GPUStack 是一个100%开源的模型服务平台 ,支持 Linux、Windows 和 macOS ,支持 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程 等 GPU 构建异构 GPU 集群 ,支持 LLM、多模态、Embedding、Reranker、图像生成、Speech-to-Text 和 Text-to-Speech 模型,支持 vLLM、MindIE、llama-box (基于 llama.cpp 与 stable-diffusion.cpp )等多种推理引擎与推理引擎多版本并行 ,支持资源自动调度分配、模型故障自动恢复、多机分布式推理、混合异构推理、推理请求负载均衡、资源与模型监控指标观测、国产化支持、用户管理与 API 认证授权等各种企业级特性 ,提供 OpenAI 兼容 API 无缝接入 Dify、RAGFlow、FastGPT、MaxKB 等各种上层应用框架,是企业建设模型服务平台的理想选择。
GPUStack 一直致力于以最简单易用的方式,帮助用户快速纳管异构 GPU 资源并运行所需的 AI 模型,从而支撑 RAG、AI Agents 以及其他生成式 AI 落地场景。为用户打造绝佳的使用体验是我们始终坚持的目标。最新发布的 v0.6 是迄今为止最重磅的版本,全方位完善了平台的整体功能、性能、稳定性和用户使用体验。
GPUStack v0.6 版本的核心更新包括:
- vLLM 多机分布式推理:提供生产级的多机分布式推理能力,支撑 DeepSeek R1 / V3 等单机 GPU 资源无法运行的超大参数量模型。
- 昇腾 MindIE 支持:为昇腾 910B 和 310P 用户提供内置的 MindIE 推理引擎支持,以提供最佳的模型推理表现。
