大模型作为数据库管理的新界面
现代大型语言模型(LLM)本质上是一个经过深度训练的智能知识库,其显著特征包括:
- 全领域知识覆盖:内化了包括MySQL、PostgreSQL、MongoDB等各类数据库系统的完整知识体系
- 语义理解能力:能够准确解析技术术语和自然语言混合表达的查询意图
- 上下文感知:可结合对话历史理解复杂的多轮操作请求
通过专用工具链的增强,我们能够实现:
- 无代码数据库操作:用户只需用日常语言描述需求,系统自动生成专业级SQL语句
- 智能运维建议:基于数据库状态分析,提供索引优化、查询调优等专业建议
- 多模态交互:支持语音输入、文本对话等多种交互方式
这里我们就以VS Code(Visual Studio Code)和当前热门的MCP(Model Context Protocol)技术为例,体验一下使用自然语言来操作MySQL数据库。
安装配置
安装 VS Code和Cline插件
首先需要安装VS Code,到官网下载安装包(链接如下👇🏻)。这里我使用了macOS版本的。
https://code.visualstudio.com
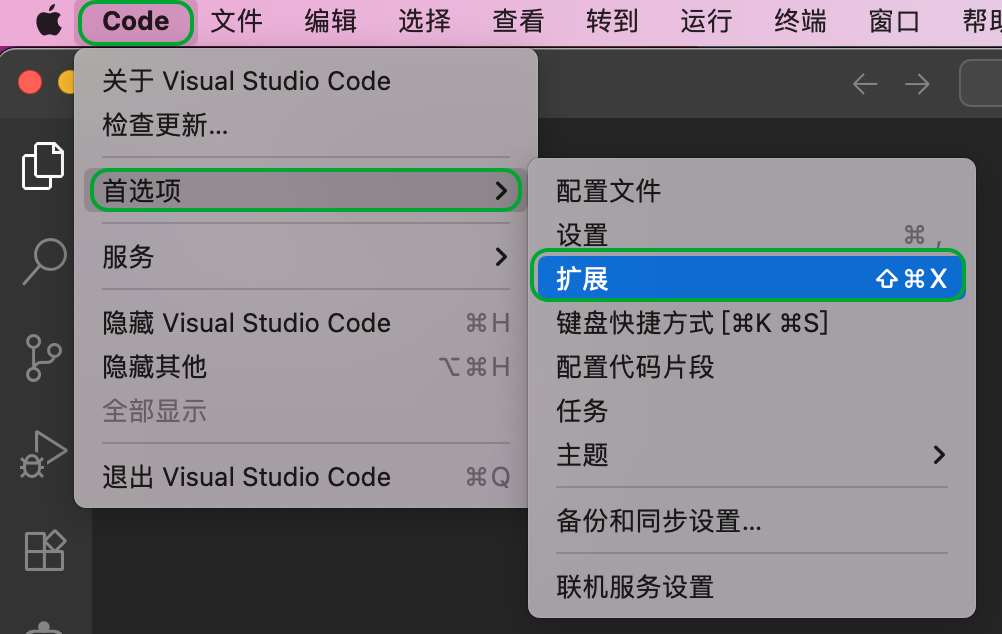
VS Code安装之后,需要安装Cline插件。打开首选项 -> 扩展。
![]()
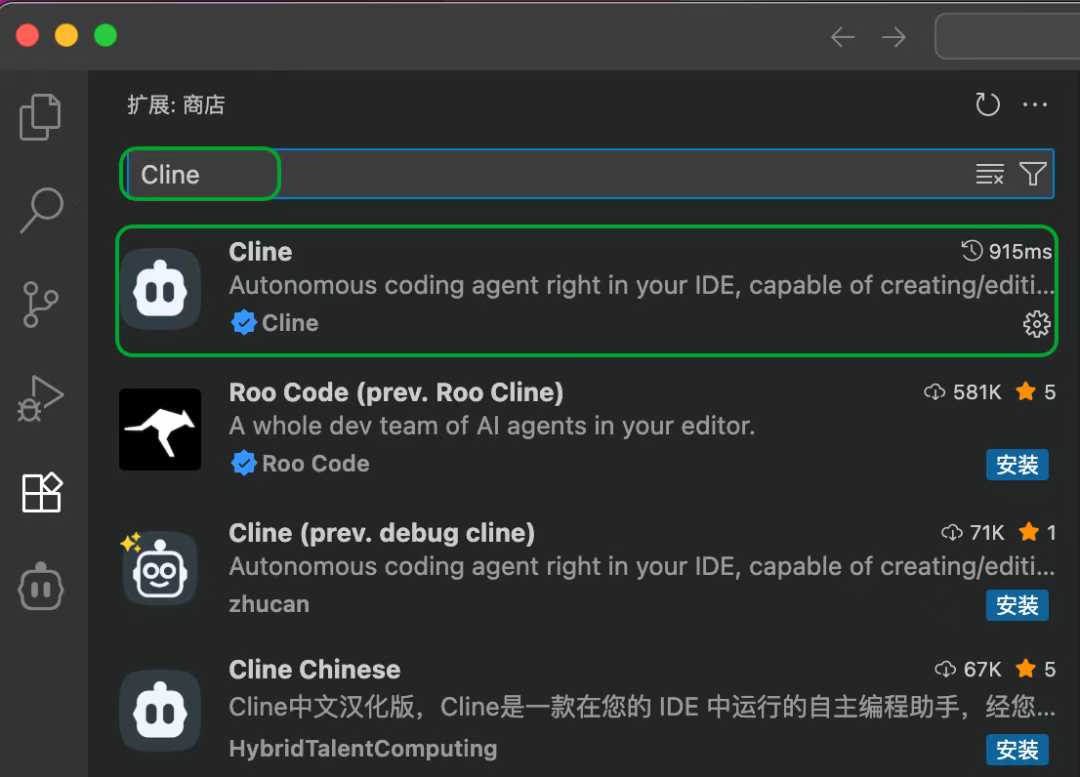
搜索Cline,进行安装。
![]()
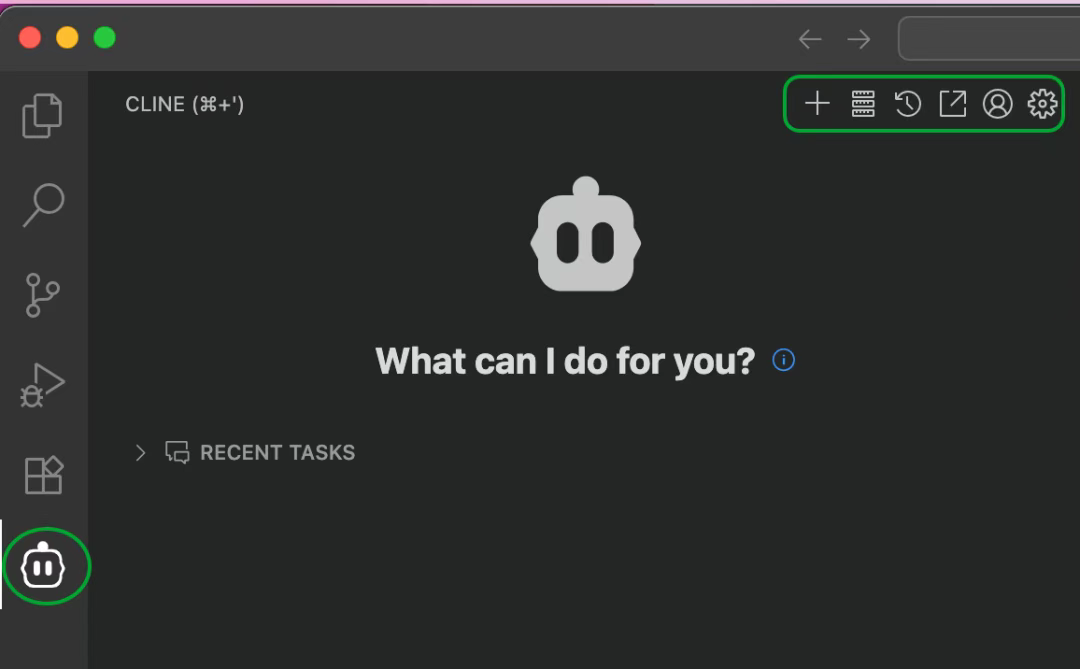
在使用Cline来访问MySQL数据库之前,需要先做一些设置。
![]()
Cline支持国内外的多个大模型,比如OpenAI、Google Gemini、DeepSeek、Doubao、Alibaba Qwen等。
![]()
开通DeepSeek
这里方便起见,我使用了DeepSeek。登陆DeepSeek API开发平台(链接如下👇🏻),创建一个API Key。
