![]()
随着数据量的爆炸式增长和业务需求的多样化,许多企业的大数据平台在多年的演进中堆积了 Hadoop、Hive、Spark、Flink、Kafka 等数十种组件,复杂度的累积使架构演变为"难以维护的黑盒",企业用户不得不承受着传统数据架构的慢性疼痛。亚舟将在本次分享中,以用户行为分析场景为例,介绍 Databend Cloud 如何化繁为简,帮助企业摆脱复杂技术栈的束缚,快速构建端到端的数据管道,从而实现一套可扩展、灵活、低成本的用户行为数据分析架构。
在 Data Infra 第 24 期活动中,我们邀请到 Databend Cloud 研发负责人李亚舟 ,分享如何使用湖仓一体的 Databend Cloud 使大数据架构化繁为简。
以下是精彩演讲实录: :
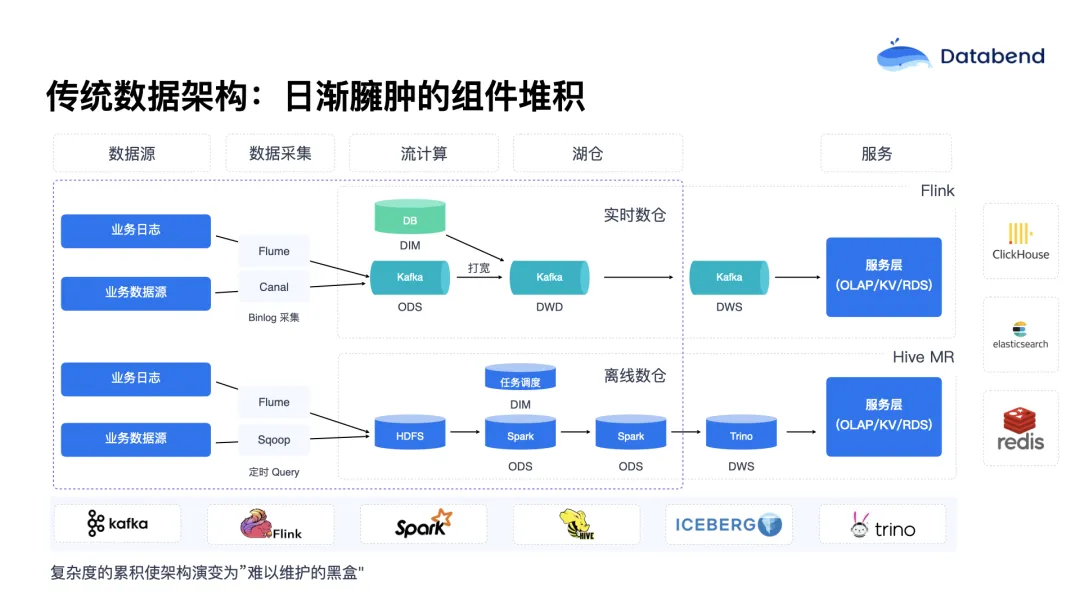
在传统意义上,大数据架构基本上是沿袭自 Hadoop 技术栈。随着技术的不断演进与迭代,整个架构中涉及的组件数量也不断增加。除了数据的存储与分析之外,还涵盖了数据采集、任务调度、实时分析、批处理、数据湖等多个方面。随着时间的推移,这些组件在架构中日渐臃肿。
![]()
从积极的一面来看,这样的架构具有较强的可扩展性;但从现实使用层面看,它更像是一种"堆叠"而非真正的"统一架构"。随着组件数量的增加,系统的整体复杂度也在不断提高。每新增一个组件,不仅在能力层面带来了提升,同时也带来了新的复杂性。比如在一个数据采集到 ETL 再到报表输出的完整链路中,每增加一个组件,都会带来数据口径管理上的额外挑战,一旦出问题,需要跨多个组件排查,复杂度呈"层级式增长"。
此外,每一个组件往往都需要专门的技术专家进行管理。例如像 Flink、Spark 这样的核心计算组件,都要求数据工程师或架构师对其具备较深入的理解,才能有效支持日常的数据开发需求。
更重要的是,这些组件往往缺乏弹性。用户在使用这些组件时,不仅要掌握其工作原理,还需要根据其特点进行资源的精细调度。同时,不同组件之间的权限体系往往无法打通,这也进一步导致了数据孤岛的出现。而在如今对安全与合规性要求越来越高的背景下,每新增一个组件,也意味着整个系统的攻击面进一步扩大,从而加重了安全维护的负担。
