SpreadJS 性能飙升秘籍:底层优化技术深度拆解
基础性能优化策略
SpreadJS 基础性能优化的核心在于通过挂起恢复机制减少不必要的计算与渲染开销。该机制主要分为三类实现方式,分别针对不同性能瓶颈场景提供解决方案。
减少重绘优化
此机制通过暂停视图渲染引擎,避免批量操作过程中的频繁界面更新。当执行大量单元格赋值时,可调用 suspendPaint() 方法阻止中间状态的绘制,完成后通过 resumePaint() 恢复渲染,从而将多次重绘合并为单次操作。
// 减少重绘示例
spread.suspendPaint();
for (let i = 0; i < 1000; i++) {
sheet.setValue(i, 0, `数据 ${i}`); // 批量赋值
}
spread.resumePaint(); // 恢复后一次性渲染
避免重复计算优化
针对公式密集型场景,通过 suspendCalcService() 暂停公式计算服务,在完成批量公式设置后调用 resumeCalcService() 触发一次性计算。此策略可有效避免公式依赖链的重复解析与计算,尤其适用于包含复杂函数的大型数据集。
// 避免重复计算示例
spread.suspendCalcService();
for (let i = 0; i < 500; i++) {
sheet.setFormula(i, 1, `SUM(A${i+1}:A${i+10})`); // 批量设置公式
}
spread.resumeCalcService(); // 恢复后统一计算
降低事件触发频率优化
通过 suspendEvent() 方法抑制事件系统,在高频操作(如数据导入、批量格式调整)期间阻止事件处理器的反复执行。操作完成后使用 resumeEvent() 恢复事件响应,可显著降低事件处理带来的性能损耗。
// 降低事件触发频率示例
spread.suspendEvent();
sheet.setArray(0, 0, largeDataset); // 导入大型数据集
sheet.setStyle(0, 0, 1000, 10, defaultStyle); // 批量设置样式
spread.resumeEvent(); // 恢复事件触发
组合挂起优化
在大规模数据处理时,可同时挂起渲染、计算与事件系统,实现性能最大化提升:
// 组合挂起示例
spread.suspendPaint();
spread.suspendCalcService();
spread.suspendEvent();
try {
// 执行批量操作(示例:填充10万行数据)
const data = Array.from({length: 100000}, (_, i) => [`行${i+1}`, i+1]);
sheet.setArray(0, 0, data);
} finally {
// 按相反顺序恢复
spread.resumeEvent();
spread.resumeCalcService();
spread.resumePaint();
}
适用场景总结
• 减少重绘:适用于批量单元格赋值、格式统一调整等视觉更新密集型操作
• 避免重复计算:推荐用于公式批量设置、数据模型重构等计算密集型场景
• 降低事件触发频率:优先应用于高频事件源(如滚动监听、数据导入)的性能优化
所有 API 调用均需确保成对出现,避免因挂起后未恢复导致的界面冻结或数据不一致问题。
导入文件配置优化
包含样式与未使用命名样式的处理
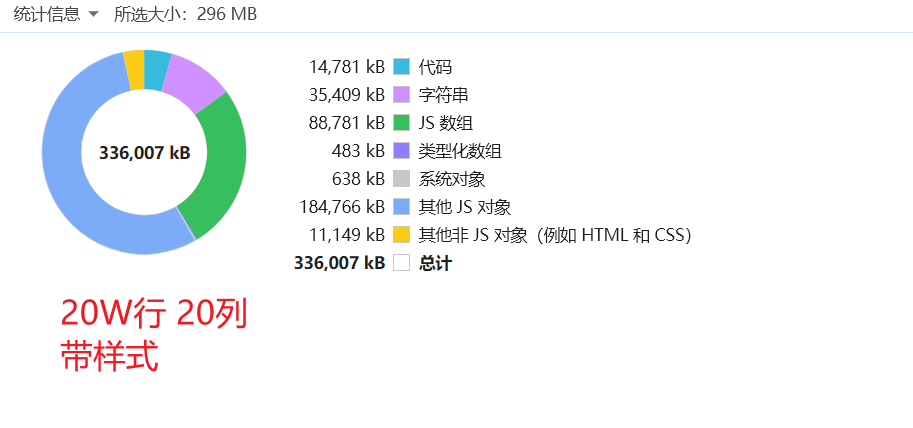
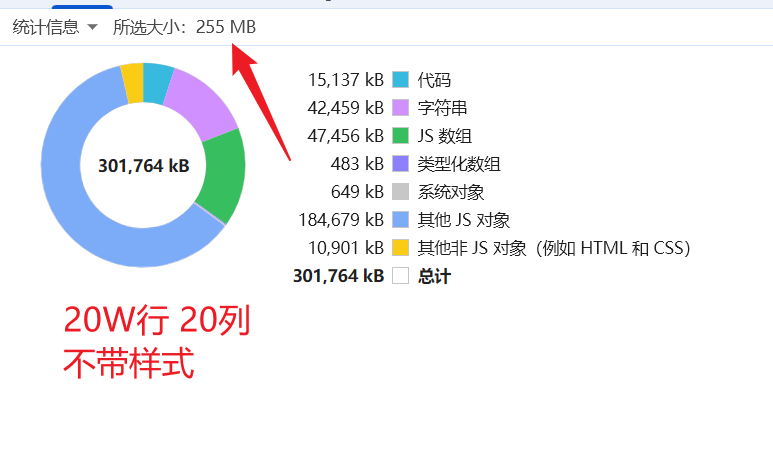
在 SpreadJS 表格性能优化中,样式处理是影响内存占用的关键因素。includeStyles 配置项直接决定是否加载文件中的样式定义,实验数据显示其对内存消耗有显著影响。 ![]()
![]()
// 样式导入配置示例
spread.import(blob,
() => console.log("导入成功"),
(error) => console.error("导入失败:", error),
{
includeStyles: false, // 不加载样式,降低内存占用
