1 概述
1.1 背景介绍
仓颉编程语言作为一款面向全场景应用开发的现代编程语言,通过现代语言特性的集成、全方位的编译优化和运行时实现、以及开箱即用的 IDE工具链支持,为开发者打造友好开发体验和卓越程序性能。
案例结合代码体验,让大家更直观的了解仓颉语言中的函数。
1.2 适用对象
1.3 案例时间
本案例总时长预计50分钟。
1.4 案例流程
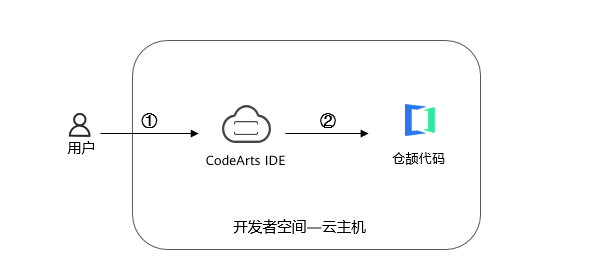
![906c40886d39683ae28c7669a8f5aba9.png]()
说明:
① 进入华为开发者空间,登录云主机;
② 使用CodeArts IDE for Cangjie编程和运行仓颉代码。
1.5 资源总览
| 资源名称 |
规格 |
单价(元) |
时长(分钟) |
| 开发者空间 - 云主机 |
鲲鹏通用计算增强型 kc2 | 4vCPUs | 8G | Ubuntu |
免费 |
50 |
最新案例动态,请查阅 仓颉之函数的魔法宝典。小伙伴快来领取华为开发者空间,进入云主机桌面版实操吧!
2 运行测试环境准备
2.1 开发者空间配置
面向广大开发者群体,华为开发者空间提供一个随时访问的“开发桌面云主机”、丰富的“预配置工具集合”和灵活使用的“场景化资源池”,开发者开箱即用,快速体验华为根技术和资源。
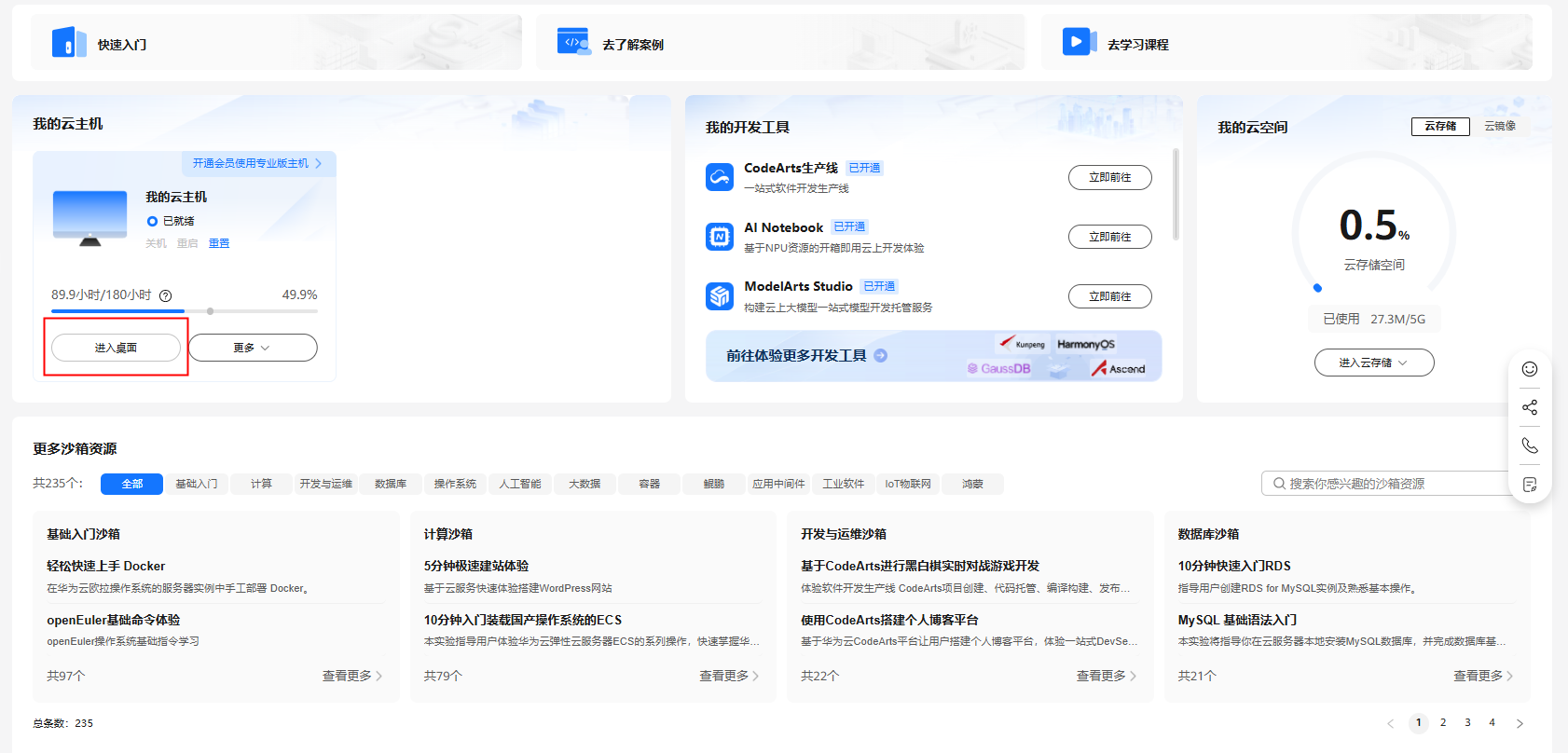
领取云主机后可以直接进入华为开发者空间工作台界面,点击进入桌面连接云主机。没有领取在开发者空间根据指引领取配置云主机即可,云主机配置参考1.5资源总览。
![2427bdcdb98bfd50840ca130685be10a.PNG]()
![552fc96c3b58a06e294e4a760ae719e3.PNG]()
2.2 创建仓颉程序
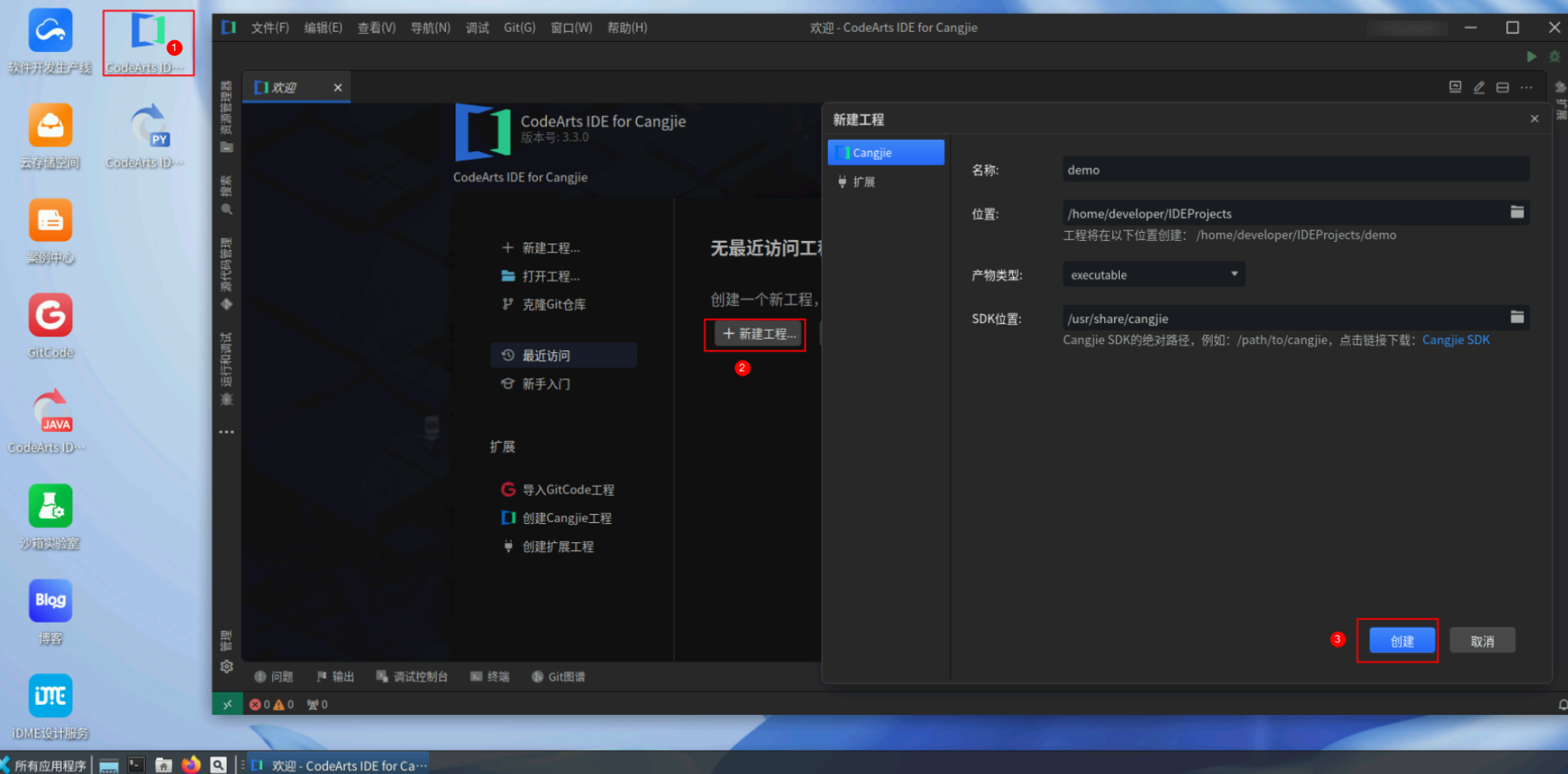
点击桌面CodeArts IDE for Cangjie,打开编辑器,点击新建工程,保持默认配置,点击创建。
产物类型说明:
- executable,可执行文件;
- static,静态库,是一组预先编译好的目标文件的集合;
- dynamic,动态库,是一种在程序运行时才被加载到内存中的库文件,多个程序共享一个动态库副本,而不是像静态库那样每个程序都包含一份完整的副本。
![28acbca9146a8a6aacbfdd4f6ac3791b.png]()
2.3 运行仓颉工程
创建完成后,打开src/main.cj,参考下面代码简单修改后,点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
package demo
// 第一个仓颉程序
main(): Int64 {
println("hello world")
println("你好,仓颉!")
