OpenAI 宣布在 Apache 2.0 协议下开源两款轻量级语言模型 —— gpt-oss-120b 和 gpt-oss-20b,可在低成本下实现强大的实际应用性能。这是自2019年GPT-2发布以来,OpenAI 首次回归开源领域。
“一个健康开放的模型生态系统,是实现 AI 广泛普及并惠及所有人的重要维度。我们正在发布自己的开放模型,以探索我们如何为这一生态系统做出贡献,以及这些模型的优势和好处是否值得 OpenAI 在未来投资于开放模型。”
该公司表示,与同等规模的开放模型相比,这两款模型在推理任务中表现更优,展现出强大的工具使用能力,并针对在消费级硬件上高效部署进行了优化。它们通过强化学习与 OpenAI 最先进内部模型(包括 o3 及其他前沿系统)所启发的技术相结合进行训练。
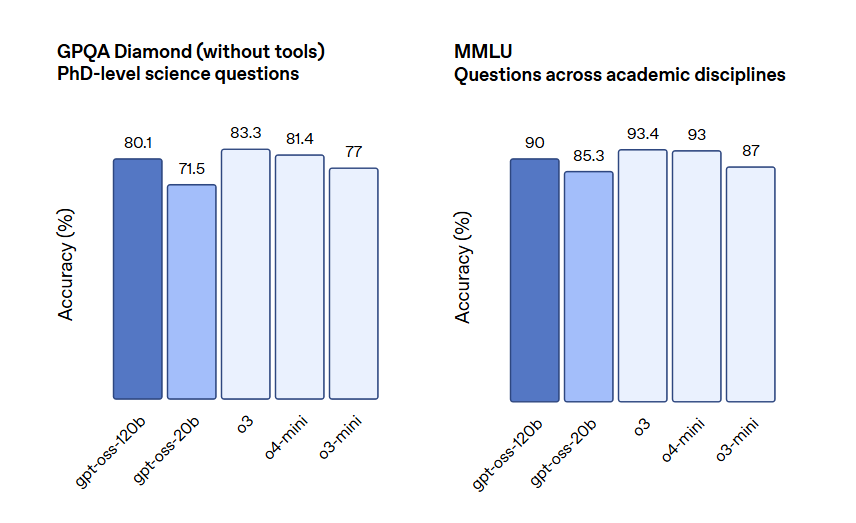
公告称,Gpt-oss-120b 模型在核心推理基准测试中与 OpenAI o4-mini 模型几乎持平,同时能在单个 80GB GPU 上高效运行。Gpt-oss-20b 模型在常见基准测试中与 OpenAI o3‑mini 模型取得类似结果,且可在仅配备 16GB 内存的边缘设备上运行,使其成为设备端应用、本地推理或无需昂贵基础设施的快速迭代的理想选择。
