在这个 AI 技术迭代如潮、大模型层出不穷的时代,网站正从传统的人类信息载体,逐步演变成大语言模型 ( LLM ) 的重要数据源。然而,各种网站中复杂的 HTML 嵌套结构与广告内容,又可能让 LLM 的数据采集面临以下挑战:
...
为了更好解决上述问题,将重要的网站信息集中并结构化,llms.txt 应运而生。
什么是 llms.txt ?
简言之,llms.txt 是一个优化网站内容与 LLM 适配的暂拟标准,以托管在网站根目录下的纯 Markdown 文件(路径为 /llms.txt ),轻量化汇总网站的重要信息,不含 HTML 杂码、JavaScript 脚本或广告干扰。
该标准包含两个核心文件:
该标准可以在 https://llmstxt.org/ 查看
llms.txt 最初是由 Answer.AI 的联合创始人 Jeremy Howard 提出,随着 2024 年 11 月 Mintlify(一个开发人员文档平台)为其托管的所有文档网站推出对 llms.txt 的支持后,几乎在一夜之间,包括 Anthropic 和 Cursor 在内的数千个文档网站开始支持 llms.txt 。
builtwith 显示:截止 7 月,已有 5000+ 网站使用了 llms.txt
不同于 robots.txt(告诉爬虫规避内容)或 sitemap.xml(仅罗列无上下文的 URL ),llms.txt 侧重轻量化罗列网站的重点信息。llms.txt 文件内容包含:
以下是官方的模拟示例:
# Title
> Optional description goes here
Optional details go here
## Section name
- [Link title](https://link_url): Optional link details
## Optional
- [Link title](https://link_url)
为了将轻量化进行到底,该标准还包含一个的“ Optional ”部分。该部分通常用于存放一些可以忽略的次要信息,当面临更短上下文时,Optional 内的 URL 则会被跳过。
llms.txt 文件的多功能性使其可以服务于多个场景:从帮助开发者梳理软件文档结构,到为企业勾勒组织架构,甚至能为利益相关方(网站与用户)拆解复杂的法律法规,例如:明确网站信息的查阅权、更正权、删除权等。
llms.txt 出现的意义
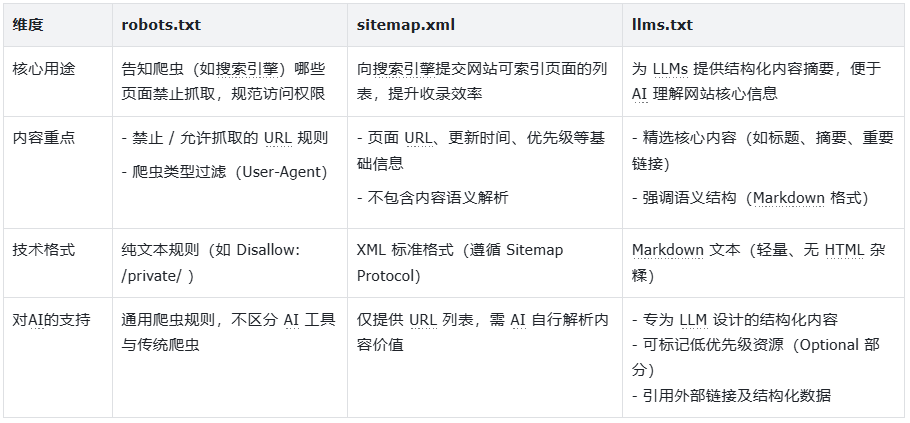
随着 AI 生成式内容逐渐成为人们使用、评估、与品牌互动的常见方式,急需有一个标准去实现“ Web - LLM - 人”的三方桥接。而如果我们将 robots.txt 、sitemap.xml 、llms.txt 三者对比起来看,更能明白其中的区别,以及 llms.txt 的意义,如下表:
![]()
在传统的 SEO 场景下,robots.txt 通常定义爬虫的“抓取边界”,对大模型所需的“哪些内容更具价值”并无定义;而 sitemap.xml 仅能列出本站 URL ,且不提供内容摘要或结构化标签,面对一些大型网站动辄上万个页面,大模型在信息抓取、信息清洗时非常吃力,且容易丢失一些核心内容。
所以,llms.txt 的出现旨在:
-
提高 AI 工具理解准确性:通过提供结构化的内容信息,帮助 AI 更准确地理解网站内容;
-
增强 AI 回答质量:AI 可基于更完整的信息提供更准确、深度的回答;
-
控制 AI 访问内容:网站所有者可以主动决定向 AI 提供哪些内容;
-
减少 AI 抓取负担:AI 工具可以直接获取结构化的内容,减少对网站的抓取负担,且降低算力消耗。