- 模型兼容性检测:提供对模型是否支持部署的兼容性检测,目前提供对模型架构支持、操作系统兼容、资源可用性、本地路径可用性等依赖的实时检测,后续还会持续加入更多检测条件,提供更加友好的模型部署体验。
- 模型下载管理:支持管理已下载的模型文件、支持以不占用 GPU 资源分配为前提,发起单机/多机的模型下载任务、支持将本地路径的模型文件添加到 UI 中进行统一管理。
- 模型故障自动恢复:支持模型在发生故障时的自动恢复机制。
- 端口暴露优化:优化需要暴露的端口范围,API 入口到模型实例的推理请求统一经过代理转发,不再需要暴露模型实例端口,降低 96% 以上的端口暴露,并支持用户自定义。
- 增强国际化支持:GPUStack 用户遍布全球上百个国家和地区,本次 GPUStack 社区用户贡献了俄语和日语支持,为不同语言的用户提供更加友好的使用体验,加速推进 GPUStack 的全球化应用。
- UI / UX 全方位优化:全方位的 UI / UX 优化,逐帧打磨,打造业界最好用的模型推理平台。
这一版本总共包含上百项增强、修复、稳定性改进和用户体验优化,为用户的生产落地提供强大的场景支持。
有关 GPUStack 的详细信息,可以访问:
GitHub 仓库地址: https://github.com/gpustack/gpustack
GPUStack 用户文档: https://docs.gpustack.ai
重点特性介绍
vLLM 多机分布式推理
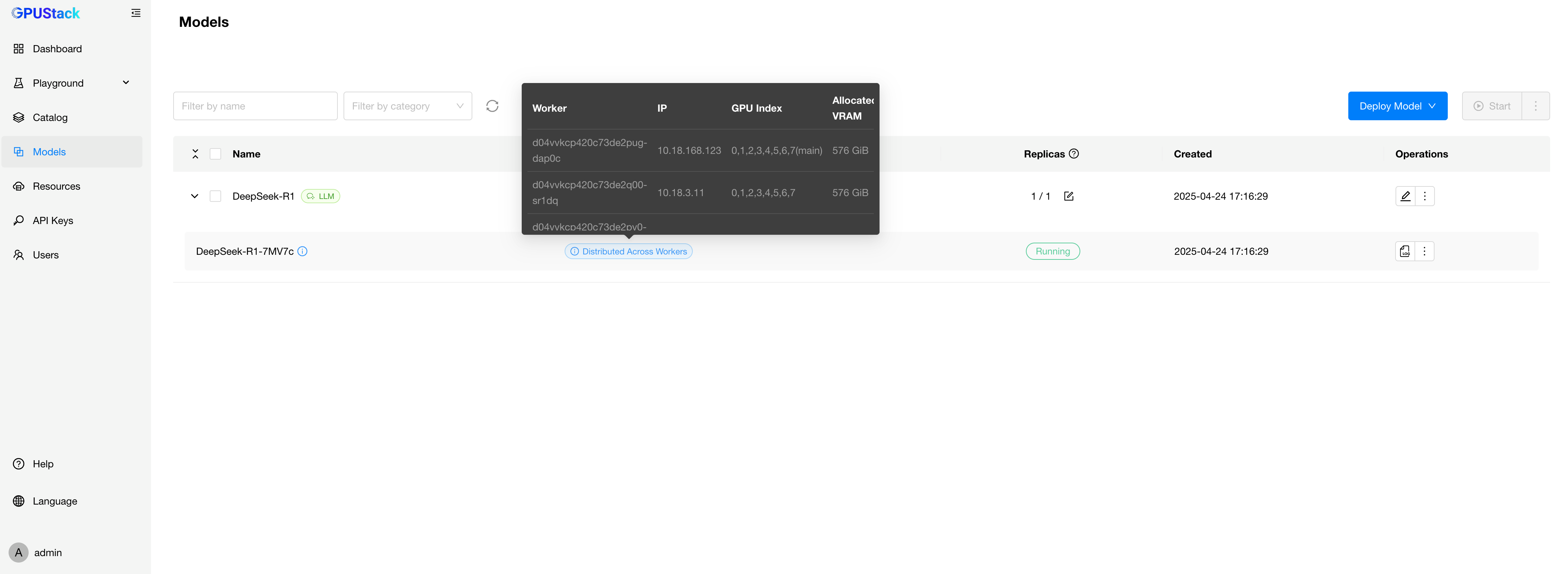
随着大语言模型的参数规模不断提升,传统单机 GPU 资源已难以满足推理部署的实际需求。为此,GPUStack 在当前版本中正式支持生产级的 vLLM 多机分布式推理能力。通过跨主机部署,将模型按张量或按层切分,分布到多个节点运行,从而实现对超大参数模型(如 DeepSeek R1、DeepSeek V3 等)的推理支持。
当前,GPUStack 对以下两类推理引擎提供分布式支持:
llama-box:异构分布式,适用于研发测试环境
• 支持 Linux、Windows 和 macOS 操作系统;
• 允许不同操作系统、不同品牌、不同规格的 GPU 混合实现异构分布式推理;
• 可在桌面或轻量服务器上快速构建异构分布式推理环境;
• 更适用于日常研发、模型验证、兼容性测试等场景。
vLLM:同构分布式,面向生产环境
• 支持在多台 Linux 服务器之间进行同构分布式推理;
• 要求参与节点的硬件环境基本一致(如 GPU 型号、数量、显存);
• 支持张量并行和流水线并行,具备良好的推理吞吐能力;
• 适合生产环境下对高并发、低延迟模型服务的部署需求。
通过 vLLM 和 llama-box 的分布式推理能力,GPUStack 能够覆盖从模型研发验证到大规模生产部署的完整流程。在研发阶段,用户可使用 llama-box 构建灵活的测试集群;在生产部署阶段,则可通过 vLLM 提供稳定可靠的推理服务能力。
![model-info]()
昇腾 MindIE 支持
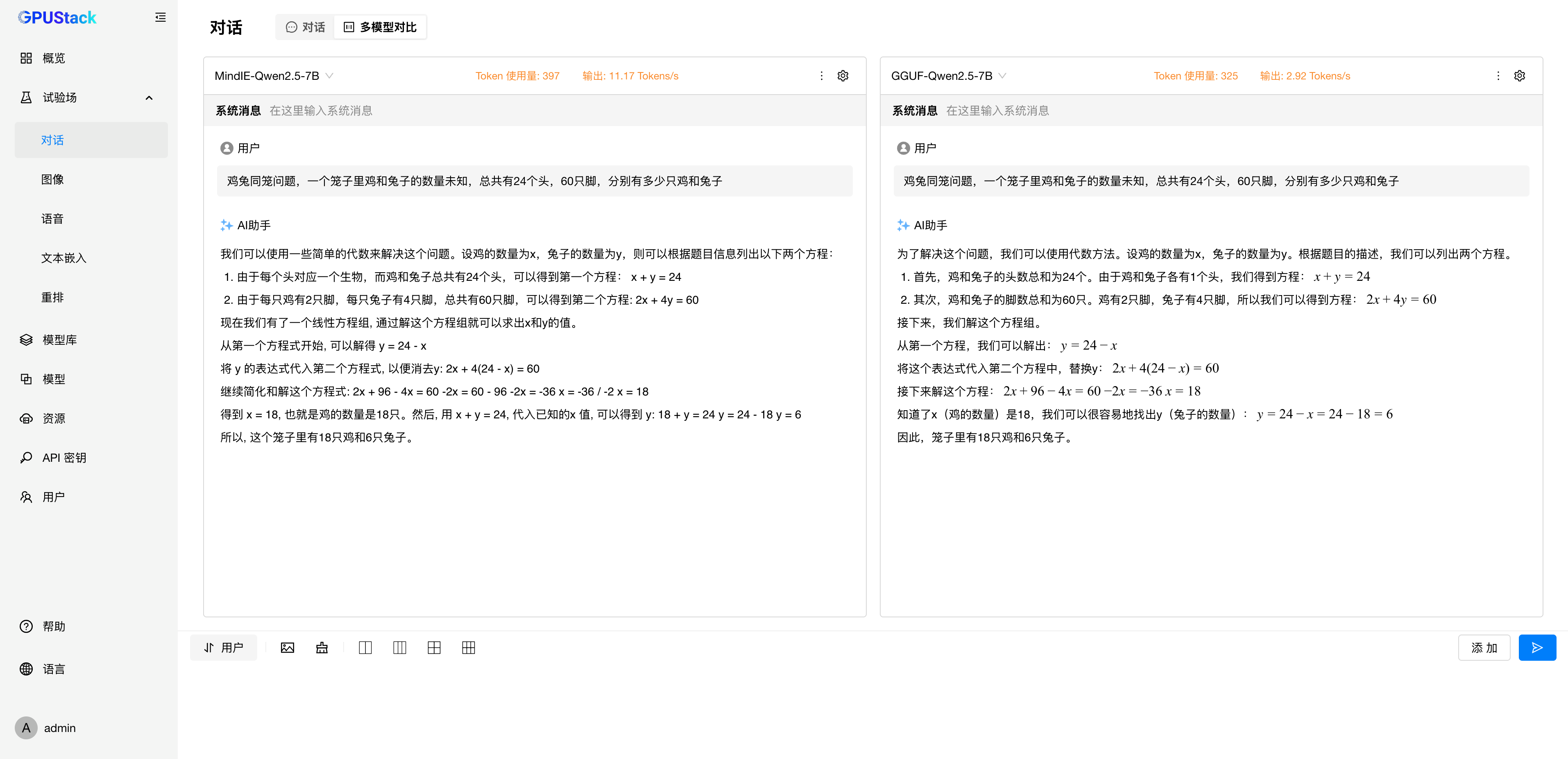
在之前版本中,GPUStack 基于 llama-box 推理引擎初步支持了昇腾 910B 和 310P 芯片的模型推理。然而由于算子支持不全及相关生态不够完善,实际使用中存在较多限制,例如只支持模型的部分量化精度,在性能和稳定性方面也弱于昇腾官方推理引擎 MindIE。
为了提升用户在昇腾 NPU 上的模型推理体验,GPUStack 现已内置集成 MindIE 推理引擎,对 910B 和 310P 提供更加稳定且高性能的模型推理能力。
MindIE 是昇腾官方推出的高性能深度学习推理框架,具备运行加速、调试调优与快速部署等多项优势,目前在昇腾硬件上表现最为出色。得益于其较为成熟的软硬件协同生态,MindIE 已成为在 NPU 上部署推理模型的主流方案。