综合来看,这一切最终带来的结果是:每当进行新的数据开发任务时,工程师们不仅要理解架构的复杂性,还要掌握业务数据本身的复杂性,同时还要满足合规性的多重要求。这样的工作模式,使得数据开发周期变得越来越难以控制。
Databend Cloud 简化架构的思路
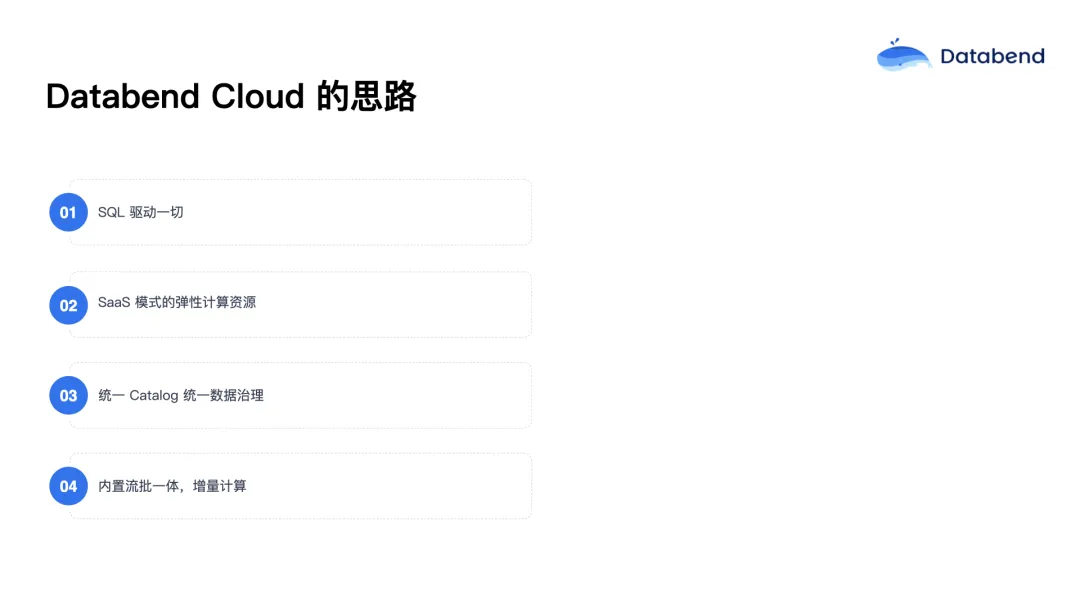
Databend Cloud 的目标就是简化整个数据架构,让用户能够更专注于业务本身的数据需求,而不是被底层技术复杂度所困扰。
![]()
首先,将整个数据架构视为一个统一的整体性解决方案 ,而非一堆松散拼接的技术组件。在对外接口上,Databend Cloud 的核心理念是:一切皆可通过 SQL 驱动。无论是日常的数据开发任务,还是复杂的数据处理流程,用户都可以统一使用 SQL 作为开发语言,极大地降低了技术门槛。
其次,Databend Cloud 是基于 SaaS 模式构建的云原生数据平台,提供托管式、弹性化资源管理能力,真正实现了免运维。用户无需关心底层架构中的具体组件,只需聚焦在业务逻辑本身。
因为是一个统一的平台,Databend Cloud 具备以下几个核心优势:
- 统一的 元数据管理 (Catalog) ;
- 统一的 数据治理 体系;
- 对流批数据的支持 ,实现流批一体的增量计算能力;
- 降低数据处理链路中对多组件的依赖,从而减少整体架构复杂度。
案例解析: 用户行为分析 数据架构如何化简
用户行为数据以及相关的"埋点"指标,是数据仓库和各种数据架构中最核心的数据源之一。尤其对于互联网公司来说,用户行为数据往往是其最宝贵的数据资产之一。这类数据能够直接反映用户是如何使用 APP 的,也为后续的产品优化和用户体验改进提供了依据。
然而,用户行为数据分析本身具备一些特性,使得构建一套可扩展、灵活、低成本的用户行为数据分析架构具有相当大的挑战。
首先是数据流量高、容量大。 用户行为数据是在用户操作 APP 时持续不断地产生的,因此数据量庞大、写入频繁。
另一方面,分析场景既包括结构较为固定的 ****BI 报表 ,也涵盖探索性分析所需的临时复杂查询(Adhoc SQL),需要系统兼顾稳定性与灵活性。
