作者:来自 Elastic Adel Wu
![]()
Elasticsearch 与行业领先的 Gen AI 工具和提供商进行了原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础知识,或构建可用于生产的应用程序 Elastic Vector Database。
要为您的用例构建最佳搜索解决方案,请开始免费试用云,或立即在本地计算机上试用 Elastic。
解析是大多数 RAG 管道中的瓶颈。扫描的 PDF 和电子表格可能很混乱,输入不当会导致检索不完整、产生幻觉和脆弱的结果。近 80%** 的企业知识被困在这些格式中,传统的 OCR 使结构和意义扁平化。
应对这一挑战需要先进的解析技术,将传统的 OCR 和视觉语言模型 (VLM) 相结合来解释文档布局和内容,并生成结构化的、LLM 就绪的块。本文将探讨这种混合方法,并演示如何将 Reducto 的文档解析 API 与 Elasticsearch 集成以进行语义搜索。
解析为何仍是巨大挑战
传统的 OCR 和基础文本提取方法只能生成文档的 “扁平” 视图。这可能适用于复制粘贴,但对于搜索来说是灾难性的。
想象一下把一份财务报告或复杂表单扁平化成一串纯文本:
-
表格、标题、脚注和正文之间的关系被抹去
-
关于布局、重要性和层级的上下文线索丢失
-
基于向量或关键词的检索系统失去了有效的信号
Reducto 没有沿用 “先 OCR 一切 → 再导入 Elastic” 的传统流程,而是设计了一种新方法:保留现实文档中的结构、上下文和语义。
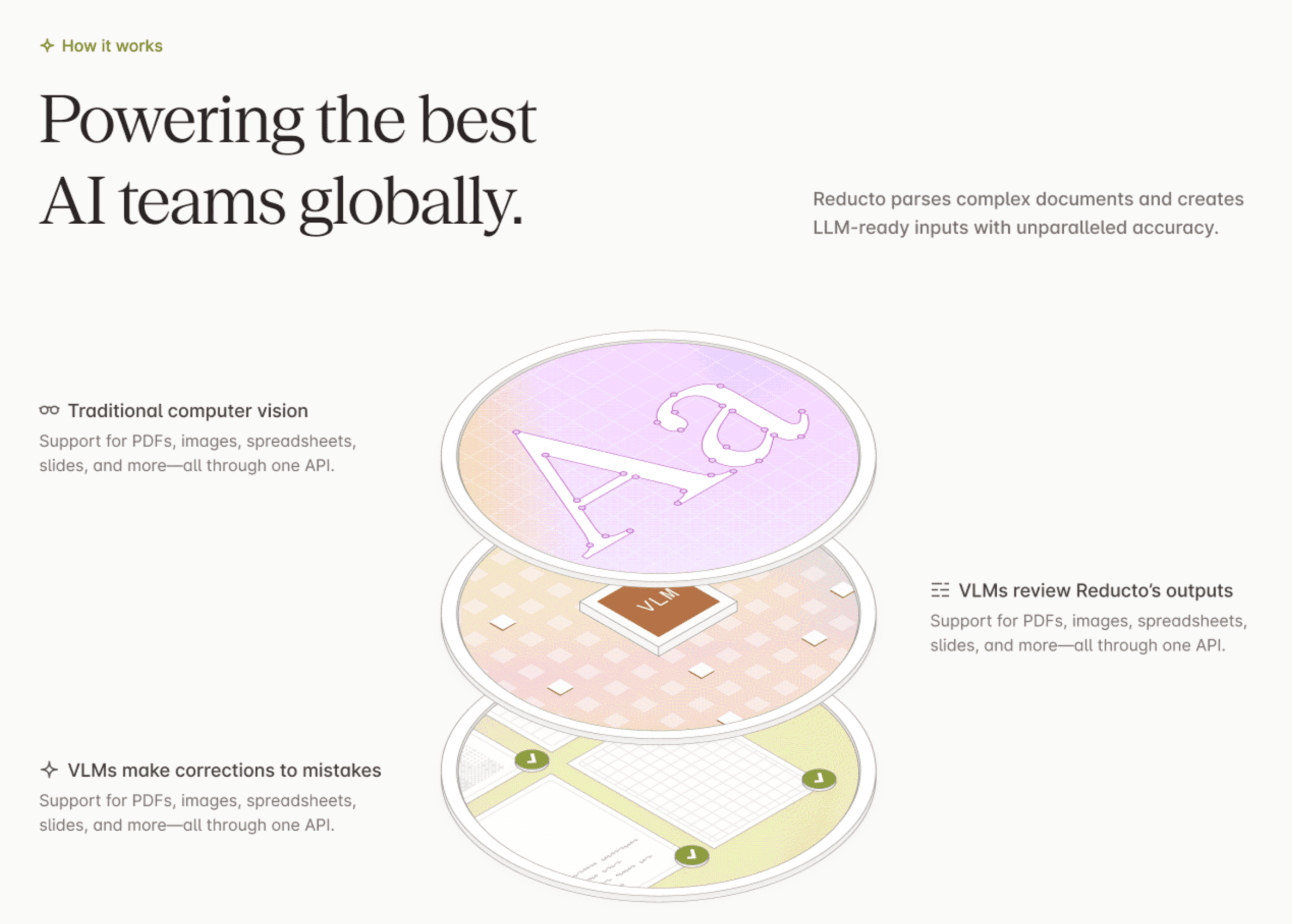
Reducto 的 “视觉优先” 方法
Reducto 的 parsing API 不再把文档仅仅当作文本,而是作为具有上下文意义的视觉对象来处理。
我们的解析流程结合了:
Reducto 的混合方法在基准测试中相比传统纯文本解析器带来了显著提升(例如,在 RD-TableBench 这类开源表格解析基准数据集上,一些实现表现提升超过 20 个百分点)。
![]()
通过同时分析文档的内容和视觉结构,Reducto 可生成:
最终解析结果完整保留了原始文档的丰富信息,适用于需要拆分与上下文嵌入的检索流程。
![解析挑战]()
引入 Agentic OCR:多轮自我纠错
即使是最好的模型,也难免会出现解析错误。复杂的扫描件、手写笔记或多层嵌套表格可能会让一次性解析器失效。
为了解决这个问题,我们引入了 Agentic OCR ——一个多轮自我纠错框架。
可以把它看作是一个 “人类参与” 的过程 —— 只是无需人工。该方法大幅提升了真实环境下的稳健性,确保即使是复杂、从未见过的文档也能被清晰准确地解析。
示例:将 Reducto API 与 Elasticsearch 一起使用
解析不是最终目标,搜索才是。
Reducto 的客户经常将解析后的输出直接集成到 Elasticsearch 中,用于内部知识库、智能文档检索或检索增强生成(retrieval-augmented generation - RAG )系统。
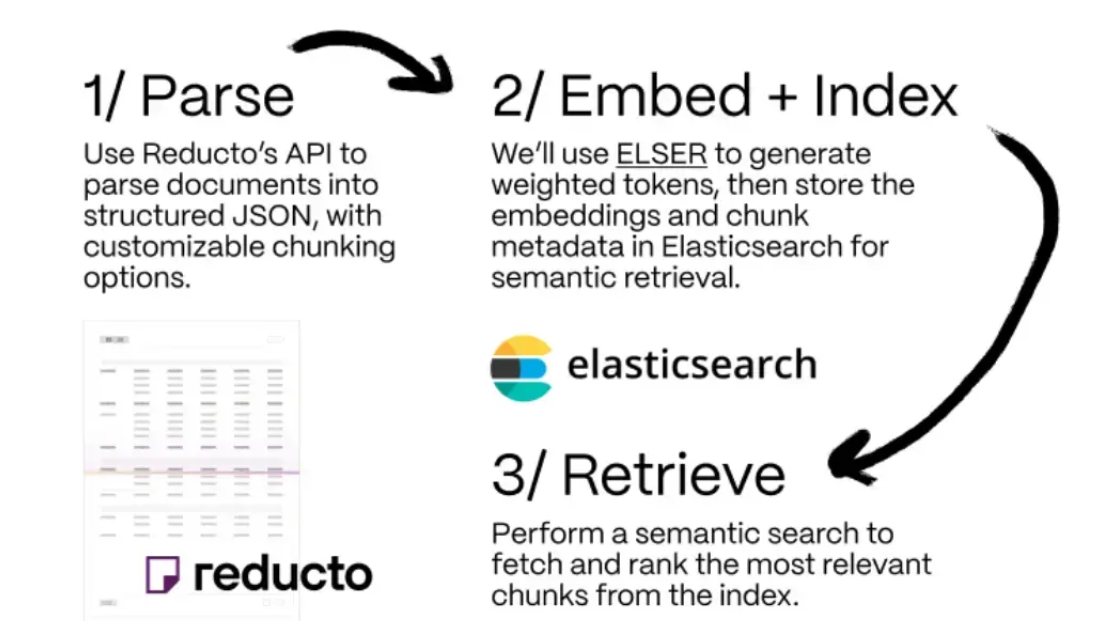
以下是一个高级概览:
- 解析:使用 Reducto 的 API 将文档解析为结构化的 JSON,可自定义分块选项。
- 嵌入 + 索引:我们将在本例中使用 ELSER,这是一种内置于 Elasticsearch 的稀疏检索模型,可以非常轻松地执行语义搜索,用于生成加权的 tokens。我们会将嵌入向量和分块元数据存储到 Elasticsearch 中以实现语义检索。
- 检索:给定一个查询,从索引中获取最相关的分块。
如果你有兴趣进一步了解稀疏向量以及为什么它们是语义搜索的优秀选择,请阅读此博客以了解更多信息。
![]()
🧾 1. 使用 Reducto(通过 API)进行解析和分块
要获取 Reducto 的 API 密钥,请前往 reducto.ai 并点击 “Contact us”。我们会安排一次简短的入职电话,了解你的使用场景,并为你设置一个试用密钥。
安装我们的 Python SDK —— 与我们 API 交互的最简单方式。
pip install reductoai
然后,调用我们的解析函数。这里有一些与分块相关的配置需要注意:
我们建议 RAG 用例保持 Reducto 默认的 “variable” 分块模式,因为它在捕获和分组最语义相关的数据方面最灵活。使用默认值时,调用中无需设置特定配置。
更多可配置项请参考 Reducto 的 API 文档中 Parse 端点的说明。你也可以试用我们的 UI 体验区,查看 “Configure Options” 下的所有选项。
from reducto import Reducto
from getpass import getpass
# Parse documents using Reducto SDK
reducto_client = Reducto(api_key=getpass("REDUCTO_API_KEY"))
upload = reducto_client.upload(file=Path("sample_report.pdf"))
parsed = reducto_client.parse.run(
document_url=upload,
options={ # Optional configs would go here
"chunking": {
"chunk_mode": "variable",
"chunk_size": 1000,
}
}
)
# Parsed output
print(f"Chunk count: {str(len(parsed.result.chunks))}")
print(parsed.result.chunks)
使用我们提供的示例股票研究报告(链接在这里),解析后的输出大致如下:
Chunk count: 32
ResultFullResultChunk(blocks=[ResultFullResultChunkBlock(bbox=BoundingBox(height=0.022095959595959596, left=0.08823529411764706, page=1, top=0.04671717171717172, width=0.22549019607843138, original_page=1), content='Goldman Stanley', type='Title', confidence='high', image_url=None), ...])