return 0
}
(* 注意:后续替换main.cj文件代码时,package demo保留)
(* 仓颉注释语法:// 符号之后写单行注释,也可以在一对 /* 和 */ 符号之间写多行注释)
![d1e16b48f5f9620fafe9fc59ae62a367.png]()
到这里,我们第一个仓颉程序就运行成功啦!后面案例中的示例代码都可以放到main.cj文件中进行执行,接下来我们继续探索仓颉语言。
3 仓颉中的函数
3.1 定义函数
仓颉使用关键字 func 来表示函数定义的开始,func 之后依次是函数名、参数列表、可选的函数返回值类型、函数体。
函数定义举例,具体代码如下:
// 定义了一个名为add的函数
// 参数列表由两个Int64类型的参数a和b组成
// 函数返回值类型为Int64
// 函数体中将a和b相加并返回
func add(a: Int64, b: Int64): Int64 {
return a + b
}
main():Int64 {
return 0
}
参数列表:
一个函数可以有0个或者多个参数。根据函数调用时是否需要给定参数名,可以将参数列表中的参数分为两类:非命名参数和命名参数。
非命名参数的定义方式是 p: T,其中 p 表示参数名,T 表示参数 p 的类型,参数名和其类型间使用冒号连接。
命名参数的定义方式是 p!: T,与非命名参数的不同是在参数名 p 之后多了一个感叹号!。
非命名参数定义举例,具体代码如下:
// add函数的参数列表,定义了两个非命名参数
// 参数名a,参数类型Int64
// 参数名b,参数类型Int64
func add(a: Int64, b: Int64): Int64 {
return a + b
}
main():Int64 {
return 0
}
命名参数定义举例,具体代码如下:
// add函数的参数列表,定义了两个命名参数
// 命名参数a,参数类型Int64,并设置默认值
// 命名参数b,参数类型Int64,并设置默认值
func add(a!: Int64 = 1, b!: Int64 = 1): Int64 {
return a + b
}
main():Int64 {
return 0
}
非命名参数和命名参数使用注意事项:
- 只能为命名参数设置默认值,不能为非命名参数设置默认值;
- 参数列表中可以同时定义非命名参数和命名参数,非命名参数只能定义在命名参数之前;
- 函数参数均为不可变变量,在函数定义内不能对其赋值。
函数返回值类型:
函数返回值类型是函数被调用后得到的值的类型。函数定义时,返回值类型是可选的:可以显式地定义返回值类型,也可以不定义返回值类型,交由编译器推导确定。
函数返回值类型举例,具体代码如下:
// 定义了一个名为add的函数
// 函数返回值类型为Int64
func add(a: Int64, b: Int64): Int64 {
return a + b
}
main():Int64 {
return 0
}
函数体:
函数体中定义了函数被调用时执行的操作,通常包含一系列的变量定义和表达式,也可以包含新的函数定义(即嵌套函数)。如下 add 函数的函数体中首先定义了 Int64 类型的变量 r(初始值为 0),接着将 a + b 的值赋值给 r,最后将 r 的值返回。
有关函数体的举例,具体代码如下:
func add(a: Int64, b: Int64) {
var r = 0
r = a + b
