上海人工智能实验室与浙江大学等机构近日联合推出IWR-Bench,这是首个专门评估大语言模型将视频转化为交互式网页代码能力的基准测试。该基准旨在更真实地衡量多模态大语言模型(LVLM)在动态网页重建方面的能力,填补了AI前端开发领域动态交互评测的空白。
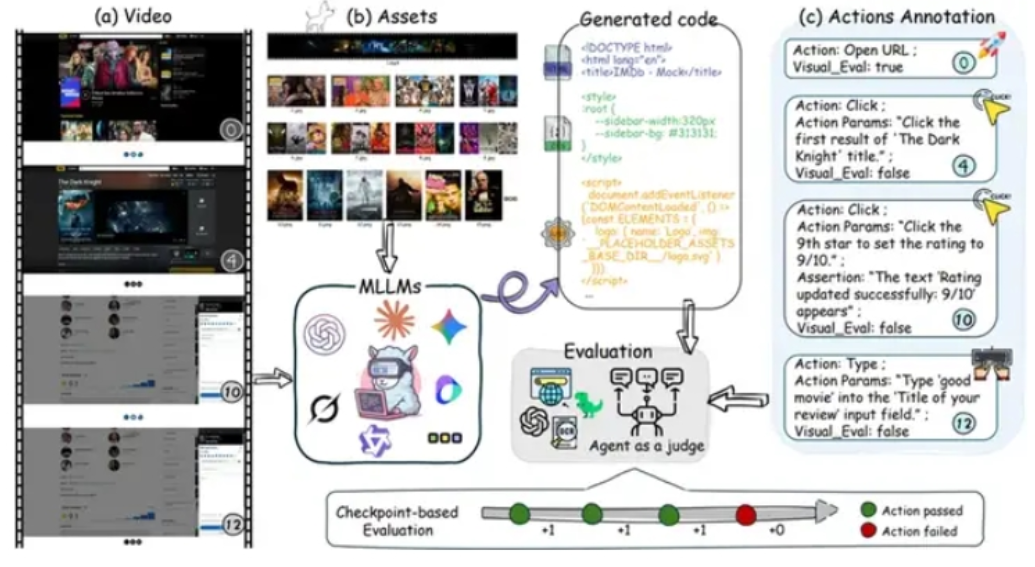
与传统的图像转代码(Image-to-Code)任务不同,IWR-Bench要求模型观看记录用户完整操作流程的视频,结合网页所需的所有静态资源,重建网页的动态交互行为。任务复杂度涵盖从简单的网页浏览到复杂的游戏规则重建,包括2048游戏、机票预订等多种应用场景。
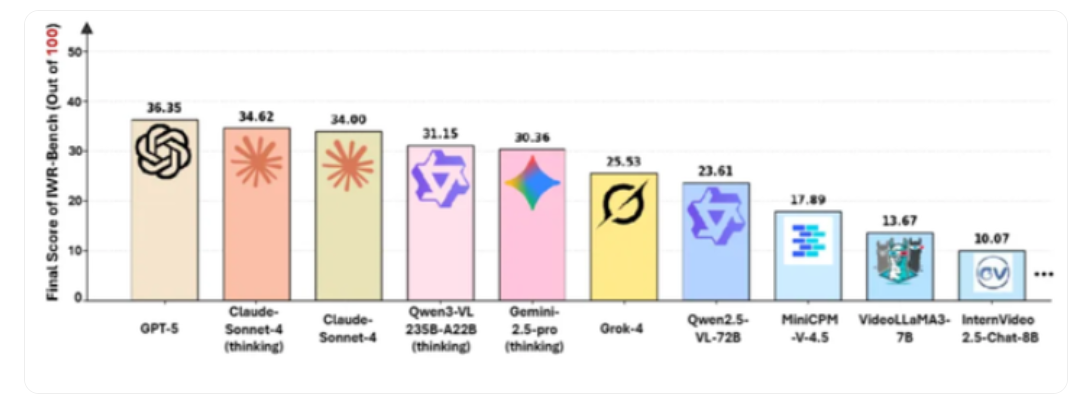
测试结果显示了当前AI模型在这一任务上的显著局限。在对28个主流模型的评测中,表现最好的GPT-5综合得分仅为36.35分,其中交互功能正确性(IFS)得分为24.39%,视觉保真度(VFS)得分为64.25%。这一数据清晰反映出模型在视觉还原方面相对较强,但在实现事件驱动逻辑和动态交互功能方面存在明显短板。
![]()
从评测方法来看,IWR-Bench不仅关注模型的视觉还原能力,还通过自动化代理评估其交互功能的正确性。每个任务都提供完整的静态资源,且所有文件名经过匿名化处理,迫使模型依靠视觉匹配而非语义推理来关联资源。这种设计更贴近真实开发场景,要求模型理解操作视频中的因果关系和状态变化,然后将其转化为可执行的代码逻辑。
研究人员还发现了一些有趣的现象。带有"思考"机制的模型版本在某些任务中表现更好,但提升幅度有限,表明基础模型的能力仍是决定性因素。此外,专门针对视频理解优化的模型在该任务中的表现并不如通用多模态模型,说明视频转网页任务与传统视频理解任务存在本质差异——前者需要的不仅是理解视频内容,更需要将动态行为抽象为程序逻辑。
![]()
从技术挑战来看,视频转网页任务的难点在于多个层面。首先是时序理解,模型需要从连续的视频帧中提取关键交互事件和状态转换。其次是逻辑抽象,需要将观察到的行为模式转化为事件监听、状态管理等编程概念。第三是资源匹配,在匿名化的静态资源中准确找到对应的图片、样式等文件。第四是代码生成,需要产生结构合理、逻辑正确的HTML、CSS和JavaScript代码。
GPT-5仅获得36.35分的综合得分,说明即使是最先进的多模态模型,在将动态行为转化为可执行代码这一任务上仍有很大提升空间。24.39%的交互功能正确率意味着模型生成的网页中,超过四分之三的交互功能存在问题。这可能包括事件响应不正确、状态管理错误、业务逻辑遗漏等问题。
![]()
IWR-Bench的推出对AI研究和应用都有重要意义。从研究角度看,它为多模态模型的动态理解和代码生成能力提供了新的评测维度,有助于识别当前技术的薄弱环节。从应用角度看,视频转网页能力如果成熟,可以大幅降低前端开发的门槛,让非技术人员通过演示操作就能生成功能原型。
不过需要注意的是,即使模型在该基准上取得高分,距离实际应用仍有距离。真实的网页开发涉及性能优化、兼容性处理、安全防护、可维护性等多个维度,这些都难以通过视频演示来完全传达。此外,复杂的业务逻辑、边缘情况处理和用户体验细节,也很难仅从操作视频中完全推断出来。
从行业趋势来看,IWR-Bench代表了AI代码生成从静态向动态、从单帧向多帧、从描述向演示的演进方向。这与当前AI编码助手主要依赖文本描述的模式形成对比,为"所见即所得"的智能开发工具提供了技术基础。如果未来模型在该任务上取得突破,可能催生新一代的原型开发工具,让产品经理或设计师通过录制操作视频就能生成可交互的网页原型。
从测试结果来看,当前AI模型在理解复杂动态交互方面仍处于早期阶段。视觉保真度64.25%相对较高,说明模型已经能够较好地还原页面的静态外观。但交互功能正确性仅24.39%,表明将观察到的行为转化为正确的程序逻辑仍是巨大挑战。