作者:黄晓萌(学仁)
![]()
概述
有许多的业务场景需要用到短周期的任务,比如:
- 订单异步处理:每分钟扫描超时未支付的订单进行订单处理。
- 风险监控:每分钟扫描metrics指标,发现异常进行报警。
- 数据同步:每天晚上同步库存、门店信息。
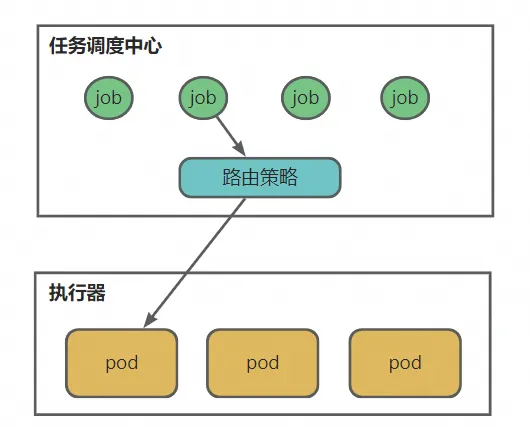
任务调度系统负责管理这些短周期的任务,通过用户设置的调度时间,周期性的把任务分发给执行器执行。每次任务要分发给哪个执行器执行,就是由路由策略决定的。
![]()
不同任务处理不同的业务逻辑,有些执行时间长,有些执行时间短,有些消耗资源多,有些消耗资源少。如果选择的路由策略不合适,可能会导致集群中执行器负载分配不平均,资源利用率上不去,成本上升,甚至产生稳定性故障。
轮询(Round Robin)
轮询(Round Robin)路由策略是一种简单且常见的负载均衡方法,其核心原理是按照顺序将请求或任务依次分发到后端节点上,从而确保任务的平均分布,避免资源过度集中在某一节点上。具体实现方式通常是维护一个计数器,记录当前分配的节点索引。分发请求时,该索引递增并对节点总数取模,从而实现循环分配。在任务调度系统中,分为任务级别轮询和应用级别轮询。
任务级别轮询
代表产品是XXLJOB [ 1] ,为每个任务都维护了一个计数器。比如有ABC三个执行器。每个任务调度的时候都会按照 A->B->C->A 这个顺序轮询机器。
-
如果所有任务的调度时间都一致(比如每小时执行一次),会导致所有任务每次执行都落在同一台后端节点上,负载严重不均衡。为了解决这个问题,XXL-JOB初始化每个任务计数器的时候,做了随机,可以大大降低该问题的概率。
AtomicInteger count = routeCountEachJob.get(jobId); if (count == null || count.get() > 1000000) { // 初始化时主动Random一次,缓解首次压力 count = new AtomicInteger(new Random().nextInt(100)); } else { // count++ count.addAndGet(1); }
-