其次,这类数据往往需要兼顾结构化和半结构化数据。 随着应用不断迭代,行为日志的种类也在持续变化,因此一个固定的数据结构难以覆盖整个应用生命周期的所有需求。
此外,对于一些异常行为的实时检测和响应,也对系统的实时性提出了较高要求。
![]()
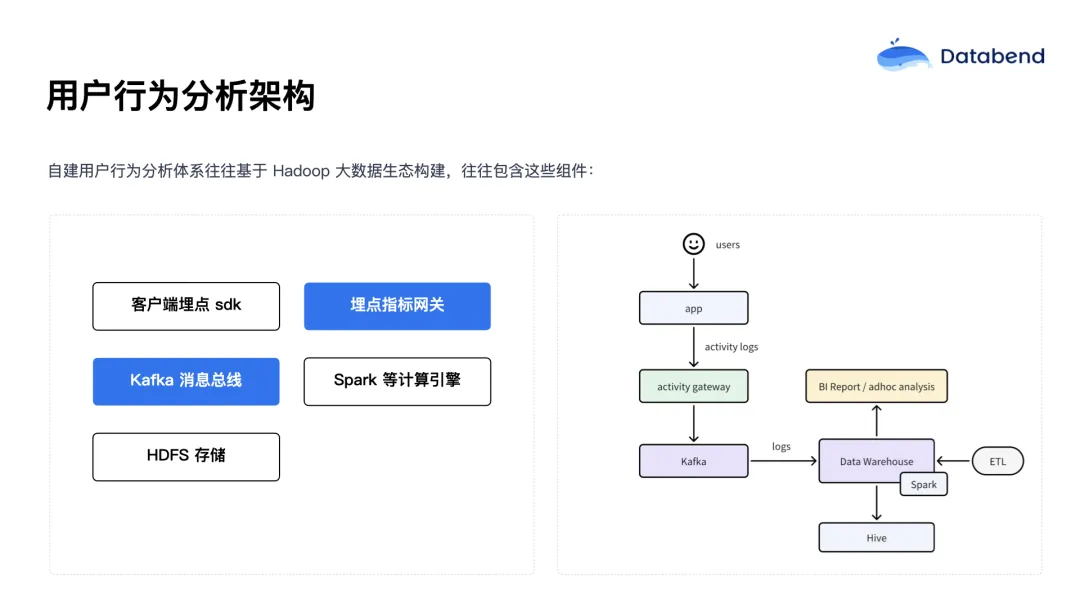
传统的用户行为分析架构通常基于 Hadoop 等大数据生态系统构建,主要由以下组件构成:
- 埋点 ****SDK:部署在客户端上,像日志一样记录用户操作;
- 数据收集 网关:汇聚客户端日志数据;
- 消息队列 (如 Kafka ) :作为数据传输的中间层;
- 数据仓库:对收集来的原始日志进行加工处理;
- ETL 工具链(如 Spark + Airflow) :进行数据清洗、转换、调度;
- BI 工具或临时查询接口:用于分析和呈现结果。
表面上看这个架构似乎并不复杂,但在实际运维中,每一个组件都是潜在的数据源。例如,Kafka 本身就是一个分布式系统,还依赖于 ZooKeeper;Kafka 到数据仓库之间通常还需同步组件;数据 ETL 过程可能依赖 Airflow,而 Spark 又需要运行在 Yarn 等资源调度系统中;元数据管理可能还要依赖 Hive Metastore,而底层存储如 HDFS 又有扩展性和稳定性上的挑战。
当所有这些组件都暴露给开发和运维团队时,就意味着每一个环节都可能出问题。要让团队成员具备对每个组件的深入理解和维护能力,几乎不现实。这种架构整体复杂度非常高,且在成本控制方面面临巨大挑战:我们常常不知道该从哪个环节入手进行优化。
因此,在重新思考用户行为分析架构时,我们应回归"第一性原理":
![]()
- 降低存储成本:建议将用户行为日志存储在对象存储中,因为对象存储具备极高的性价比;
- 降低运维成本:尽量采用简洁的架构设计,减少组件数量,从而减少各组件之间的依赖和故障点。
成本并不仅限于存储和计算资源,维护成本往往是被忽视但又最为关键的一部分。在许多大数据架构中,维护成本甚至高于资源本身。当维护成本足够低时,就能更高效地优化资源使用;而在一个复杂架构中,即使理论上存在降低资源成本的空间,高昂的维护开销也会让这变得难以实现。
