作者:来自 Elastic Simon Cooper
在kNN向量搜索中使用重新排序可以提高搜索召回率,但可能会增加延迟。了解如何通过利用 direct IO 来减少这种影响。
通过这个面向 Search AI 的自学动手课程亲自体验向量搜索。你可以现在开始免费云试用,或者在本地机器上试用 Elastic。
在 Elasticsearch 9.0 中,我们为使用量化向量的字段搜索引入了kNN 向量重新排序。虽然重新排序能显著提高召回率,但在某些情况下会大幅增加延迟。为了理解原因,我们将探讨重新排序的作用,以及 Lucene 和操作系统如何管理磁盘上的数据。我们还会解释启用 direct IO 如何影响延迟。
向量重新排序的工作原理
一个 HNSW 量化向量索引会存储:
- 用于在向量空间中导航的 HNSW 图
- 以位形式存储的量化向量数据
- 以 32 位浮点数存储的原始向量数据
当执行近似 kNN 搜索时,会先通过 HNSW 图来找到与搜索向量最接近的 k 个向量,使用的是量化向量数据。如果启用了重新排序,图会默认按 3 倍的比例进行过采样,这意味着会在图中搜索 3k 个量化向量。然后重新排序步骤会使用未量化的原始向量数据,将这 3k 个过采样的量化向量过滤成 k 个最近的向量。
对于每个过采样的量化向量,都会读取原始向量并与搜索向量进行比较,以找到实际最近的 k 个向量,然后将它们从查询中返回。这个操作需要对每个过采样向量在原始向量数据中进行一次随机访问读取。而原始向量数据可能非常大 —— 通常占整个索引的 90%-95%,大小可能是几十 GB,甚至 TB 级别。
为什么页面缓存会成为瓶颈
当操作系统从磁盘(无论是 SSD、NVMe 还是机械硬盘)读取数据时,会将读取的数据副本缓存在 RAM 中,以防再次需要这些数据或其附近的数据。
这通常是以 4KB 的页面进行的,因此称为页面缓存。操作系统会使用系统中所有空闲的 RAM 作为页面缓存。
$ free -m
total used free shared buff/cache available
Mem: 31536 14623 6771 1425 12021 1691
在这个例子中,系统有 32GB RAM,其中 15GB 被正在运行的程序使用,12GB 被页面缓存和其他缓冲区使用。
因此,为了从磁盘读取数据,操作系统首先会将所请求的相关页面从磁盘复制到内存中,然后这些数据才能被正在运行的程序访问。
如果没有足够的空闲 RAM 来存储刚读取的页面,页面缓存中的现有页面就会被驱逐,新页面会替换它。
但应该驱逐哪个页面呢?这是一个由来已久的软件工程问题 —— 缓存失效。现代操作系统在判断哪些页面未来不太可能被使用方面已经做得相当不错,但它们(目前)无法预测未来。向量重新排序的随机访问模式是完全不可预测的,这让操作系统只能猜测应该驱逐哪个页面。
这是个问题。过采样向量的原始向量数据可能位于索引的任何位置,并且根据 k 的不同,可能需要读取很多页面。这可能意味着操作系统在重新排序过程中需要驱逐大量页面 —— 包括那些存有 HNSW 图的页面。
$ sar -B 1
pgpgin/s pgpgout/s fault/s majflt/s
112099.20 16493.60 11562.00 10761.60
