Glide 5.0.3 发布,Android 图片加载和缓存库
Glide 5.0.3 发布了,Glide 是一个 Android 上的图片加载和缓存库,其目的是实现平滑的图片列表滚动效果。 更新内容如下: Compose 版本升级至 1.0.0-beta06 KTX 版本升级至 1.0.0-beta06 Bugs 修复缺失的 gif_decoder 模块。参阅#5580。 更新说明:https://github.com/bumptech/glide/releases/tag/v5.0.3
阶跃星辰正式发布最强开源端到端语音大模型 Step-Audio 2 mini,该模型在多个国际基准测试集上取得 SOTA 成绩。
它将语音理解、音频推理与生成统一建模,在音频理解、语音识别、跨语种翻译、情感与副语言解析、语音对话等任务中表现突出,并率先支持语音原生的 Tool Calling 能力,可实现联网搜索等操作。
一句话总结,Step-Audio 2 mini “听得清楚、想得明白、说得自然”。
据介绍,Step-Audio 2 mini 在多个关键基准测试中取得 SOTA 成绩,在音频理解、语音识别、翻译和对话场景中表现突出,综合性能超越 Qwen-Omni 、Kimi-Audio 在内的所有开源端到端语音模型,并在大部分任务上超越 GPT-4o Audio。
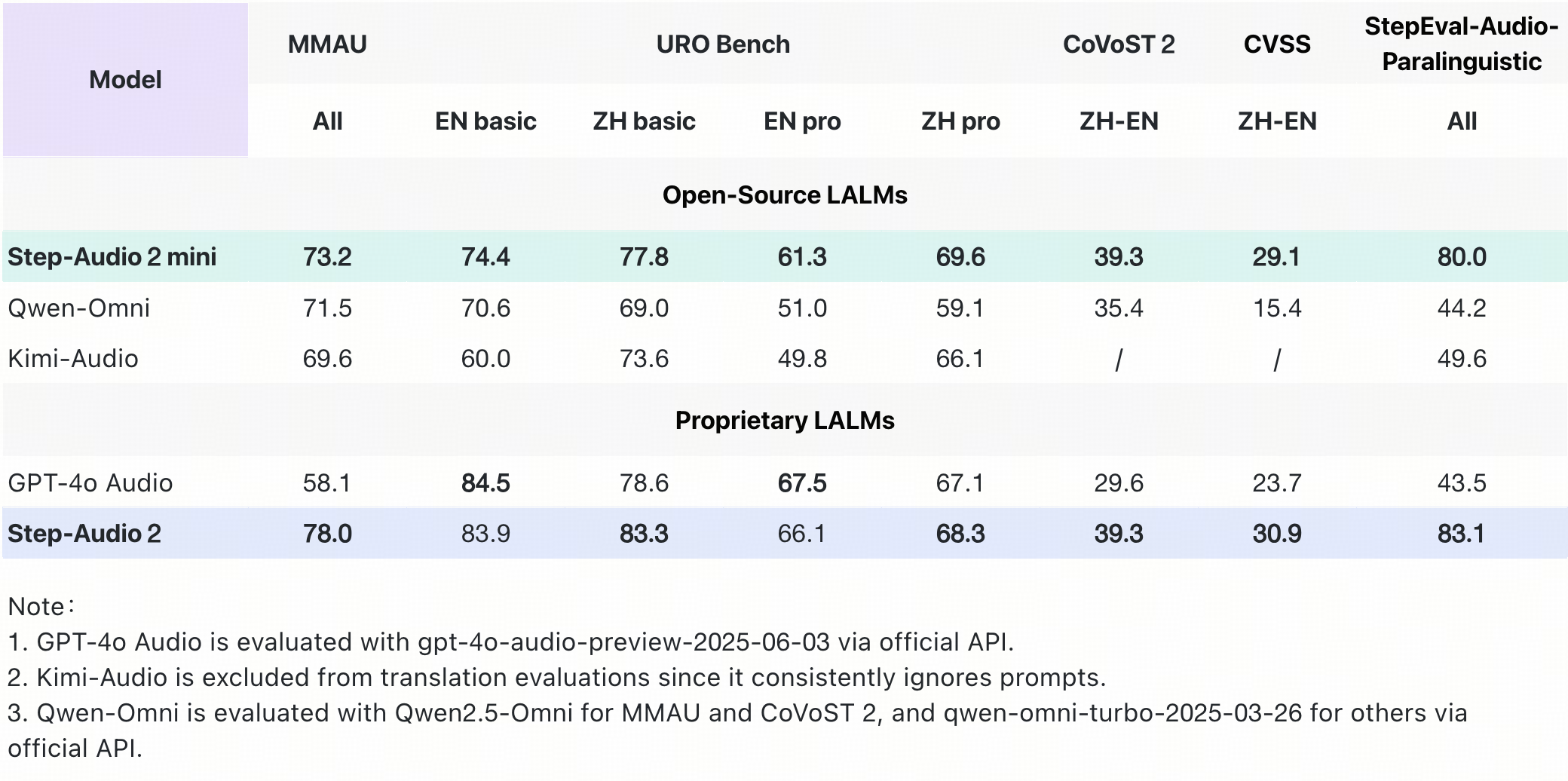
在通用多模态音频理解测试集 MMAU 上,Step-Audio 2 mini 以 73.2 的得分位列开源端到端语音模型榜首;
在衡量口语对话能力的 URO Bench 上, Step-Audio 2 mini 在基础与专业赛道均拿下开源端到端语音模型最高分,展现出优秀的对话理解与表达能力;
在中英互译任务上, Step-Audio 2 mini 优势明显,在 CoVoST 2 和 CVSS 评测集上分别取得 39.3 和 29.1 的分数,大幅领先 GPT-4o Audio 和其他开源语音模型;
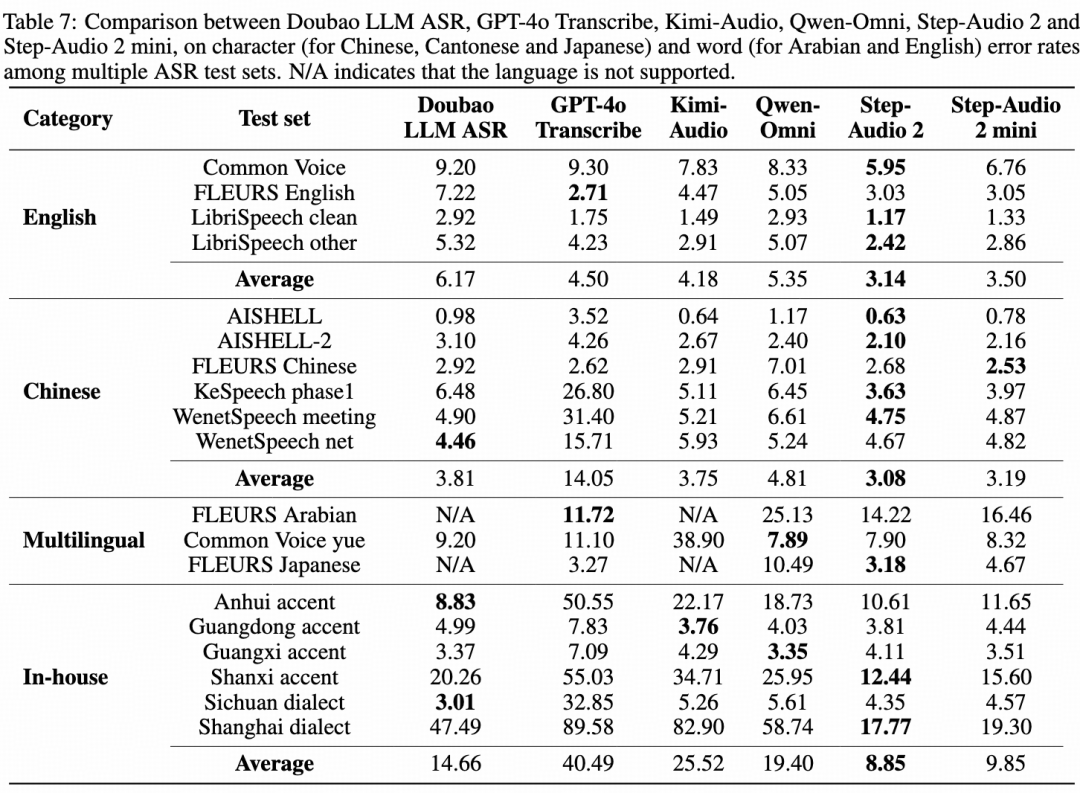
在语音识别任务上,Step-Audio 2 mini 取得多语言和多方言第一。其中开源中文测试集平均 CER(字错误率) 3.19,开源英语测试集平均 WER(词错误率) 3.50,领先其他开源模型 15% 以上。
