导语
本文分析了在网络超时场景下,RPC服务调用数据一致性的问题,对于接口无幂等、接口幂等失效情况下,对异常数据快速处理做了分析思考和尝试,开发了一款轻量级仿幂等数据校正处理辅助工具。该工具可以MOCK或SPY服务调用,不限于RPC接口,进程内的方法调用也支持,与JSF、WebService、HTTP方式无关,只要方法能被代理,就可以使用,写服务、读服务均可以支持。目前已在生产环境中使用,在关键时刻可以发挥相应的作用。本文工具并不重要,重要的是与大家一起探讨一些解决方案,给大家提供一种思路。如果小伙伴有类似诉求,也欢迎大家合适的场景下接入使用。
由来
最近在参与系统的故障与处理恢复专题,我脑海中衍生了一个关于数据校正处理(或称之为修数,或数据处理)相关的一个idea,可以在一些场景下发挥重要作用。
本文的重点不是探讨故障与处理恢复措施,比如三板斧、三把刀,而是将我脑海中的这个idea场景剖开,打算设计和开发一款对应的数据处理提效工具,落地到相应场景中去使用。
场景分析
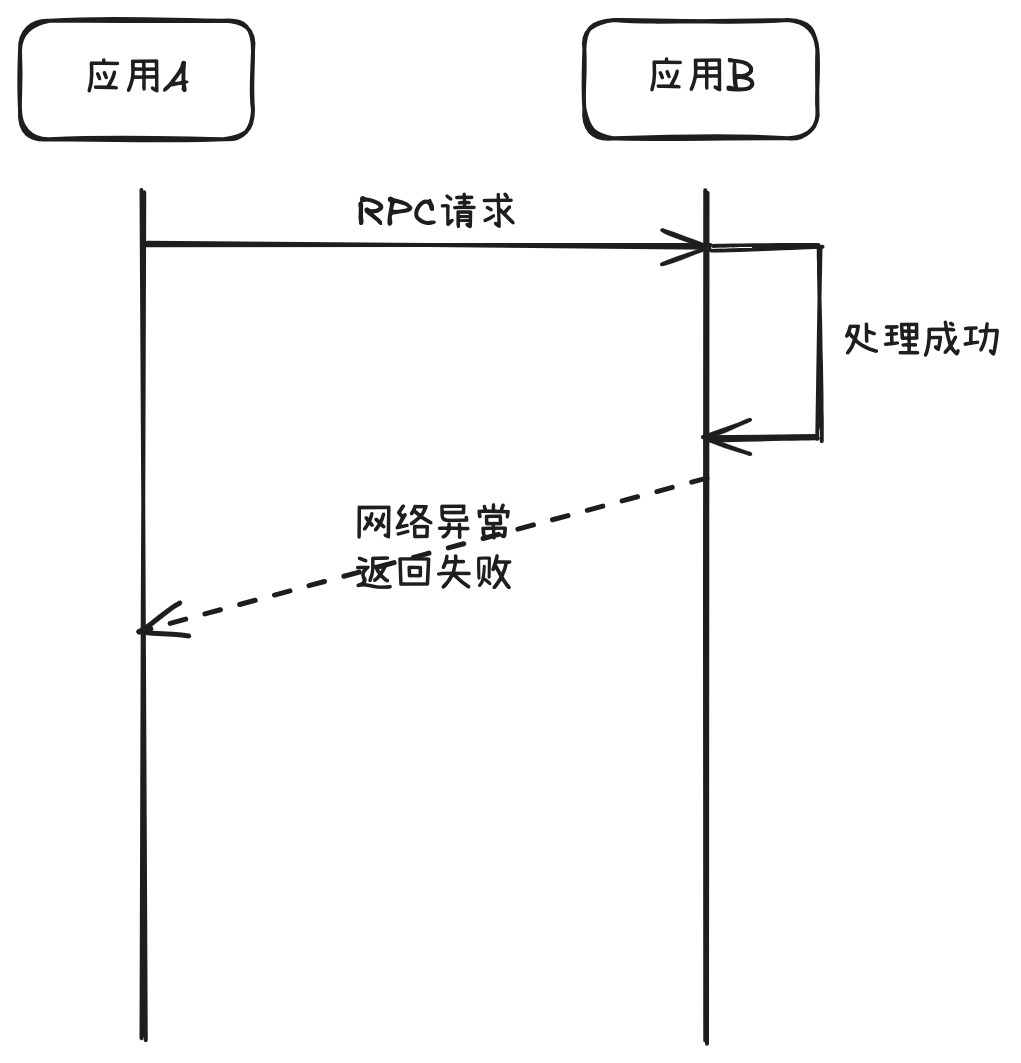
在分布式架构中,应用之间的网络通信,简单说存在三种状态:成功、失败、超时,简称为网络三态。
成功:请求成功发送并且得到正确的响应。
失败:请求发送失败或收到的响应表示操作失败。
超时:请求在指定时间内没有收到响应。
对于成功而言,可以正常响应处理。
对于失败而言,可以进行数据回退、重试补偿等手段。
对于成功、失败这两种状态而言,结果都是明确的,在分布式数据一致性处理上也相对比较简单。
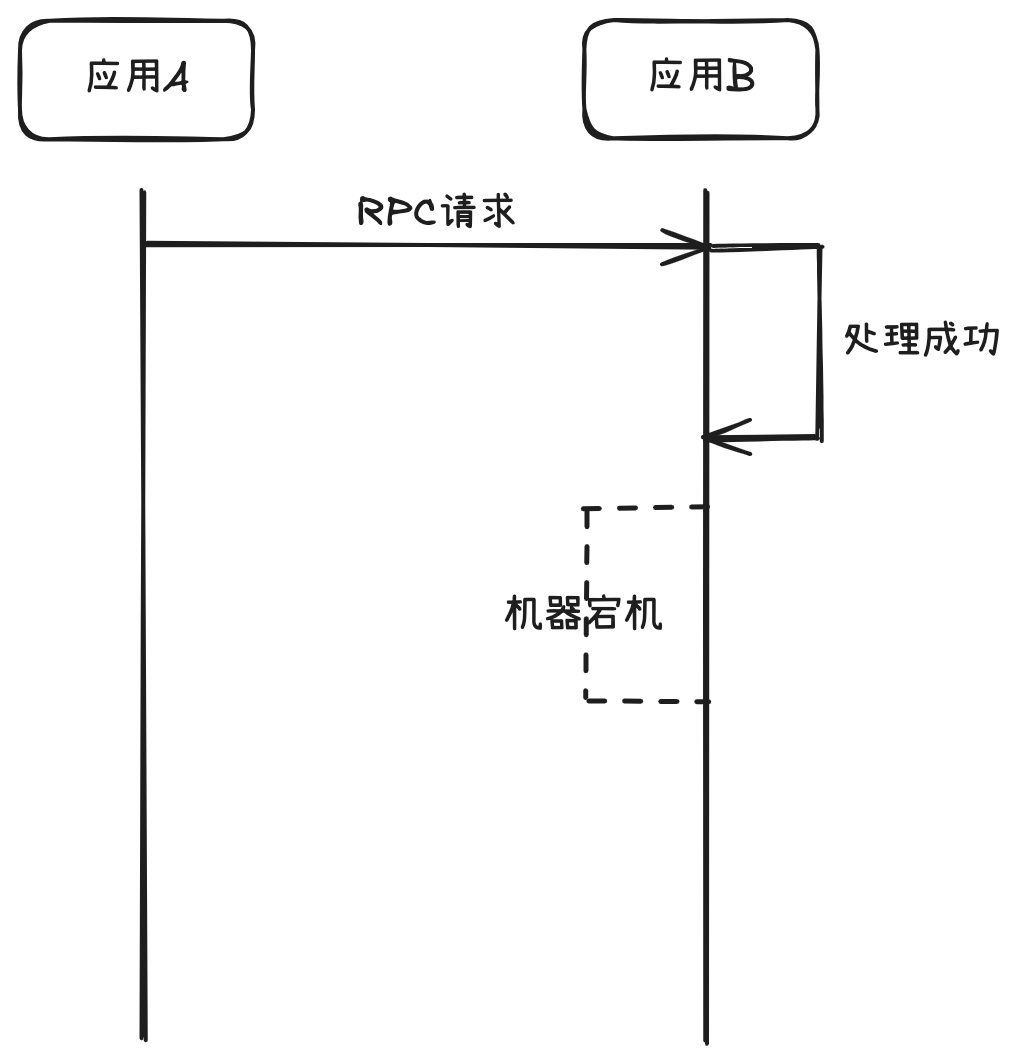
对于超时而言,调用方感知的是超时,服务提供方处理的时间超出预期时间,但服务提供方最终是否执行成功,不得而知。有可能执行失败,也有可能最终处理成功并落库,只是未能响应给调用方。
在超时情况下,即使调用方再感知超时后,回退自身数据后,同时尝试回退服务提供方的数据时,大概率也是回退失败,因为此时服务提供方尚未执行完成,数据尚未落库完成。如果说delay一段时间后,再去回退服务提供方的数据,倒是可行,但delay多长时间,回退多少次才能成功,都不确定,对调用方来说,也增加了复杂性和运维难度。
