导读
上海证券引入 SelectDB 作为核心实时分析引擎,有效弥补了实时数据处理与分析的能力短板,实现湖仓一体与流批一体,同时替换了原架构中的 Elasticsearch 组件。达成了写入性能提升 4 倍,支撑 1000+ QPS 高并发访问,关键决策响应速度 200 ms,开发效率提升 50%,运维成本大幅降低的关键收益。
业务背景
上海证券成立于 2001 年 5 月,秉承“开放、包容、规范、协同”的核心理念,致力于成为“特色鲜明、区域领先、品牌知名”具有专业特色的财富管理型券商。近年来,上海证券资产规模持续扩大,经营实力不断增强,取得了显著的社会效益和经济效益。
与此同时,数据基础设施的建设也需进一步深化,以应对持续增长的业务规模带来的挑战。上海证券原先基于 Hadoop 体系建设数据平台,面临着三重挑战:
![上海证券_doris_业务背景.PNG]()
- 架构孤岛化: 当前架构为烟囱式数据架构,存在多套独立的数据采集、调度工具,协同效率低下。
- 标准体系缺失: 缺乏统一数据标准规范,全流程质量管控依赖技术部门强驱动。
- 服务能力断层: 缺少“水到田头”的数据服务,业务部门无法自助快速获取数据,决策响应延迟较长。
为应对上述挑战,上海证券计划构建全栈信创数据中台,以同时满足以下三方面核心需求:
- 技术需求:全面升级数据平台基础设施,实现国产化与技术自主掌控,打造集数据治理、开发、分析、应用于一体的一站式平台。原有架构中,缺少实时数据处理与分析能力,需要引入相关产品,实现湖仓一体与流批一体能力,突破实时分析瓶颈。
- 业务需求: 全面支撑实时与离线计算、结构化与非结构化数据分析,赋能公司各业务线数字化转型。
- 效率与成本需求: 全面整合公司数据资源,有效降低总体数据成本,显著提升数据开发效率。通过选择适配的产品组合,以最优路径完成数据中台的构建。
基于 SelectDB 的数据中台方案
面对上述需求,上海证券于 2024 年 2 月正式完成基于 SelectDB 的数据中台基础搭建,10 月实现全量业务迁移,目前处于深度应用期。
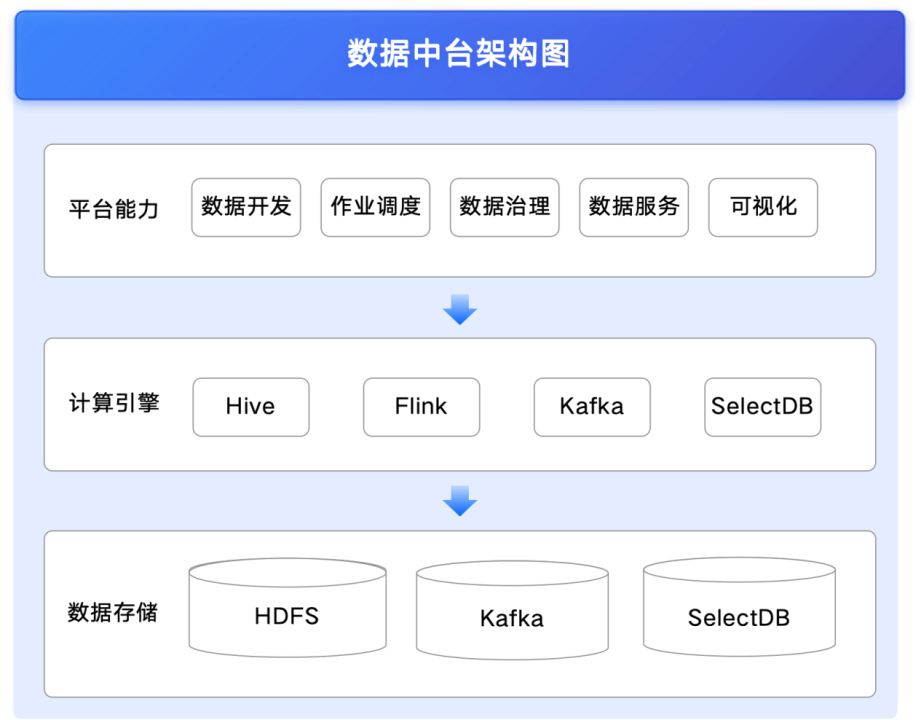
01 整体架构方案