Databend Cloud 架构设计
Databend Cloud 是一个从第一天起就完全面向对象存储 设计的平台,其原生的云架构使其能够充分利用对象存储的高吞吐、低成本 特性。相比传统数据架构,Databend 在执行层的设计上可最大化发挥对象存储的优势,同时实现了计算与存储的完全解耦。
Databend Cloud 完全兼容标准 SQL(兼容 ANSI SQL),支持对结构化与半结构化数据的分析,并提供了强大的自定义 UDF(用户自定义函数)能力。在处理非结构化数据场景下,用户可以通过编写 JavaScript 函数灵活扩展系统能力:
- 对于简单逻辑,可以使用内置 SQL 函数直接完成;
- 对于复杂逻辑,可以通过 JavaScript 编写 UDF 函数来实现,极大提升了灵活性和扩展性。
此外,Databend 是完全无状态 的,天然支持云原生的自动弹性伸缩特性。其内置的 Task 调度机制,也让用户无需再部署和维护独立的调度器组件,从而进一步简化系统架构。
Databend Cloud 在企业级数据场景中的落地实践
目前,Databend Cloud 已在众多关键企业级数据场景中实现落地,包括:
- 离线数据分析替代方案;
- 实时推荐系统;
- 日志存储与 Elasticsearch 替换;
- 在线数据库归档场景;
- 用户行为数据分析。
其中,针对用户行为数据分析,Databend Cloud 提供了极具优势的简化架构和运维体验。
简洁的数据摄入与分析流程
![]()
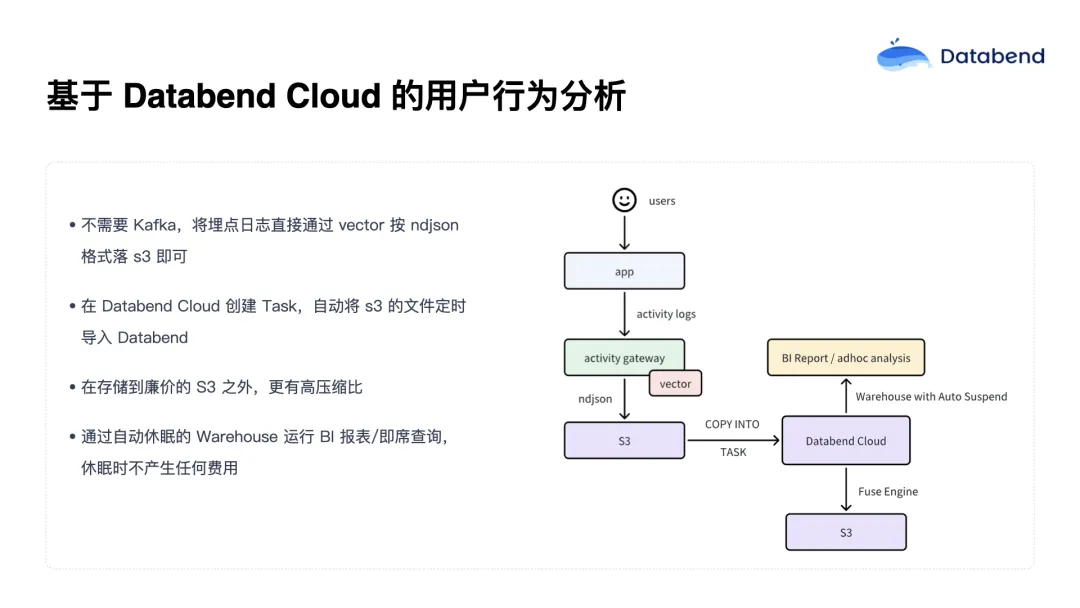
在 Databend Cloud 架构中,数据摄入流程极为简化:
- 用户日志数据写入对象存储(如 S3、阿里云 OSS、腾讯云 COS 等);
- Databend Cloud 通过内置 Task 自动从对象存储中拉取数据;
- 数据进入仓库后继续落入对象存储,完成分析闭环。
整个流程中,实际涉及的仅有两个组件:
- 对象存储(S3 等):既是数据摄入入口,又是数据持久化载体;
- Databend Cloud:负责计算、调度、查询与管理。