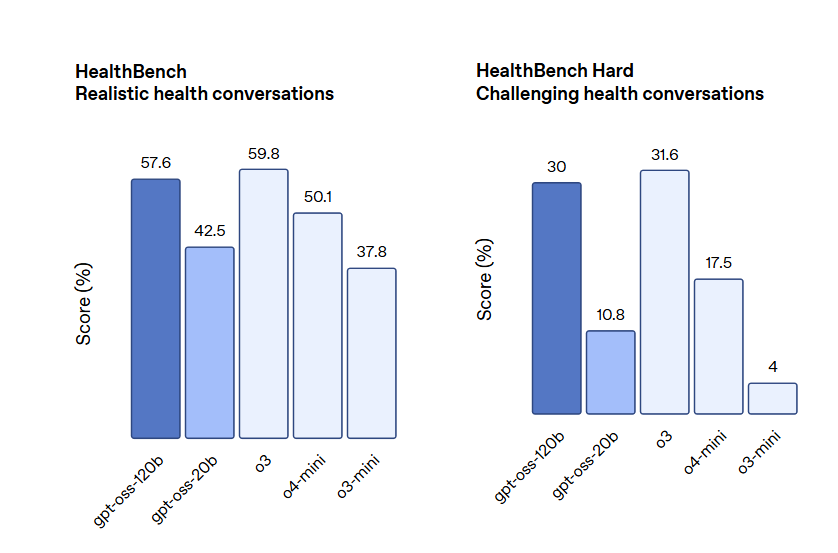
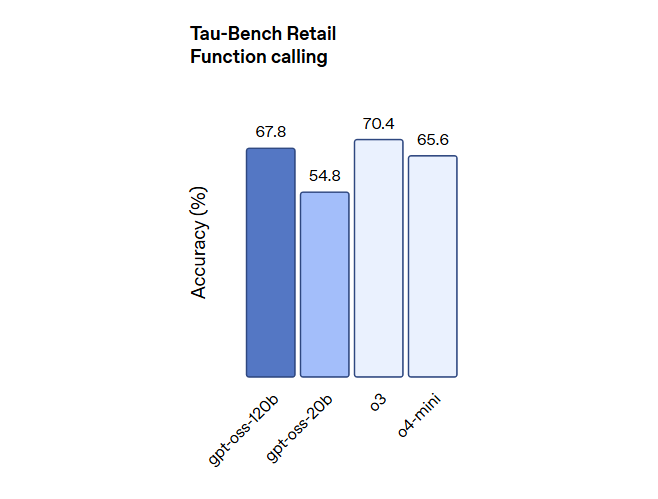
在工具使用、少样本函数调用、CoT推理(如在 Tau-Bench 智能体评估套件中的结果所示)以及 HealthBench 测试中也表现强劲(甚至超越了 OpenAI o1 和 GPT‑4o 等专有模型)。
“这些模型与我们的回复 API兼容,并专为在智能体工作流中使用而设计,具备卓越的指令执行能力、工具使用能力(如网页搜索或 Python 代码执行)以及推理能力——包括根据任务需求调整推理力度的能力,尤其适用于无需复杂推理且/或需要极低延迟最终输出的任务。它们完全可定制,提供完整的思维链 (CoT),并支持结构化输出。”
此外,OpenAI 还提到了“安全”这一核心原则。“我们还通过在我们的《防范准备框架》下测试一个经过对抗性微调的 gpt-oss-120b 版本,引入了额外的评估层。Gpt-oss 模型在内部安全基准测试中的表现与我们的前沿模型相当,为开发者提供了与我们近期专有模型相同的安全标准。”
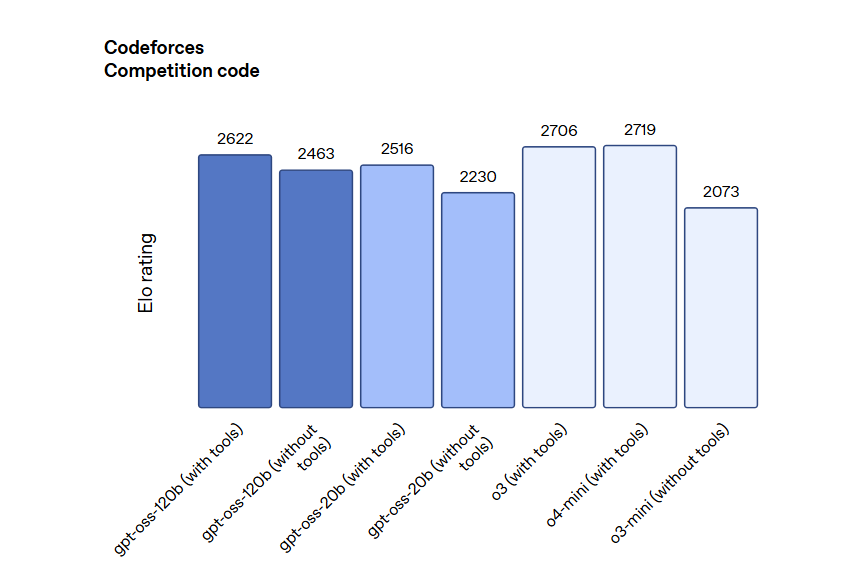
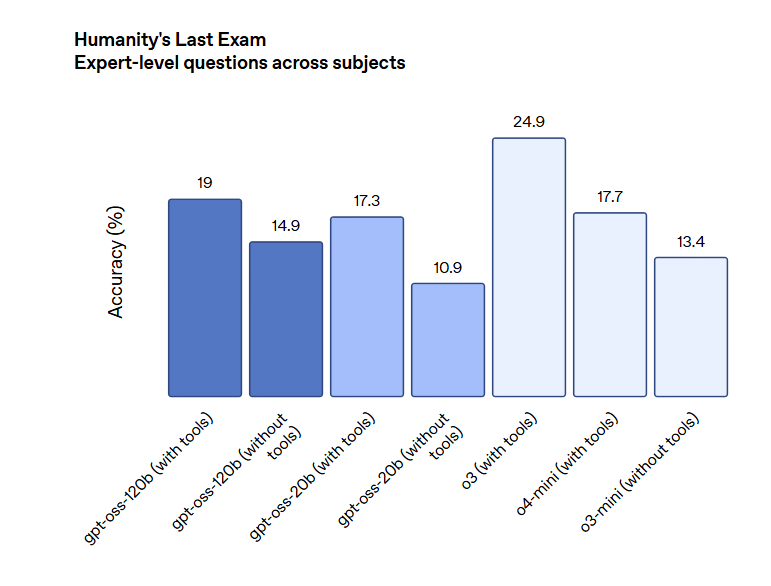
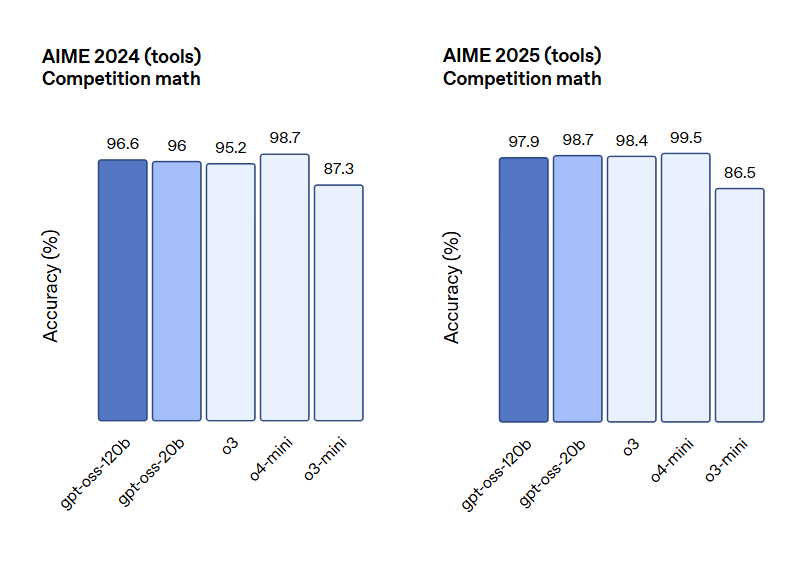
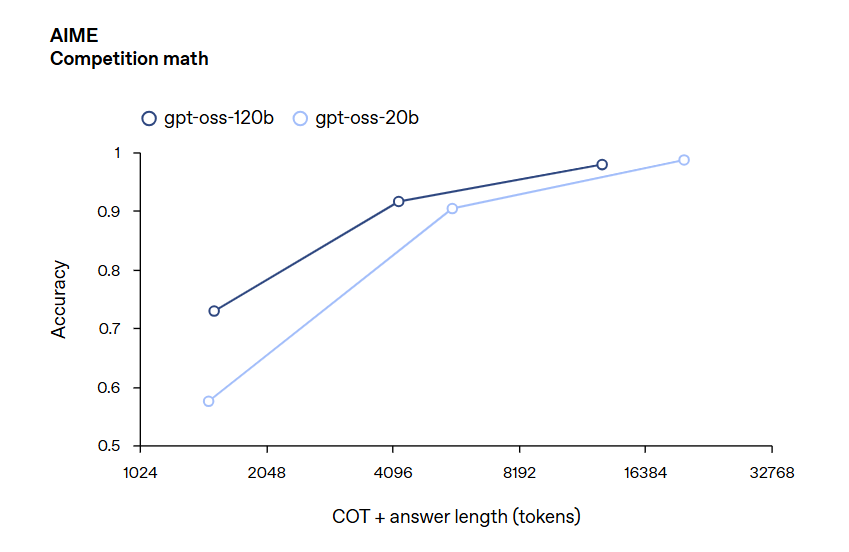
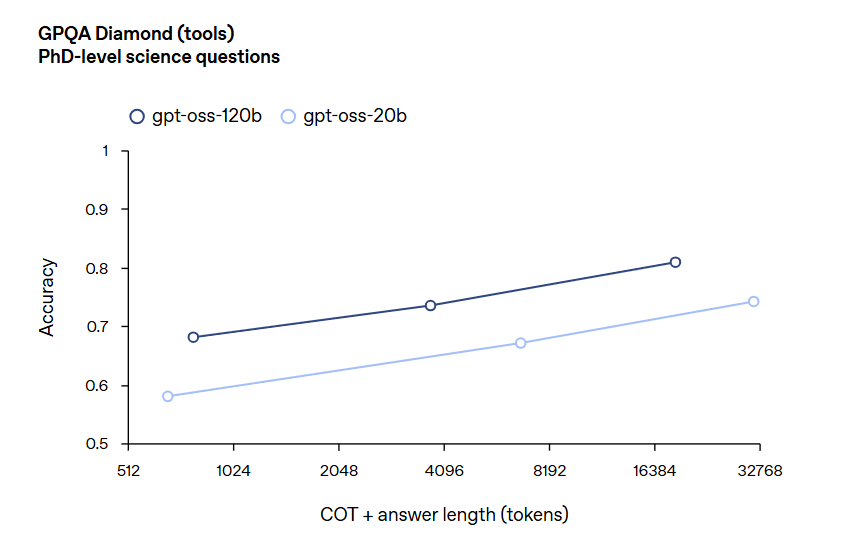
测评结果表明,Gpt-oss-120b 在竞赛编程 (Codeforces)、通用问题解决 (MMLU 和 HLE) 以及工具调用 (TauBench) 方面表现优于 OpenAI o3‑mini,并与 OpenAI o4-mini 持平或超越其性能。在健康相关查询 (HealthBench) 和竞赛数学 (AIME 2024 和 2025) 方面表现得比 o4-mini 更好。尽管 gpt-oss-20b 的规模较小,但在这些相同的评估中,它与 OpenAI o3‑mini 持平或超越后者,甚至在竞赛数学和医疗方面表现得更好。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
此外,作为此次更新的一部分,微软还为 Windows 设备推出了 GPU 优化版的 gpt-oss-20b 模型。这些模型基于 ONNX Runtime,支持本地推理,并可通过 Foundry Local 和 VS Code AI 工具包获取,使得 Windows 开发者更容易使用开放模型进行开发。
更多详情可查看官方公告。