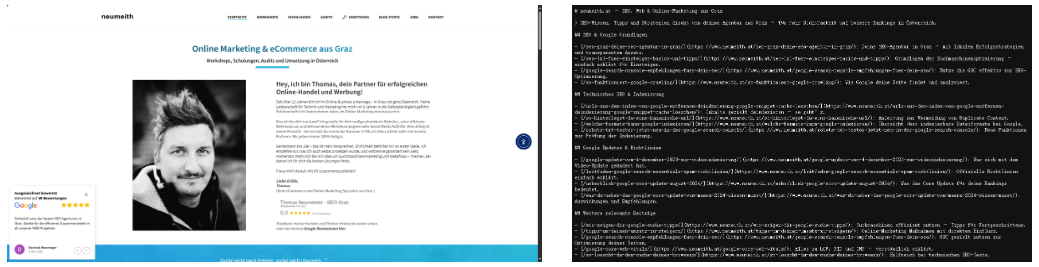
以 https://www.neumeith.at/ 的 llms.txt 文档为例:
![]()
左图为原网站页面,右图为 /llms.txt 截图
该 llms.txt 对网站内容,如 SEO 基础、技术 SEO 、谷歌更新等内容板块做了清晰的分类,帮助大模型快速识别内容的层级关系,抓取各板块核心链接,无需在复杂网页结构里筛选。而在内容上,每一个 H2 标题对应明确 URL ,大模型可以顺着链接精确获取深度内容,如“ SEO - Agentur 介绍”“谷歌搜索控制台指南”等,便于大模型构建知识图谱。
笔者认为,llms.txt 的出现更像是网络向“ AI 友好型”演进的缩影——通过优化大模型数据处理,推动 AI 从“被动数据消费者”向“结构化交互参与者”转型。这将带来怎样的改变呢?
第一、网站逐步把“机器可读能力”纳入基础设计。例如:CMS 通过多模态输出体系,将同一数据源转换为兼顾人类浏览的 HTML 与 AI 友好的 llms.txt 格式,并同步提供通用结构化格式( JSON、CSV ),以支持 AI 快速提取信息、执行逻辑操作。
第二、随着 llms.txt 等结构化标准的普及,网站优化将从“人类可见性优化”向“大模型优化( LLMO )”转型。例如:网站若希望在 AI 生成式答案中获得更靠前的曝光与精准定位,倾向于采用 llms.txt 作为 SEO 的补充方案——例如,电商页面的 HTML 需优化图片加载速度(人类体验),同时 llms.txt 需标注商品 SKU 、价格等结构化数据( AI 需求)。
虽然编制一个 llms.txt 轻而易举,如今也有 5000+ 网站支持 llms.txt ,但 llms.txt 目前仍是一个暂拟标准,且鲜有被大模型厂商正式采用。在《 What Is llms.txt, and Should You Care About It? 》 一文中,其作者 Ryan Law 表示:
-
OpenAI(GPTBot):遵循 robots.txt ,但未官方采用 llms.txt。
-
Anthropic(Claude):发布了自家的 llms.txt 文件,但未声明其爬虫会使用该标准。
-
谷歌(Gemini/Bard):通过User-agent: Google-Extended使用 robots.txt 来管理人工智能的爬取行为,未提及对 llms.txt 的采用。
-
Meta(LLaMA):无公开爬虫或相关指引,暂无使用 llms.txt 的迹象。
Ryan Law 还提到了一个观点,我认为 llms.txt 之所以备受关注,是因为我们都想影响 LLM 中的内容可见性(即,提升关键词曝光),但又缺乏相应的工具,于是便抓住这类看似能带来掌控感的想法。
而在 Reddit 上关于 llms.txt 的高评帖上,也有网友表示,正在使用 llms.txt ,但没有什么特别的效果。
除此之外,也有网友表示,当网站内容被 chatGPT、Perplexity 等大模型引用时,链接将直接指向 Markdown 文件,而用户点击引用链接时,将会得到一个满是 Markdown 纯文本的页面,这对于网站所有者来说,毫无益处。
![]()
以及,即便创建一个 llms.txt 很简单,但也绝对不是一劳永逸的,所需要的持续维护变相增加了网站的运营成本,对于一些大型、复杂的网站尤甚。
![]()
还有一位网友的观点则是:如果 llms.txt 这样的标准得以确立,这可能会带来更透明的 AI 信息溯源和更完善的引用机制。对于拥有复杂文档或知识库的网站而言,能够为检索增强生成(RAG)系统和 AI 代理提供关键内容的清晰结构化概览,将具有重要价值。
![]()