return r
}
main():Int64 {
return 0
}
3.2 调用函数
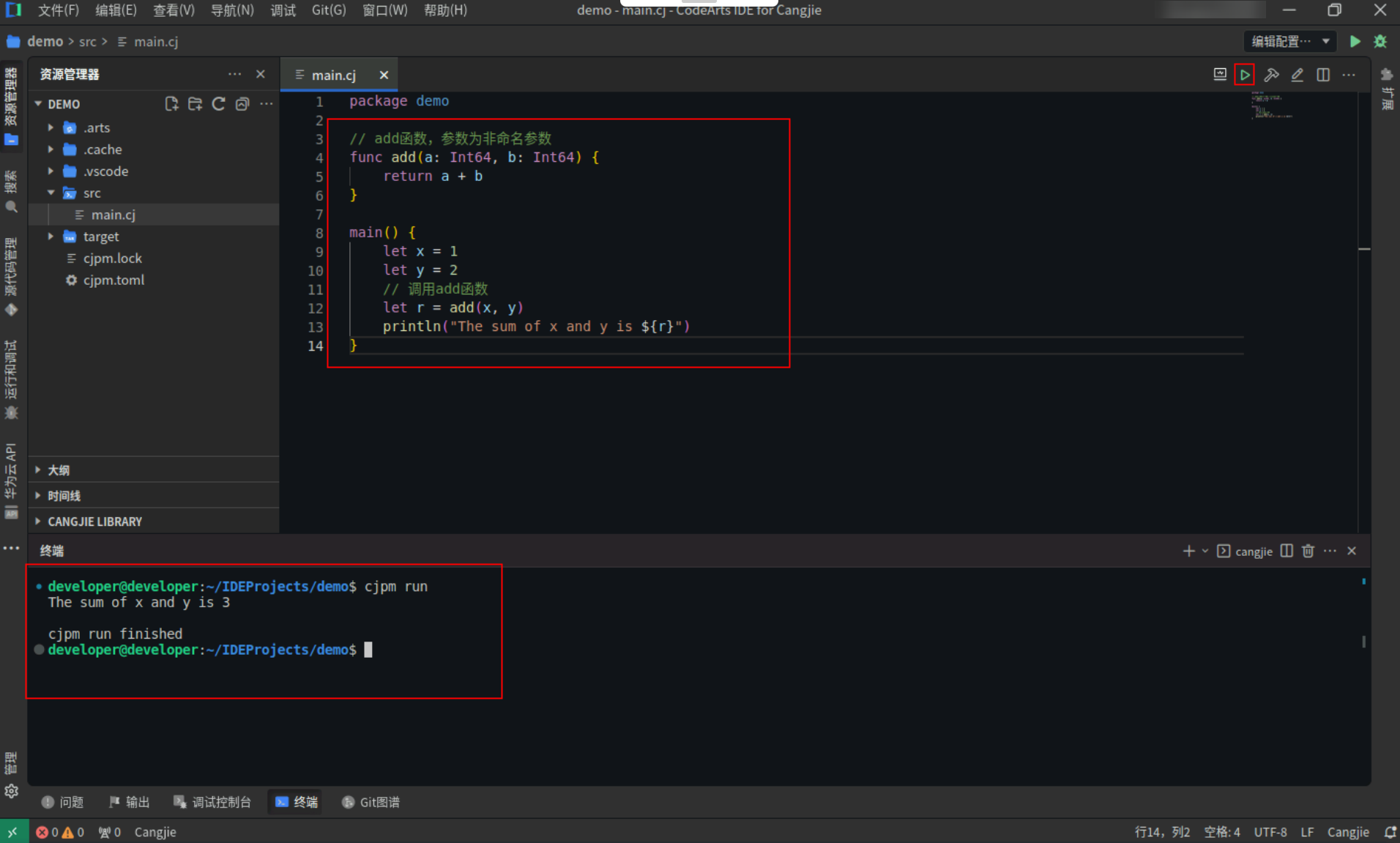
非命名参数调用举例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// add函数,参数为非命名参数
func add(a: Int64, b: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
// 调用add函数
let r = add(x, y)
println("The sum of x and y is ${r}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![f693703102b1102c9cf64baf24041e59.PNG]()
命名参数调用举例,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
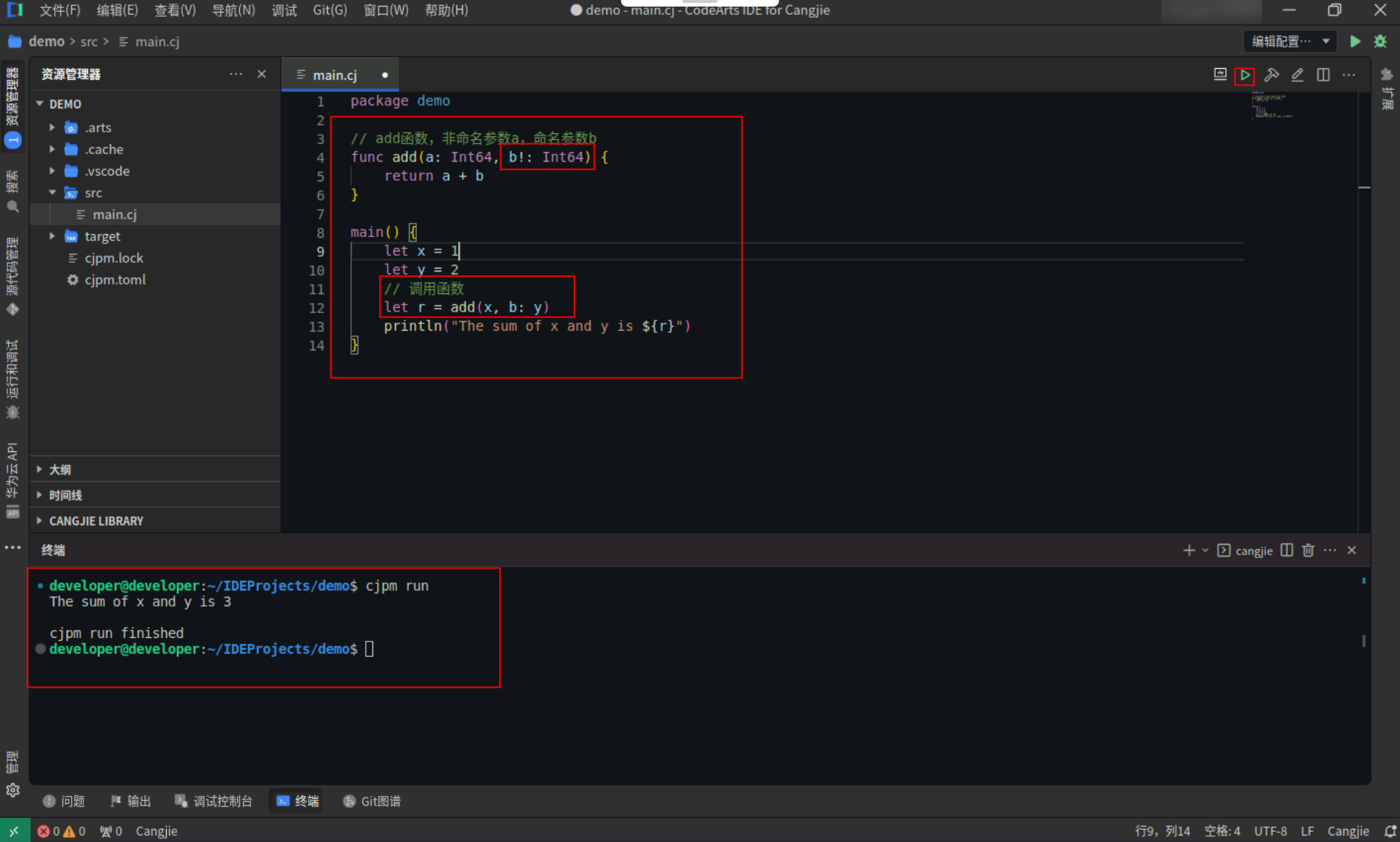
// add函数,非命名参数a,命名参数b
func add(a: Int64, b!: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
// 调用函数
let r = add(x, b: y)
println("The sum of x and y is ${r}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![fd13226cfac37e5e5005ca4ad58a31b7.PNG]()
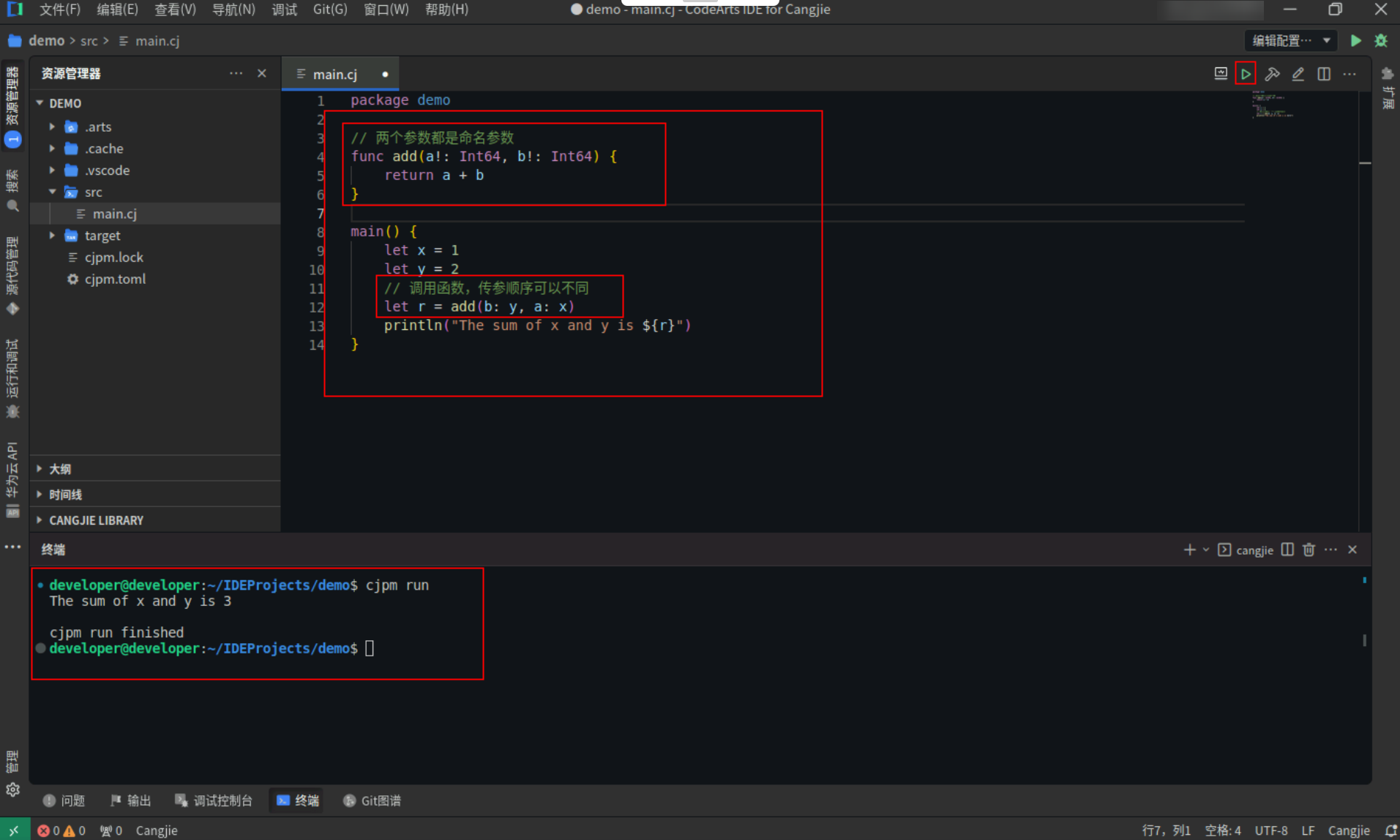
对于多个命名参数,调用时的传参顺序可以和定义时的参数顺序不同。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 两个参数都是命名参数
func add(a!: Int64, b!: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
// 调用函数,传参顺序可以不同
let r = add(b: y, a: x)
println("The sum of x and y is ${r}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![b67bd802b0db7b7c6aa9703f6ce20985.PNG]()
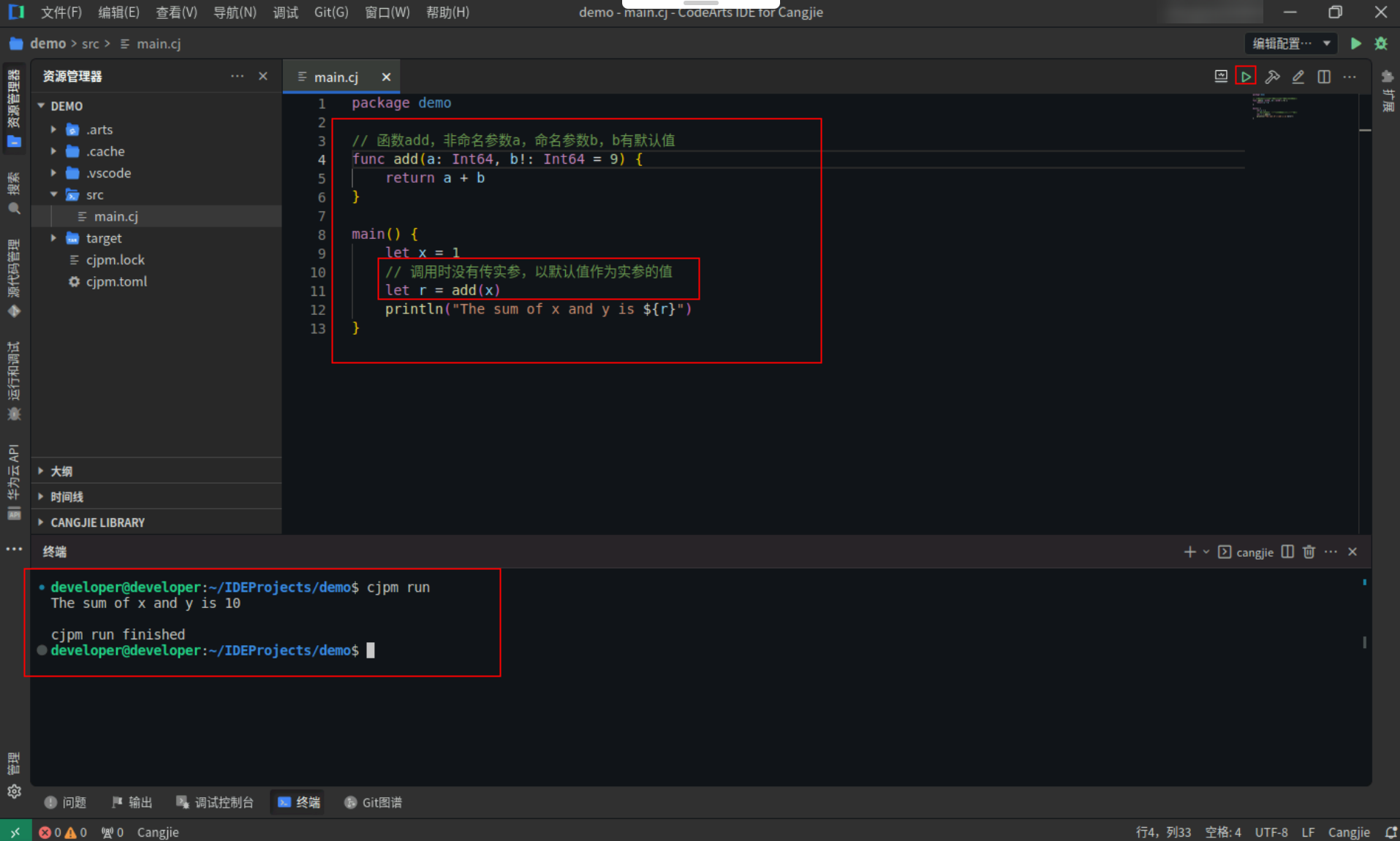
对于拥有默认值的命名参数,调用时如果没有传实参,那么此参数将使用默认值作为实参的值,具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 函数add,非命名参数a,命名参数b,b有默认值
func add(a: Int64, b!: Int64 = 9) {
return a + b
}
main() {
let x = 1
// 调用时没有传实参,以默认值作为实参的值
let r = add(x)
println("The sum of x and y is ${r}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![573c6d0151be931f9cad56ecd6b80a86.PNG]()