如果任务的调度频率不一致,因为每个任务都按照自己计数器轮询,也有可能在某个周期,大部分任务都调度到同一个执行器上,导致负载不均衡。
应用级别轮询
整个应用下所有任务共享同一个计数器,每个任务调度的时候,都会让计数器+1。该算法可以保证所有执行器接收到的任务次数是平均的。如果所有任务负载和执行时间差不多,是负载均衡的,但是如果有大任务和小任务并存,情况又不一样了。
![]()
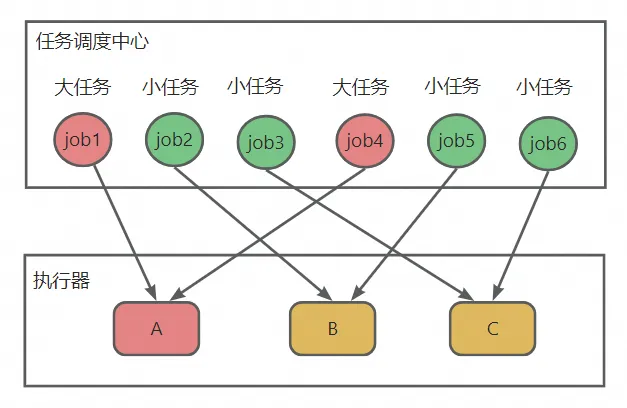
如上图所示,
- 有ABC三个执行器,job1~job6一共6个任务需要依次调度,其中job1和job4是大任务。
- job1调度到A节点,job2调度到B节点,job3调度到C节点,job4调度到A节点,job5调度到B节点,job6调度到C节点。
- job1和job4这2个大任务,每次都调度到A节点,导致A节点负载比其他节点高。
阶段总结
- 如果所有任务负载和执行时间差不多,建议选择应用级别轮询。
- 如果有大任务和小任务存在,这两种算法都有可能导致负载不均衡,建议给大任务配置任务级轮询,防止每次都落到同一台节点上。
随机
随机路由策略是一种简单的负载均衡算法,它通过随机选择一个后端服务器来处理每个请求,来达到负载均衡的目的。在任务调度系统中,任务每次调度的时候,随机选一个执行器执行。
随机路由策略由于算法完全依赖随机数生成器,负载均衡全凭运气,如果拉长时间区间(比如看一整天的调度情况)看可能是负载均衡的,但是可能存在短时间负载不均的问题(某些服务器在一定时间段内被选中的概率较高)。
最近最少使用(LFU)
最近最少使用(LFU,Least Frequently Used)是一种基于访问频率的缓存淘汰算法,主要用于内存管理和缓存系统中。其实现机制是为每个数据项维护一个访问计数器,数据被访问时计数器加1,当需要淘汰数据时,选择计数器值最小的数据项。
在任务调度系统中,可以统计执行器的调度次数,优先选择最近使用次数最少的执行器进行任务调度,从而达到负载均衡的目的。如果所有任务都配置成LFU路由策略,该算法最终使用效果,和轮询算法是差不多的,算法还复杂,没有太大必要。如果集群中的任务配置了多种路由策略,不同执行器调度次数不一样,出现了负载不均衡的情况,给新任务配置LFU算法,一定能调度到调度次数最少的执行器上,才能真正发挥它的作用。
