本系列目录:
- 改变与优势
- 领域分析基础
- 读写隔离
- 充血模型之实体
- 充血模型之Service
- 关于重构与落地
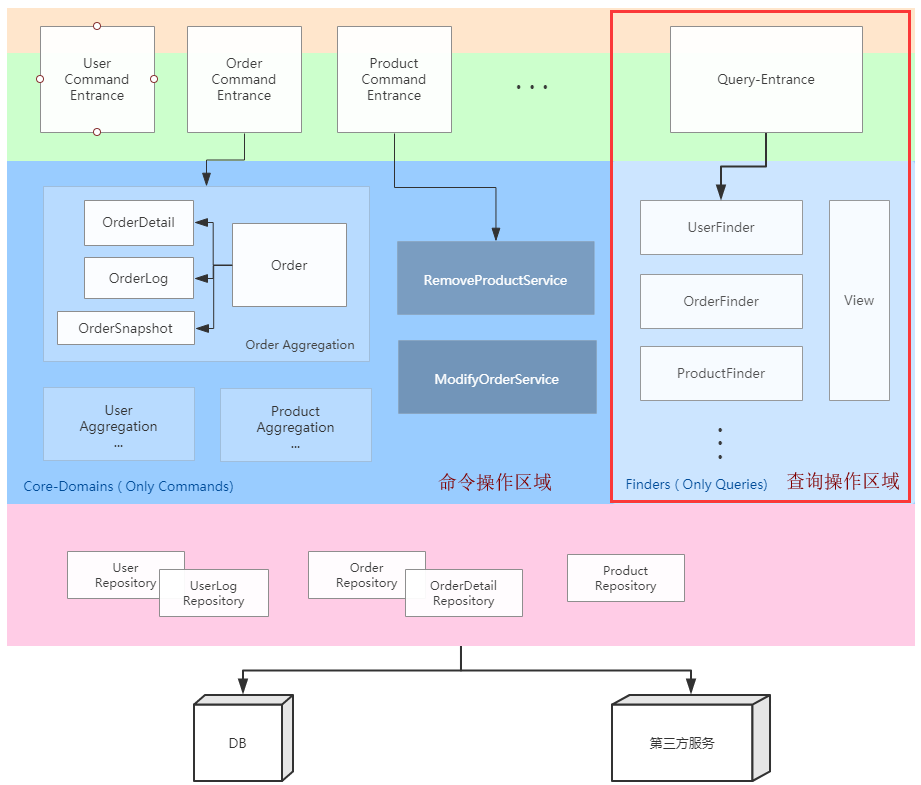
读写隔离后的世界
基于上面提到的读写隔离的思想,那么我们可以很清楚地看到上面这种情况可以看到:
![世界观]()
查询业务,从入口层(如Controller),调用Finder,而Finder调用Repository(具体实现如Hiberante,Mybatis等等均可),这一条线下来,我们全然不用考虑这个系统的增删改就是如何做的,就像他们完全处于不同的空间一样,互不干涉,互不影响,甚至,永远互不相见。 某种程度上来说,这种这种架构追求的效果,一种美感。
所以,接下来,我们关注的,就是增删改这一部分了,也就是命令操作 是开始要扎扎实实地来对这个系统进行修改了
首先让我们把视野抬高一些,从整个项目产品的上空来看看
业务灵魂-状态图
除开少数非常扁平的纯技术服务项目(比如AI识别,文本分析等等),其他绝大部分企业项目都有其核心的商业逻辑,而这些逻辑,往往也会以核心的领域概念来提现,从简单粗暴一点角度映射到设计开发中,那就是类class
- 电商系统,核心领域至少有【商品】,【订单】,【用户】,【物流】等;
- SNS社交平台,至少有【用户】,【博文/帖子】,【私信】,【通知】等;
- 进销存系统,至少有【账户】,【角色/权限】,【商品】,【客户/供应商】等;
- 在线教育平台,至少有【用户】,【课程】,【订单】等;
而这其中,也有主次,大家可以回头看看自己所开发过的项目。 但凡是有状态字段的类,很大可能都是整个项目的核心领域之一。 其实很好理解,因为它有流程,因为它需要被各类操作来变更它的状态,所以,他很可能贯穿了这个项目中某一个关键商业逻辑,比如电商系统中,
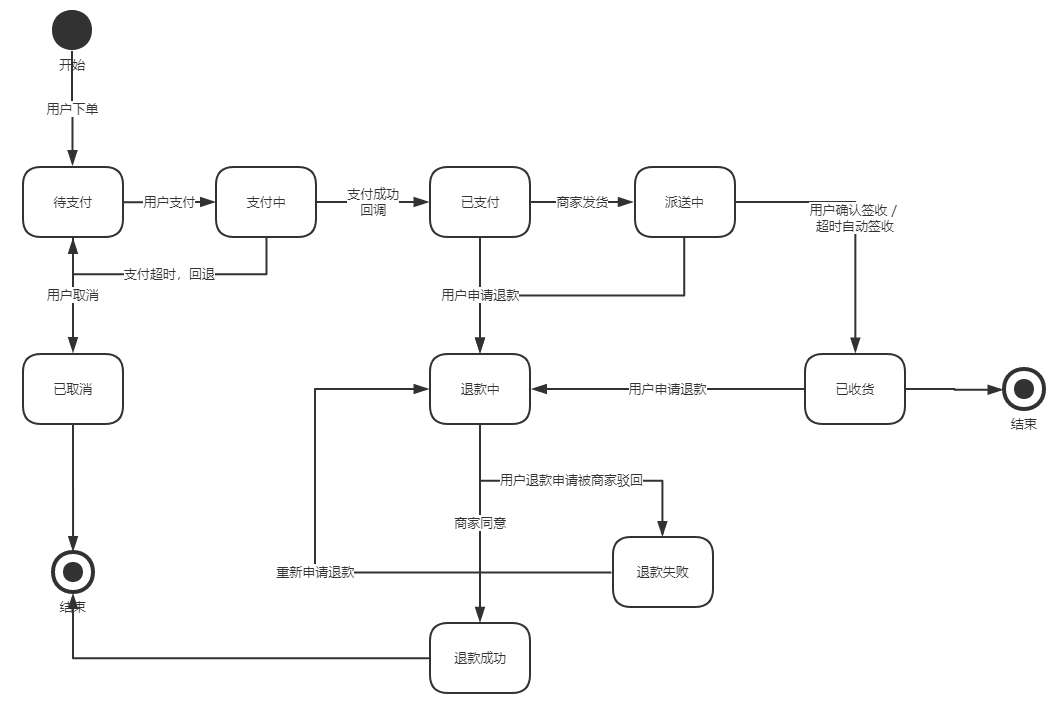
- 【订单】肯定有状态,从[待支付]-[已支付]-[派送中]-[已收货],甚至还有[已取消],[退款中],[退款失败],[退款成功],脑补一下,就知道会生成多少复杂的业务流程了
