
字节跳动联合清华大学开源统一多模态框架:HuMo
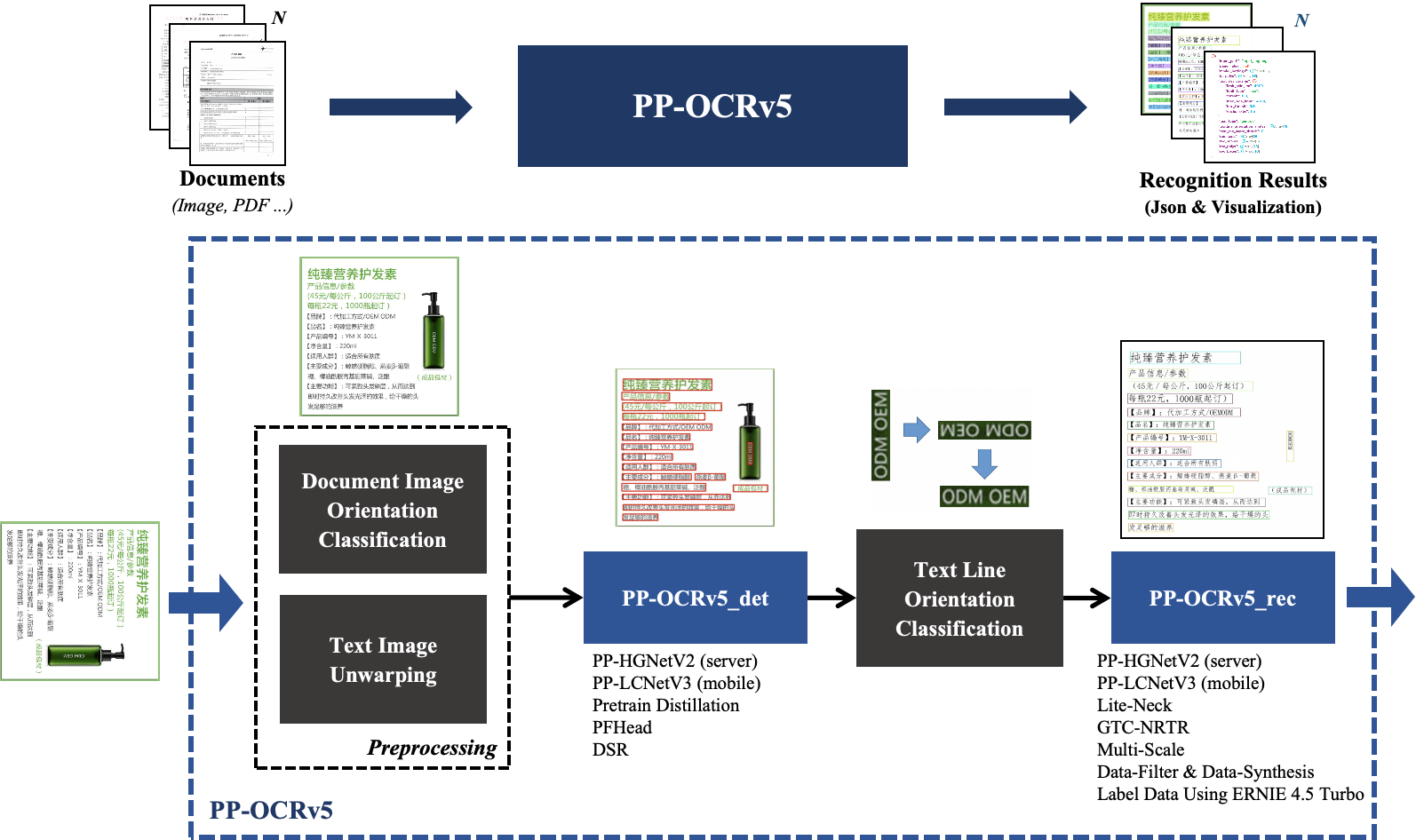
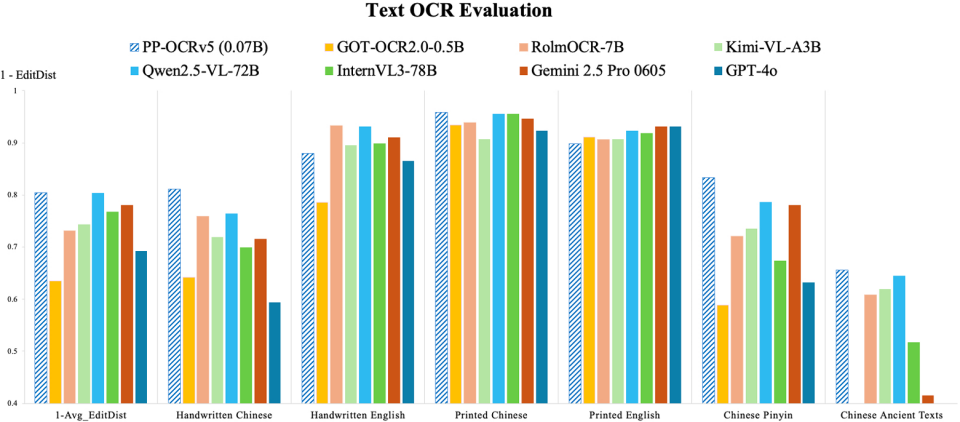
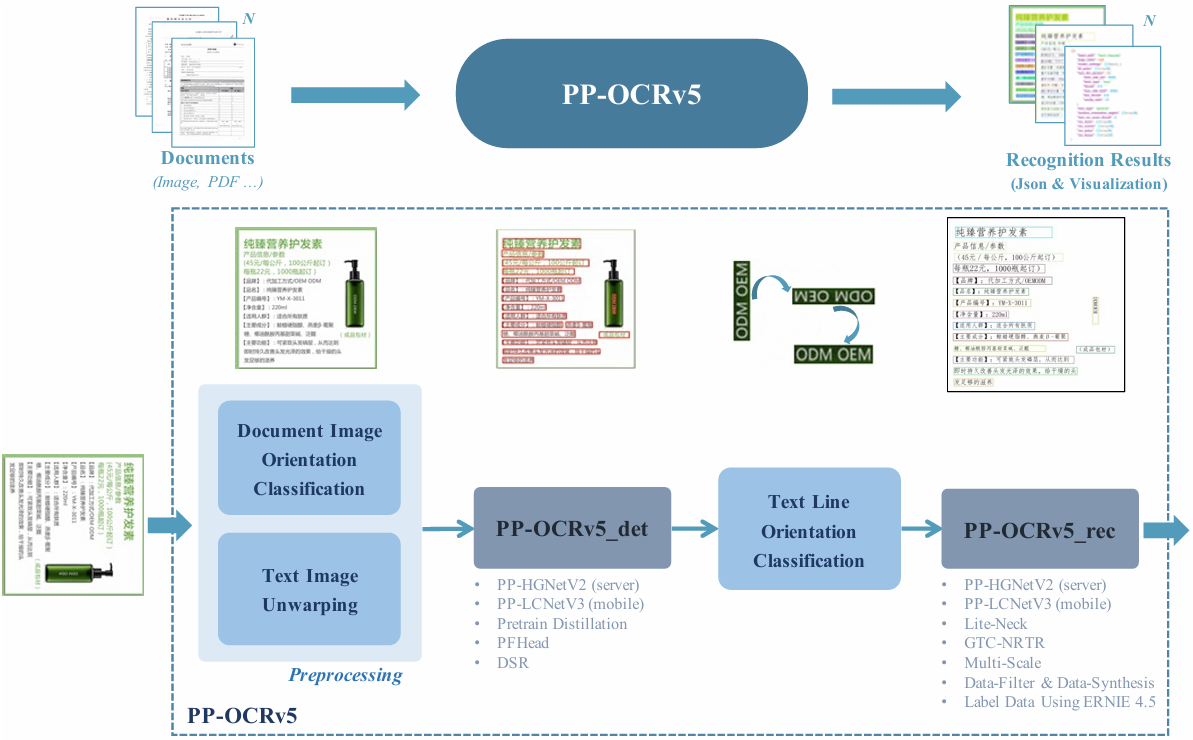
字节跳动智能创作团队联合清华大学共同开源了名为HuMo的统一 HCVG(Human-Centric Video Generation)框架。 论文地址: https://arxiv.org/abs/2509.08519 Human-Centric Video Generation,即人体视频生成框架,支持文本、图像、音频三种模态协同驱动。 HuMo(意指 Human-Modal)通过构建高质量数据集和设计创新的渐进式训练范式,成功实现了对多模态输入的协同控制,在各项子任务上超越了现有的专业化方法,可输出 480P 与 720P 分辨率、最长 97 帧、25FPS 的精细可控人物视频。 HuMo 框架的核心在于其创新的数据处理流程、渐进式多模态训练范式以及灵活的推理策略。 项目地址: https://phantom-video.github.io/HuMo https://github.com/phantom-video/humo