作者:蔡文睿(清素)、汪诚愚(熊兮)、严俊冰(玖烛)、黄俊(临在)
前言
自然语言处理领域因大语言模型(LLM)的突破发生重大变革,深度推理模型如 Open AI o1、DeepSeek-R1 等,通过思维链推理策略,模拟人类思考过程。然而上述长推理模型在实际使用中仍然存在两个问题。首先,模型体积庞大,计算需求高,部署成本昂贵,这为实际应用场景带来了一系列挑战。其次,在某些特定任务中,思维链推理的过程常因路径过长导致冗余,在效率和准确性上存在进一步提升的空间。
基于阿里云人工智能平台(PAI)的蒸馏工具包EasyDistill https://github.com/modelscope/easydistill, 我们提出变长思维链蒸馏技术,探索如何通过蒸馏的方式将小模型的推理能力提升到极致。在此基础上产出了当时业界最大的高质量变长思维链数据集OmniThought,以及DistilQwen-ThoughtX系列蒸馏模型(DistilQwen-ThoughtX:变长思维链推理模型,能力超越DeepSeek蒸馏模型)。近期,PAI团队进一步更新了OmniThought数据集,并发布了新的蒸馏模型DistillQwen-ThoughtY系列。DistillQwen-ThoughtY系列是基于全新Qwen3 学生模型和DeepSeek-R1-0528教师模型训练而成。该模型在数学、代码等领域,全面提升小模型推理能力。相关模型权重、蒸馏方法与蒸馏DeepSeek-R1-0528模型获得的OmniThought-0528数据集已在 EasyDistill框架开源。
本文将重点解析基于EasyDistill框架实现DistillQwen-ThoughtY模型的蒸馏,评测模型相关效果,最后介绍了DistillQwen-ThoughtY模型在开源社区和PAI平台上的使用方式。
技术简介
OmniThought-0528 数据集的构建
在先前的工作(DistilQwen-ThoughtX:变长思维链推理模型,能力超越DeepSeek蒸馏模型),我们构建了OmniThought思维链数据集,从多个公开数据源搜集推理问题构成框架的输入,涵盖数学、编码、科学等不同领域的推理问题。对于每个问题,采用DeepSeek-R1和QwQ-32B作为教师模型生成多个思维链,采用"LLM-as-a-judge"方法对生成的思维链进行多个方面的正确性验证,仅当验证为正确的思维链才能最终被选为训练集。此外,对于每条思维链,我们标注了"推理冗余度(Reasoning Verbosity,RV)"和"认知难度(Cognitive Difficulty,CD)"这两个指标,描述如下所示: ![]()
从推理冗余度的角度看,由于对于难度较大的问题,较长的思维链能够纠正模型自身的错误;而在处理简单任务时,思维链的过度推理和验证不仅会增加计算资源的消耗,还可能降低解决问题的准确性。因此,推理冗余度与问题的难度有较大的关联性。从认知难度的角度看,小模型由于参数量和学习到的知识量限制,通常依赖更简单的方法来解决问题,而大模型则能够施展其高级的认知优势,应用更高阶的技术。因此,思维链的认知难度应该与需要训练的学生模型大小相匹配。最终,我们可以根据目标模型大小和问题难度,选择合适的思维链用于蒸馏训练。
为了进一步加强高质量思维链数据对模型蒸馏的效果,我们采用DeepSeek-R1-0528作为教师模型,构建了OmniThought数据的最新版本------OmniThought-0528。DeepSeek-R1-0528模型在数学、编程以及通用逻辑等多个测评基准上表现优异,整体表现接近国际顶尖模型。在本次的发布中,OmniThought-0528思维链的标注标准与OmniThought原始数据集相同。
OmniThought-0528数据集已经在Huggingface和ModelScope开源,包括36.5万条思维链数据。数据格式如下,其中每条数据都包括一个问题(question),和至少2个思维链回答(reasoning),每个思维链都包含认知难度(Cognitive_Difficulty)和推理冗余度(Reasoning_Verbosity)的评分,并且包含一个思维链回答(full_response):
{ "question": "TL;DR", "reasoning": [ { "Cognitive_Difficulty": { "judge": "QwQ-32B", "level": 6 }, "Reasoning_Verbosity": { "judge": "QwQ-32B", "level": 5 }, "full_response": "TL;DR" }, { "Cognitive_Difficulty": { "judge": "QwQ-32B", "level": 5 }, "Reasoning_Verbosity": { "judge": "QwQ-32B", "level": 5 }, "full_response": "TL;DR" } ] }
使用 EasyDistill 进行思维链数据生成、评分
通过使用阿里云人工智能平台(PAI)推出的新的开源工具包EasyDistill ,用户可以轻松实现生成思维链数据、对思维链数据打分。
- 克隆代码库,并安装相关依赖:
git clone https://github.com/modelscope/easydistill cd EasyDistill pip install -r requirements.txt
- 可以使用各种配置文件生成训练数据,以思维链数据生成为例,配置文件如下:
{ "job_type": "cot_generation_api", "dataset": { "input_path": "./cot_question.json", "output_path": "./cot_question_with_answer.json" }, "inference":{ "base_url": "ENDPOINT", "api_key": "TOKEN", "stream": true, "prompt" : "Your role as an assistant involves thoroughly exploring questions through a systematic long thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracing, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Thought and Solution. In the Thought section, detail your reasoning process using the specified format: <|begin_of_thought|> {thought with steps separated with '\n\n'} <|end_of_thought|> Each step should include detailed considerations such as analisying questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Solution section, based on various attempts, explorations, and reflections from the Thought section, systematically present the final solution that you deem correct. The solution should remain a logical, accurate, concise expression style and detail necessary step needed to reach the conclusion, formatted as follows: <|begin_of_solution|> {final formatted, precise, and clear solution} <|end_of_solution|> Now, try to solve the following question through the above guidelines:", "max_new_tokens": 1024 } }
- 完成思维链数据生成后,可以使用思维链评价打分功能,配置文件如下:
{ "job_type": "cot_eval_api", "dataset": { "input_path": "cot_input.json", "output_path": "cot_output.json" }, "inference":{ "base_url": "ENDPOINT", "api_key": "TOKEN", "max_new_tokens": 8196 } }
运行下面的命令,即可完成对cot数据质量的评价打分:
python .eval/data_eval.py --config .configs/cot_eval_api.json
DistillQwen-ThoughtY的模型训练
基于我们提出的OmniThought数据集及其扩展版本OmniThought-0528数据集,我们训练了DistillQwen-ThoughtY系列模型,这一系列模型是对DistillQwen-ThoughtX系列模型的重大升级,主要体现在两个方面:第一,模型基于Qwen3底座,分为4B、8B和32B三个参数量级,分别适配不用的使用和部署场景;第二,模型的训练数据集同时考虑了OmniThought和OmniThought-0528,同时融合了DeepSeek-R1、DeepSeek-R1-0528以及QwQ-32B这三个教师大模型的深度推理知识。在思维链筛选方面,同样使用了基于OmniThought数据集的筛选方法(参考DistilQwen-ThoughtX:变长思维链推理模型,能力超越DeepSeek蒸馏模型)。
此外,为了保证模型尽可能从DeepSeek-R1-0528学习知识,我们规定数据集来源于两个部分:1. 原始OmniThought数据集和2. OmniThought-0528思维链。在最终的方案中,我们并没有完全使用来自DeepSeek-R1-0528的思维链而是采用混合的方式,因为虽然DeepSeek-R1-0528整体表现较好,但在特定问题上,并非DeepSeek-R1-0528生成的思维链质量最佳。相反,采用不同教师模型生成思维链并且筛选能取得更好的效果。
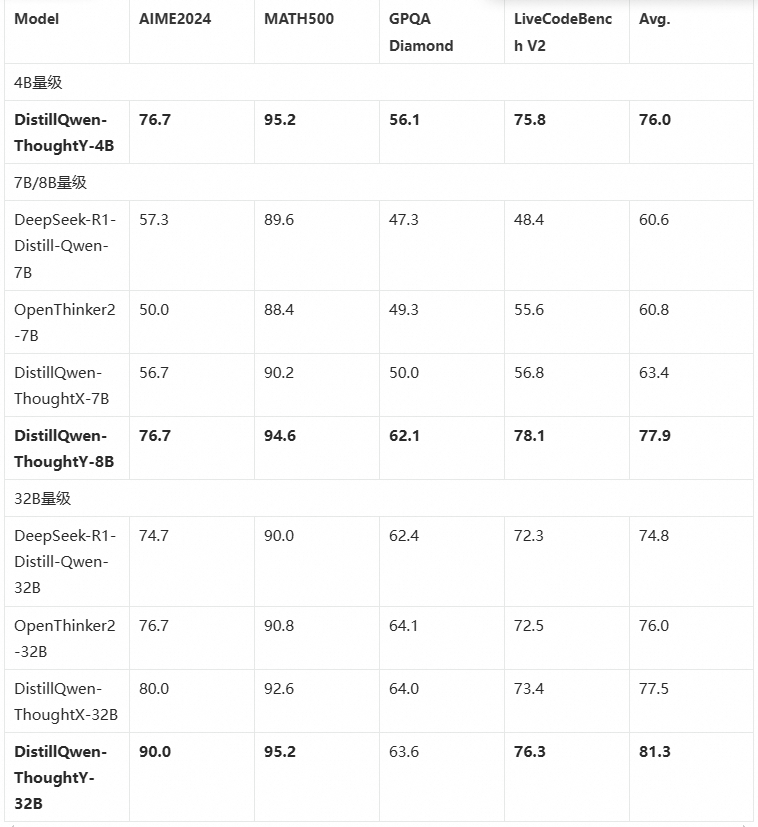
我们使用单机8卡(A800 80GB)进行DistillQwen-ThoughtY-4B/8B的训练,使用4机32卡(A800 80GB)进行DistillQwen-ThoughtY-32B的训练。默认使用的学习率为5e-5,epoch为3,序列长度为8192,我们也尝试了其他超参数的组合进行模型优化。我们从 Qwen3 系列底座(4B、8B和32B)初始化,训练三个模型,分别命名为 DistillQwen-ThoughtY-4B/8B/32B。数据组织的格式与Qwen3 系列的thinking模式相同。我们将我们的模型先前的DistillQwen-ThoughtX,DeepSeek蒸馏的R1模型进行比较。结果表明,DistillQwen-ThoughtY 模型在数学、代码等场景下的效果相比 Baseline 模型有明显的提升,证明了 DistillQwen-ThoughtY 模型强悍的推理能力,以及蒸馏方法的有效性。 ![]()
在下文中,我们描述如何使用 EasyDistill 框架进行训练。
使用 EasyDistill 进行思维链数据筛选和模型训练
在生成思维链数据和完成思维链打分后,我们需要对思维链进行筛选,并将筛选出的思维链数据进行模型训练。
- 运行下面的脚本筛选思维链数据:
python ./recipes/distilqwen_series/distillqwen2.5-thoughtX/filter.py
- 用筛选出的思维链数据进行模型的训练,配置文件如下,可以按需更新配置文件并训练:
{ "job_type": "kd_black_box_local", "dataset": { "labeled_path": "train_labeled.json", "template" : "./chat_template/chat_template_kd.jinja", "seed": 42 }, "models": { "student": "student/Qwen/Qwen2.5-0.5B-Instruct/" }, "training": { "output_dir": "./result/", "num_train_epochs": 3, "per_device_train_batch_size": 1, "gradient_accumulation_steps": 8, "max_length":512, "save_steps": 1000, "logging_steps": 1, "learning_rate": 2e-5, "weight_decay": 0.05, "warmup_ratio": 0.1, "lr_scheduler_type": "cosine" } }