includeUnusedStyles: false // 忽略未使用的命名样式
}
);
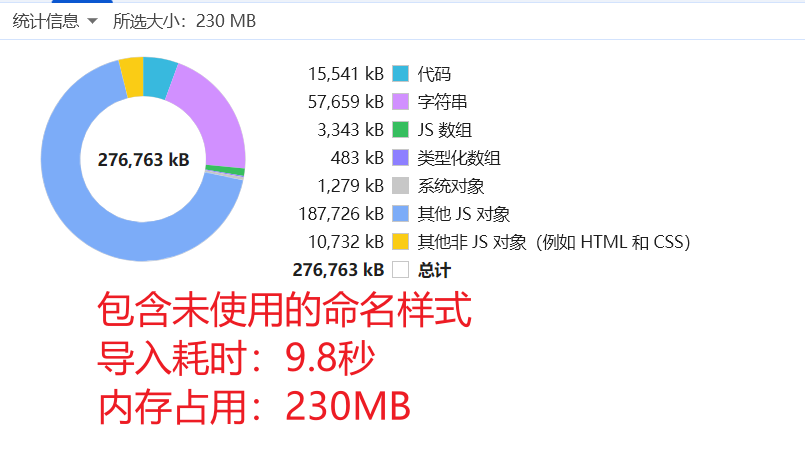
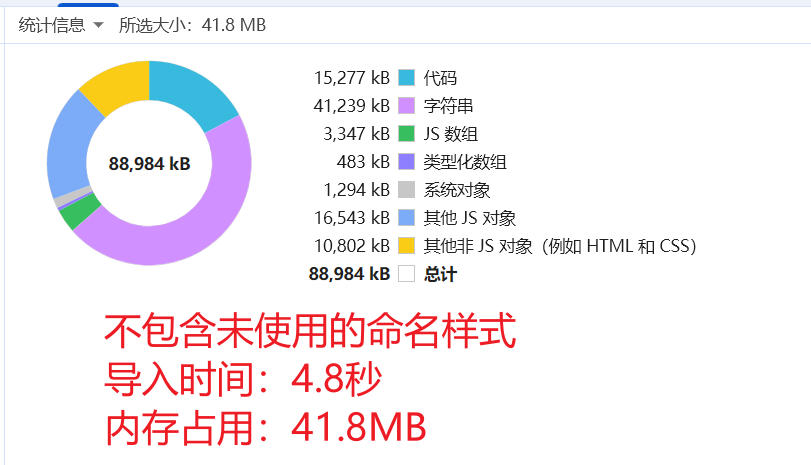
对于包含大量命名样式的文件,includeUnusedStyles 配置提供了针对性优化方案。当禁用未使用命名样式加载时,测试数据显示内存占用可控制在 41.8 MB,导入时间缩短至 4.8 秒。
![]()
![]()
懒加载模式应用
懒加载模式通过按需加载策略,仅在用户操作触发特定工作表访问请求时才加载目标工作表及其直接关联数据。
// 懒加载配置示例
spread.import(blob,
() => console.log("导入成功"),
(error) => console.error("导入失败:", error),
{
openMode: 'lazy' // 启用懒加载模式
}
);
关键技术特性:采用"引用驱动加载"模型,通过解析公式依赖链识别必要数据单元,实现跨工作表引用场景下的最小化数据加载,既保证计算准确性又避免冗余数据传输。
增量加载与进度显示
增量加载采用"数据优先、公式延后"的分层加载策略,优先渲染基础数据单元格内容,再异步加载计算公式。
// 增量加载配置示例
spread.import(blob,
() => console.log("导入成功"),
(error) => console.error("导入失败:", error),
{
openMode: 'incremental', // 启用增量加载
progress: (progress) => {
// 更新进度条
document.getElementById("progress-bar").style.width = `${progress}%`;
}
}
);
此机制不提升实际加载速度,而是通过重构加载时序优化感知体验,特别适用于单个大型工作表且包含大量公式的场景。
公式相关优化
增量计算机制
增量计算通过定期释放线程资源,解决公式计算时的界面假死问题:
// 启用增量计算
spread.options.enableIncrementalCalculation = true;
spread.options.incrementalCalculationMaxIterations = 100; // 设置最大迭代次数
spread.options.incrementalCalculationInterval = 20; // 设置释放线程的时间间隔(ms)
在包含 10 万行数据和多层级公式引用的财务报表场景中,启用增量计算后,用户编辑单元格的响应延迟从 800 毫秒降至 30 毫秒以内。
按需计算策略
按需计算仅在用到公式结果时才执行计算,减少无效计算开销:
// 启用按需计算
spread.options.calcOnDemand = true;
// 注意:易失函数场景下应禁用按需计算
// spread.options.calcOnDemand = false; // 处理易失函数时使用
核心优化逻辑:通过计算时机的精细化控制,将系统资源集中分配给实际需要的计算任务,从根本上避免全表扫描式的资源浪费,这一机制在数据密集型应用中可使计算效率提升30%以上。
动态数组公式应用
动态数组公式分为结果扩展型(如FILTER、SORT)和聚合计算型(如SUMPRODUCT)两类:
// 动态数组公式示例 - FILTER函数
sheet.setValue(0, 0, "产品");
sheet.setValue(0, 1, "价格");
// 填充示例数据
sheet.setArray(1, 0, [
["商品A", 80], ["商品B", 120], ["商品C", 150],
["商品D", 90], ["商品E", 200]
]);
// 筛选价格大于100的产品
sheet.setFormula(0, 3, 'FILTER(A2:B6, B2:B6>100)');
// 动态数组公式示例 - SORT函数
sheet.setFormula(0, 5, 'SORT(A2:B6, 2, false)'); // 按价格降序排序