当前,GPUStack 已完成对 MindIE 引擎的初步集成,相比于 llama-box 引擎,在部分场景可以达到数倍的推理速度提升。未来还将持续优化,并探索对更多推理引擎的支持,例如 vLLM(vLLM-Ascend),以满足在昇腾平台上的多样化模型推理需求。
![image-20250415095544399]()
模型兼容性检测
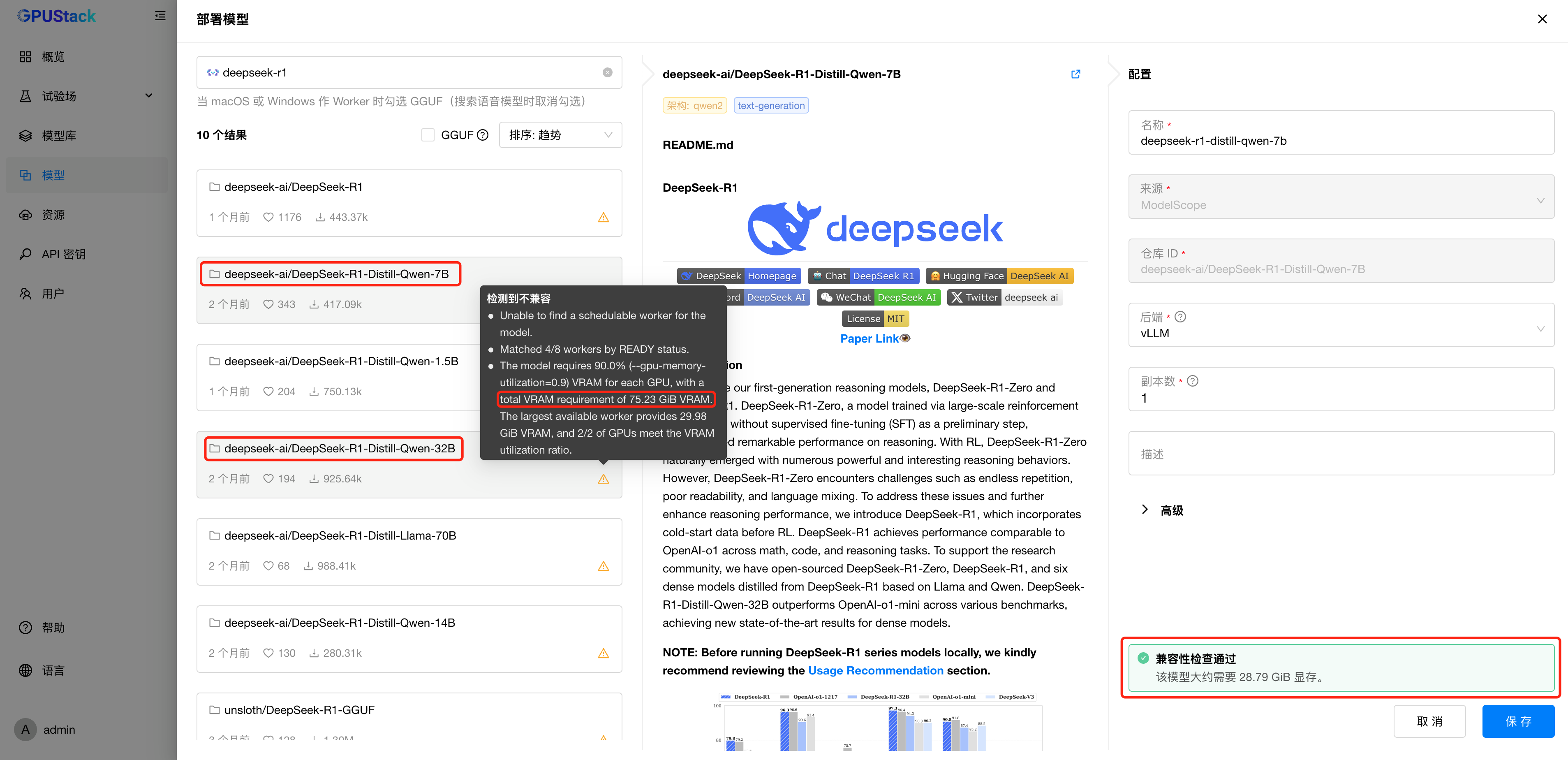
在过往版本中,用户直接从 Hugging Face 或 ModelScope 搜索任意模型进行部署时,存在一定的失败可能性。常见原因包括显存不足、操作系统与推理引擎不兼容、模型架构不被支持、本地路径配置错误等。这些问题不仅浪费时间,还严重影响用户体验。
为了解决这一痛点,GPUStack 推出了模型兼容性检测机制。系统会在部署前自动检测模型与运行环境的匹配情况,涵盖模型架构与引擎支持、操作系统兼容性、GPU 资源是否充足、本地路径是否有效等多个关键维度。通过这些检测,潜在问题能够被提前识别,并提供清晰提示,帮助用户避免不必要的部署失败。
我们设定了三个明确的目标:第一,部署前提供清晰的兼容性提示;第二,在满足条件的情况下将部署成功率提升至 99% 以上;第三,对于特殊需求场景,允许用户跳过检测,强制部署,保留灵活性。
这项功能特性将持续演进,未来将支持更多检测项、覆盖更广泛的系统环境,不断完善检测机制,全面助力用户在不同平台上实现稳定、高效的模型部署。
![image-20250421173053252]()
模型下载管理
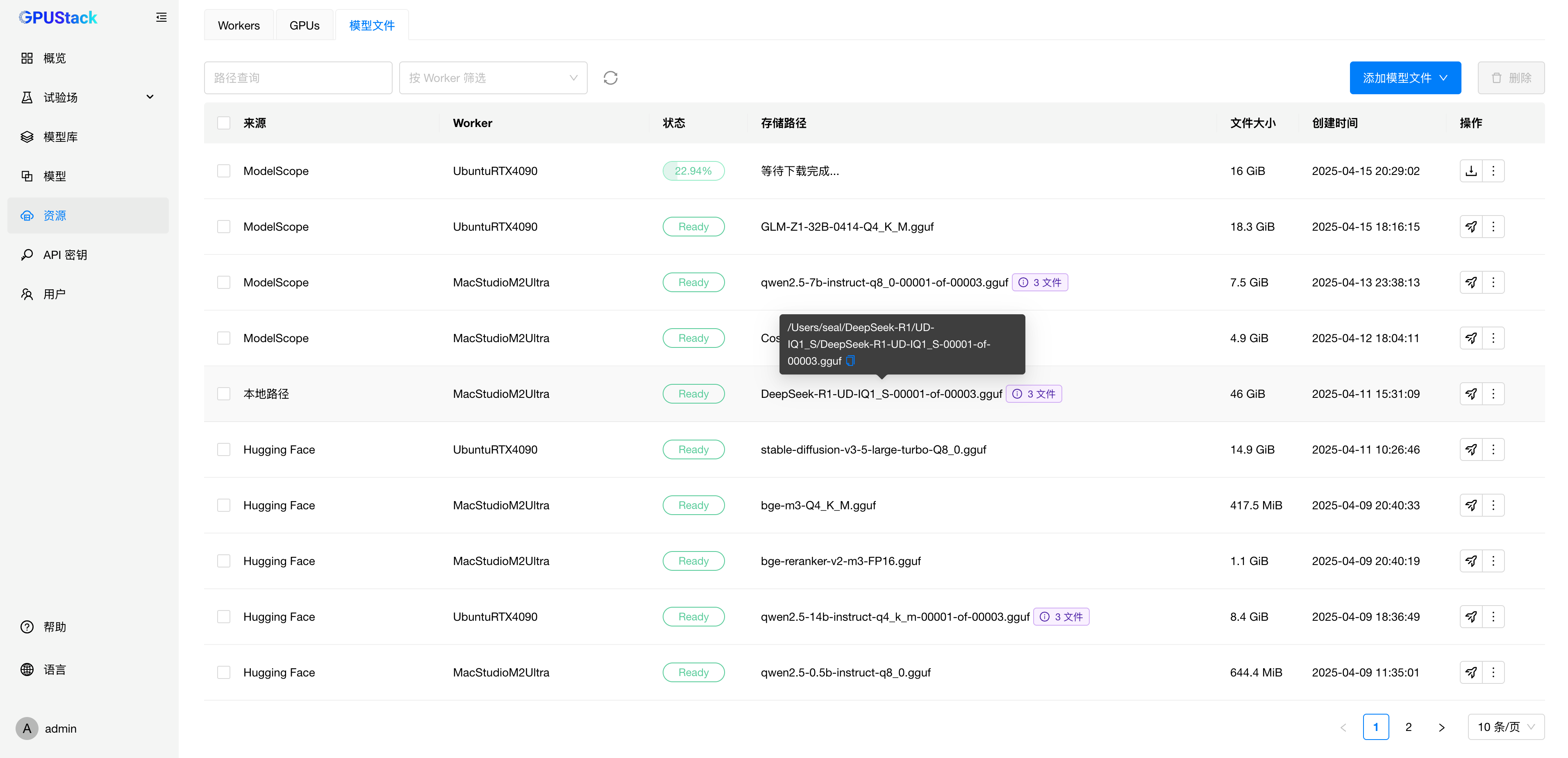
在模型部署过程中,模型文件的统一管理与高效分发始终是用户关注的核心问题。以往,模型下载通常依赖于实例启动时自动触发,既需占用 GPU 资源,又常常依赖额外的手动操作才能完成下载;同时,GPUStack 也无法管理用户预先下载到本地路径的模型文件,导致部署效率低下,管理体验不佳。