- 【用户】一般来说也会有状态,比如[正常],[冻结],但是可以想到,如果某个系统没有这方面权限与安全的要求,【用户】也可能就没有状态了,那么自然也不会有对应的操作对其进行修改,可能只会有创建
所以,如果在这些系统的早期设计阶段,要我选择一个最重要的UML图,我会选择状态图,以下就是整个系统中最核心的订单状态图
![支付状态图]()
可以看到,把握一个核心领域的状态变更,自然而然就能归纳出来很大一部分系统的功能需求。我们在这里看到,这些所有箭头所触发的动作,其实都是命令,也其实都是会落地到各个相关领域的增删改上。
当然这里还是一个粗粒度的表示,无法单单依据这个就马上落地开发,因为即使每一个箭头所代表的功能都可以写出一个完整甚至很复杂的用例。但至少这是一个非常清晰的引导。
贫血模型的世界
我们目前所用的Spring体系,几乎都是贫血模型,也就是说,真正的实体类里,都只有各个属性的Get与Set方法。 而假如我们要进行一个操作,订单取消,那么最常见的做法是什么?
//一个大而全的订单服务类
public class OrderService{
public void cancelOrder(Long orderId){
Order order = orderRepository.getById(orderId);
order.setStatus(OrderStatus.CANCELLED);
//省略,其他属性的操作...
}
}
//然后在上层(如Controller层)中这么调用
orderService.cancelOrder(10086);
这是目前行业中非常流行的做法,也是Spring的IOC机制天然形成的做法————尽可能的无状态化。这种做法,在业务迭代时对代码的变动评判标准相对简单,都往Service里放就行了,然后实体对象只需要GetSet即可,简单粗暴,非常容易上手,也正是这种特性,让这种编码风格广为流传。
以上这些话没有任何贬义,因为任何事情,存在即合理,我所经历的公司项目,几乎都是这样做的,大家合作起来没多大问题,业务也都还跑得不错。
那为什么我还想去做一些改变呢?
