![]()
结合 IP来源以及 keyname;跟业务同学沟通确认:
由于业务读请求量大涨导致,业务请求从每分钟27w左右上涨到70w左右,主要有:
![]()
2.4 机制分析
内存用量上涨超限会触发Redis节点基于已经配置的volatile-lru策略进行过期数据淘汰,所以需要找到内存上涨的来源。基于监控指标排查分析,基本确定了发生异常期间没有集中的大量数据写入,反而发现大量网络数据的输出,抓包也印证了此时节点主要是在处理get命令读请求。进一步地发现了client-output-buffer-limit这个指标出现异常上涨,才最终锁定到Redis的回包积压问题。
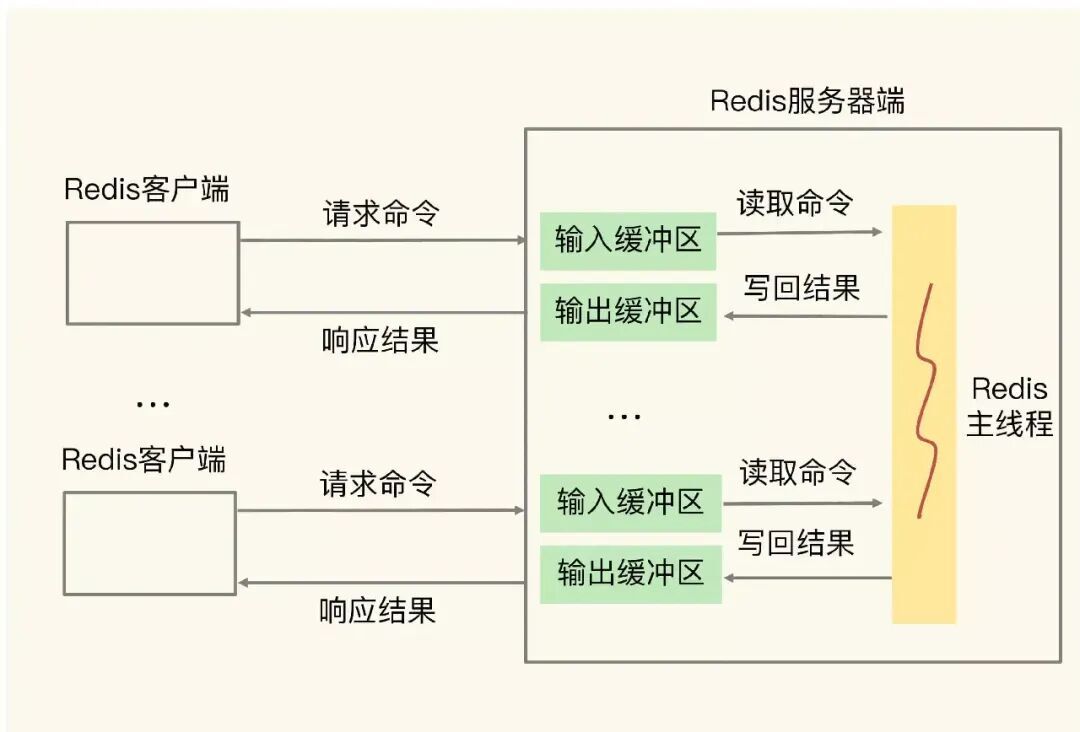
关于Redis的结果回包逻辑,首先要了解Redis的结果存储空间设计。Redis针对每一个连接客户端都会初始化一个大小为16K的静态的buf区域和一个空的链表结果,相关声明代码如下:
#define REDIS_REPLY_CHUNK_BYTES (16*1024) /* 16k output buffer */
char buf[REDIS_REPLY_CHUNK_BYTES];
list *reply;
c->reply = listCreate();
对于Redis而言正常执行的命令都会有数据回包,而回包结果都需要在客户端中做暂存。Redis是如何结合以上两个数据进行结果存储的呢?主要逻辑是如果静态buf区域能够满足回包结果存储,即结果不大于16k,那么结果就会存储静态buf中,将结果不断插入reply链表中;同时我们都知道Redis支持丰富的数据类型和操作命令,有些批量数据读取命令的结果可能会有很多字段,这些字段也会作为一个个链表元素追加到reply链表中。正常情况下,我们在Redis节点上执行info clients命令可以获得如下客户端的统计信息:
> info clients
# Clients
connected_clients: 1
client_longest_output_list: 0
client_biggest_input_buf: 0
blocked_clients:
其中的client_longest_output_list字段代表此时节点的所有连接客户端中回包结果的缓存情况。
但是按照之前服务监控和抓包结果分析,具体执行的指令都是get,实际数据也没有超过16k大小,并没有满足将结果存储到链表的条件。这里有个经常被忽略的场景,就是Redis其实支持pipeline命令执行方式的,简单来说就是Redis支持一次性接收一个客户端的多个指令,具体执行过程中会把这些指令的结果不断暂存,然后在后续流程中集中回包,如果这时候不能及时地把数据通过网络发出去,就有可能出现reply链表长度激增的现象,进而导致客户端占用内存激增,这正是我们本次遇到的场景。
![图片]()
Redis的maxmemory参数限制的是Redis实例可以使用的最大内存,这部分内存主要包括以下几个部分:业务数据占用的内存、客户端连接的输入/输出缓冲区、复制积压缓冲区、AOF 缓冲区以及其他一些内部开销。
具体来说,Redis 的maxmemory 限制包括:
-
业务数据占用的内存,这部分是用户在Redis中存储的数据。
-
客户端连接的输入/输出缓冲区,用于暂存客户端发送的命令和Redis 返回给客户端的数据。
-
复制积压缓冲区:用于主从复制,当从节点断线重连时,可以从这个缓冲区拉取丢失的数据。
-
AOF 缓冲区:用于持久化,当开启AOF 持久化时,Redis 会将写操作追加到AOF 缓冲区,然后异步地写入AOF 文件。
-
其他内部开销:包括Redis 进程本身的一些数据结构、对象、碎片内存等。
因此,在设置Redis 的maxmemory 参数时,需要综合考虑业务数据的内存占用、各个缓冲区的大小以及内存碎片率等因素,合理地分配内存,避免出现内存溢出或性能下降的问题。
三、问题解决
3.1 紧急修复
3.2 根本解决
业务进行业务逻辑优化,将请求打散,避免同一时间集中大量请求Redis。
四、总结
本次问题是由于业务集中请求Redis,导致缓存积压内存增长达到最大内存限制,触发Redis淘汰策略对key进行驱逐。key被淘汰丢失后,需要增加兜底机制去DB侧请求避免业务报错。虽然Redis性能比较好,但是也要尽量打散请求,合理评估存储侧的性能。
同时,对于Redis淘汰策略,对于数据比较重要的集群,可以考虑使用不驱逐的方式。合理设置TTL保留时间,把Redis的内存使用率保持在安全的区域。