相比传统方案中 Kafka + Kafka Connect 的复杂堆叠架构,Databend 仅需两个组件即可构建出一套稳定高效的数据分析系统,极大降低了系统复杂性和运维成本。
架构是否真的简单?
有人可能会质疑:"Databend Cloud 架构看起来简单,但会不会只是'看起来简单',实际内部也很复杂?"事实上,Databend Cloud 简洁性来自于其底层架构的云原生设计:
- 每一个计算节点(Warehouse)本身是无状态的;
- 调度轻松、弹性强,可以随时拉起或关闭;
- 系统负载与资源消耗完全按需分配,避免资源浪费。
此外,BI 报表通常并不需要实现实时、持续的访问。换句话说,BI 报表的查询频率相对较低,一般只需要在每天或每小时生成一次结果即可。而对于交互式的即时查询场景,通常也是数据分析师在特定时段内手动发起的,访问频率远不如用户请求那样高频且连续。
正因为如此,这类场景具备一个很好的特性------可自动休眠。当分析师不活跃,或暂时不需要报表输出时,系统可以自动进入休眠状态,等真正需要进行数据分析或报表查询时再"唤醒"。这样一来,整个系统在一天 24 小时中可能只有 2~3 小时是真正活跃的,其余时间均可释放资源,极大地降低了资源占用和成本。因此,这种架构在成本控制方面表现非常出色。
一个完整的用户行为数据分析流程
接下来介绍一下在 Databend Cloud 上,如何构建一个完整的用户行为分析流程。
![]()
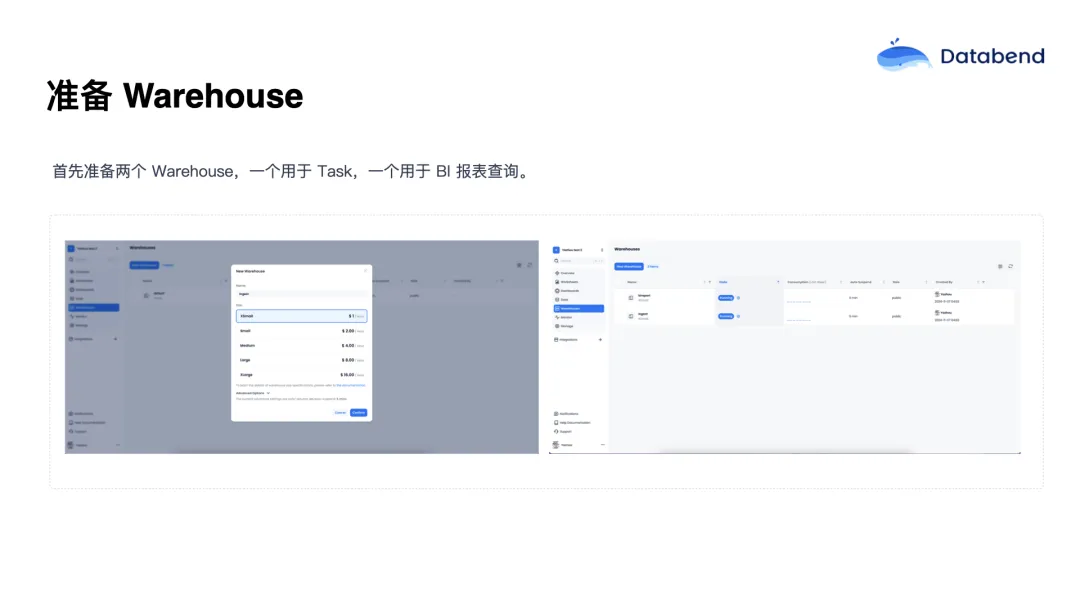
首先,在 Databend Cloud 上,可以创建一个 Warehouse。Databend 的 Warehouse 是基于使用时长计费的,正如前面提到的,BI 报表以及数据分析师的工作通常集中在每天的两到三个小时内,所以这套按需计费模型可以带来非常可观的成本节约。
多个 Warehouse 的协同
在实际使用中,通常会创建两个 Warehouse:
- Ingest Warehouse:用于数据摄入和调度 Task;
- BI Report Warehouse:用于 BI 报表查询。