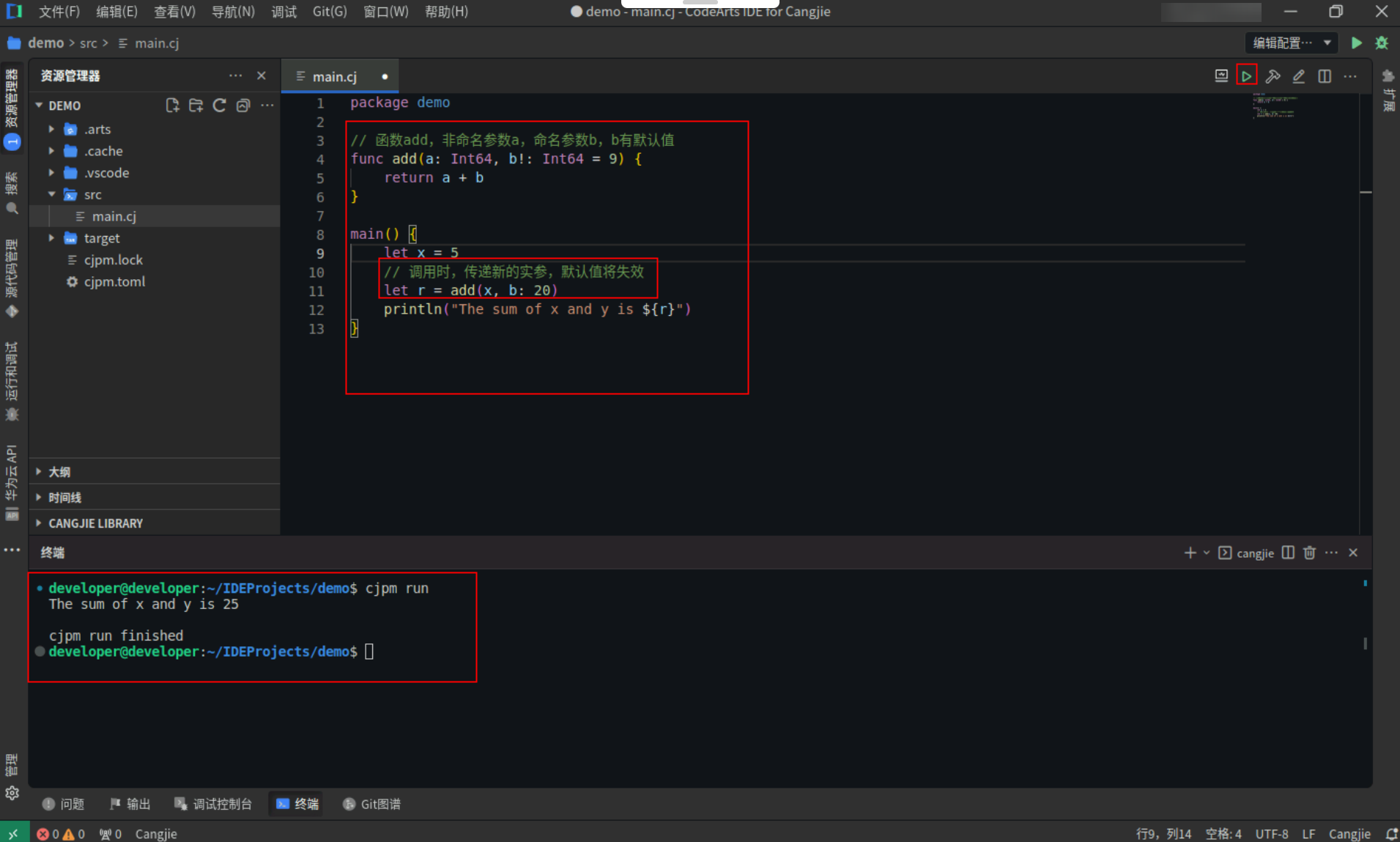
对于拥有默认值的命名参数,调用时也可以为其传递新的实参,此时命名参数的值等于新的实参的值,即定义时的默认值将失效。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 函数add,非命名参数a,命名参数b,b有默认值
func add(a: Int64, b!: Int64 = 9) {
return a + b
}
main() {
let x = 5
// 调用时,传递新的实参,默认值将失效
let r = add(x, b: 20)
println("The sum of x and y is ${r}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![aef8421c3ecd5b0b94a7eb312d5894ff.PNG]()
3.3 函数类型
仓颉编程语言中,函数是一等公民,可以作为函数的参数或返回值,也可以赋值给变量。因此函数本身也有类型,称之为函数类型。
函数类型由函数的参数类型和返回类型组成,参数类型和返回类型之间使用 -> 连接。
函数类型举例,具体代码如下:
func hello(): Unit {
println("Hello!")
}
上述示例定义了一个函数,函数名为 hello,其类型是 () -> Unit,表示该函数没有参数,返回类型为 Unit。
函数类型另外示例,具体代码如下:
func add(a: Int64, b: Int64): Int64 {
a + b
}
函数名为 add,其类型是 (Int64, Int64) -> Int64,表示该函数有两个参数,两个参数类型均为 Int64,返回类型为 Int64。
函数类型的类型参数:
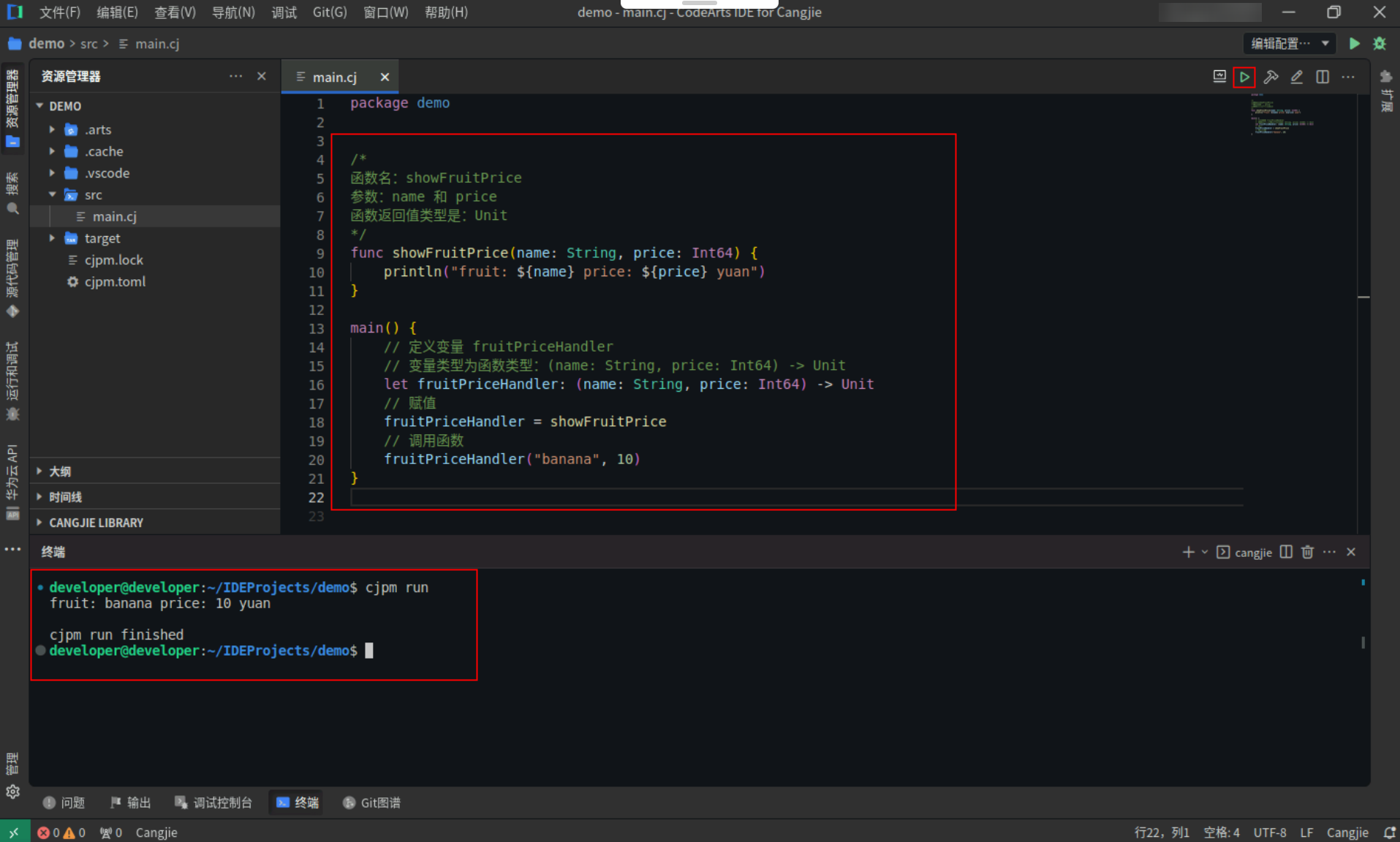
可以为函数类型标记显式的类型参数名,下面例子中的 name 和 price 就是类型参数名。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
/*
函数名:showFruitPrice
参数:name 和 price
函数返回值类型是:Unit
*/
func showFruitPrice(name: String, price: Int64) {
println("fruit: ${name} price: ${price} yuan")
}
main() {
// 定义变量 fruitPriceHandler
// 变量类型为函数类型:(name: String, price: Int64) -> Unit
let fruitPriceHandler: (name: String, price: Int64) -> Unit
// 赋值
fruitPriceHandler = showFruitPrice
// 调用函数
fruitPriceHandler("banana", 10)
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![c12cbb1a05a5bd67819d99e8315118ce.PNG]()
注意:对于一个函数类型,只允许统一写类型参数名,或者统一不写类型参数名,不能交替存在。
