大家好,我是陈哥。
你的公司肯定遇到过这种情况:每周都花不少时间用来追进度,靠微信问、邮件催、会议对,最后汇总成的Excel报表,往往更新到一半就成了过时数据。
员工忙得脚不沾地,管理层却像蒙眼开车:不知道谁工作轻松、谁工作繁多,更看不清项目链条哪里卡住了。
今天就来聊聊如何用一张资源日历,把这种信息不透明、管理不清晰的难题逐一破解,让团队的人力负载、任务进度、资源调度都变得清晰可控。
点击此处,了解人力资源日历插件。留言【资源日历 30】,获人力资源日历插件。
一、为什么你总摸不透团队的工作情况?
1. 人力负载看不清,进度全靠追着问
你想了解员工任务进度,是不是只能靠反复问“做完了吗”“还差多少”“能不能按时交付”,但其实根本不清楚每个人每天实际干了多久、手头积压了多少活、同时在忙几个项目,更不知道谁的工作已经饱和到快扛不住了。
这种信息对不上的后果就是资源分配不合理,整个团队的效率就在这种混乱中被拖后腿。
2. 调度决策拍脑袋,排期全凭感觉走
真到了要调度人的时候,问题就更明显了。
突然来个急活,只能在工作群里喊一嗓子“谁现在有空”,看谁回复快就先把活派给谁,或者看谁最近加班少就觉得对方还有余力,结果等人接了活才发现他手里已经堆了好几个项目,最后两边都耽误。跨部门借人时更是全凭感觉,要么硬压任务把人累得够呛,要么因为没人可用导致项目一拖再拖。
以前调度全靠“拍脑袋”,没有数据做支撑,表面上看是把活分出去了,实际上全是隐患。
3. 人力数据碎片化,历史经验不沉淀
最后说回人力数据管理,很多公司的人力数据都是散的。
项目做完了,到底用了多少人力、每个人的时间花得值不值,根本就说不清楚。
某个岗位的人长期忙不过来,还误以为是他们效率低,其实可能早就该招人了。
人力数据散落在各环节的沟通记录、Excel 表格里,没办法形成有效沉淀,用来指导未来的人力规划,既看不见过去的坑,也预判不了前方的弯。
二、用一张日历看懂整个团队的活怎么干
其实解决办法很简单:让每个人的任务、每个项目的进展都能一目了然。
禅道【人力资源日历】 就可以把这些信息全铺在可视化看板上。
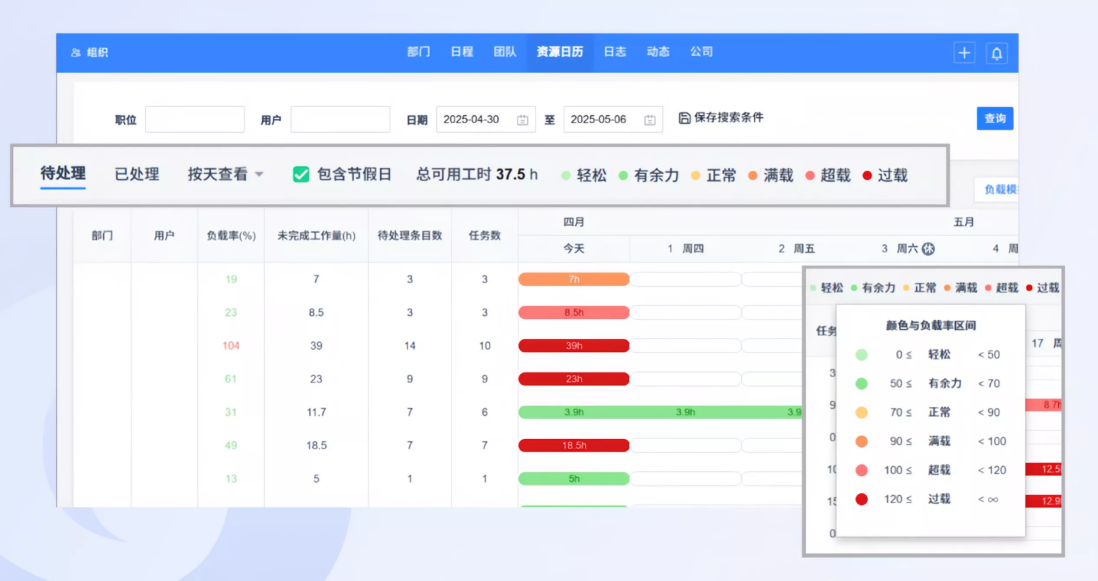