开源XXLJOB具体实现上,使用的是任务级别的LFU,最终使用效果和任务级别轮询一致。
最近最久未使用(LRU)
最近最久未使用(LRU,Least Recently Used)是一种基于访问时间的缓存淘汰算法,主要用于管理有限缓存空间内的内存数据,当缓存已满时,依据数据最近使用时间,优先移除最近最久未使用的数据。
在任务调度系统中,可以统计执行器的调度时间,优先选择最久未调度的执行器进行任务调度,从而达到负载均衡的目的。因为每次调度的时候,也会更新执行器调度次数,所以该算法最终使用效果,和LFU是差不多的。
开源XXLJOB具体实现上,使用的是任务级别的LRU,最终使用效果和任务级别轮询一致。
一致性哈希
有些业务场景,需要任务每次执行在固定的机器上,比如执行器上有缓存,可以较少下游数据加载、加快任务处理速度。最直接的想法就是使用哈希算法,通过任务ID(JobId)和执行器数量取mod,把任务调度到固定的机器上。但是如果某个执行器挂掉了,或者执行器扩容的时候,执行器数量发生了变更,会导致所有任务重新哈希到了不同的机器上,所有缓存全部失效,可能会导致后端流量一下子突增。
XXLJOB提供了一致性哈希路由算法,可以保证执行器挂掉或者扩容的时候,大部分任务调度的执行器不变。
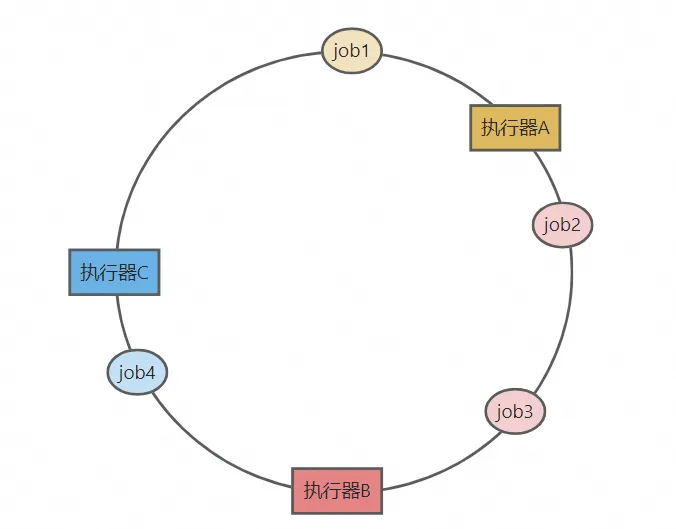
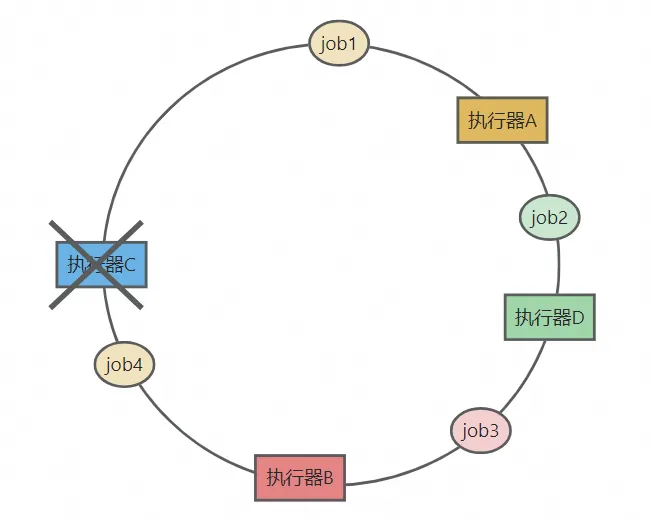
- 一致性哈希算法将2^32划分为一个逻辑环,其中每个执行器节点根据哈希值被映射到环上的某个位置。任务通过JobId做哈希也映射到环上,然后顺时针找到最近的执行器,即为目标执行器。如下图所示,job1固定调度到执行器A,job2和job3固定调度到执行器B,job4固定调度到执行器C:
![]()
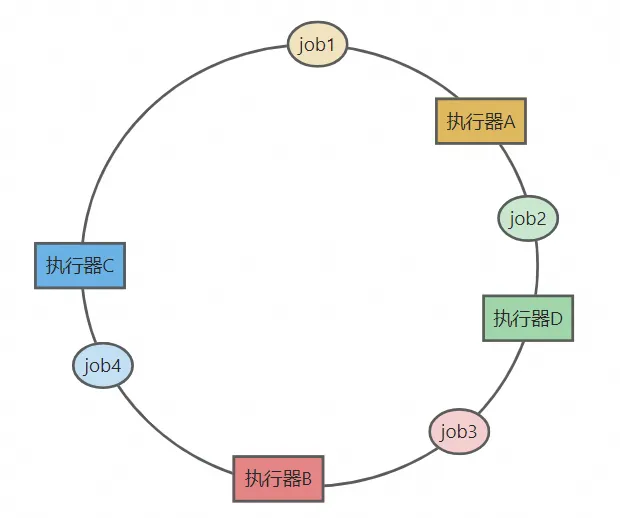
- 如果添加一个执行器D,通过哈希值映射到了job2和job3中。如下图所示,job2会调度到执行器D上,其他任务调度的机器保持不变:
![]()
- 如果执行器C突然挂掉了,如下图所示,job4会调度到执行器A上,其他任务调度的机器保持不变:
![]()
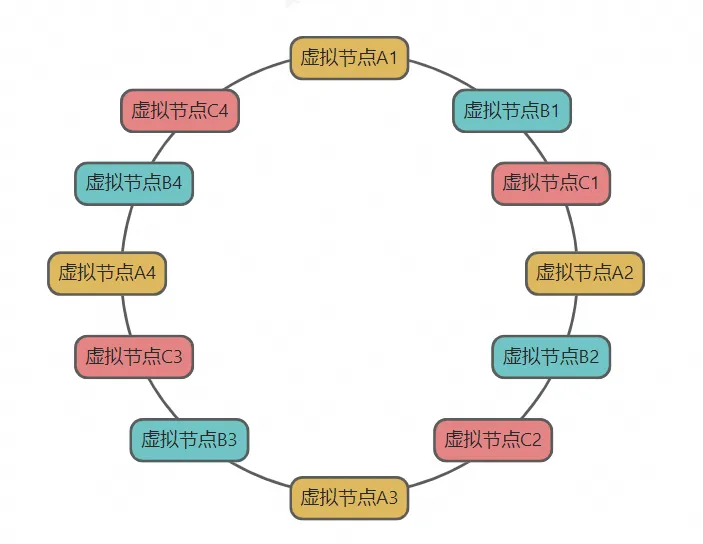
如果执行器节点不多,直接映射到哈希环上的时候,有可能无法平均分布,导致任务分配不均。为了解决这个问题,可以引入虚拟节点(XXLJOB引入了100个虚拟节点),将虚拟节点平均分布在哈希环上,然后物理节点映射虚拟节点。
![]()
如上图所示,一共有3个执行器ABC,每个执行器分配4个虚拟节点,保证所有虚拟节点平均分布在哈希环上,这样所有任务调度就基本上负载均衡了。
负载最低路由策略
上面提到的路由策略都没法解决一个问题,就是应用下同时存在大任务和小任务,导致执行器负载不均衡。那么我们是否可以采集所有执行器的负载,每次调度的时候按照负载最低优先调度呢?确实有些调度系统是这样做的,代表产品是Kubernets [ 2] 。Kubernetes使用kube-scheduler进行调度,本质上是把Pod调度到合适的Node上,默认策略就是调度到负载最低的Node上。在容器服务中,每个Pod都会预制占用cpu和内存,kube-scheduler每调度一个Pod,就能实时更新所有Node的负载,该算法没有问题。
但是在传统的任务调度系统中(比如XXLJOB),一般都是通过线程运行任务的,没法提前知道每个任务会占用多少资源。任务调度到执行器上,也不是马上导致执行节点负载上升,通常会有滞后性。甚至有些逻辑复杂的任务,可能好几分钟后才会有大量的IO操作,导致该执行节点好几分钟后才能明显负载上升。举个例子,有AB两个执行节点:
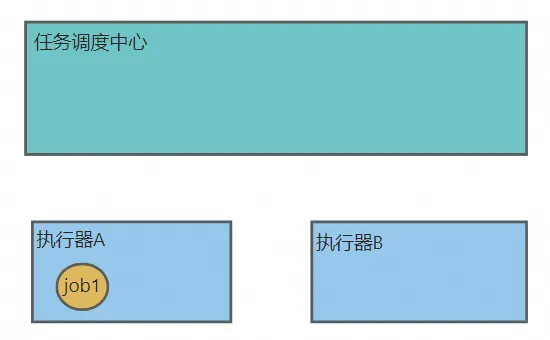
- A节点上当前有1个任务在运行,A节点负载20%,B节点当前没有任务运行,负载0%。
![]()
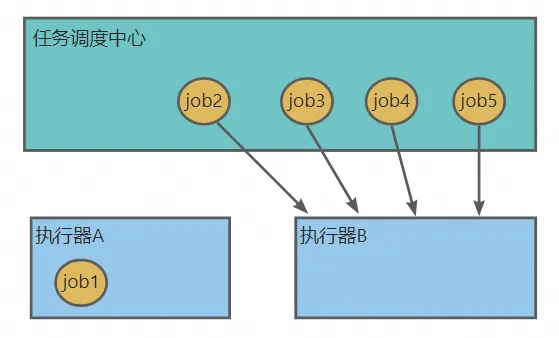
- 这个时候有job2~job5一共4个任务要调度,都选择了当时负载最低的执行器B。
![]()
- 4个任务都发送到执行器B后,过了一会,执行器B负载上升到100%,执行器A还是5%,导致负载不均衡。
任务权重路由策略