Step-Audio 2 mini 通过创新架构设计,有效解决了此前语音模型存在的问题,做到“走脑又走心”。
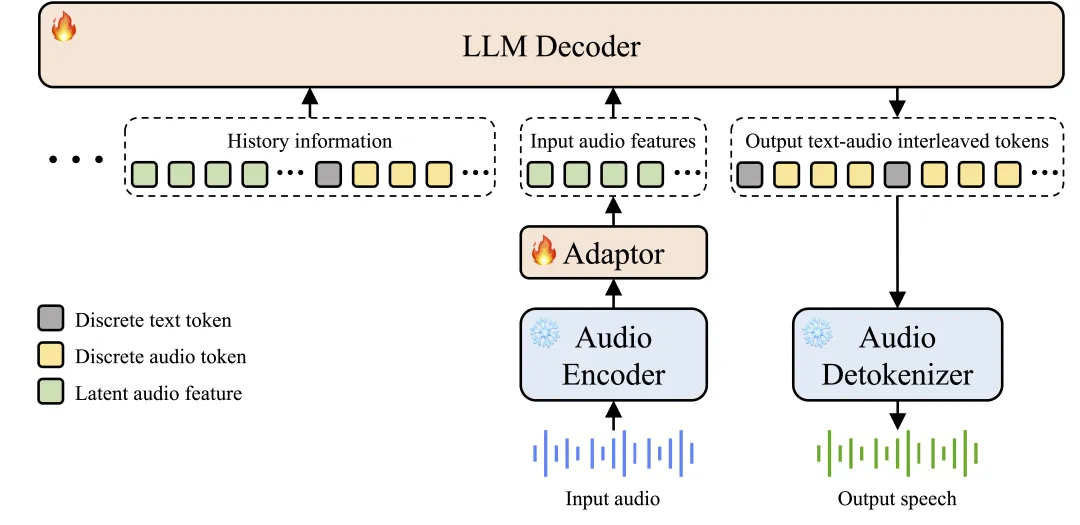
图:Step-Audio 2 mini 模型架构图
CoT 推理结合强化学习:Step-Audio 2 mini 在端到端语音模型中首次引入链式思维推理(Chain-of-Thought, CoT)与强化学习联合优化,能对情绪、语调、音乐等副语言和非语音信号进行精细理解、推理并自然回应。
音频知识增强:模型支持包括 web 检索等外部工具,有助于模型解决幻觉问题,并赋予模型在多场景扩展上的能力。
模型现已上线 GitHub、Hugging Face 等平台。
GitHub:https://github.com/stepfun-ai/Step-Audio2
Hugging Face:https://huggingface.co/stepfun-ai/Step-Audio-2-mini
ModelScope:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273