豆包超越 DeepSeek,夺 8 月中国原生 AI App 月活第一
QuestMobile最新发布的2025年8月数据显示,豆包月活跃用户规模超越DeepSeek,登顶中国原生AI App月活榜首。 2025年8月,豆包月活跃用户规模达15742万,环比增长6.6%,从第二名升至第一名。曾居首位的DeepSeek,8月用户规模虽仍处亿级,但因-4.0%的环比增速,排名下滑1位。 其他选手表现各异,腾讯元宝以22.4%的高环比增速,稳坐第三,月活规模处于1000万-1亿量级。
北京深度逻辑智能科技有限公司宣布于近日推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。
“旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。”
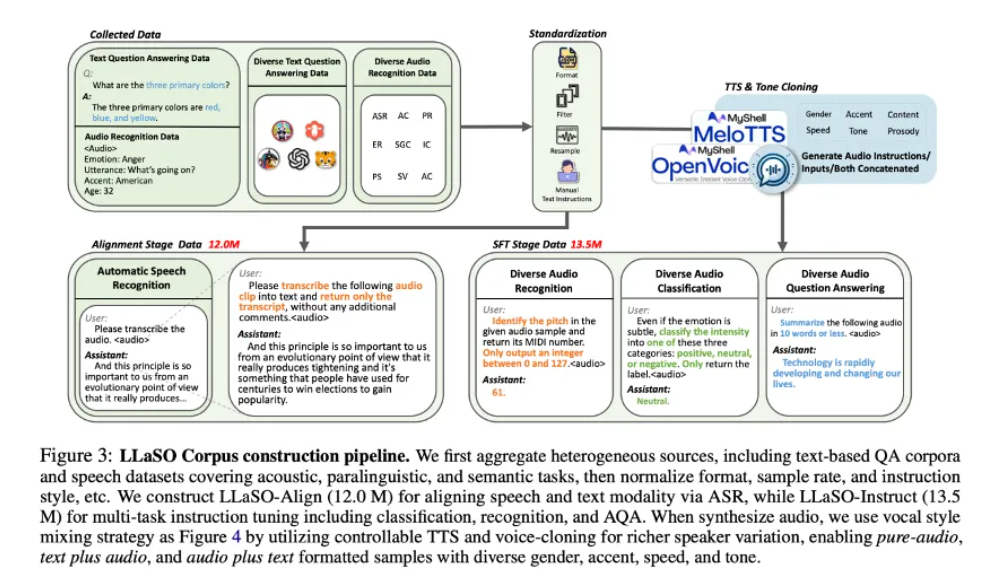
LLaSO 框架包括三个核心开源组件:
LLaSO-Align:大规模语音 - 文本对齐数据集
LLaSO-Instruct:多任务指令微调数据集
模态支持:系统性支持三种交互配置
LLaSO-Eval:标准化评估基准
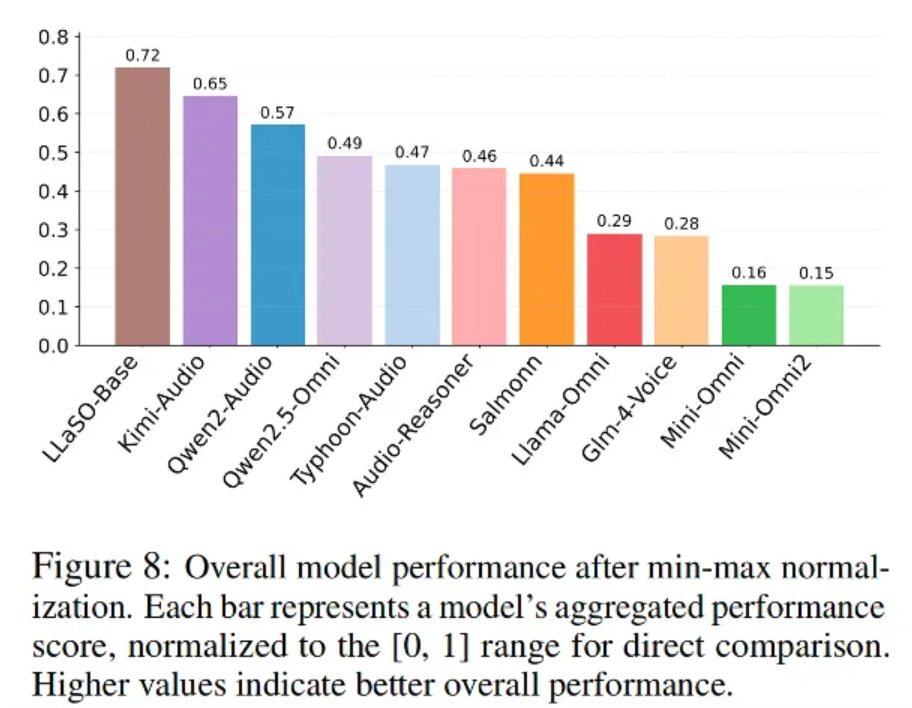
为验证框架有效性,逻辑智能团队基于 LLaSO 数据训练了 38 亿参数的参考模型 LLaSO-Base。实验结果表明,LLaSO-Base 以 0.72 的得分在所有参评模型中排名首位,相较于排名第二的 Kimi-Audio (0.65) 和第三位的 Qwen2-Audio (0.57) 展现出明显的性能优势。该结果充分验证了 LLaSO-Base 模型的整体效能。
进一步分析发现,采用多任务训练范式的模型(如 LLaSO-Base)在综合评测中的表现明显优于专门针对特定任务(如 AQA)进行定向优化的模型(例如 Llama-Omni 和 Mini-Omni)。这一现象印证了多样化任务训练策略在提升模型泛化能力方面的重要价值。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273