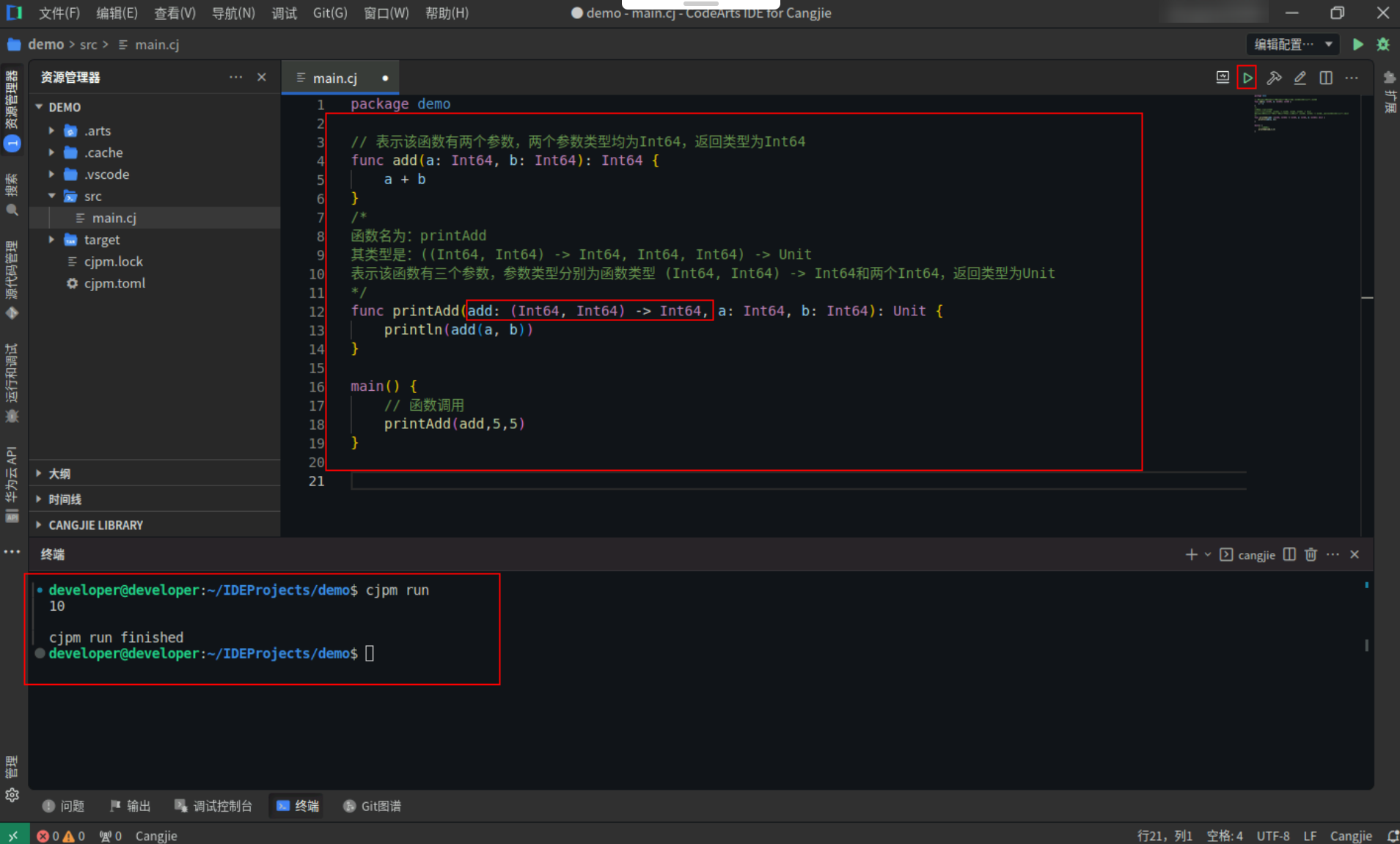
函数类型作为参数类型:
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 表示该函数有两个参数,两个参数类型均为Int64,返回类型为Int64
func add(a: Int64, b: Int64): Int64 {
a + b
}
/*
函数名为:printAdd
其类型是:((Int64, Int64) -> Int64, Int64, Int64) -> Unit
表示该函数有三个参数,参数类型分别为函数类型 (Int64, Int64) -> Int64和两个Int64,返回类型为Unit
*/
func printAdd(add: (Int64, Int64) -> Int64, a: Int64, b: Int64): Unit {
println(add(a, b))
}
main() {
// 函数调用
printAdd(add,5,5)
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![20b50a9b86d5a57c547f4e5ed5d6713b.PNG]()
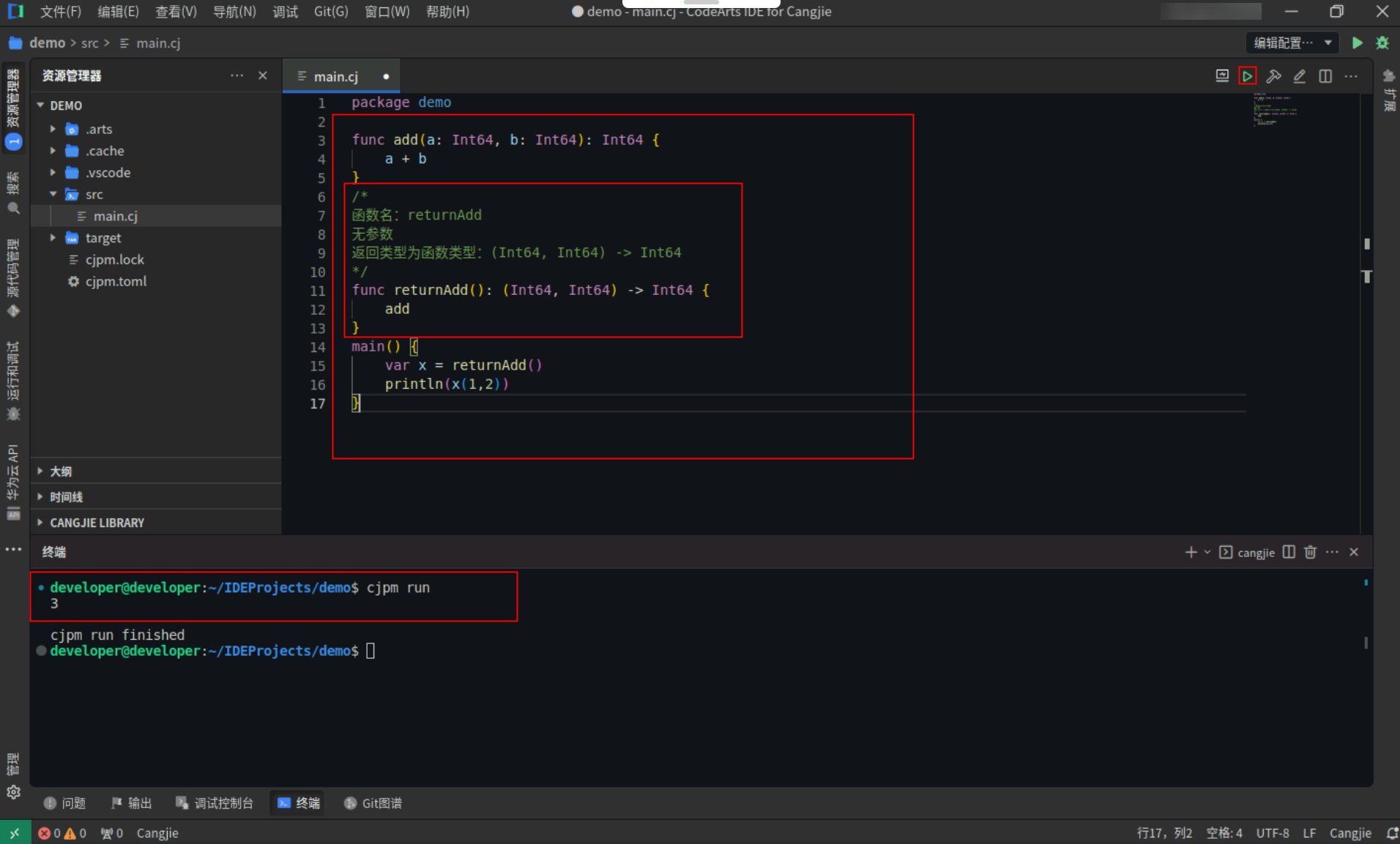
函数类型作为返回值类型:
函数名为 returnAdd,其类型是 () -> (Int64, Int64) -> Int64,表示该函数无参数,返回类型为函数类型 (Int64, Int64) -> Int64。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
func add(a: Int64, b: Int64): Int64 {
a + b
}
/*
函数名:returnAdd
无参数
返回类型为函数类型:(Int64, Int64) -> Int64
*/
func returnAdd(): (Int64, Int64) -> Int64 {
add
}
main() {
var x = returnAdd()
println(x(1,2))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![eb655c71e1efb7e1bb4e270a6c0ba1b3.PNG]()
3.4 嵌套函数
定义在源文件顶层的函数被称为全局函数。定义在函数体内的函数被称为嵌套函数。
函数 foo 内定义了一个嵌套函数 nestAdd,可以在 foo 内调用该嵌套函数 nestAdd,也可以将嵌套函数 nestAdd 作为返回值返回,在 foo 外对其进行调用。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
func foo() {
func nestAdd(a: Int64, b: Int64) {
a + b + 3
}
println(nestAdd(1, 2))
return nestAdd
}
main() {
let f = foo()
let x = f(1, 2)
println("result: ${x}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![89879ec4b8405244b7c321aa47cd6a28.PNG]()