1. 一键看清人力负载
以前看员工任务进度靠“报”不靠“看”,现在打开资源日历,每个成员的任务状态像日历一样清晰:
- 消耗工时:每天实际投入工作的时间
- 未完成工作量:积压的任务量
- 并行工作量:同时承担的项目数量
- 负载率:工作饱和度一目了然(绿色-有余力、黄色-正常、红色-超载/过载)
不用再追着问进度了,谁卡在哪、谁有空,一眼就看清。
![zentao-calendar-1]()
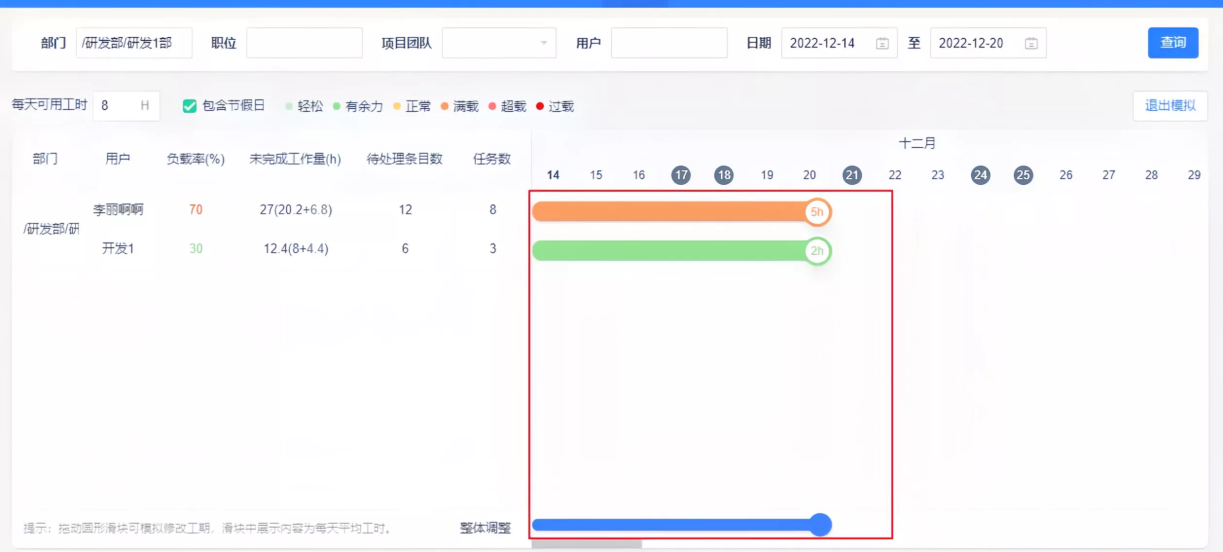
2. 动态调度资源,让排期有数据支撑
每次排期、调人的时候总犯难。其实,排期调度的难题,资源日历插件的模拟负载功能就可以解决,它可以模拟调整待处理工作的工期长短,实时查看模拟后的工作负载变化。
这样,无论是应对突发项目需求,还是提前规划资源配置,都可以按项目进度和任务优先级,动态调整人员的分配,让合适的人在合适的时间处理合适的任务,从根本上减少调度混乱导致的成本浪费。
简单来说,以前调度靠“谁有空派谁”,现在靠“谁合适、怎么调最合理”。每个决策都有数据支撑,团队沟通时对着清晰的负载表,不用为任务分配吵架,效率自然就提上来了。
![zentao-calendar-2]()
3. 数据闭环,把过去的人力资源盘活
企业在日常人力资源管理中,其实都在寻找一个“承前启后”的关键:既要把过去的人力数据盘活,又要用它为未来的人力布局铺路。资源日历插件就能把这些历史数据变成未来决策的依据。
当团队的工时投入、人员负载等数据持续沉淀,我们能清晰看到每个项目的推进节奏是否顺畅,每个人的工作饱和度是否合理,甚至能从任务分配的细枝末节里,察觉出某个岗位是否存在隐性的人力缺口。
结合接下来的业务规划,提前算出下季度各部门内大概需要多少人、重点补充什么技能的人才。有了数据打底,招聘计划不再是拍脑袋决策,人才培养也能更精准地对接业务痛点,让人力准备真正走在业务需求的前面。
三、立即体验:让改变从“看清” 开始
现备注【人力资源日历 30】,让团队人力状况以可视化图表清晰呈现,任务调度变得可模拟、可预测,轻松解决项目延期、资源浪费这些“老大难”问题。