https://platform.deepseek.com/sign_in
![]()
使用API Key之前,还需要先进行实名认证,并充一些钱进去。
配置MySQL MCP
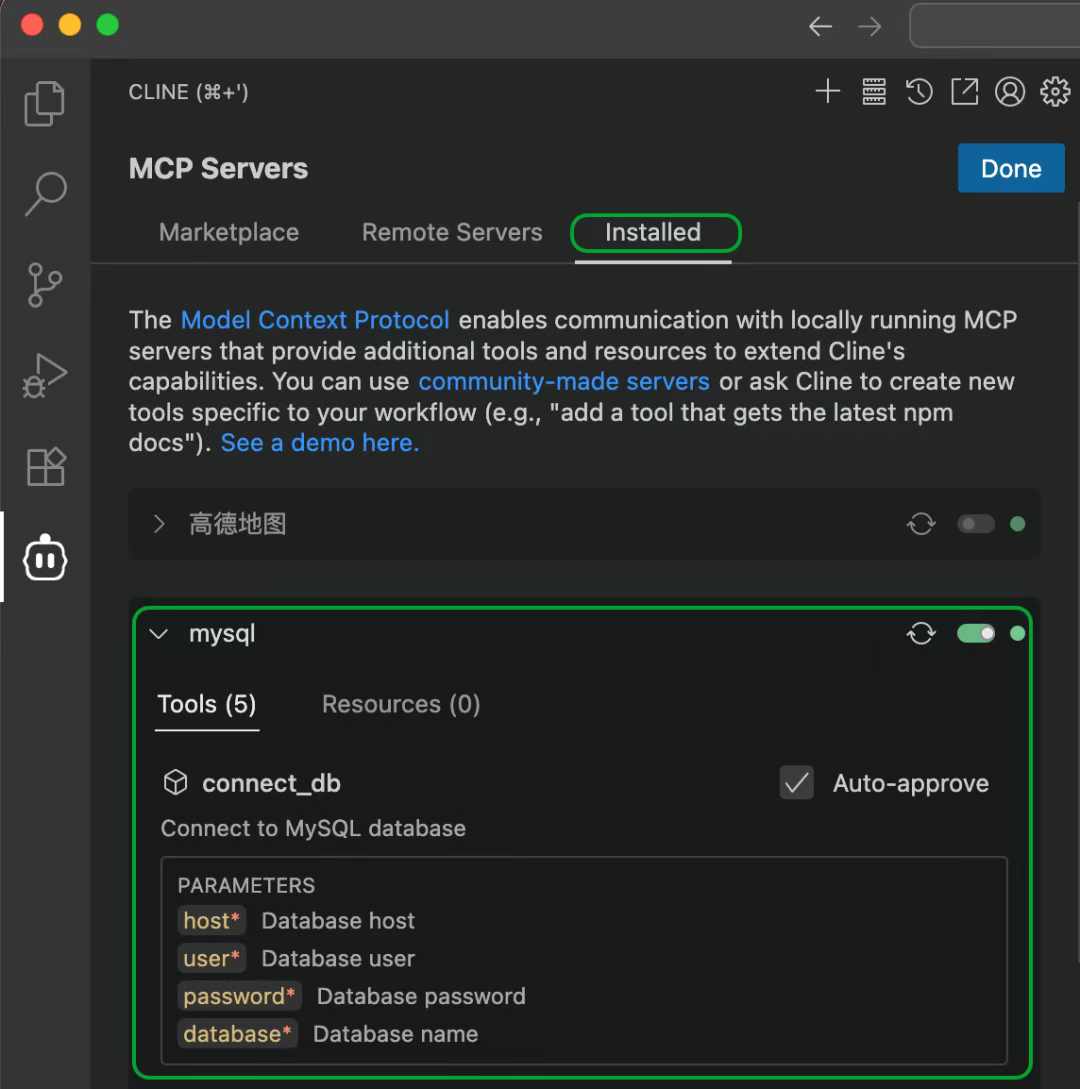
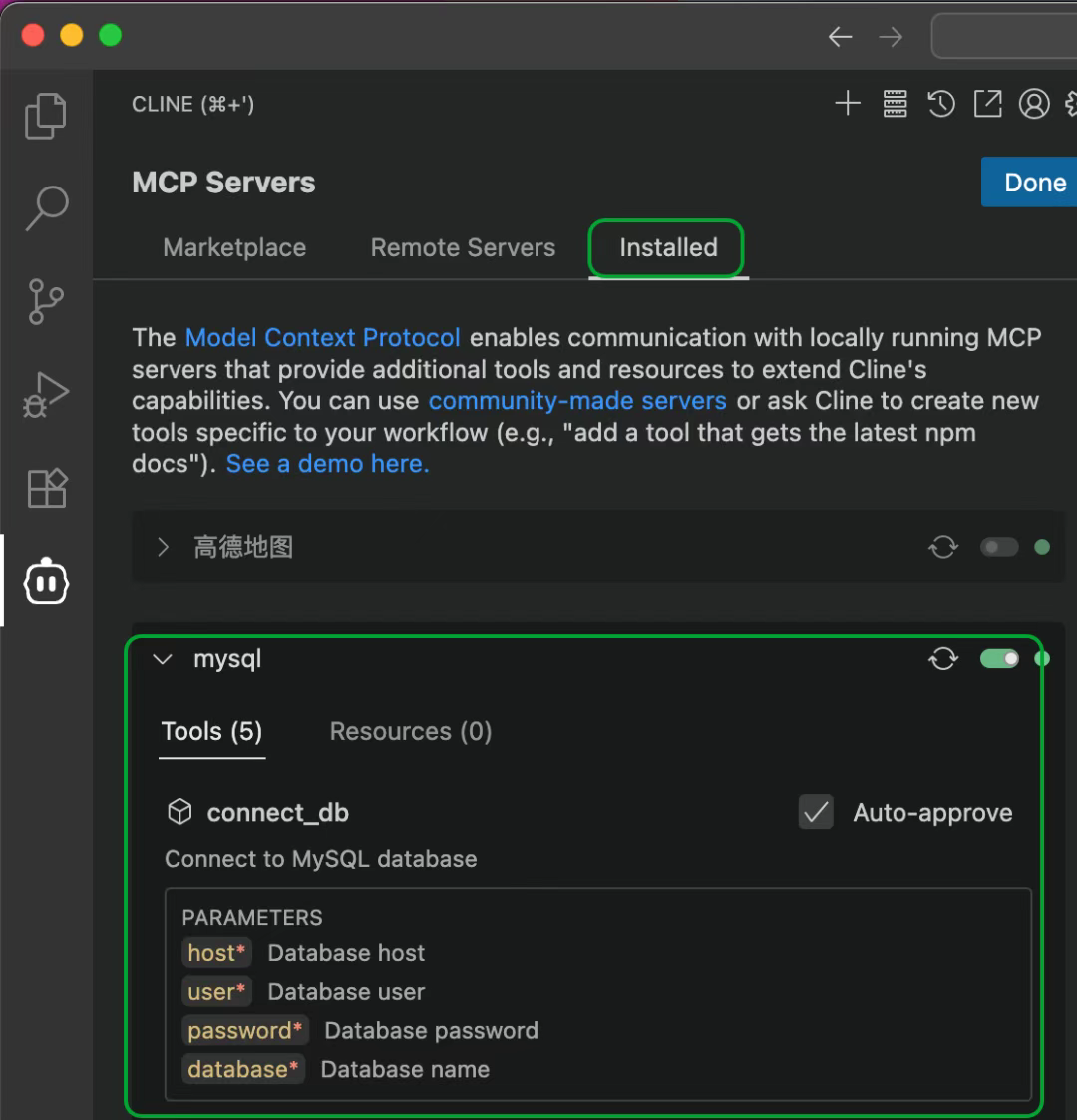
为了让Cline能访问MySQL,还需要再配置一个MCP Server。打开Cline的MCP配置页面,在Installed标签页中,打开"Configure MCP Servers"。
![]()
将下面这段配置保存到cline_mcp_settings.json中。
{
"mcpServers": { "mysql": { "autoApprove": [ "list_tables", "connect_db", "execute", "query", "describe_table" ], "timeout": 