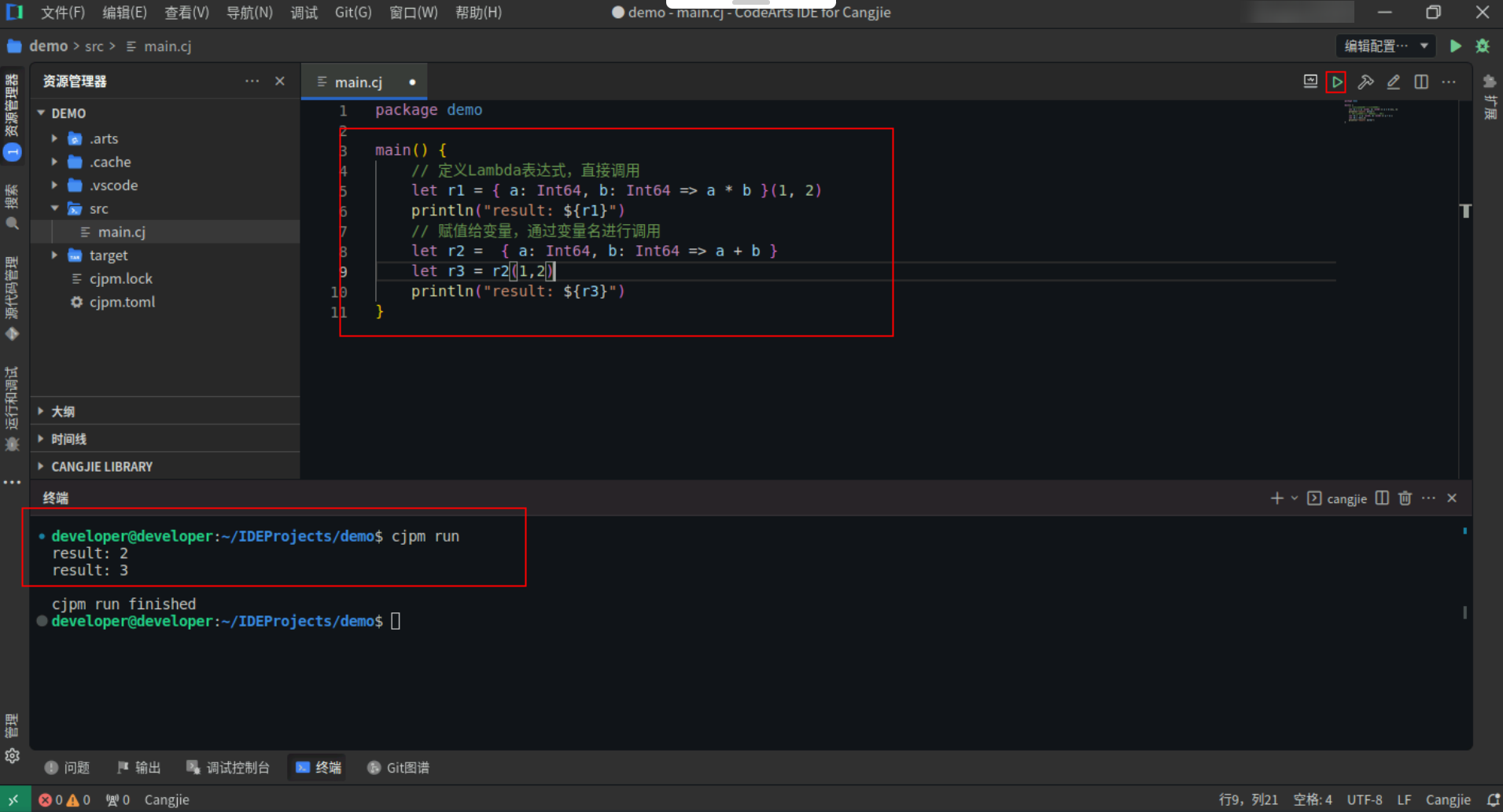
3.5 Lambda表达式
Lambda 表达式定义:
Lambda 表达式的语法为如下形式: { p1: T1, ..., pn: Tn => expressions | declarations }。
其中,=> 之前为参数列表,多个参数之间使用 , 分隔,每个参数名和参数类型之间使用 : 分隔。=> 之前也可以没有参数。=> 之后为 lambda 表达式体,是一组表达式或声明序列。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
main() {
// 定义Lambda表达式,直接调用
let r1 = { a: Int64, b: Int64 => a * b }(1, 2)
println("result: ${r1}")
// 赋值给变量,通过变量名进行调用
let r2 = { a: Int64, b: Int64 => a + b }
let r3 = r2(1,2)
println("result: ${r3}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![f2b715bd0fd285d5c30ab82a164ec0a6.PNG]()
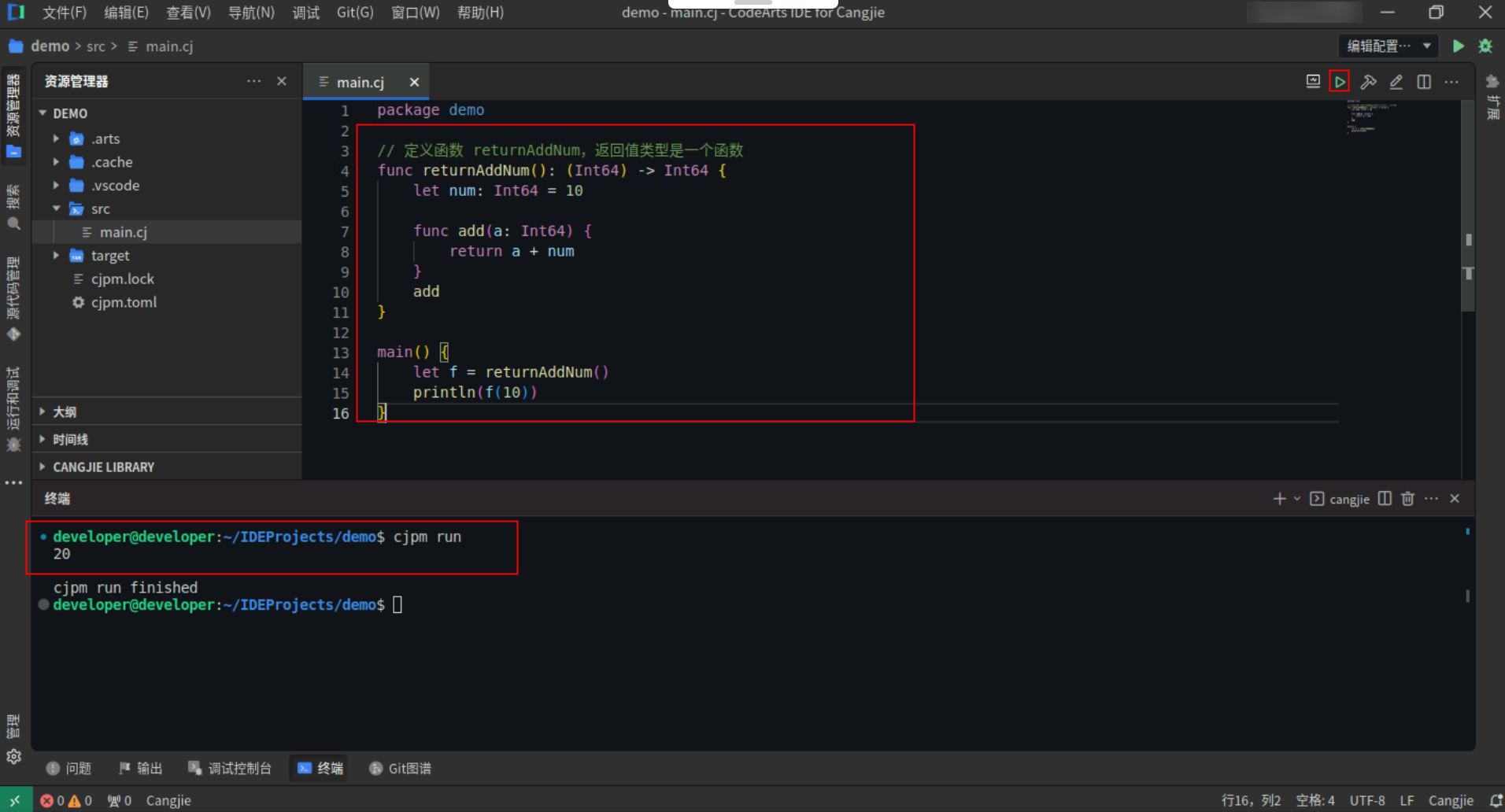
3.6 闭包
一个函数或 lambda 从定义它的静态作用域中捕获了变量,函数或 lambda 和捕获的变量一起被称为一个闭包,这样即使脱离了闭包定义所在的作用域,闭包也能正常运行。
闭包 add,捕获了 let 声明的局部变量 num,之后通过返回值返回到 num 定义的作用域之外,调用 add 时仍可正常访问 num。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 定义函数 returnAddNum,返回值类型是一个函数
func returnAddNum(): (Int64) -> Int64 {
let num: Int64 = 10
func add(a: Int64) {
return a + num
}
add
}
main() {
let f = returnAddNum()
println(f(10))
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![63a8534eaf51cddbd4b33769ab91048f.PNG]()
3.7 函数调用语法糖
流操作符包括两种:表示数据流向的中缀操作符 |> (称为 pipeline)和表示函数组合的中缀操作符 ~> (称为 composition)。
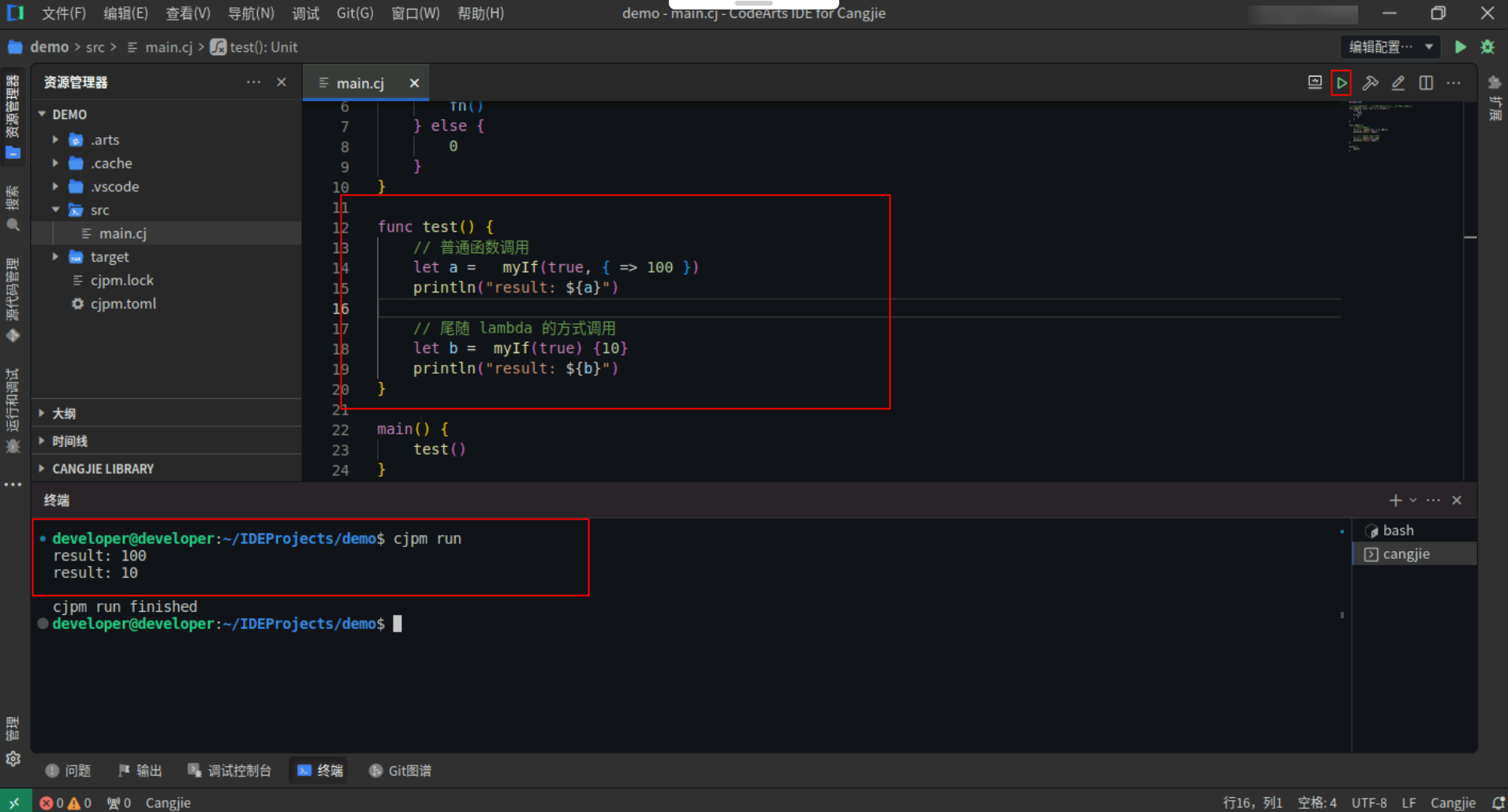
尾随 lambda:
尾随 lambda 可以使函数的调用看起来像是语言内置的语法一样,增加语言的可扩展性。
当函数最后一个形参是函数类型,并且函数调用对应的实参是 lambda 时,可以使用尾随 lambda 语法,将 lambda 放在函数调用的尾部,圆括号外面。