有没有办法可以像kube-scheduler一样,调度的时候就预算每个执行节点的负载呢?因为定时任务都是周期性运行的,每次执行的代码或者脚本是固定的,通过业务逻辑或者历史执行时间,我们其实是知道哪些是大任务哪些是小任务的。每次任务调度的时候,我们只要知道当前各个执行器上运行了多少个大任务多少个小任务,就能把当前这个任务分发到最合适的执行器上。
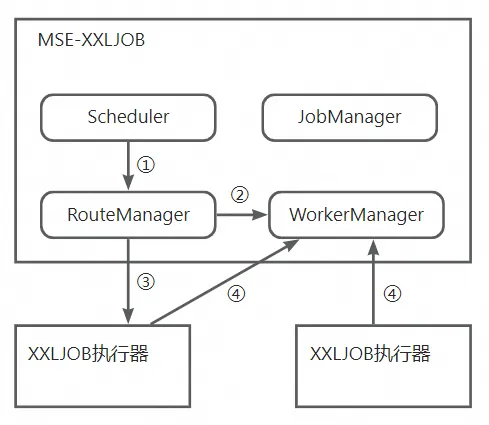
MSE-XXLJOB [ 3] 设计并实现了任务权重路由策略,每个任务都可以用户自定义权重(int值),交互流程如下:
![]()
如上图所示,
- Scheduler调度器开始调度任务。
- RouteManger负责路由策略,如果是任务权重路由策略,去WorkerManger里寻找当前权重最小的执行器,并更新该执行器的权重(+当前任务的权重)。
- RouteManger把任务分发给权重最小的执行器执行任务。
- 执行器运行完任务,更新WorkerManger,把该执行器的权重减去该任务的权重。
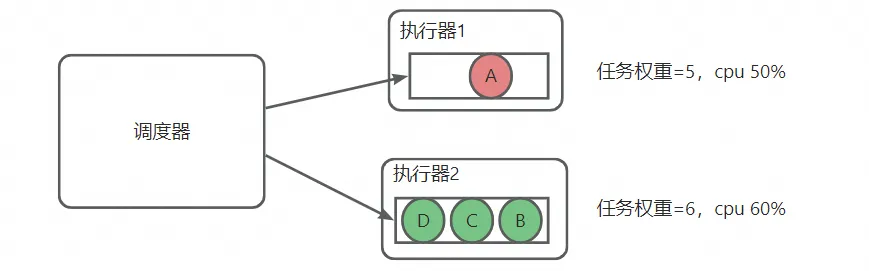
下面以一个详细的例子来说明。当前有两个执行器,有ABCD 4个任务需要调度,其中A是大任务,按照历史经验cpu会占用50%,BCD是小任务,每个会占用cpu 20%。将A任务权重设置为5,BCD设置为2。初始化执行器1和执行器2的权重都是0。
- A任务调度到执行器1,执行器1的权重变为5,执行器2的权重还是0。B任务选择任务权重最小的机器,调度到执行器2,执行器2的权重变为2。C任务选择任务权重最小的机器,调度到执行器2,执行器2的权重变为4。D任务选择任务权重最小的机器,调度到执行器2,执行器2的权重变为6。
![]()
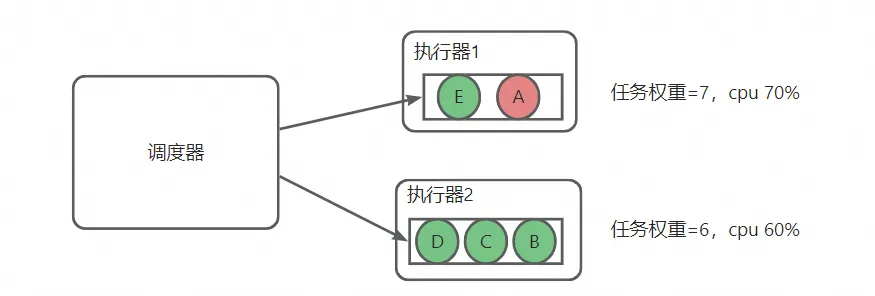
- 这个时候,又有个小任务E要调度,权重也是2,选择当前权重最小的机器1,则机器1的权重变为了7,如下图
![]()
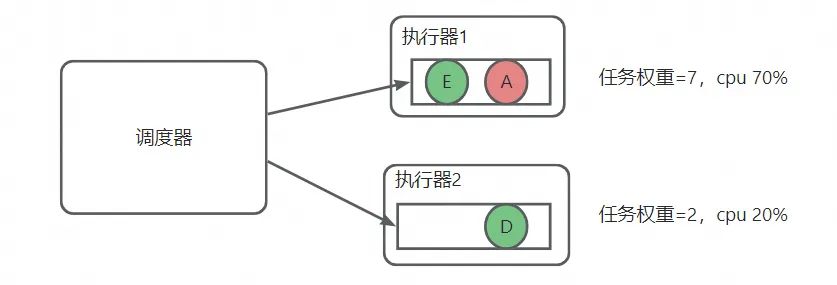
- 小任务B和C执行很快就跑完了,这个时候执行器2的权重减去4,变为了2,如下图:
![]()
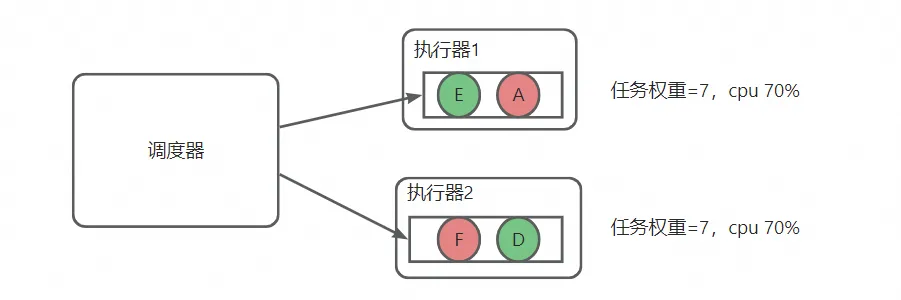