这么做的原因是,数据摄入通常是一个耗时较长但资源需求较低的过程,所以可以用规格更小的 Warehouse 来节省资源。而报表查询往往对响应速度要求更高,所以可以为其单独配置资源。
![]()
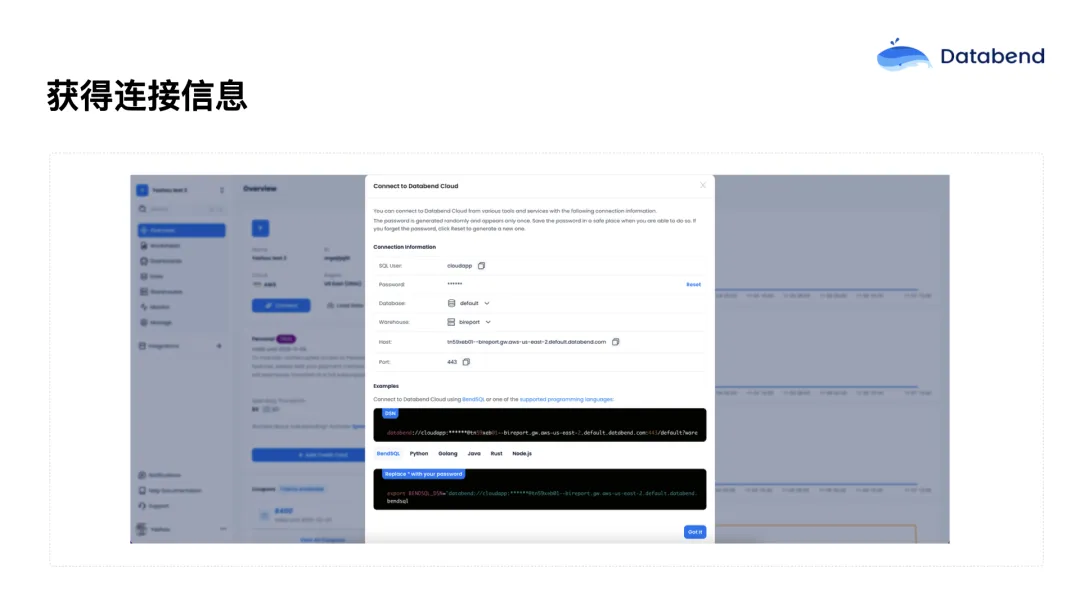
Warehouse 创建好之后,可以在 Databend Cloud 首页中获取连接串信息(Connect 字段),用于连接各种 Driver 或生态系统中的工具。
数据建表与 Stage 设置
![]()
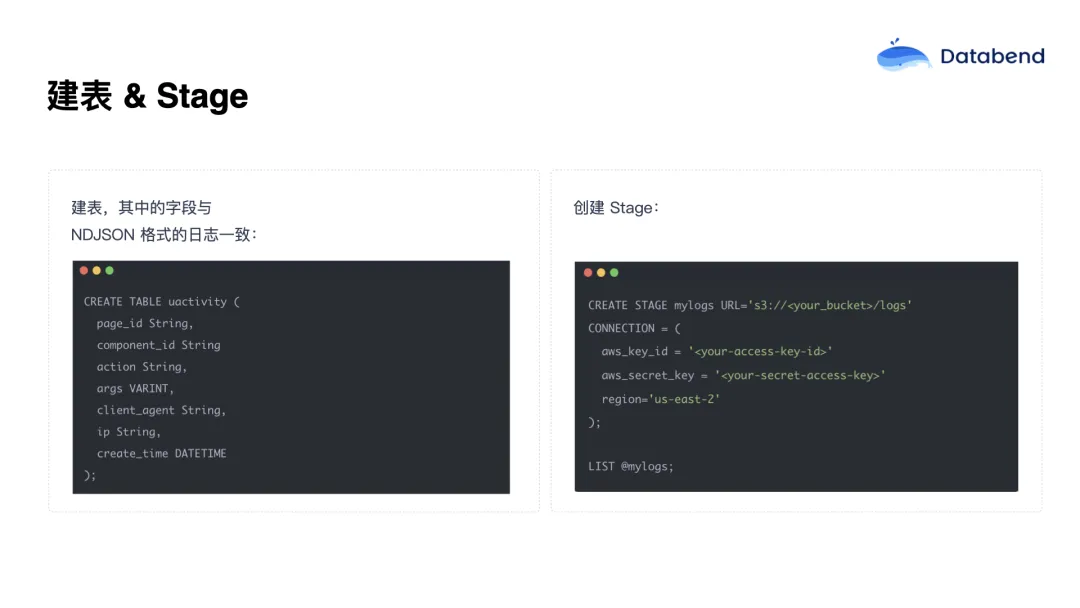
先创建一个行为日志表,比如叫 activity,表结构在实际生产中可能会更宽,但此处为演示做了简化。
然后再创建一个 Stage。Stage 可以理解为映射到对象存储(如 S3)中的某个目录。只要将日志文件写入该目录,Databend Cloud 就能自动识别并导入。
使用 Task 实现自动摄入
![]()
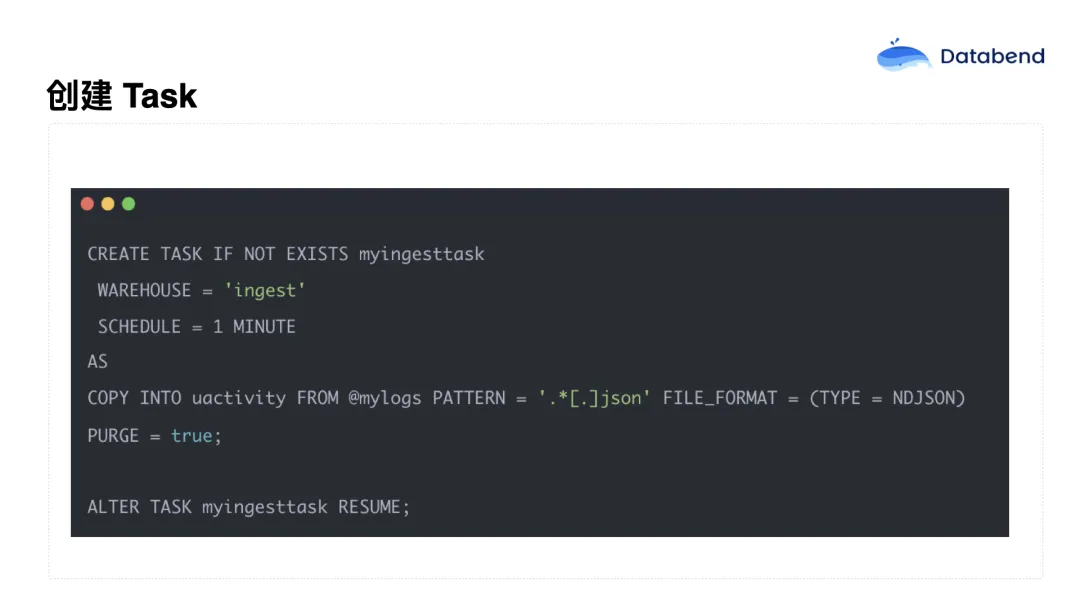
接着创建一个 Task,设置为每分钟执行一次。这个 Task 的作用是将指定 Stage(也就是 S3 目录)中的 JSON 文件自动导入到 Databend 中的表里。
一个关键参数是 purge = true,它表示每个文件在成功导入后会被自动删除。这样一来,S3 中的目录就相当于一个简化的消息队列 ,Databend 的 COPY INTO 语句具备事务性保障,确保文件数据不会重复导入,也不会遗漏。这一机制大大简化了架构设计,同时避免了 Kafka Connect 这类组件带来的复杂性和成本。
Databend Cloud 架构优势
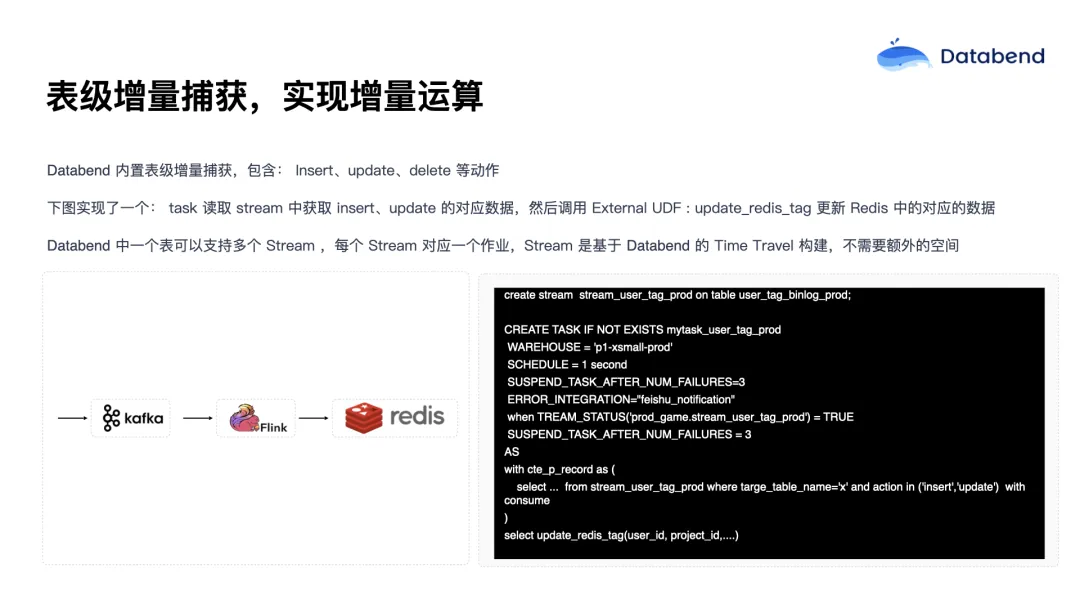
表级增量捕获,实现增量运算
![]()
数据成功导入后,可以进行后续的 ETL 或分析处理。Databend 提供了一个非常有价值的特性 ------ Stream。每一张表都可以开启一个 Stream,用于捕获表的增量变更(CDC)。
在查询一个 Stream 时,系统只会返回自上一次提交以来新增的记录(或变更记录),而且同样具备事务保障 ------ 只有当前 Task 执行成功并提交之后,Stream 的"点位"才会前移,确保数据处理的准确性和一致性。