与传统数组公式相比,动态数组公式通过一次输入完成整列数据计算,系统自动分配结果区域,减少重复计算次数。
Lambda公式的优势与应用
Lambda公式允许用户创建自定义、可重用函数:
// 定义Lambda公式(通过单元格输入)
sheet.setFormula(0, 0, 'LAMBDA(fullName, LEFT(fullName, FIND(" ", fullName)-1))("张三 工程师")');
// 命名Lambda公式(通过API)
spread.addCustomName("GetFirstName", 'LAMBDA(fullName, LEFT(fullName, FIND(" ", fullName)-1))', 0, 0);
sheet.setFormula(1, 0, 'GetFirstName("李四 设计师")'); // 调用自定义Lambda函数
Lambda公式可导出到xlsx,并被Excel、WPS等桌面软件识别,终端用户可直接创建,无需研发人员介入。
其他性能优化要点
条件格式的合理使用
条件格式的性能优化关键在于精简规则设计和规避易失函数:
// 优化的条件格式配置示例
const conditionalFormat = new GC.Spread.Sheets.ConditionalFormatting.NormalConditionRule();
conditionalFormat.ruleType(GC.Spread.Sheets.ConditionalFormatting.RuleType.cellValueRule);
conditionalFormat.compareType(GC.Spread.Sheets.ConditionalFormatting.ComparisonOperators.greaterThan);
conditionalFormat.value1(100);
conditionalFormat.style({backColor: "red"});
// 应用于特定区域而非整个工作表
sheet.conditionalFormats.addRule(conditionalFormat, "B2:B10000"); // 限制应用范围
正确配置原则:
- 合并相邻区域规则,使用相对引用替代绝对引用
- 避免使用 TODAY()、RAND() 等易失性函数
- 限制条件格式应用范围,避免全表规则
大数据量处理策略
传统的单元格级操作方法在处理大数据时存在性能瓶颈,推荐使用数据绑定技术:
// 大数据量处理示例 - 传统方法(性能较差)
// for (let i = 0; i < 100000; i++) {
// sheet.setValue(i, 0, `行${i+1}`);
// sheet.setValue(i, 1, i+1);
// }
// 大数据量处理示例 - 数据绑定(性能优化)
const dataSource = Array.from({length: 100000}, (_, i) => ({
名称: `行${i+1}`,
值: i+1
}));
// 设置数据绑定
sheet.setDataSource(dataSource);
// 绑定列
sheet.setBindingPath(0, 0, "名称");
sheet.setBindingPath(0, 1, "值");
数据绑定技术通过直接从数据源抽取原始值并批量映射至表格区域,跳过中间数据节点创建环节,使数据加载速度得到数量级提升。
总结
在实际应用 SpreadJS 进行性能优化时,需根据具体业务需求、数据规模、用户交互模式综合评估并选择优化组合方案。各类优化策略(如虚拟滚动、数据绑定模式选择、公式计算优化等)均有其特定的优势与局限性,并非在所有场景下都能产生同等效果。
关键原则:性能优化需以业务目标为导向,避免盲目套用技术方案。在实施过程中,应通过基准测试量化优化效果,优先解决核心性能瓶颈,并在用户体验与系统资源消耗之间寻求平衡。
通过合理配置与动态调整优化策略,才能最大限度发挥 SpreadJS 的性能潜力,满足不同业务场景的需求。
扩展链接
文章配套仓库Gitee地址
可嵌入您系统的在线Excel