假如服务调用是同一个线程中的本地调用,访问同一个数据库实例,则可以直接使用数据库事务来保障一致性。
如果是分布式调用,可以采取分布式事务措施,例如2PC、3PC、TCC、Saga事务等方式来保障一致性,市面上也有成熟的分布式事务中间件可以使用,例如Seata解决方案。
上面说到分布式事务只是顺着话题延伸了一下,本文重点不是探讨分布式事务的解决方案,况且很多京东系统,并没有接入分布式事务解决方案,本文重点思考在超时场景下,有没有一些手段或工具可以帮助快速数据一致性处理、故障恢复。
思考
超时也许是由于网络抖动,或者服务器负载过高造成的服务超时,也有可能是程序性能不佳造成的持续超时。最终的数据处理和恢复方向,都是要让数据在应用之间得以流动落地,才能使整个链路的流程走下去,即要保障应用间数据的最终一致性。
如果服务可以降级,则降级是比较快速的一个恢复手段。
如果服务不可降级,则通过重试补偿等手段来恢复数据的一致性。
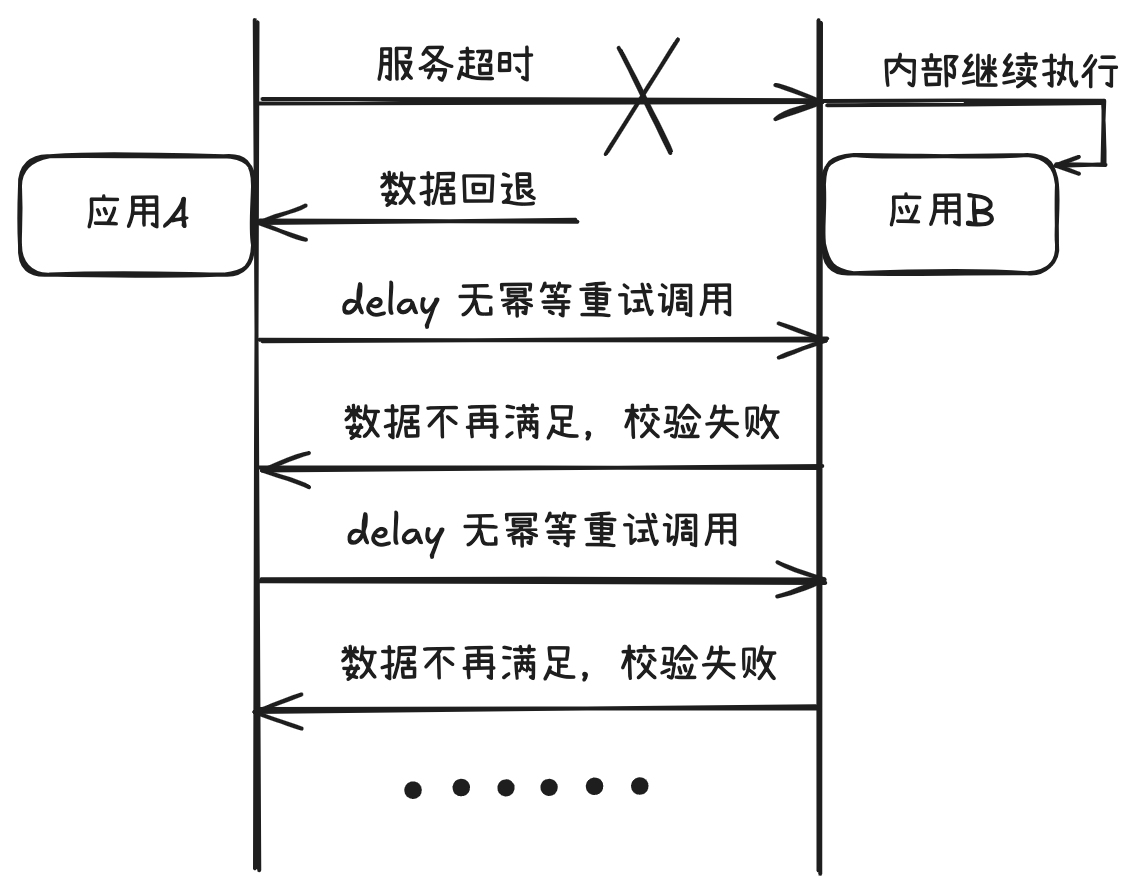
RPC服务重试,调用方、服务提供方需要保障接口的幂等性才能保证重试无副作用。
何为幂等性?幂等是一次和多次请求某一个资源对于资源本身应该具有同样的结果,换言之,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
接口的幂等性,需要调用方和服务提供方相互配合才行,倘若服务提供方提供的接口支持幂等性,双方按照约定接口入参中的uuid作为唯一序列号进行防重,但服务提供方每次的重试调用(无论上次调用成功与否)uuid都会改变,这就会使得幂等失效。
如果接口没有实现幂等性,或者由于调用方每次必变uuid导致幂等失效,在这种情况下,该如何快速恢复数据呢?
如上图所示,由于服务超时后,应用B内部仍在持续执行,此时恢复手段是:人工介入,梳理数据后,人工将应用B的数据进行回退,或者人工将应用A的数据进行补齐推动流程向后走,人工保证A和B之间的数据一致性。倘若应用A、B背后的流程比较长,涉及的表关系比较复杂,数据量比较大,这时候人工就难以处理了,也容易出错,造成二次伤害。