- 这个时候又来个大任务F,权重是5,选择权重最小的机器2,机器2的任务权重变为了7,如下图:
![]()
- 可以看到该算法,将每个任务实际消耗的资源映射成任务权重,可以实时统计每个执行器的权重,提前规划不同权重的任务分配到哪个执行器上去执行,达到全局最优解。
总结
在真实生产环境下,不同的任务处理不同的业务逻辑,如果选错路由策略,可能会导致集群中大部分执行节点负载不到10%,但是个别节点负载会冲高到100%,虽然平均负载不高,但是也无法减少规格,可能还需要增大规格防止出稳定性问题。但是如果选对了路由策略,集群所有节点负载均衡,就可以减少节点规格,成本降低50%以上。下面以一个表格详细介绍不同路由算法的场景:
| | 适合场景 | 不适合场景 | | :------- | :------------------------ | :-------------------------- | | 轮询 | 所有任务执行时间和负载差不多 | 有大任务和小任务并存 | | 随机 | 全凭运气,不推荐 | | | LFU | 所有任务执行时间和负载差不多,部分任务设置成LFU | 所有任务都设置成LFU,效果和轮询差不多 | | LRU | 所有任务执行时间和负载差不多,部分任务设置成LRU | 所有任务都设置成LRU,效果和轮询差不多 | | 一致性哈希 | 客户端有缓存,需要任务固定在一台机器执行 | 任务不需要固定机器,需要整体负载均衡 | | 任务权重路由策略 | 有大任务和小任务并存 | 所有任务执行时间和负载差不多,每个任务都配置权重太麻烦 |
相关链接:
[1] XXLJOB
https://github.com/xuxueli/xxl-job
[2] Kubernets
https://blog.csdn.net/jy02268879/article/details/148855464
[3] MSE-XXLJOB
https://help.aliyun.com/zh/schedulerx/schedulerx-xxljob/getting-started/create-and-deploy-a-xxljob-job-in-a-container-in-10-minutes