实体Entity的世界
因为我觉得我们需要再重新审视一下实体Entity
实体为什么要有主键? 因为没有主键,那我们怎么知道时要查询/修改哪条数据呢?
这个回答没有问题,只是这句话里其实还蕴藏更深的含义
- 这个实体是一个真实存在的东西(对,哪怕它看不见摸不着,但也是存在的),而且会以一种形态被“存储/持久化”在一个存储介质里,比如说数据库;
- 当我们需要对某个实体进行操作时,我们需要通过一种手段将它“加载/读取/获得”出来,就像你取快递时,快递员根据你提供的编号,从包裹里把那个东西取出来,完全一样;
- 取出来了怎么办?那自然就是要对它进行操作了。没错,这个操作,就是对我们找出来的实体进行操作,而不是别的东西。
所以,从“拿取”,到“操作”,这两步,一切顺理成章,行云流水,所以,以领域驱动设计的做法,或者说,充血模型的做法,会是这样:
//应用层入口类,这里以Controller为例
public class OrderController{
@PostMapping("/cancel")
@Transactional
public ActionResponse cancelOrder(@RequestBody CancelOrderRequest request){
//拿取:根据标识符定位到我们要操作的实体
Order order = orderRepository.getById(request.getOrderId());
//操作:对,没错,说的就是你 order,就是对你,进行操作,不是别人!
order.cancel();
//返回结果
return ActionResponse.ok();
}
}
//真正的业务逻辑,就是在Order实体里
@Entity
public class Order{
private OrderStatus status;
private String customerName;
//...
public void cancel(){
//变更状态
status = OrderStatus.CANCELLED;
//一些其他属性变动,略
}
}
好,依旧有不少值得探讨的地方:
- 我们这里直接在Controller中就开启了Transactional,可能看起来有点反常规,但我个人觉得没什么问题,除了有点不习惯,仔细想想,本身都只不过是Spring的一种组件而已
- 所以如果你用的诸如Hibernate之类的JDBC框架,可以无需再进行多余的类似save操作,这也更好的提现了领域设计的思想,因为这时,这个order就是一个实实在在被我们找出来的实体,对它的改动,自动映射到底层持久化,很自然,也必然。
最更容易引发槽点的地方,就是order.cancel(),也就是充血模型的精髓,将行为定位到一个实体类上,而不是不加思考地直接扔进OrderService里。
业界一直有一种非常“美妙”地说法,曾经我一度非常向往,就是“让代码成诗”。 换句话说,就是既然追求可读性,那么我们要尽可能的让代码天然具有一种“主谓宾”的感觉,就拿上面“取消订单”做比方,我们是否会觉得:
订单好端端的在那里放着,它自己又不能对自己做什么,自然应该“别人”对他进行了操作:
OrderService.cancel(orderId);
某某某 取消了 这个订单
Perfect! 这样读起来,才非常通顺,可读性才更好!
我曾经也是这种风格死忠,而Spring广为流传的无状态架构模式也将这种风格发扬光大。 只是我现在,在经历了越来越多复杂业务,长事务的开发需求后,越来越觉得,这个还有有些硬伤
-
如果一定要读得通畅,更应该是someOperator.cancel(orderId)即某个操作人取消了订单,而不是OrderService,谁都知道OrderService就是一个无状态的代码大集合,一个冰冷的代码而已。但显然someOperator.cancel(orderId)这种做法也是更加不可能实现的,原因就不用过多解释了。
-
order.cancel(),只有2个部分,{操作目标是谁}.{做了什么事情},清晰明了,言简意赅。我相信绝大多数人的阅读习惯也都是从左往右,那么视线第一下扫到的目标一定是最左边的执行对象,也就是order,那么可以在第一时间明确,这个行为是发生在谁身上,而如果是orderService.cancel(orderId),无形中,orderService是一个占据了视线最有力位置的一个巨大的噪点——因为它没有任何的业务意义,你要看的,反而是后面的方法和参数,这在阅读上百行甚至几百行的复合长业务的时候,你会很快困顿,迷失方向。很多时候,我们真的不是技术不达,而是身心疲惫。