这会造成大量的缺页中断。
操作系统并不知道这些页面是用来做什么的,或者它们里面有什么。它也不知道 HNSW 图在该索引的每次向量查询开始时都会被使用。对操作系统来说,这些只是磁盘上的字节,加上一些之前访问时间的信息。
如果 HNSW 图的页面被驱逐,那么在下一次向量查询时,部分或全部页面都需要重新加载。而磁盘访问时间相比内存访问时间要长得多 —— NVMe 需要几十微秒,SSD 需要几百微秒,HDD 则可能需要几毫秒。
这导致当向量数据大到无法完全放进页面缓存时,操作系统会在每次查询时交换出页面——造成查询性能急剧下降,因为它不断在 HNSW 图和原始向量之间切换。额外增加几 GB 的向量数据就可能让查询延迟增加 100 倍,甚至更多。
Direct IO 来拯救
那么该怎么办?页面缓存是由操作系统控制的,不是 Elasticsearch 控制的 —— 那我们能做什么吗?幸运的是,我们可以。除了向操作系统提供一些关于读取数据用途的提示(操作系统可以选择使用或忽略)外,我们还可以告诉操作系统完全绕过页面缓存,每次访问都直接从磁盘读取。这叫做 “direct IO”。
显然,这比从 RAM 中已缓存的页面读取要慢得多,但它避免了为了存储新页面而驱逐页面缓存中的现有页面。更重要的是,这让操作系统可以把 HNSW 图保留在内存中,放在它应该在的位置。
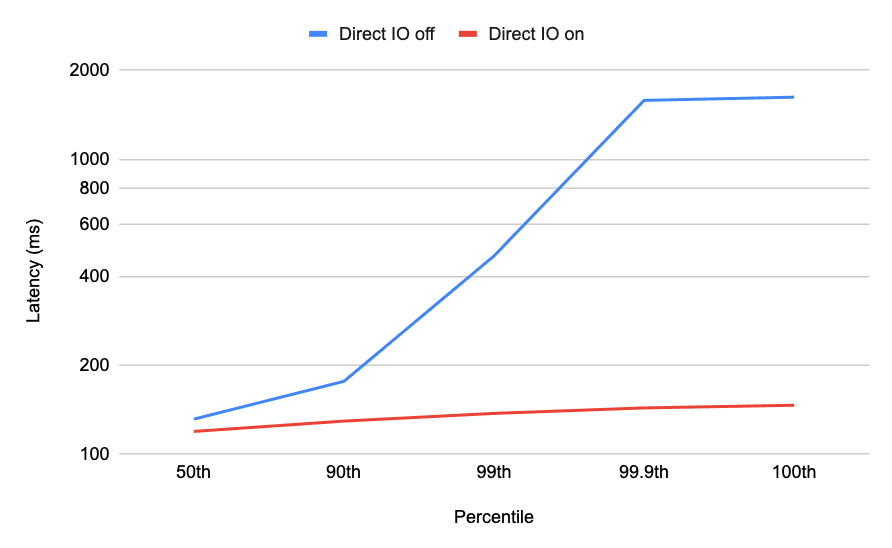
在低内存场景下,direct IO 对搜索延迟的改善非常显著(注意这里是对数刻度):
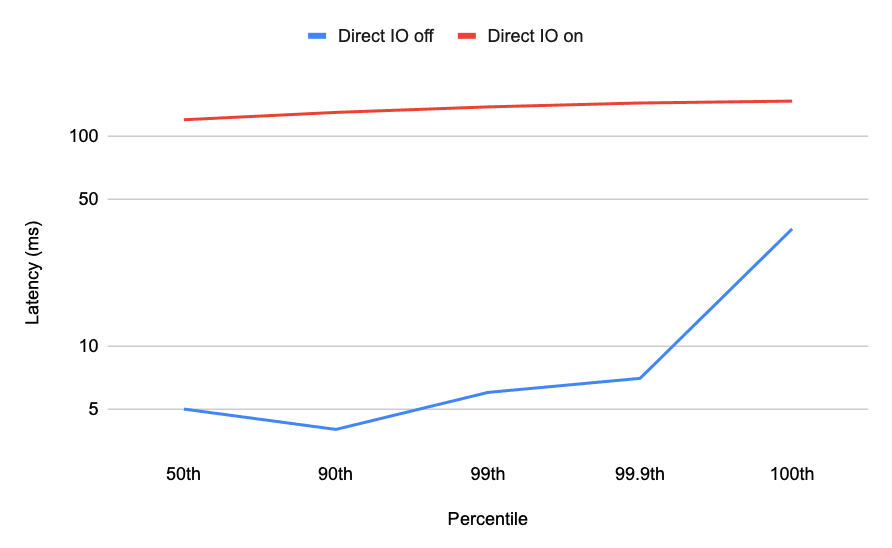
然而,这也是有代价的。由于 direct IO 会强制绕过页面缓存,当内存足够存储所有向量数据时启用 direct IO 会导致速度大幅下降:
理想情况下,我们希望检测到向量数据何时在页面缓存中交换,但在 JVM 内部的工具中这很难做到。我们正在努力,但还没实现。
什么时候(和什么时候不)启用 direct IO?
如你所见,当向量数据大到超过 RAM 容量时开启 direct IO 可以显著降低 kNN 向量搜索的高延迟。但当内存足够时开启 direct IO 会导致性能大幅下降。
从 Elasticsearch 9.1 开始,你可以在 bbq_hnsw 索引上使用 direct IO 进行向量重新排序。当前默认关闭,因为在内存充足时可能导致性能下降。
如果你的向量搜索延迟很高,可以尝试添加 JVM 选项-Dvector.rescoring.directio=true,启用 bbq_hnsw 索引上所有重新排序的 direct IO。
我们正在探索未来以不同方式暴露这个选项,并评估未来 Elasticsearch 版本的性能差异。
如果你发现它提升了你的向量搜索性能,请告诉我们!
注意Elasticsearch 9.1.0 存在一个已知问题,direct IO 默认开启,这将在 Elasticsearch 9.1.1 中修复。我们会继续评估 direct IO 的使用及未来可能的应用方式。
原文:Using Direct IO for vector searches - Elasticsearch Labs