![基于 SelectDB 的数据中台方案.PNG]()
为平衡成本与效率,上海证券在基础架构设计中保留了大部分现有 Hadoop 组件,引入 SelectDB 作为核心实时分析引擎的同时,替换了 Elasticsearch。SelectDB 的引入有效弥补了原架构中实时数据处理与分析的能力短板,成为上海证券实现湖仓一体与流批一体的关键技术支撑。
- 全面支持 Hadoop 生态,实现湖仓一体: SelectDB 能够无缝对接并高效访问上海证券现有 Hadoop 体系中的 HDFS 存储和 Hive 元数据,最大程度地复用已有数据资产。同时 SelectDB 提供高性能实时分析能力,统一支撑上海证券结构化与非结构化数据的分析需求。
- 构建数据治理、开发、服务一体化平台: 上海证券基于 SelectDB 构建的新平台整合了数据治理规范、统一开发流程和自助数据服务能力,解决了原有架构标准缺失、流程割裂的问题,实现了从数据入湖到业务应用的全生命周期一体化管理。
- 通过统一数据开发平台,实现流批一体: 利用 SelectDB 强大的实时写入与批量处理能力,实现了流式数据和批量数据的统一加工、存储与分析,成功突破了原有架构的实时分析瓶颈,赋能业务快速决策。
- 全栈国产化兼容: SelectDB 在核心引擎、周边生态及部署环境上实现了全面国产化兼容,满足了证券公司对数据平台基础设施国产化与技术自主掌控的关键需求,保障了系统安全可控。
- 服务团队支持力度高,运维有保障: SelectDB 背后专业服务团队的高效响应和有力支持,为上海证券在平台建设、迁移上线和后期运维的全过程提供了可靠保障,有效降低技术风险,确保平台稳定运行。
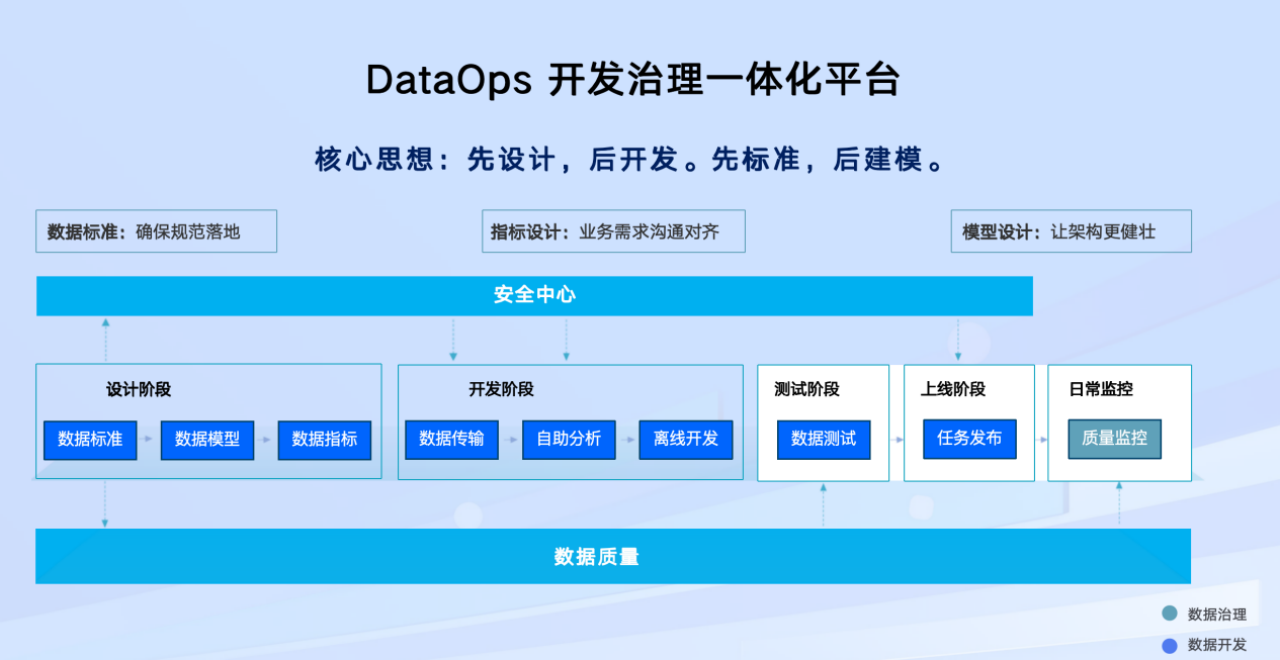
02 DataOps 开发治理一体化
![02 DataOps 开发治理一体化.PNG]()
上海证券以“先设计,后开发;先标准,后建模”为核心原则,结合全信创数据中台,构建数据全生命周期闭环管理体系(图片来源于网络):
- 设计阶段: 通过统一数据标准、与业务对齐的指标设计及健壮模型设计,从源头保障数据规范性与质量。