下例中定义了一个 myIf 函数,它的第一个参数是 Bool 类型,第二个参数是函数类型。当第一个参数的值为 true 时,返回第二个参数调用后的值,否则返回 0。调用 myIf 时可以像普通函数一样调用,也可以使用尾随 lambda 的方式调用。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 定义函数myIf,第一个参数是Bool类型,第二个参数是函数类型
func myIf(a: Bool, fn: () -> Int64) {
if(a) {
fn()
} else {
0
}
}
func test() {
// 普通函数调用
let a = myIf(true, { => 100 })
println("result: ${a}")
// 尾随 lambda 的方式调用
let b = myIf(true) {10}
println("result: ${b}")
}
main() {
test()
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![d01c7ffed054052d47d4764bbc7d38b8.PNG]()
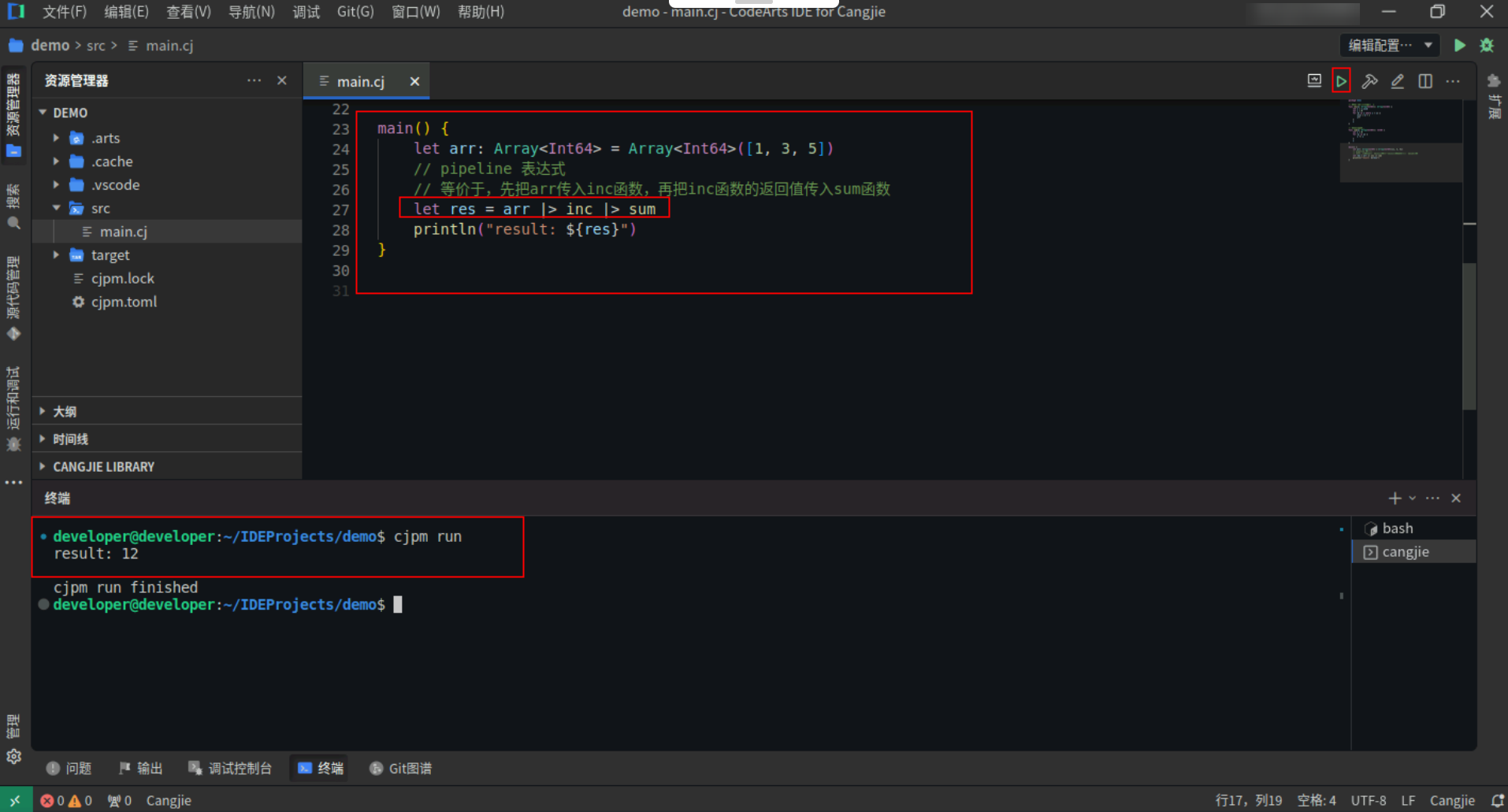
Pipeline表达式:
当需要对输入数据做一系列的处理时,可以使用 pipeline 表达式来简化描述。pipeline 表达式的语法形式如下:e1 |> e2。等价于如下形式的语法糖:let v = e1; e2(v) 。
其中 e2 是函数类型的表达式,e1 的类型是 e2 的参数类型的子类型。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
// 数组中的每个元素都加1
func inc(x: Array<Int64>): Array<Int64> {
let s = x.size
var i = 0
for (e in x where i < s) {
x[i] = e + 1
i++
}
x
}
// 数组元素求和
func sum(y: Array<Int64>): Int64 {
var s = 0
for (j in y) {
s += j
}
s
}
main() {
let arr: Array<Int64> = Array<Int64>([1, 3, 5])
// pipeline 表达式
// 等价于,先把arr传入inc函数,再把inc函数的返回值传入sum函数
let res = arr |> inc |> sum
println("result: ${res}")
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![68b6c7c4be136d376412e5d2081f5f3b.PNG]()
composition表达式:
composition 表达式表示两个单参函数的组合。composition 表达式语法如下: f ~> g。等价于如下形式: { x => g(f(x)) }。
其中 f,g 均为只有一个参数的函数类型的表达式。
f 和 g 组合,则要求 f(x) 的返回类型是 g(...) 的参数类型的子类型。
具体代码如下:
func f(x: Int64): Float64 {
Float64(x)
}
func g(x: Float64): Float64 {
x
}
main() {
// The same as { x: Int64 => g(f(x)) }
var fg = f ~> g
}
3.8 函数重载
函数重载定义?