60, "type": "stdio", "command": "npx", "args": [ "-y", "@f4ww4z/mcp-mysql-server" ], "env": { "MYSQL_HOST": "localhost", "MYSQL_USER": "root", "MYSQL_PASSWORD": "passwd", "MYSQL_DATABASE": "dbname" } } }}
配置好之后,在Installed页面能看到mysql这个MCP Server。
![]()
Cline会通过下面这个命令来启动mysql MCP Server。
npx -y @f4ww4z/mcp-mysql-server
数据库智能运维初体验
配置好Cline插件后,就可以开始体验用自然语言来操作MySQL了。这里需要有一个测试的MySQL环境。如果你想了解更多MySQL安装部署的内容,也可以参考极客时间里MySQL运维实战课里的这篇文章(链接如下👇🏻)。
https://time.geekbang.org/column/article/801720
连接到数据库
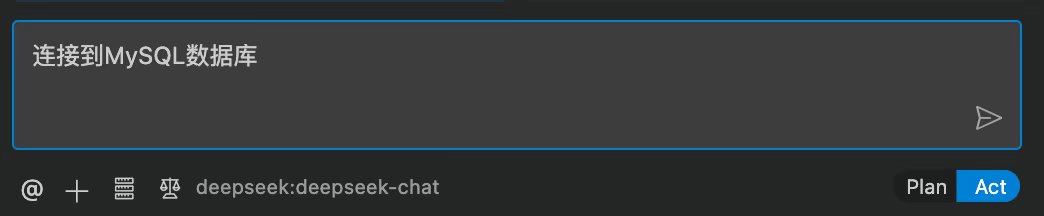
在Cline里输入"连接到MySQL数据库"。
![]()
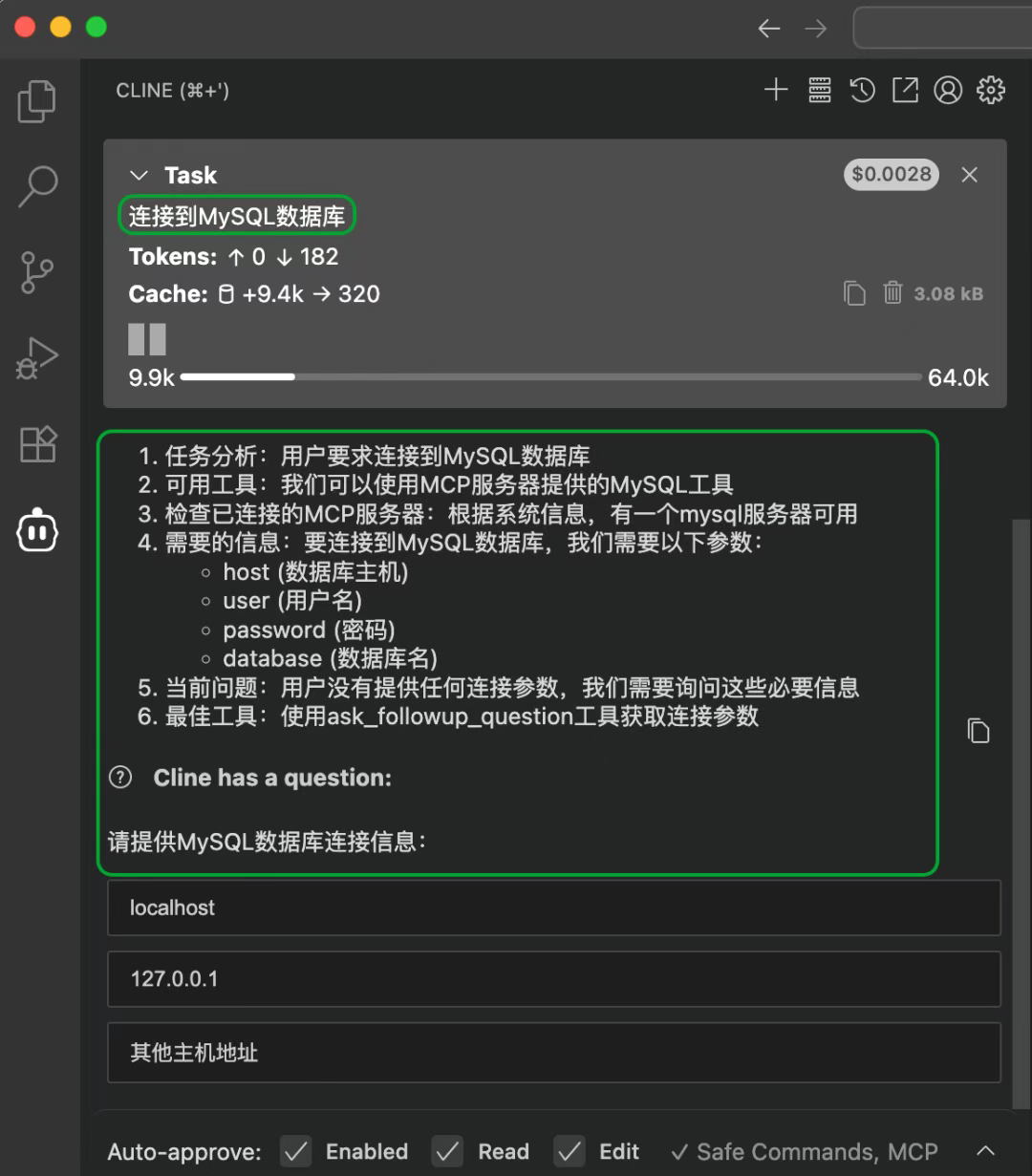
Cline提示需要提供数据库的连接信息。
![]()
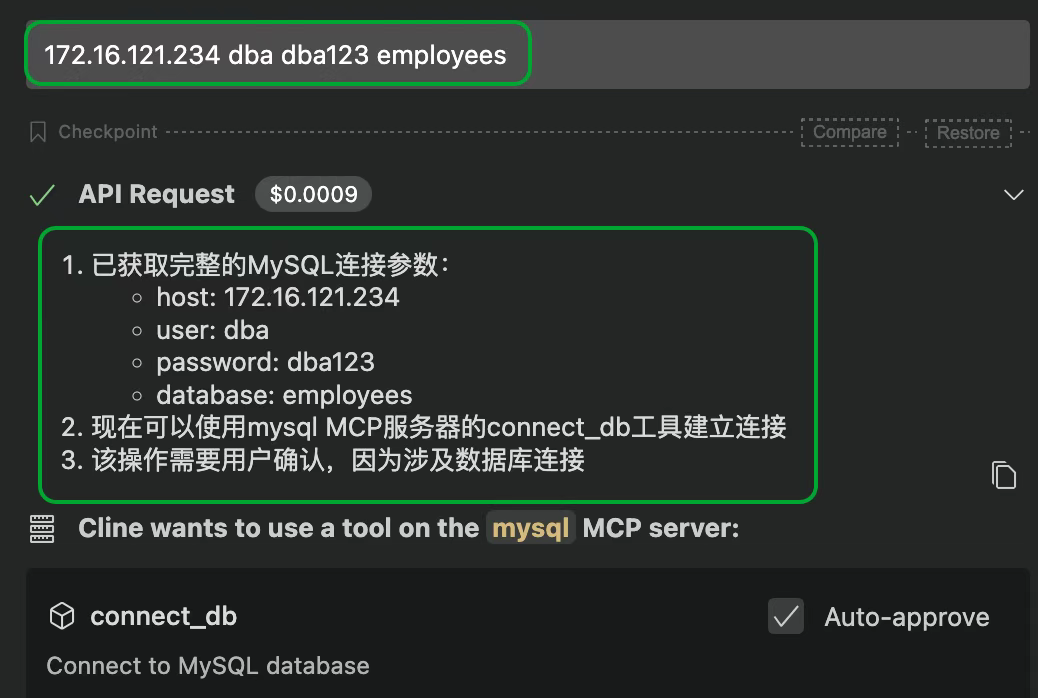
输入数据库连接信息后,连接上数据库。
![]()
![]()
使用自然语言访问数据
这里已经连接到了MySQL的employees样例数据库,接下来使用自然语言来访问数据。
数据库里有哪些表
![]()
查看入职时间最晚的员工的信息
![]()
在这个测试库中,我把salaries表的主键删掉了,导致查询salaries表超时了。这里工具还给出了建议:为 salaries表添加索引。
查看记录数最多的表
![]()
查看数据库中当前运行时间超过5分钟的用户会话
![]()
查看InnoDB Buffer Pool的配置
![]()
将InnoDB Buffer Pool设置为512M
![]()
总结
在上面的这些例子中,我们使用了自然语言来访问数据库中的业务数据,分析数据库中的一些问题,还进行了一些运维的操作。
大模型掌握的数据库知识,远比普通人更加全面和深入,它有以下5点优势:
这种知识优势使得AI可以:
- 在秒级内完成普通人需要数小时研究的复杂问题诊断
- 提供教科书上找不到的实际场景优化建议
- 预判新手容易犯的典型错误并提前规避
- 自动适配不同行业的数据库使用模式
袋鼠云专注于可观测运维,致力解决企业上云难、用云难、管云难三大问题。基于云数据库提供7*24小时保障服务,提供开发支持、数据库体系规范、持续优化、数据库架构支持,保障企业数据库高效稳定运行。全面提升企业的运维效率和稳定性,助力企业完成云时代的数字化转型,满足客户在数据库管理和云迁移方面的多样化需求!