为此,GPUStack 引入了模型文件下载管理 模块:用户可在 UI 中为多个目标主机手动发起模型的下载任务,且无需占用 GPU 资源。各节点上已下载的模型文件也可在 UI 中统一可视化管理与部署,进一步提升了部署的灵活性与效率。
同时,GPUStack 还支持将本地已有的模型文件路径添加到 UI 中进行统一管理,适配私有部署、离线环境等多种使用场景。通过这一模块,既解决了用户独立下载模型文件的需求,也使 GPUStack 能够更好地支持多机分布式部署,提升了部署效率与多机协同能力。
![image-20250415204131503]()
模型故障自动恢复
在追求高可用性和稳定性的生产环境中,模型推理服务的稳定性至关重要。为了进一步提升这一点,GPUStack 引入了模型故障自动恢复机制!当模型发生故障时,GPUStack 会自动触发恢复机制,迅速尝试重新启动模型,确保服务不中断。
同时,为了避免过于频繁的无效重启,GPUStack 采用了5分钟为上限的指数退避延迟机制,在故障持续时逐步延迟重启,避免系统资源的浪费。总体而言,v0.6 版本提供的模型故障自动恢复机制大幅提升了模型服务的容错能力,让生产的模型推理更加稳健!
端口暴露优化
在旧版本架构中,每台 Worker 节点需为每个模型实例开放端口访问,以供 Server 端进行推理请求的转发。在用户大规模使用时暴露了一些问题:由于大量端口需要映射,容器启停缓慢,且在启动时容易发生端口冲突;防火墙配置容易遗漏,导致推理请求转发异常。此外,也不支持用户自定义端口范围。
为此,我们在 v0.6 版本中重构了端口暴露机制:推理请求从 API 入口到模型实例的链路现已通过统一的代理转发,无需再为每个模型实例开放端口访问。同时优化了端口分配,将端口暴露范围压缩超过 96%,显著降低部署复杂度和运维风险。同时也支持用户自定义端口配置,使系统能够灵活适配不同的网络环境与安全策略,为用户带来更简单、稳定的部署体验。
增强国际化支持
目前 GPUStack 的用户遍布全球上百个国家和地区,随着 GPUStack 用户群体在全球范围内的持续扩大,我们致力于为不同语言背景的开发者提供一致、便捷的使用体验。本次 GPUStack 社区用户贡献了俄语 和日语支持,标志着 GPUStack 在国际化进程中的又一重要里程碑。
通过持续拓展多语言能力,GPUStack 为全球社区用户创造了更加包容与高效的使用体验。未来,我们将继续深化本地化支持,为全球用户提供更全面、更优质的服务体验,加速推动 AI 应用的全球落地与普及。
![image-20250413233340395]()
![image-20250413233303590]()
全方位的 UI / UX 优化
在本次版本中,我们对 UI / UX 进行了全方位优化,从信息展示到交互细节,几乎每一处都经过精心打磨,力求带来更流畅、更易用的使用体验。过去几个月收集的每一条用户建议,都是此次优化的重要参考。
我们始终坚持一个目标:打造业界最好用的模型推理平台,而 GPUStack 正在持续朝这一目标稳步前进。也正因为有用户的积极反馈,我们才能不断迭代优化------如果你有任何建议或想法,欢迎随时向我们提出,我们会认真评估并持续改进。
参与开源
想要了解更多关于 GPUStack 的信息,可以访问我们的仓库地址:https://github.com/gpustack/gpustack。如果你对 GPUStack 有任何建议,欢迎提交 GitHub issue 。在体验 GPUStack 或提交 issue 之前,请在我们的 GitHub 仓库上点亮 Star ⭐️关注我们,也非常欢迎大家一起参与到这个开源项目中!
如果觉得对你有帮助,欢迎点赞 、转发 、关注。