📐 📦 2. 使用 ELSER 进行嵌入和索引
创建你的 Elastic Cloud Serverless 集群,或选择你喜欢的部署方式。
安装 Elasticsearch 的 Python 客户端。
pip install elasticsearch
初始化客户端并连接到你的 Elasticsearch 实例。
from elasticsearch import Elasticsearch, exceptions
# Create Elasticsearch Client
es_client = Elasticsearch(
getpass("ELASTICSEARCH_ENDPOINT"),
api_key=getpass("ELASTIC_API_KEY")
)
print(es_client.info())
创建用于生成嵌入向量的 ingest pipeline,使用 ELSER,并应用到我们的新索引中。
INDEX_NAME = "reducto_parsed_docs"
# Drop index if exists
es_client.indices.delete(index=INDEX_NAME, ignore_unavailable=True)
# Create the ingest pipeline with the inference processor
es_client.ingest.put_pipeline(
id="ingest_elser",
processors=[
{
"inference": {
"model_id": ".elser-2-elasticsearch",
"input_output": {
"input_field": "text",
"output_field": "text_semantic"
}
}
}
]
)
print("Finished creating ingest pipeline")
# Create mappings with sparse_vector for ELSER
es_client.indices.create(index=INDEX_NAME, body={
"settings": {"index": {"default_pipeline": "ingest_elser"}},
"mappings": {
"properties": {
"text": { "type": "text" },
"text_semantic": { "type": "sparse_vector" }
}
}
})
print("Finished creating index")
将每个 Reducto 分块索引到 Elasticsearch 中,Elastic Inference Service 会通过 ingest pipeline 生成嵌入向量。
# Index each chunk
for i, chunk in enumerate(parsed.result.chunks):
doc = {
"text": chunk.embed
}
es_client.index(index=INDEX_NAME, id=f"chunk-{i}", document=doc)
🔍 3. 检索
使用推理服务执行稀疏向量查询,为查询生成嵌入向量。该查询由 ELSER 构建的稀疏向量组成。
# Use semantic text search
response = es_client.search(
index=INDEX_NAME,
query={
"sparse_vector":{
"field": "text_semantic",
"inference_id": ".elser-2-elasticsearch",
"query": "What was the client revenue last year?"
}
}
)
# Print results
for hit in response["hits"]["hits"]:
print(f"Score: {hit['_score']:.4f}")
print(f"Text: {hit['_source']['text'][:300]}...\n")
print(f"ELSER Embedding: {hit['_source']['text_semantic']}...\n")
当查询我们示例股票研究报告的分块时,结果可能如下,包含余弦相似度分数和对应的分块内容:
Score: 13.0095
Text: # Operations (cont.)
Figure 2 - Jazz Historical and Projected Revenue Mix by Product...
ELSER Embedding: {'studio': 0.5506277, 'copyright': 0.29489025, 'def': 1.0905615, ... }
Score: 12.0828
Text: # Jazz Pharmaceuticals (JAZZ) (cont.)
## Strong Q1 FY14 & Multiple Catalysts Ahead (cont.)...
ELSER Embedding: {'##arm': 0.12544458, 'def': 1.4090042, '##e': 0.48080343, ... }
.
.
.
Elasticsearch 是领先的向量数据库,为 AI 应用提供大规模性能。它在处理庞大嵌入数据集方面尤为强大,得益于其分布式架构和将向量相似度与关键词相关性结合的混合搜索质量。Reducto 通过提供结构化、适合 LLM 的分块,补充了 Elastic 的能力,确保 Elasticsearch 强大的索引和搜索检索在最高质量的输入上运行,从而带来更优的 AI 代理性能和更准确的生成结果。
结论
企业多年来一直基于不完整或扁平化的文档数据构建搜索系统——现在,新技术正出现以挖掘这些信息的更深层见解。Reducto 的 API 适合各行各业的公司,尤其是那些需要高准确性的领域,如金融、医疗和法律。
Reducto 的以视觉为先、由代理驱动的解析管道提供了前进的方向:
- 保持上下文、结构和意义
- 向像 Elasticsearch 这样的向量存储和检索系统输入更丰富、更准确的数据
- 实现更可靠、无幻觉的 RAG 和搜索体验
你可以在 Reducto Playground 体验 Reducto,或联系了解完整集成方案。如果你想构建此应用并操作代码,可以在这个 notebook 中找到说明。
有了 Reducto 和 Elasticsearch 向量数据库,企业知识变得可搜索且易理解。
来源:Possibilities and limitations, of unstructured data - Research World
原文:Making sense of unstructured documents: Using Reducto parsing with Elasticsearch - Elasticsearch Labs