训练脚本如下:
accelerate launch --num_processes n \ --config_file ./configs/train-config/muti_gpu.ymal ./easydistill/black-box/train.py \ --config ./configs/kd_black_box_local.json
模型和数据集下载和使用
DistillQwen-ThoughtY 在开源社区的下载
我们在 Hugging Face 和 Model Scope 上开源了我们蒸馏后的模型,分别为DistillQwen-ThoughtY-4B、 DistillQwen-ThoughtY-8B、DistillQwen-ThoughtY-32B。以Hugging Face为例,用户可以使用如下代码下载这两个模型:
`from huggingface_hubimport snapshot_download
model_name = "alibaba-pai/DistillQwen-ThoughtY-4B" snapshot_download(repo_id=model_name, cache_dir="./DistillQwen-ThoughtY-4B/")
model_name = "alibaba-pai/DistillQwen-ThoughtY-8B" snapshot_download(repo_id=model_name, cache_dir="./DistillQwen-ThoughtY-8B/")
model_name = "alibaba-pai/DistillQwen-ThoughtY-32B" snapshot_download(repo_id=model_name, cache_dir="./DistillQwen-ThoughtY-32B/")`
以下给出一个ModelScope的使用示例:
`from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "pai/DistillQwen-ThoughtY-4B"
tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
prompt = "Solve ∫x e^x dx. Show your reasoning step-by-step." messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # Switches between thinking and non-thinking modes. Default is True. ) inputs = tokenizer([text], return_tensors="pt").to("cuda") outputs = model.generate(**inputs, max_new_tokens=32768) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
`
OmniThought-0528 数据集在开源社区的下载
我们在 HuggingFace和 ModelScope上开源了我们的数据集OmniThought-0528。用户可以使用如下代码下载这两个模型:
`from datasets import load_dataset OmniThought = load_dataset("alibaba-pai/OmniThought-0528")
from modelscope.msdatasets import MsDataset ds = MsDataset.load('PAI/OmniThought-0528')`
DistillQwen-ThoughtY 模型在PAI的使用
DistillQwen-ThoughtY模型已经在PAI-Model Gallery中上线,使用方式可以参考:DistilQwen-ThoughtX 蒸馏模型在 PAI-ModelGallery 的训练、评测、压缩及部署实践。
可以点击PAI-DistilQwen-ThoughtY查看模型详情。
本文小结
近年来,大语言模型(LLM)推动了自然语言处理(NLP)的深刻变革,尤其在语言理解和推理任务方面取得重大进展。然而,长思维链策略在某些任务中引发"过度思考"问题,影响了模型的响应效率。阿里云PAI团队基于蒸馏工具包EasyDistill,推出了DistillQwen-ThoughtY系列模型基于更强的底座Qwen3和教师模型DeepSeek-R1-0528,显著提升了数学、科学及代码生成领域的表现。这些模型、蒸馏方法以及和相关数据集现已在EasyDistill中开源。在未来,我们将进一步基于EasyDistill框架开源更多DistillQwen模型系列和相应资源。欢迎大家加入我们,一起交流大模型蒸馏技术!
参考工作
相关论文
-
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
-
Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang.EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. arXiv preprint
-
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Training Small Reasoning LLMs with Cognitive Preference Alignment. arXiv preprint
-
Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistillQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024
技术介绍
-DistillQwen2.5-R1发布:知识蒸馏助推小模型深度思考