之前还遇到过一种情况,服务提供方和调用方都支持幂等,但由于一些原因,调用方很久之前的一个异步任务失败了,而调用方用于幂等防重的数据归档了。当时为了支持幂等重试,从归档库里拉回了相应的流水数据到生产库,才重试调用成功,费力费力,效率低。
思路
这里持续探索无幂等或幂等失效场景下的重试能力建设。
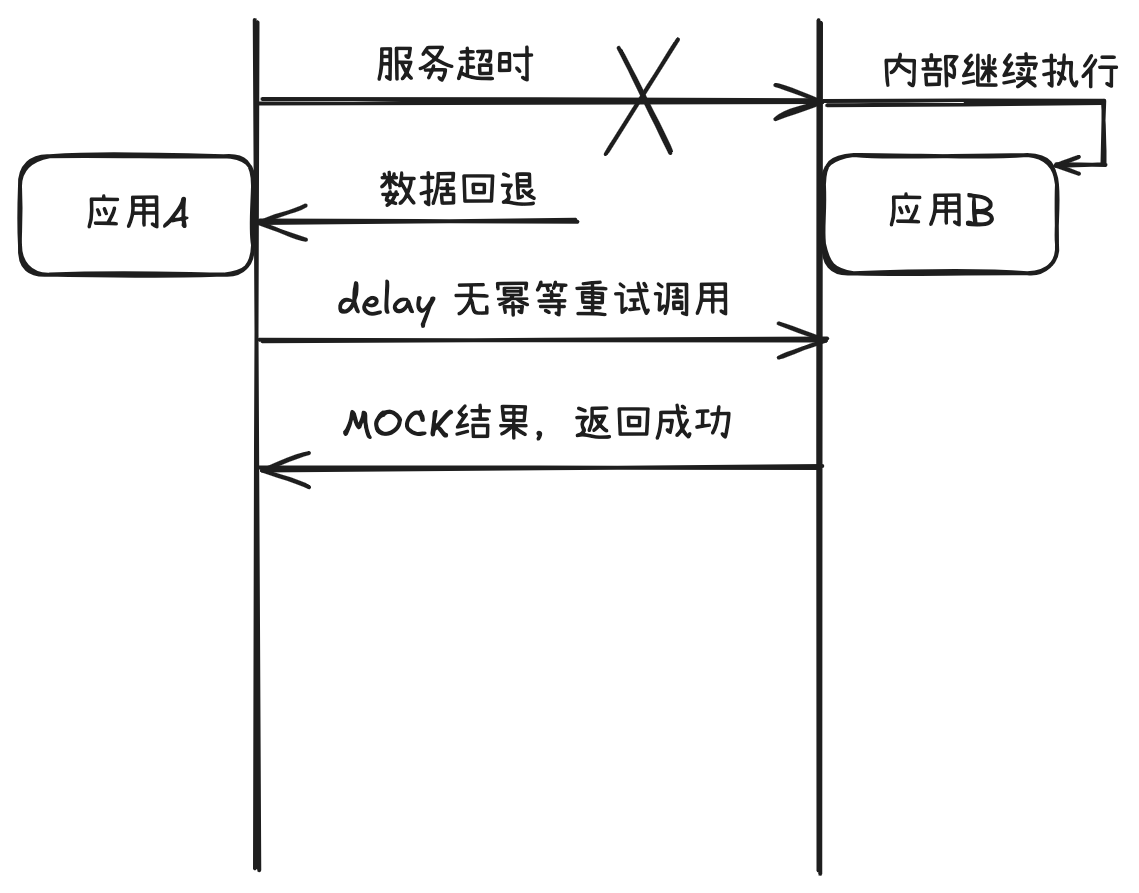
在应急处理情况下,向来都是争分夺秒,这里可以通过MOCK结果返回给调用方A,相当于“预支成功”。
并非所有的“预支成功”都是合理的,为了让“预支成功”尽可能合理,需要在服务提供方内部实现里,做好充分的判断和校验,这种判断和校验尽量是轻量级的。如果高并发情况下的“预支成功”判断不合理,事后可以人工介入核对和补偿数据。
建设工具
对工具的期望
• 由于接口无幂等或幂等失效,需要对能够预支成功的请求圈定一个范围,这个范围要支持配置,最好支持动态配置秒级生效。
• 对这个范围内的请求,进行伪幂等,MOCK特定结果,返回给调用方,使得调用方可以拿到成功结果快速推动流程。
• 圈定的范围尽可能具体,尽量避免不该MOCK的进行了MOCK,造成服务调用方的数据没得到刷新,导致数据的不一致。
在实现中,我称这个工具为“魔法工具”,是一种“障眼法”,是一种“预先支付成功”,是一种MOCK或SPY,对于调用方A来说,是一种体感上的成功,认为调用方真的处理成功了。
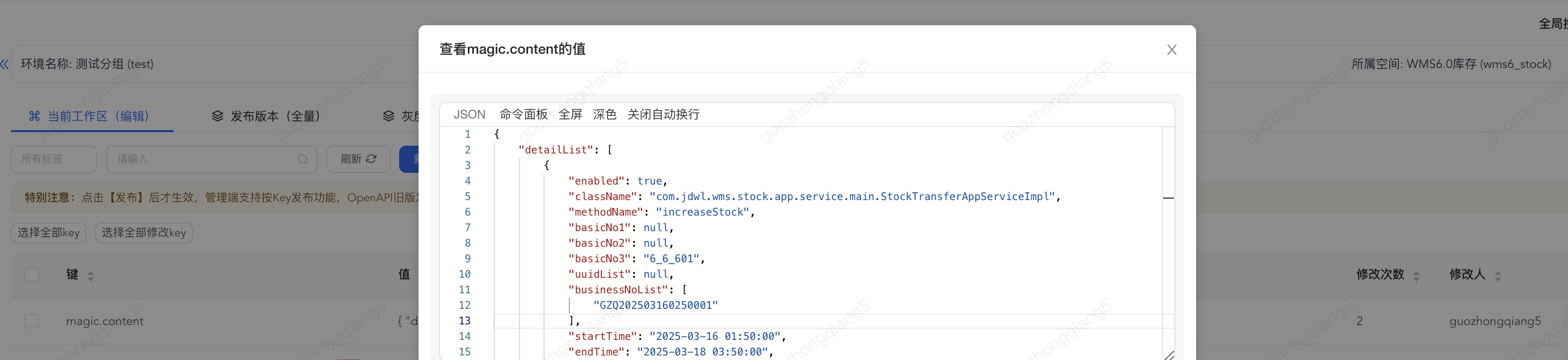
配置
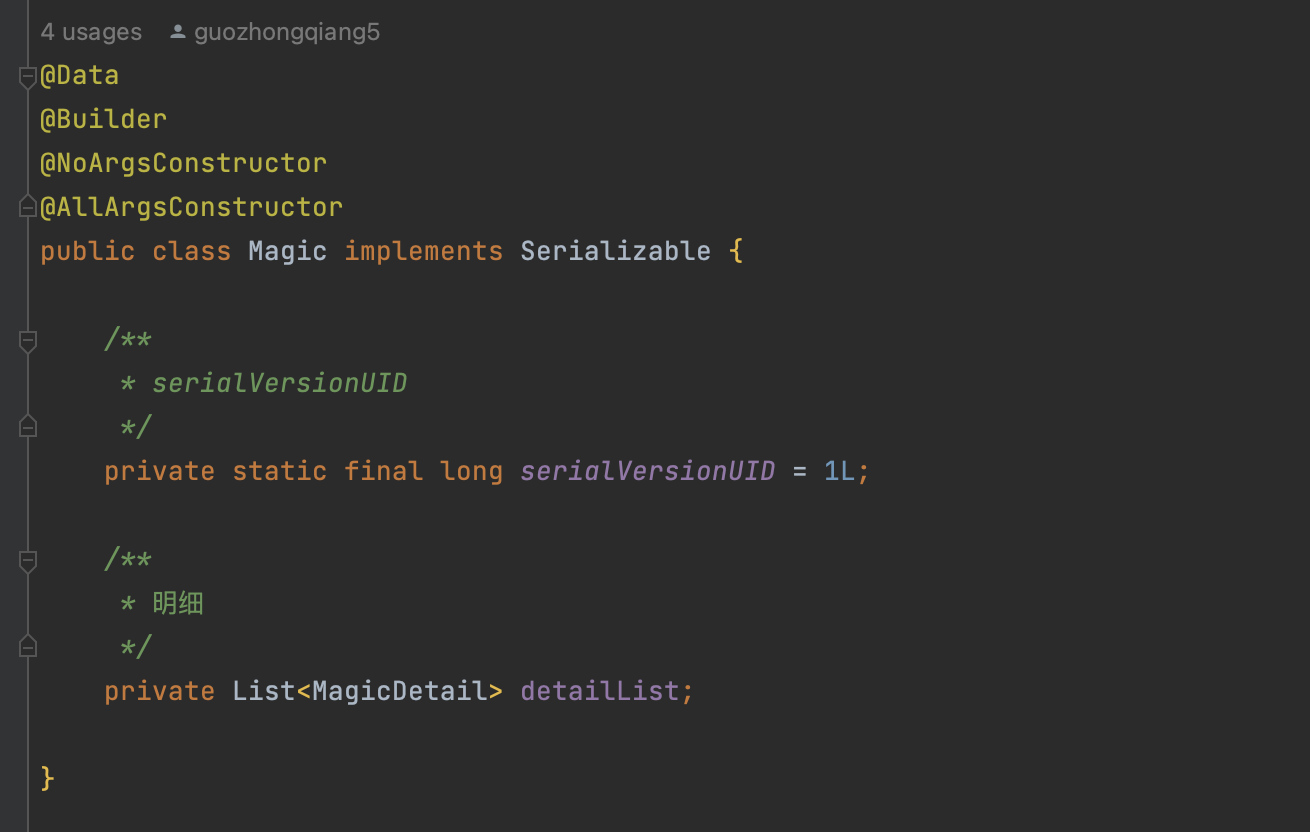
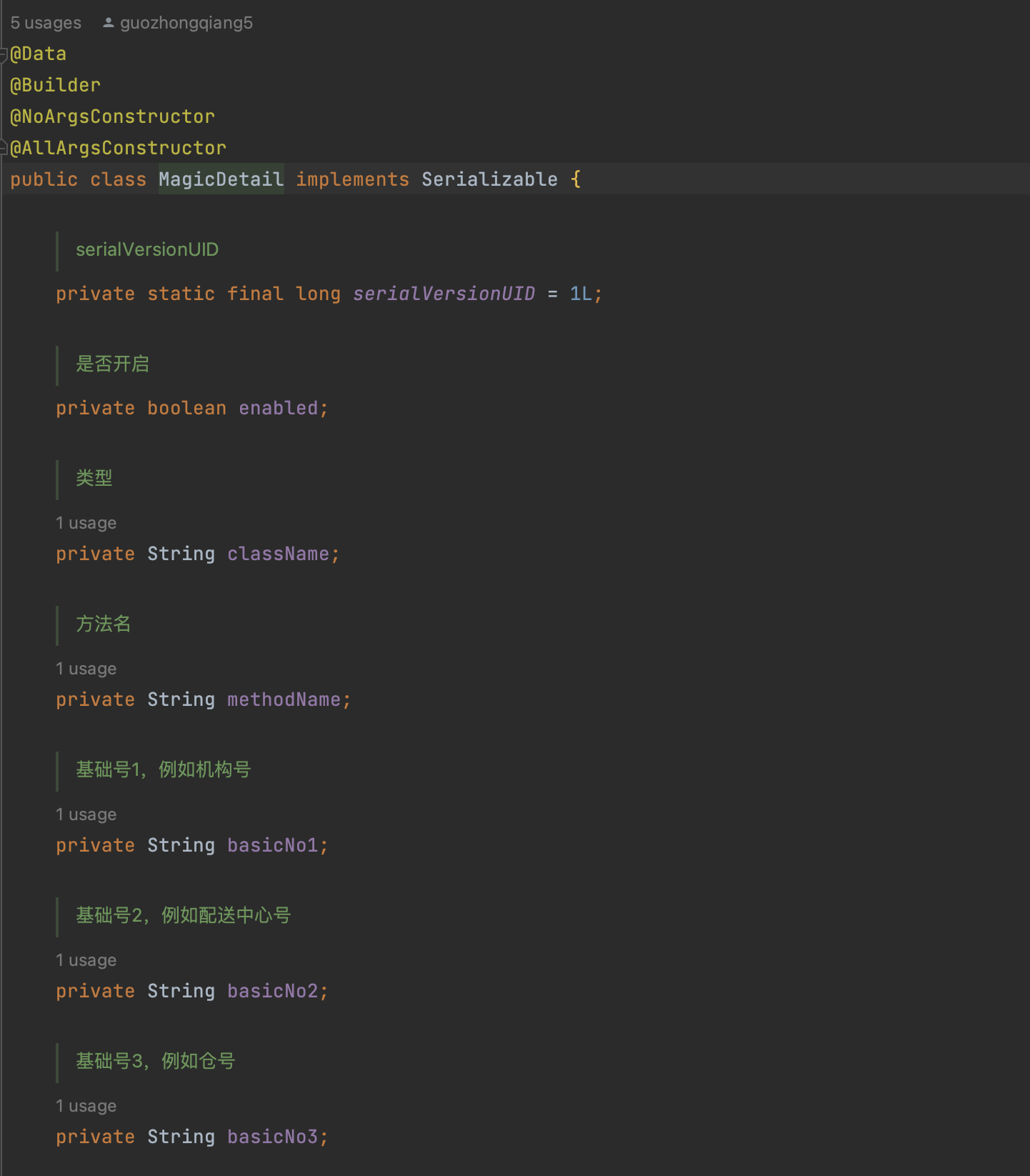
在配置中,支持多个配置内容的存在,比如有多个单据需要同时进行伪幂等MOCK。
更直观地,用一个JSON数据示例来看一下数据结构:
{
"detailList": [
{
"enabled": true,
"className": "com.jdwl.wms.stock.app.service.main.StockTransferAppServiceImpl",
"methodName": "increaseStock",
"basicNo1": null,
"basicNo2": null,
"basicNo3": "6_6_601",
"uuidList": null,
"businessNoList": [
"GZQ202503160250001"
],
"startTime": "2025-03-16 01:50:00",
"endTime": "2025-03-18 03:50:00",
"strategy": "DO_AND_RETURN_SUCCESS_REGARDLESS_OF_FAILURE",
"defaultResult": {
"resultValue": true,
"resultCode": 100000,
"prompType": 0,
"success": true
}
}
]
}
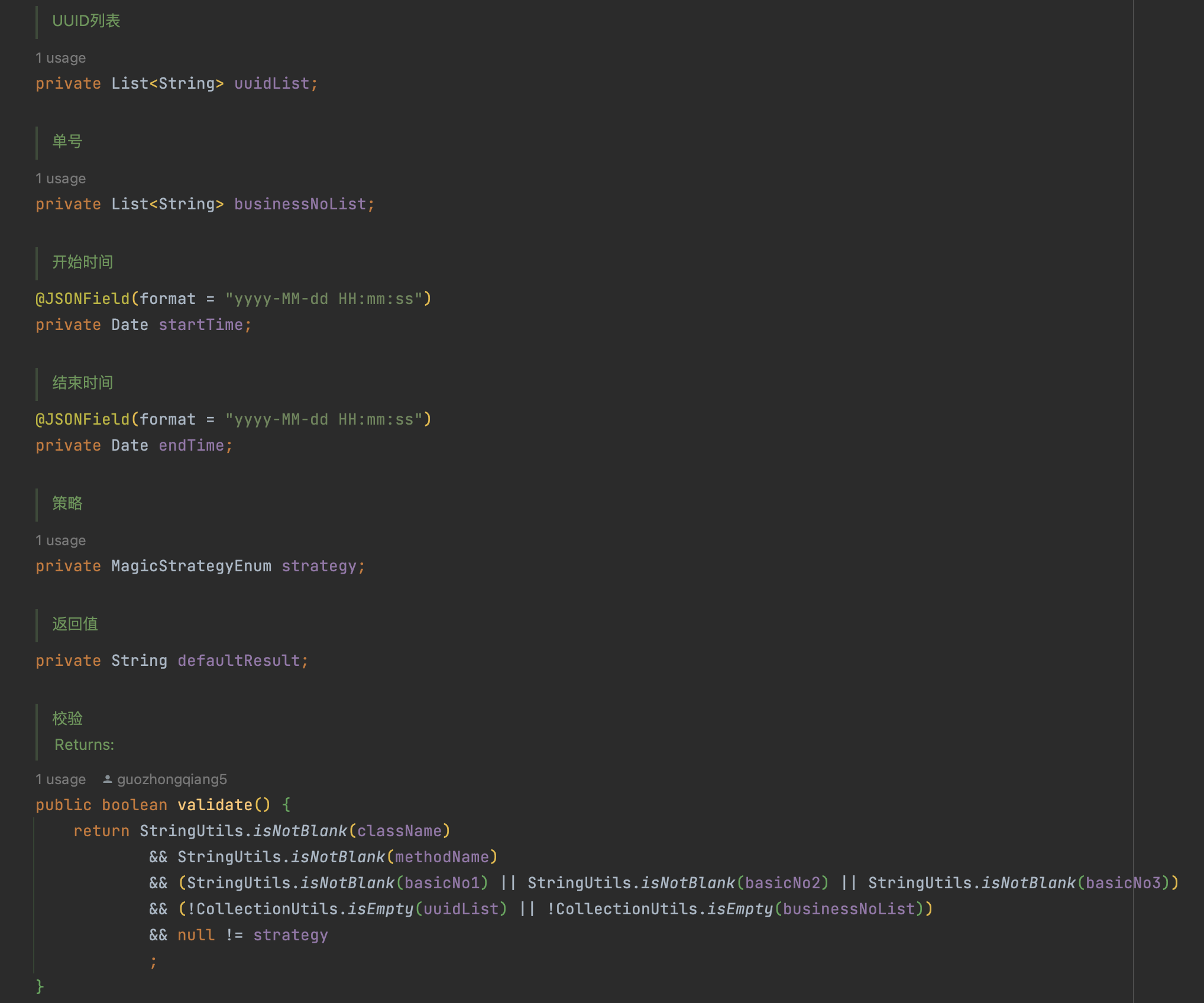
startTime、endTime 时间区间是用来卡控配置生效的时间段,正常情况下配置是短暂生效,起到数据处理的作用后,应去掉该配置。
目前策略有两种:
这两个策略的区别是要不要真正执行一次接口实现,类似于单测中的MOCK和SPY效果。
defaultResult 是该接口方法的期望返回值,配置对应的返回值JSON,会按照配置的内容直接返回给调用方。
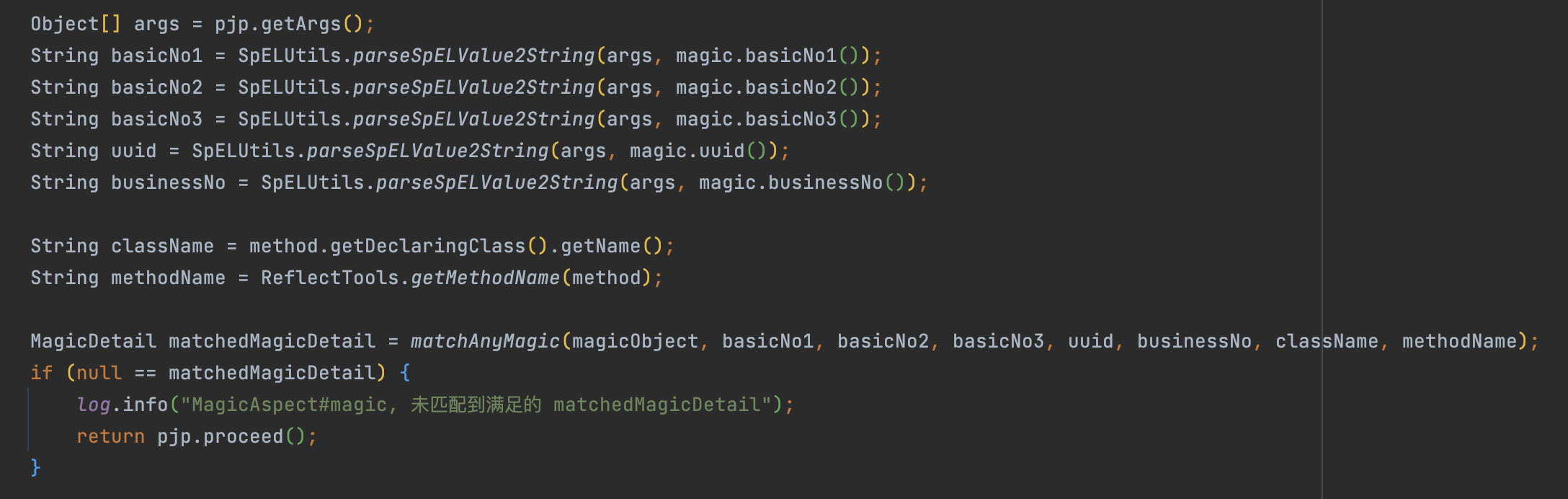
核心实现
圈定范围的匹配
按不同策略MOCK或SPY
使用案例
案例一 MOCK服务调用
通过DUCC配置圈定要MOCK的范围
{
"detailList": [
{
"enabled": true,
"className": "com.jdwl.wms.stock.app.service.main.StockTransferAppServiceImpl",
"methodName": "increaseStock",
"basicNo1": null,
"basicNo2": null,
"basicNo3": "6_6_601",
"uuidList": null,
"businessNoList": [
"GZQ202503160250001"
],
"startTime": "2025-03-16 01:50:00",
"endTime": "2025-03-18 03:50:00",
"strategy": "DO_NOTHING_AND_RETURN_SPECIFIED_VALUE",
"defaultResult": {
"resultValue": true,
"resultCode": 100000,
"prompType": 0,
"success": true
}
}
]
}
在JSF平台模拟客户端调用方发起调用
这里采用的策略是
DO_NOTHING_AND_RETURN_SPECIFIED_VALUE,即:不执行,直接返回指定的返回值
JSF的返回值就是在上面所配置的返回值内容。
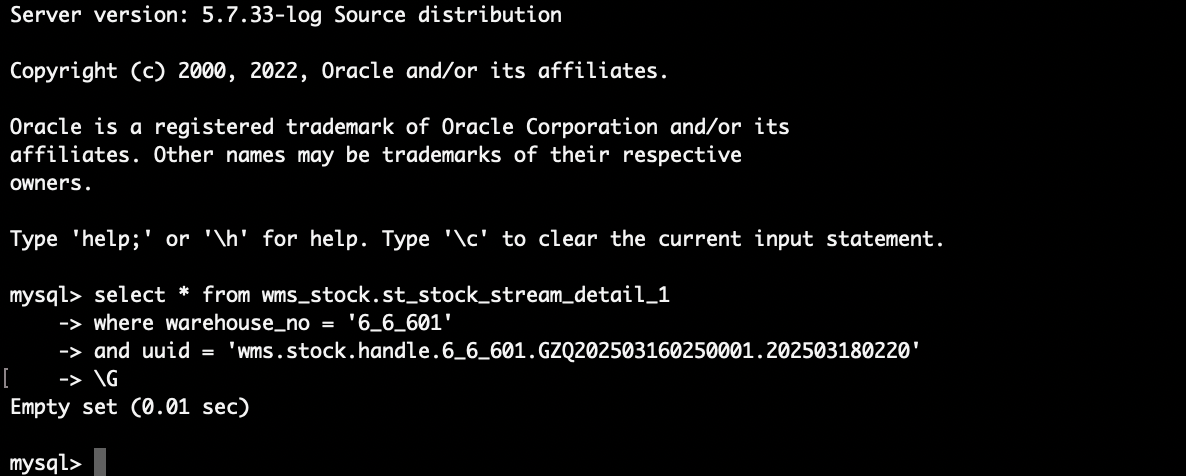
验证执行情况
这里检查数据库落库情况,看方法是否真地得到执行。
与预期一致,方法被成功MOCK,未真正执行该方法,返回了预先配置的返回值。
案例二 阻隔异常数据生成
近期生产环境遇到一个场景,逆向盘点时,有个终止盘点的操作,这个操作表示结束盘点,并且未盘点的明细则以少货缺量的方式提报差异,并预占库存。
虽然按钮有提示,但少概率下会有操作人员不看提示而误点击,形成大量的差异库存预占。
这些预占是由于误点击形成的差异预占,并非真实的差异,属于异常数据,这种数据需要释放关闭处理,如果数据量较大,现场会找研发团队协助处理。
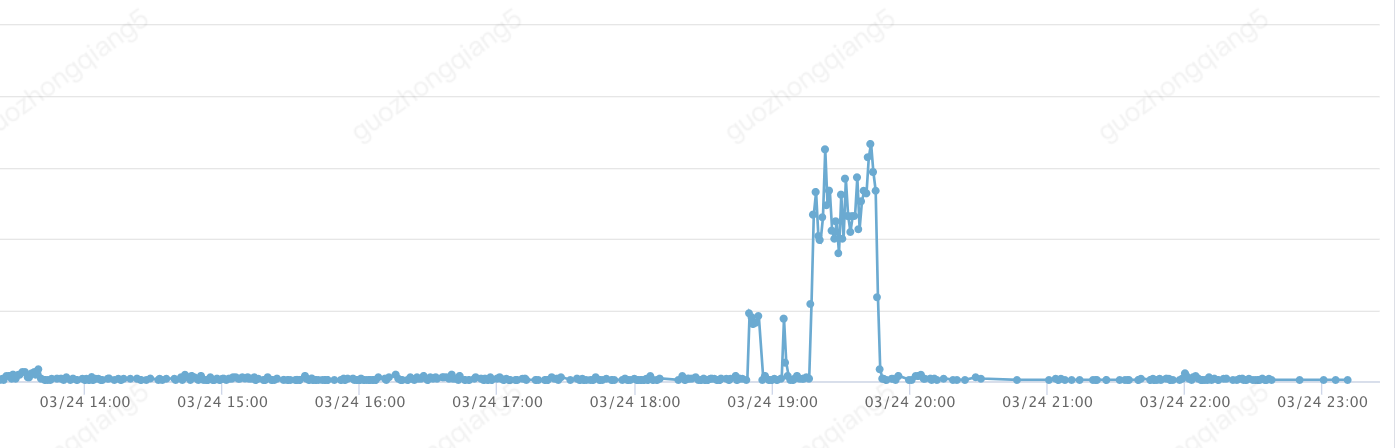
异常监控
收到监控告警,查看流量情况,发现有突发差异提报流量,短时间内调用量比日常高出很多。
阻隔配置
找到异常仓号和单号,与现场电话对齐后,决定对该异常单进行阻隔拦截,避免产生更多的异常数据。
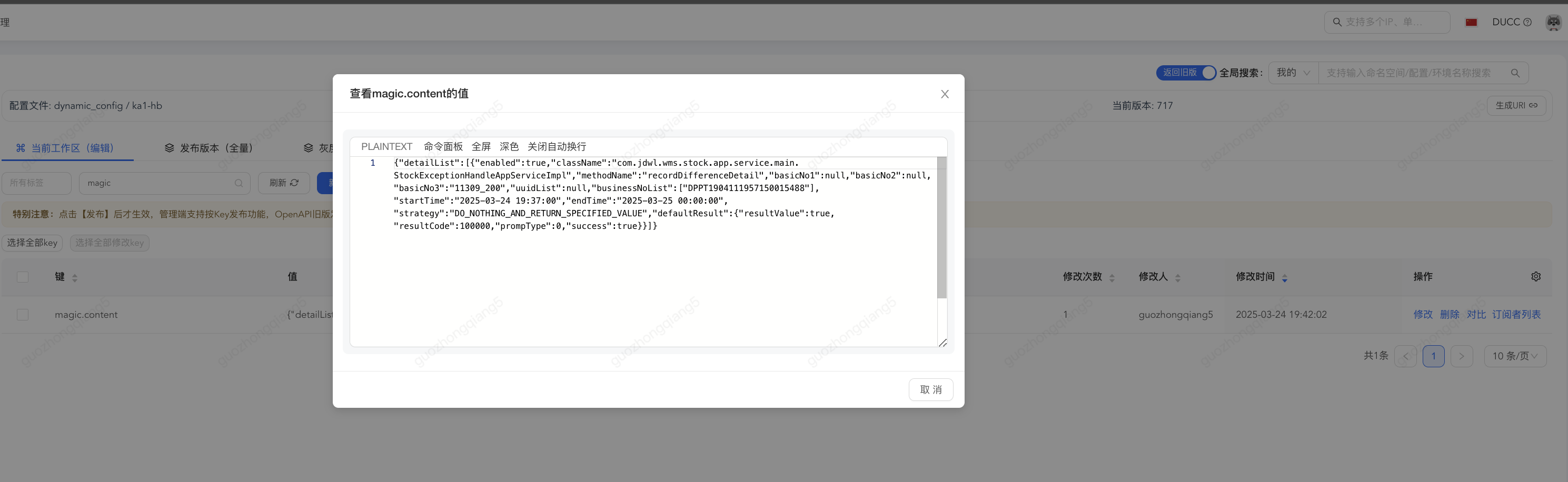
{
"detailList": [
{
"enabled": true,
"className": "com.jdwl.wms.stock.app.service.main.StockExceptionHandleAppServiceImpl",
"methodName": "recordDifferenceDetail",
"basicNo1": null,
"basicNo2": null,
"basicNo3": "11309_200",
"uuidList": null,
"businessNoList": [
"DPPT1904111957150015488"
],
"startTime": "2025-03-24 19:37:00",
"endTime": "2025-03-25 00:00:00",
"strategy": "DO_NOTHING_AND_RETURN_SPECIFIED_VALUE",
"defaultResult": {
"resultValue": true,
"resultCode": 100000,
"prompType": 0,
"success": true
}
}
]
}
结果核实
通过核实日志和数据,该工具有效阻隔了部分异常数据的生成,节省了异常数据核对和处理的时间。
总结
本文所提出的一款轻量级仿幂等数据校正处理辅助工具,可以达到MOCK或SPY的效果。不仅可以用在无幂等或幂等失效场景下,数据库快速处理恢复的场合,还可以用于一些查询类、校验类的读服务的MOCK场景。
现阶段工具还比较简单,功能还很有限,使用场景也有针对性和局限性,希望在一些场景上可以帮助大家。
本文工具并不重要,重要的是与大家一起探讨一些解决方案,给大家提供一种思路。
本文的解决方案是我短时间内的一个思考和落地尝试,未必是最优的,希望与大家一起交流更好的方案。
如何接入使用?
如果小伙伴也有类似使用诉求,大家可以先在测试、UAT环境接入试用,然后再逐步推广线上生产环境。
接入方法也非常简单,如下。
1、引入Maven依赖
<!-- http://sd.jd.com/article/44544?shareId=105168&isHideShareButton=1 -->
<dependency>
<groupId>com.jd.sword</groupId>
<artifactId>sword-aspect</artifactId>
<version>1.0.2-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
</exclusion>
<exclusion>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</exclusion>
<exclusion>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</exclusion>
<exclusion>
<groupId>com.jd.laf.config</groupId>
<artifactId>laf-config-client-jd-spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.jd.sword</groupId>
<artifactId>sword-constant</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.jd.sword</groupId>
<artifactId>sword-annotation</artifactId>
<version>1.0.1-SNAPSHOT</version>
</dependency>
对于其中的间接依赖,例如lombok等,大家可以使用自己工程中的已有依赖,在这里可以通过exclusion排掉,如果自己工程中没有这些依赖,可以不exclusion。
2、在被拦截方法上打上注解
示例:
@Magic(enabled = true, basicNo3 = "#args[0].requestHeader.warehouseNo", uuid = "#args[0].requestHeader.uuid", businessNo = "#args[0].requestHeader.businessNo")
支持SpEL表达式。
建议在服务提供方的内部方法实现内,或者调用方在调用目标API的防腐层上进行注解。
服务提供方的内部方法实现内,不一定是放在API的impl层,也可以是其内部的Service层,比如放在幂等防重和轻量级校验判断之后,重量级核心逻辑实现之前。
3、使用时进行按需配置
DUCC配置或Spring yml 配置都可以,更推荐使用DUCC动态配置生效。
使用完应尽快去掉配置,可以保留空壳,将detailList置为空list。
示例配置:
{
"detailList": [
{
"enabled": true,
"className": "com.jdwl.wms.stock.app.service.main.StockTransferAppServiceImpl",
"methodName": "increaseStock",
"basicNo1": null,
"basicNo2": null,
"basicNo3": "6_6_601",
"uuidList": null,
"businessNoList": [
"GZQ202503160250001"
],
"startTime": "2025-03-16 01:50:00",
"endTime": "2025-03-18 03:50:00",
"strategy": "DO_NOTHING_AND_RETURN_SPECIFIED_VALUE",
"defaultResult": {
"resultValue": true,
"resultCode": 100000,
"prompType": 0,
"success": true
}
}
]
}
或
magic:
content: '{"detailList":[{"enabled":true,"className":"com.jdwl.wms.stock.app.service.main.StockTransferAppServiceImpl","methodName":"increaseStock","basicNo1":null,"basicNo2":null,"basicNo3":"6_6_601","uuidList":null,"businessNoList":["GZQ202503160250"],"startTime":"2025-03-16 01:50:00","endTime":"2025-03-18 03:50:00","strategy":"DO_AND_RETURN_SUCCESS_REGARDLESS_OF_FAILURE","defaultResult":{"resultValue":true,"resultCode":100000,"prompType":0,"success":true}}]}'