- 开发阶段: 依托 SelectDB 高效计算能力,无缝集成数据传输、离线开发与自助分析任务,支撑流批一体数据处理。
- 测试及上线阶段: 通过严格的数据测试、质量监控及任务发布流程,结合 SelectDB 的实时监控能力,确保数据可靠入湖并持续稳定运行。
上海证券始终保障数据合规,形成了“设计-开发-测试-监控”的一体化治理体系,基于 SelectDB 彻底解决了原有架构标准缺失、流程割裂的问题,赋能业务自助获取高质量数据。
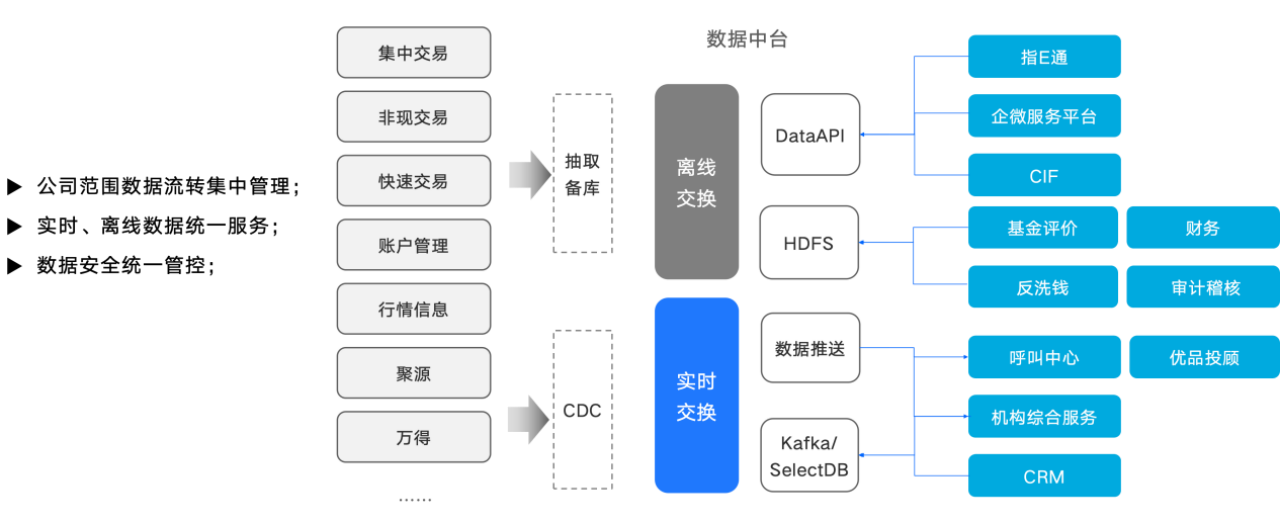
03 统一数据交换链路
![03 统一数据交换链路.png]()
上海证券通过构建统一数据交换平台,打通了公司级数据流转链路。 平台集中管理实时与离线数据服务,并实施统一安全管控,将分散的行情(万得/聚源)、交易(非现/快速)、账户等中台数据与下游业务系统(指 E 通全微服务、CRM、反洗钱等 20+ 模块)高效连接。尤其是对于实时场景,基于 SelectDB Routine Load 能力便捷接入 Kafka 数据,其高并发数据更新吞吐可达到百万行每秒,为行情推送、机构服务等提供了秒级延迟的数据服务能力。
应用场景
01 金融实时交易战报
2024 年 9 月 底,证券市场行情迅猛爆发,上海证券新增能够秒级获取全量交易、行情、新客开户数及资金引入等数据的需求。基于 SelectDB 的极速性能,上海证券相关团队在 10 月前开发并上线了实时交易战报系统,业务数据秒级实时接入,系统稳定支撑 1000+ QPS 高并发查询,复杂聚合查询响应延迟低至 200ms,实现了对全量经营指标的实时决策支持,验证了 SelectDB 在突发业务场景下的高性能与高可靠性,为金融行业实时数仓建设提供了关键支撑。
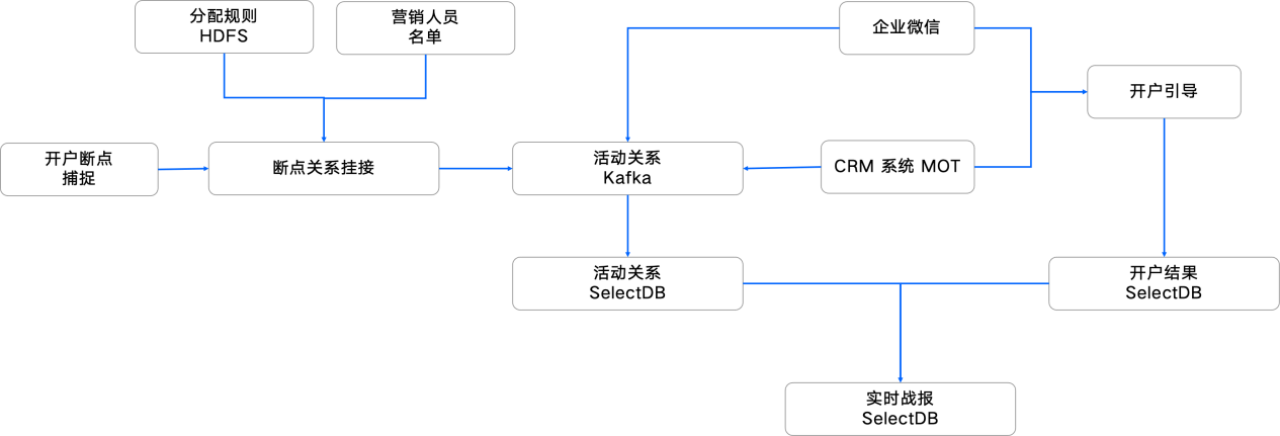
02 金融 CRM 系统建设——替换 Elasticsearch
![02 金融 CRM 系统建设——替换 Elasticsearch.png]()
上海证券在其金融 CRM 活动关系及实时战报模块原先采用 Elasticsearch 组件,因其存在两大核心缺陷:
- 数据同步延迟高: ES 批量数据同步延迟高达分钟级,客户行为数据无法实时更新,导致决策滞后。
- 运维成本高昂: ES 架构复杂,需独立维护协调节点、数据节点、主节点,集群维护困难,故障排查耗时长,导致运维成本高昂。
为此,上海证券进行了系统升级,在开户结果分析中引入了 SelectDB,并在活动关系及实时战报模块中使用 SelectDB 替换原 Elasticsearch 组件,作为实时分析引擎,实现流批一体架构。SelectDB 的写入吞吐能力是 Elasticsearch 的 4 倍,有效解决了数据同步延迟高的痛点。升级后,系统能够直接消费 Kafka 客户行为流,将数据同步时效压缩至秒级。同时,借助 SelectDB 倒排索引能力及丰富的运维生态,复杂查询响应速度提升了 2 倍,整体运维成本大幅降低。
SelectDB 的引入使得上海证券金融 CRM 系统实现了秒级实时闭环,系统能够实时获取客户开户流程中的断点情况,通过持续分析客户操作流,精准识别如资料提交中断等关键断点事件,并实时生成 MOT 任务,推送至客户经理移动端。这使得客户经理能够及时触达客户,引导续接开户流程,将断点问题解决时效提升至分钟级别。
应用收益
上海证券通过引入 SelectDB 构建数据平台,有效解决了原 Hadoop 与 Elasticsearch 架构的关键瓶颈,在性能、成本等方面实现显著突破:
- 突破实时分析瓶颈,分析效率跃升: 基于 SelectDB 直接消费 Kafka 客户行为流,写入性能提升 4 倍,数据同步延迟压缩至秒级,解决 Elasticsearch 同步效率低导致的决策滞后问题。借助 SelectDB 倒排索引能力及复杂聚合查询能力,支撑 1000+ QPS 高并发访问,关键决策响应延迟低至 200 ms,响应效率翻倍;
- 湖仓 & 流批一体架构,有效降低成本: 基于 SelectDB 的数据平台可直接访问 HDFS/Hive 数据,实现湖仓一体,复用现有存储资源,降低迁移成本。此外,SelectDB 精简的架构设计和丰富的运维生态,可同时处理流式与批量数据,避免多套系统协作开销,大幅简化集群管理,数据开发效率提升 50%,运维成本大幅降低。