借助这个机制,可以实现增量处理的 ETL,将新导入的数据加工后合并到目标表中。
这对提升 ETL 效率非常关键 ------ 在传统模式下,每次 ETL 都需要全表扫描,尤其在表达到数百 TB 或 PB 级别时,全量处理几乎是不可行的。而通过 Stream 的增量处理,每天只处理新增数据,性能和资源成本都能大幅下降。
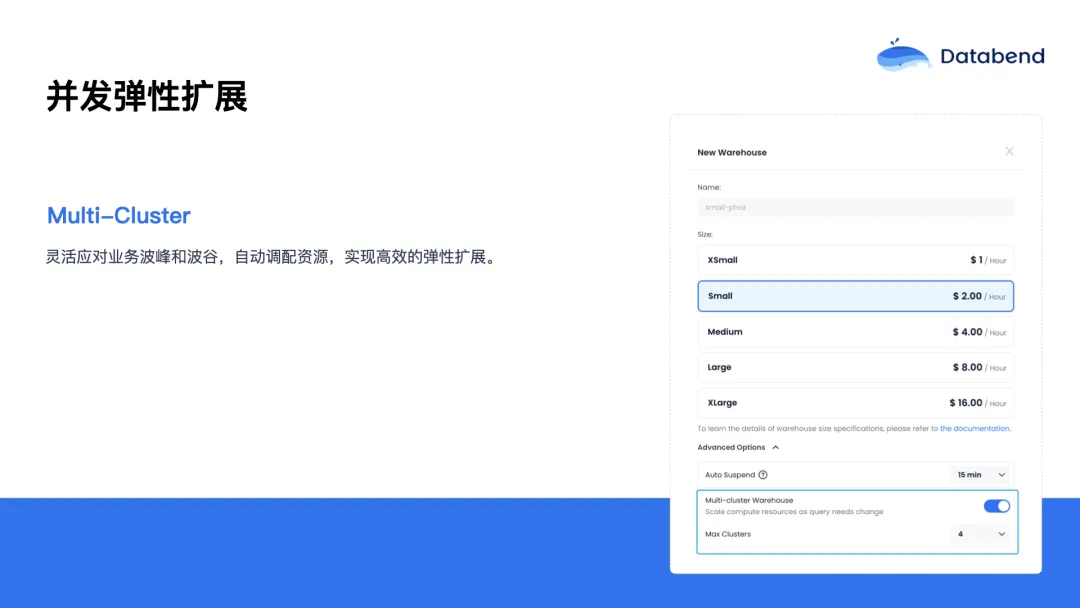
并发弹性扩展
![]()
除了分析师使用 BI 报表和交互式查询,很多业务场景还要求高并发的在线查询,比如后台数据看板、To-C 用户画像服务等。
为此,Databend Cloud 提供了强大的 Multi-cluster 弹性能力:
- 当系统检测到查询请求的并发量上涨时,可以自动扩展计算资源;
- 比如起始是一个 Small 规格的集群,用户量增大时可以自动弹出两个或更多的计算节点;
- 配置 max_clusters = 4 时,系统最多可以弹出 8 倍算力;
- 整个过程是完全自动的,无需用户手动干预。
这让系统在面对高并发访问时,依然能够保持良好的响应能力。
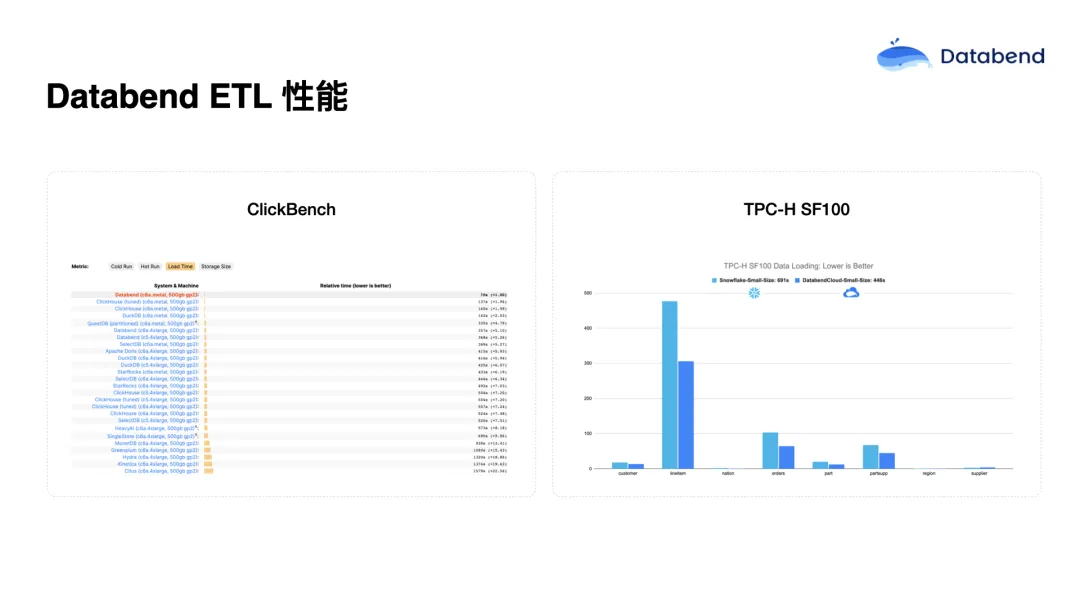
全量 ETL 性能优势
虽然前面强调了增量处理的重要性,但 Databend 在全量 ETL 的性能表现也非常出色。
![]()
在多个权威基准测试中:
- ClickBench 和 TPC-H 的测试结果表明,Databend 的查询和数据加载性能都处于领先水平;
- 在一些查询任务中,Databend 显著优于 ClickHouse 和 Snowflake;
- 特别是在数据加载阶段,Databend 在多项榜单中获得第一名的成绩。
降本增效
![]()
在当前的市场环境下,降本增效已经成为一项核心议题。Databend Cloud 正是在这一背景下,为企业提供的一个整体性降本增效解决方案。