在仓颉编程语言中,如果一个作用域中,一个函数名对应多个函数定义,这种现象称为函数重载。
具体代码如下:
// 函数名相同,函数参数不同,构成重载
func f(a: Int64): Unit {
}
func f(a: Float64): Unit {
}
func f(a: Int64, b: Float64): Unit {
}
具体代码如下:
// 两个构造函数参数不同,构成重载
class C {
var a: Int64
var b: Float64
public init(a: Int64, b: Float64) {
this.a = a
this.b = b
}
public init(a: Int64) {
b = 0.0
this.a = a
}
}
- 同一个类内的主构造函数和 init 构造函数参数不同,构成重载。
具体代码如下:
// 同一个类内的主构造函数和 init 构造函数参数不同,构成重载
class C {
C(var a!: Int64, var b!: Float64) {
this.a = a
this.b = b
}
public init(a: Int64) {
b = 0.0
this.a = a
}
}
- 两个函数名相同,参数不同的函数定义在不同的作用域,在两个函数都可见的作用域中构成重载。
具体代码如下:
// 两个函数名相同,参数不同的函数定义在不同的作用域,在两个函数都可见的作用域中构成重载
func f(a: Int64): Unit {
}
func g() {
func f(a: Float64): Unit {
}
}
- 如果子类中存在与父类同名的函数,并且函数的参数类型不同,则构成函数重载。
具体代码如下:
// 子类中存在与父类同名的函数,并且函数的参数类型不同,则构成函数重载
open class Base {
public func f(a: Int64): Unit {
}
}
class Sub <: Base {
public func f(a: Float64): Unit {
}
}
函数重载决议
函数调用时,所有可被调用的函数构成候选集,候选集中有多个函数,究竟选择候选集中哪个函数,需要进行函数重载决议,有如下规则:
- 优先选择作用域级别高的作用域内的函数;
- 如果作用域级别相对最高的仍有多个函数,则需要选择最匹配的函数;
- 子类和父类认为是同一作用域,选择更匹配的父类中定义的函数
3.9 const函数
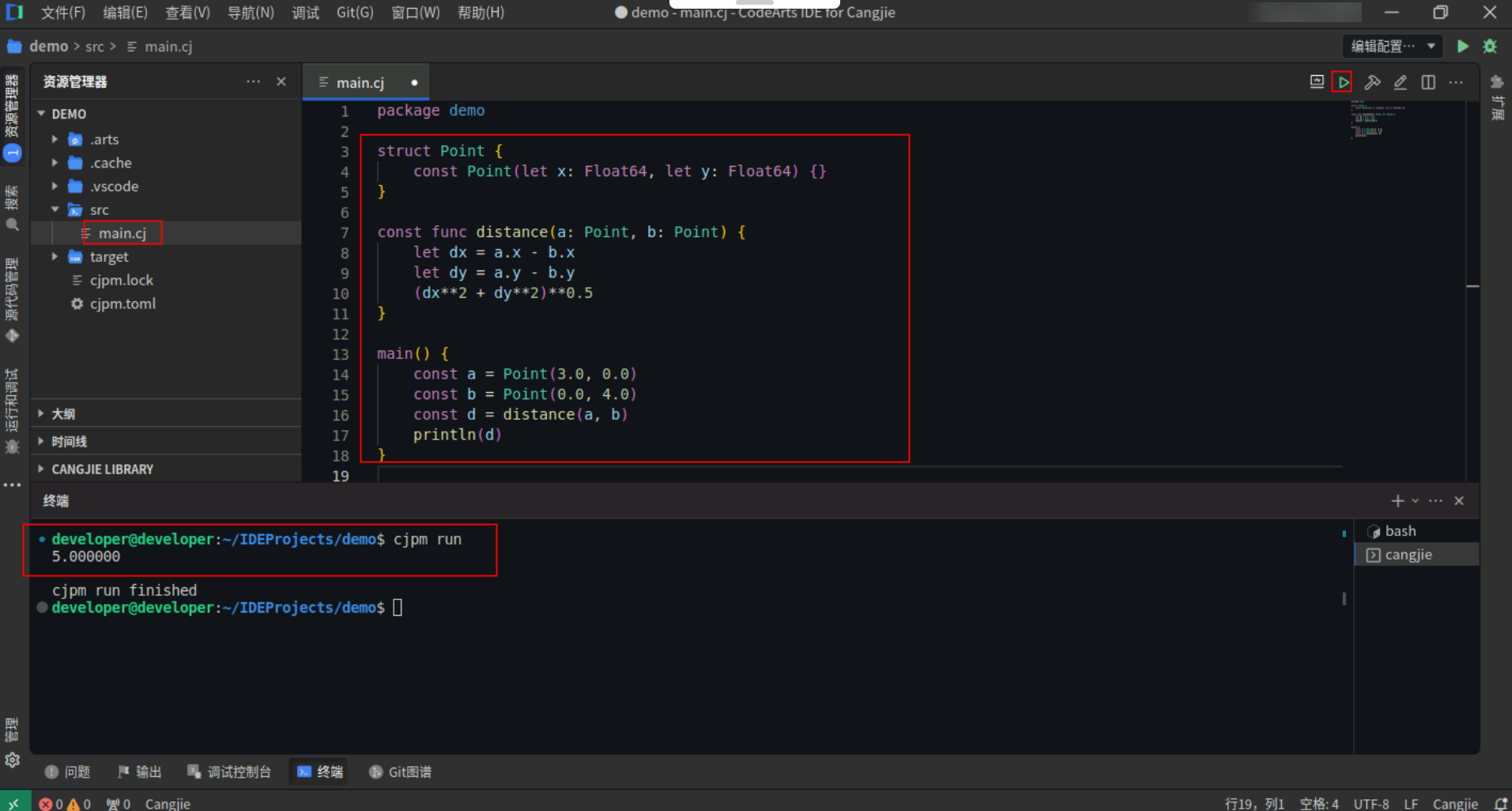
const 函数是一类特殊的函数,这些函数具备了可以在编译时求值的能力。在 const 上下文中调用这种函数时,这些函数会在编译时执行计算。而在其它非 const 上下文,const 函数会和普通函数一样在运行时执行。
下例是一个计算平面上两点距离的 const 函数,distance 中使用 let 定义了两个局部变量 dx 和 dy。
具体代码操作如下:
Step1:复制以下代码,替换main.cj文件中的代码。(保留package)
结构类型struct的定义以关键字struct开头,后跟struct的名字,接着是定义在一对花括号中的 struct 定义体。struct 定义体中可以定义一系列的成员变量、成员属性、静态初始化器、构造函数和成员函数。
struct Point {
const Point(let x: Float64, let y: Float64) {}
}
const func distance(a: Point, b: Point) {
let dx = a.x - b.x
let dy = a.y - b.y
(dx**2 + dy**2)**0.5
}
main() {
const a = Point(3.0, 0.0)
const b = Point(0.0, 4.0)
const d = distance(a, b)
println(d)
}
Step2:点击编辑器右上角运行按钮直接运行,终端窗口可以看到打印内容。
![b8f9b09cc9e2e2f23160ecc8bcd5f215.PNG]()
至此,仓颉之函数的魔法宝典案例内容已全部完成。
如果想了解更多仓颉编程语言知识可以访问:https://cangjie-lang.cn/