Databend Cloud 在部分替换 Trino 场景下能够帮助用户降低多达 75% 的成本。这主要得益于两个方面:其一是基于对象存储的架构,具备高性价比;其二是其计算引擎在 CPU 使用效率和实例配置方面具有明显优势。在特定的替换场景中,甚至可以达到 90% 的成本降低。这是因为对象存储的数据具备更高的压缩比,同时配合高效的扫描性能,使其在日志类场景中能够替代传统的 ES(Elasticsearch)反向索引,规避昂贵的索引维护和本地磁盘成本。
在数据归档场景中,其降本逻辑类似------通过廉价的对象存储和高压缩比的数据处理方式,大幅降低存储开销。例如,一位大型客户每天可向系统中摄入 1PB 的数据,这在传统架构下几乎是难以承受的成本,而在 Databend Cloud 的支持下,成本则变得极具竞争力。
Databend Cloud 展望
![]()
在当前数据架构日益复杂的背景下,组件堆叠和系统维护成本不断上升。Databend Cloud 所强调的一体化、云原生和轻量级架构,正是为了解决这一问题。它不仅能有效降低存储和计算成本,还能极大地减少维护负担,从而成为企业在数据架构选型时的重要考量因素。
建议将对象存储作为架构设计中的核心部分。实践证明,在数仓场景下,对象存储不仅具备显著的性价比优势,还能配合计算引擎实现出色的性能表现。通过 Databend Cloud,用户可以快速构建一套高性能、低成本、连接灵活的数据分析架构。在满足业务需求的同时,这种简洁的架构设计也意味着更低的运维成本,而低运维成本也间接带来了资源成本的进一步降低。
![]()
关于 2025 年的发展规划,目标是打造业内最高可用性的数据平台,并进一步提升资源管理的精细化能力,实现资源分组与隔离的灵活配置,同时在本地部署和资源调度之间实现更好的平衡。
在功能层面,Databend 将持续增强对地理空间分析的支持。值得一提的是,地理空间能力与 AI 之间也存在密切关系。例如,AI 任务中常涉及到空间距离的相似性计算,因此也将探索如何利用 Databend 构建面向 AI 的数据仓库。目标是进一步扩展其能力,打造一个支持多模态的数据仓库平台,真正实现数据与 AI 的深度融合。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab...