导读:浙江霖梓早期使用 CDH 产品套件搭建了大数据系统,面临业务逻辑冗余、查询效率低下等问题,基于 Apache Doris 进行整体架构与表结构的重构,并基于湖仓一体和查询加速展开深度探索与实践,打造了 Doris + Paimon 的实时/离线一体化湖仓架构,实现查询提速 30 倍、资源成本节省 67% 等显著成效。
浙江霖梓是一家专注于深度学习和人工智能应用的金融创新企业,自 2018 年成立以来,专注于深度学习和⼈⼯智能的应⽤ ,通过构建数据迭代能⼒形成结构化的数据决策产品,为企业提供精准经营决策。同时,提供基于大数据的风控能力的一系列高效便捷的金融服务产品。
然而,随着业务的持续扩展,大数据业务系统的局限逐渐暴露:报表系统计算缓慢、运维成本持续攀升、组件间的高度耦合导致架构稳定性较差等,严重影响了大数据系统产出效率,因此浙江霖梓引入 Doris+Paimon 重新构建了实时/离线一体化湖仓架构,为反欺诈策略、用户⾏为分析、BI 应用等若干系统提供了高效准确的服务,实现了查询提速 30 倍、资源成本节省 67% 等显著成效。
早期架构及痛点
下图是早期的 CDH 架构示意图,MySQL 数据通过 Sqoop 全量导入至 Hive,埋点数据通过 Java 程序清洗后进入 Flume 的 source 端,并最终 sink 到 Hive 的分区表中,离线数仓任务的 ETL 由 Hive 执行,批处理作业则通过 Spark SQL 运行,所有任务都从 ODS 层出发直接进入到 APP 层。数据开发与分析工作则依赖 CDH 自带的 Hue 平台,任务调度依赖 easyScheduler,最终与自主研发的报表平台对接,实现数据的可视化。
![早期架构及痛点.PNG]()
随着业务扩展,早期架构的局限逐渐暴露:数据采集、变更及分析效率低下的同时,整体运维成本也在持续攀升,并且各组件间的高度耦合降低了架构的整体稳定性。此外,由于各部门未统一指标⼝径,不同取数逻辑的分析结果存在较大差异,使得业务痛点的精准定位变得异常困难,传统的 Hive+BI 系统已无法满足需求。
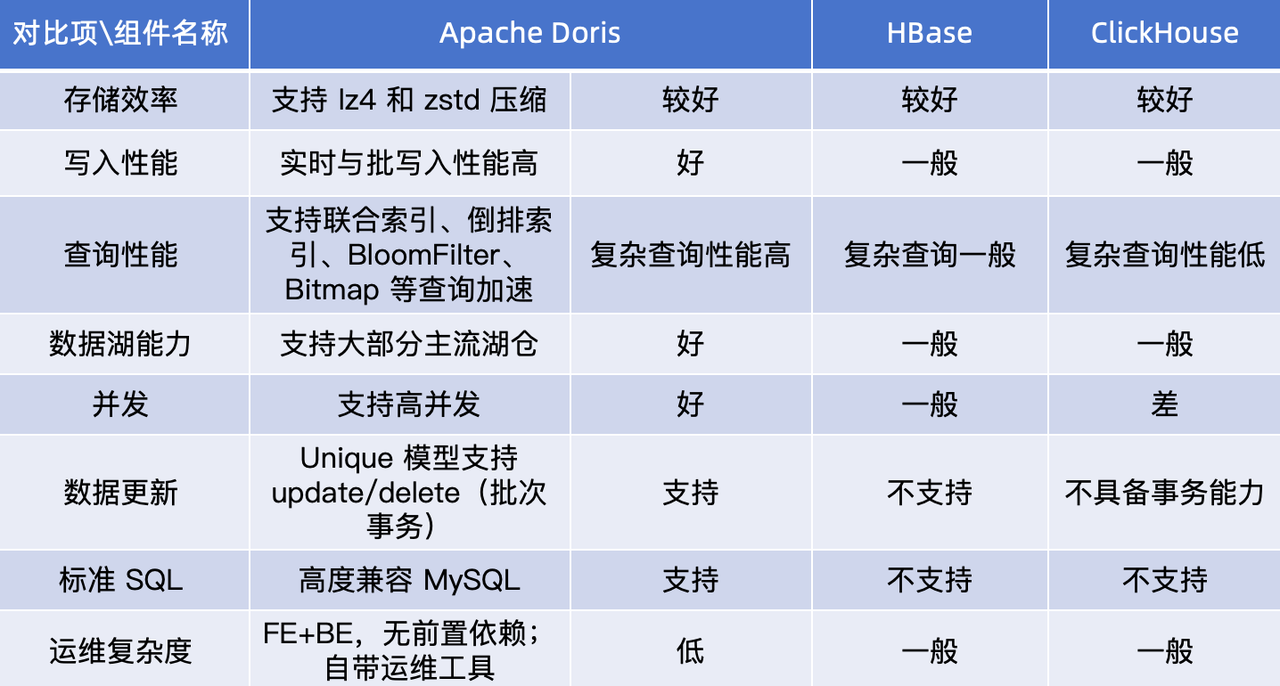
为了解决上述痛点,浙江霖梓考察了市⾯上较为常⻅的大数据分析组件,如 HBase、ClickHouse、Apache Doris 等,最终从查询性能、写入性能、投⼊成本等⽅⾯评估,最终选择了综合实⼒⾮常突出的 Apache Doris。以下为前期技术选型调研结果:
![早期架构及痛点-2.PNG]()
相较于其他产品,Apache Doris 的核心优势如下:
- 查询快:⽀持物化视图和向量化执⾏引擎,并⽀持多种表模型以及 Rollup 、BloomFilter、倒排索引等,离线跑批速度非常快,并对查询性能有显著加速效果。
- 存储省:通过表的优化和冷热数据分层特性,能够充分利用机械盘和固态盘,显著提升资源利用率。此外,采用高效的 ZSTD 压缩算法,压缩比高达 10 倍,大幅降低了存储费用。
- 运维简单:不依赖外部系统, 原架构一旦某个服务发生异常,与其关联的服务都会受到影响,给运维增加了难度。⽽ Apache Doris 的原生运维工具 Doris Manager 可以满⾜⽇常绝⼤多数的运维需求,再加上 Doris 架构简单且不存在⼩⽂件问题,在线扩展节点十分方便,⼤⼤降低了运维难度。
- 便捷迁移:兼容 MySQL 协议,报表系统只需要修改源配置就可以轻松对接。
- 社区活跃:Apache Doris 的社区⾮常活跃,技术团队解决问题的能⼒较强;版本迭代速度快,能很好的解决业务痛点。
基于 Apache Doris 的实时/离线一体化湖仓架构
![基于 Apache Doris 的实时:离线一体化湖仓架构-1.PNG]()
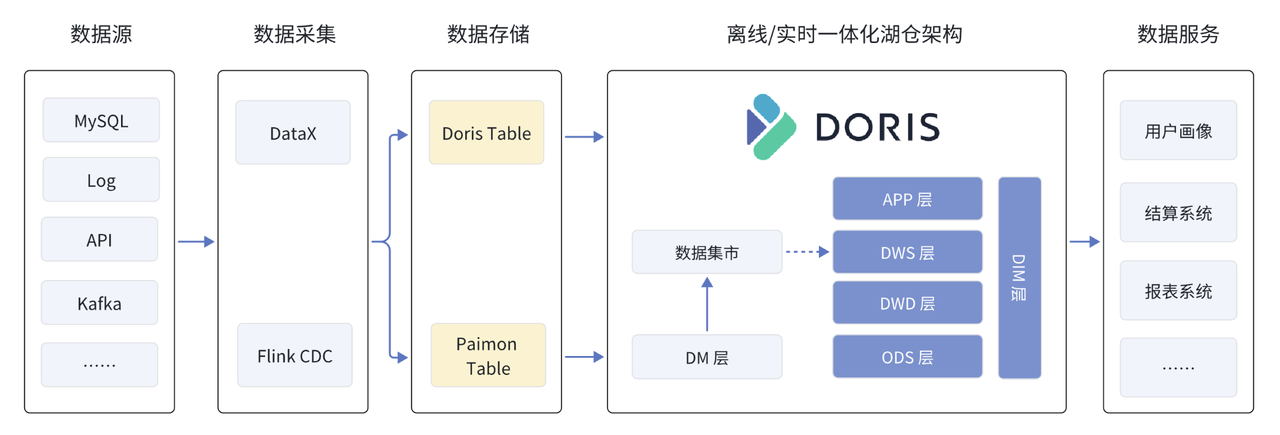
经过七个月的设计与实施,最终完成了基于 Apache Doris 离线 / 实时一体化湖仓统一架构。如上图所示,离线数据通过 DataX 同步、实时数据通过 Flink CDC 采集加工,这些数据最终存储到 Doris 或 Paimon 表格式中。
目前基于 Paimon 的全量数据入湖还在持续完善,原先的部分离线数据通过 Flink CDC 实时入湖,而另一部分会直接进入 Doris 来缩短数据链路。这些数据经由 Doris 统一分析处理后,最终服务于自研数据服务。在这其中,Doris 集群被灵活拆分为多个资源组,分别满足离线数仓、数据集市、实时业务监控等不同上游服务的数据处理与分析需求。Apache Doris 的引入,也带来许多显著收益:
- 查询效率提升 :Hive ⾯对复杂的⼤数据量跑批任务时,耗时往往超过 20min,亿级别的⼤表 Join 甚至需要花费 35-50min,⽽ Apache Doris 在未经优化的初次跑批中耗时 7min ,经过基础优化后缩减至 40s-90s,查询速度提升近 30 倍。
- 开发效率提高:原架构使用 Spark 进行 ETL 之后导入数仓,业务开发需要结合 Spark、Hive、Kafka 等多组件;切换至 Doris 后,只需专注 Doris SQL 的开发与优化,开发工作大大简化。此外,Doris 与 Kafka、DataX、Flink 等组件兼容性较高且包含丰富的插件库,进一步提高了开发效率。
- 负载隔离:利⽤ Workload Group 、Resource Group 等配置代替 Yarn,实现更加合理的资源隔离。
- 更低使用成本 :依赖 Doris 极致的压缩与计算性能,原架构的 27 台服务器精简至 10 台左右,总体资源开销降低至原来的 1/3(节省了 67%),为⽇后 PB 级别的数据量提供了更优的成本方案。
- 运维更加便捷 :通过 Doris Manager 轻松部署和接管 Doris 集群,实时查看集群的运行状态和详情,快捷地对集群进行扩缩容、升级及重启操作,数据管理更流畅、更高效。
详细可参考 Doris Manager 介绍文档与安装手册
架构升级实践与调优
01 数据接⼊
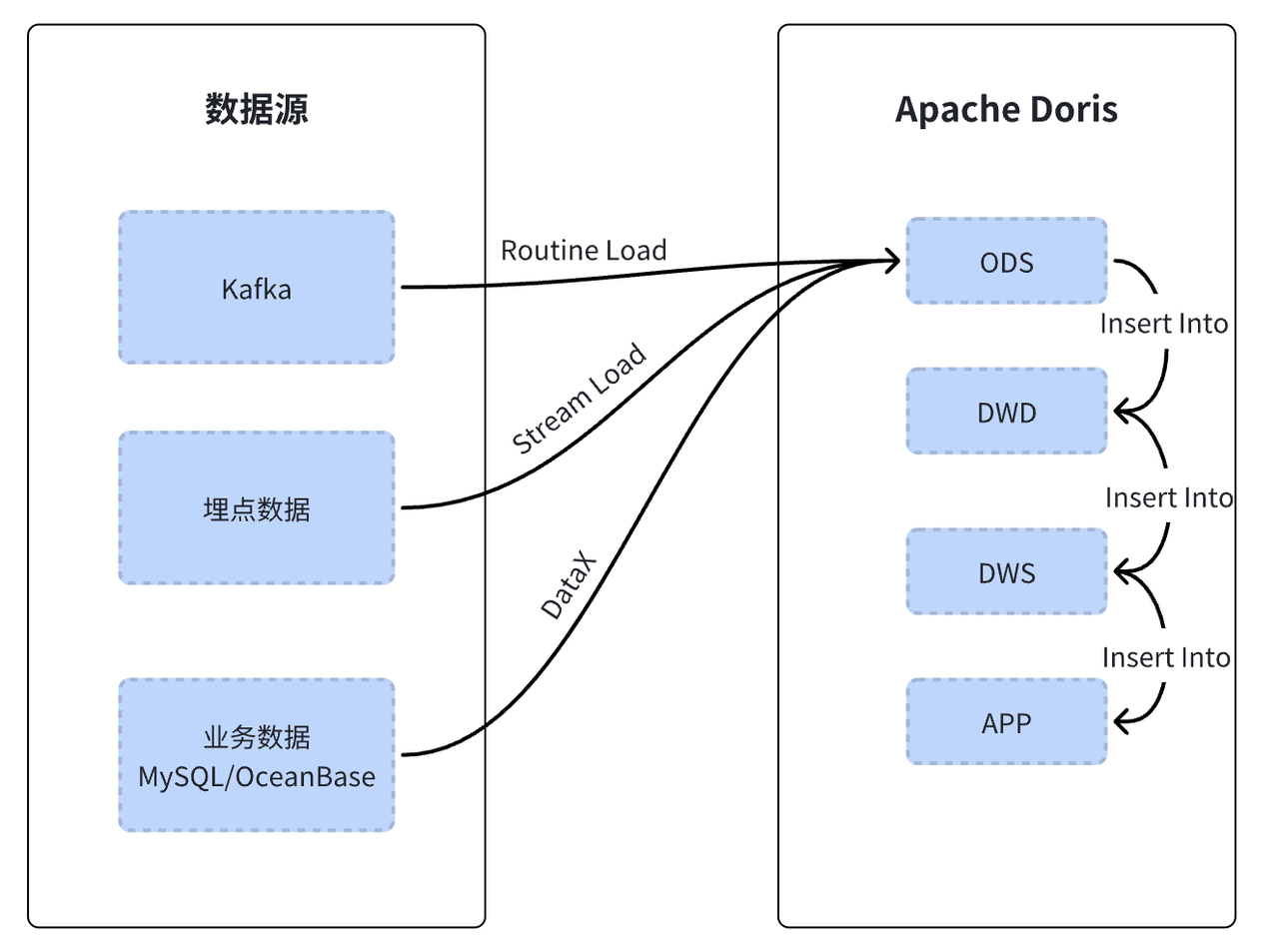
- 离线数据处理 :将 Sqoop+Flume 替换成 DataX,并新增了 Data X Doris Json 一键生成功能,利用主键模型的 Replace 特性,将全量同步优化为增量同步。改造后,数据采集时间从原来的 5h 缩短至 1.5h,处理效率提升 70%。
- 第三方埋点数据:之前需要通过大数据后端项目的接口 ETL 后传输到 Flume,改造后,ETL 逻辑依靠 Doris 实现,以 StreamLoad 的方式直接接入埋点数据。
- 后端日志数据迁移:由于后端日志打印频繁,MySQL 存储压力较大,影响业务分析效率。改造后通过 Routine Load 对接 Kafka 消费日志数据,并设置了 TTL,此外还根据业务开发侧的需求进行了简单的数据清洗,实现高性能的日志检索功能。
- 风控业务的实时命中策略与反欺诈实时指标处理:Flink 负责将 ETL 处理后的数据写入 Paimon,通过结合 Doris 的湖分析能力接入 Paimon,凭借 Doris 的统一查询入口为业务决策系统和数据分析提供数据服务。这一优化确保了业务问题能够迅速被发现并解决,有效避免了以往 T+1 数据模式下因数据滞后和业务感知延迟所带来的问题。
02 基于 Doris 的数仓建模
在构建新架构的同时,对数据表也进行了深度重构。基于 OneData 理论和 Apache Doris 的表模型设计,我们从底层建表逻辑出发,精心整理了以下内容,现与大家分享:
ODS 贴源层:使用主键模型备份 MySQL 的原始数据,可以接受 MySQL 历史数据的物理删除,从⽽减轻业务压⼒,降低云上存储成本。
DWD 明细层:主要使用主键模型,为了确保明细数据的准确性,也可以采用其他模型进行校验。在此层将屏蔽 ODS 层的数据,以提高数据表的复用性。
DWS 汇总层:采用聚合模型来汇集不同维度的表数据,形成若⼲张 Base 表,后续基于 Base 表进⾏维度上卷或 BI 分析,使 SQL 语句更加简洁、批处理性能得到提升。
APP 报表层:对接报表系统并定期通过邮件或办公软件发送至业务⽅,以供业务监控与业务决策。 由于该层涉及到基于不同时间字段维度以及维度上卷,因此选用明细模型。
![02 基于 Doris 的数仓建模.png]()
重构后的数据表结构更加简洁,显著提升了 SQL 语句的可读性,也使得数据同步性能,有效减轻了大规模数据全量同步所带来的沉重负担,从而避免业务阻塞。
03 结算系统数据回流
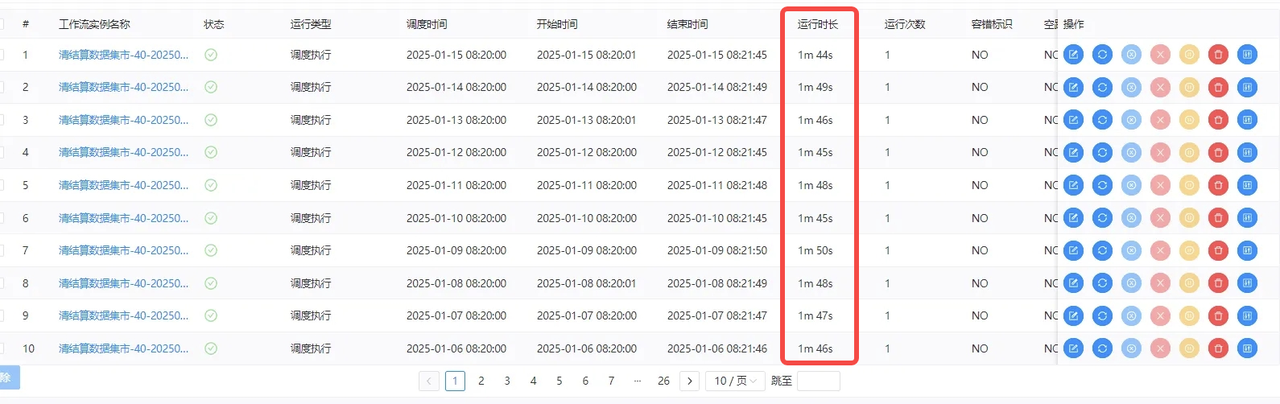
早期业务结算系统的核心数据难以复用,资源浪费的同时,数据批处理的效率也较为低下。引入 Doris 后,基于 Doris 的数仓建模复用了 DM 层的数据,有效支撑了结算代偿、回购对账、账户管理等核心业务需求的及时处理。此外还接入了风控决策引擎,为其提供了实时反欺诈数据指标,实现了高效实时计算和核心数据回流。
得益于 Doris 出色的即席查询和实时写入能力,数据回流的调度执行耗时平均不超过 2 秒,业务系统的灵活性和数据响应速度相比之前提高了 8-12 倍。
![03 结算系统数据回流.png]()
04 资源管理与权限控制
改造初期,由于资源管理配置不当,集群性能未达预期,可以通过调整 Workload Group 的并⾏查询数量、等待队列容量和超时时间,避免多条 SQL 语句抢占资源从⽽降低集群整体性能,此外,调整 Workload Group 的 max_concurrency、max_queue_size、queue_timeout 等参数,避免查询超时。
Workload Group 相关数据开发的逻辑概念如下:
![04 资源管理与权限控制.png]()
05 基础性能优化项
早期架构由于缺乏系统性的架构设计理论依据,导致了组件开发与维护工作十分复杂,既未设置合理的数据分区,也未对存储效率、查询索引等数据管理机制进行合理规划,所以在升级成为新架构时,浙江霖梓全面梳理并提炼业务关键指标,并针对 Doris 的各项基础性能进一步优化,有效提高了离线 / 实时一体化数仓的数据处理效率。
分区分桶
在建表时设置合理的分区分桶字段,其⼤⼩根据业务查询时间区间与数据体量决定,原理与 Hive 分区分桶基本---致,需要注意的是,业务变更频率较⾼的场景,不建议使⽤⾃动分区。我们综合考虑表数据量、增⻓趋势、表使⽤⽅法等情况,设置了动态分区,建表示例 SQL 如下:
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
前缀索引
Apache Doris 的前缀索引属于稀疏索引,表中按照相应的⾏数的数据构成---个逻辑数据块( Data Block),每个逻辑数据块在前缀索引表中存储---个索引项,其⻓度不超过 36 字节,查找前缀索引表时,可以帮助确定该⾏数据所在逻辑数据块的起始⾏号。由于前缀索引内存占⽤较⼩,可以全量在内存缓存,并快速定位数据块。设计原则⼀般遵循:<时间字段> + <分桶键> + <主键 id> ,对于 ODS 表, 要确保这些字段不存在 NULL 值 ,否则会导致输出数据不⼀致。
倒排索引
主要⽤于规则明细表与⽇志表中,⽤于快速统计规则路由情况以及关键词出现频次,减少资源占⽤率。Table 中的⾏对应⽂档、列对应⽂档中的某个字段,可以根据关键词快速定位其所在⾏,达到 WHERE ⼦句加速的⽬的。
BitMap 去重
BITMAP 类型的列可以在 Aggregate 表、Unique 表或 Duplicate 表中使⽤ ,针对---些特定的场景如 UV 、规则命中次数进⾏查询加速。SQL 示例如下:
#建表
create table metric_table (
dt int,
hour int,
device_id bitmap BITMAP_UNION
)
aggregate key (dt, hour)
distributed by hash(dt, hour) buckets 1
properties(
"replication_num" = "1"
);
#查询
select hour, BITMAP_UNION_COUNT(pv) over(order by hour) uv from(
select hour, BITMAP_UNION(device_id) as pv
from metric_table -- 查询每⼩时的累计UV
where dt=xxx
group by hour order by 1
) res;
开启执行优化器
在 Doris 2.1.x 版本中,建议启用 Pipeline X 和 local shuffle,以进一步提升复杂查询的执行效率。经过压测,开启 Pipeline X 优化器之后,性能提升了 20-30%。以下是 Pipeline X 优化器开启状态确认步骤:
#查看新优化器是否开启
#确保值全为true
show variables like '%enable_nereids_dml%';
show variables like '%experimental_enable_nereids_dml_with_pipeline%';
show variables like '%experimental_enable_nereids_planner%';
#默认 30,根据实际情况调整
show variables like '%nereids_timeout_second%';
此时对 Doris 、Hive 、Spark 进行压测,具体是对 15 个大表执行 join 操作,每张大表的平均数量约 13 亿条,测试过程中还涉及了 2 个表之间的笛卡尔积计算。根据执行结果,Doris 平均耗时只需 6 分钟。相比之下,Hive 执行相同任务耗时长达 2 小时,而 Spark 则执行失败。
报表优化
ADS 报表层在建表时开启 Merge-On-Write,以提升报表数据响应性能,同时开启⾏列混存以及查询缓存,避免刷新导致静态数据重复查询,影响集群性能。
#开启⾏存
"store_row_column" = "true"
总结与规划
截至目前,基于 Doris + Paimon 的实时/离线一体化湖仓架构已为反欺诈策略、用户⾏为分析、业务监控、 BI 应用等若干系统提供了服务,实现查询提速 30 倍、资源成本节省 67% 等显著成效。未来,浙江霖梓将持续扩大 Apache Doris 在内部系统的使用范围,并将对数据湖能力、智能实时应用进行探索及应用:
- 全面接入数据湖:逐渐扩大 Doris + Paimon 湖仓⼀体化架构的应用范围,打通存量数据湖与 Doris 数仓的对接,为日后 PB 级数据的分析做好充分准备。
- 打造实时智能金融客服:推动 Doris App 报表丰富度的提升,将 Doris 数据导出到 Elasticsearch 做知识库并接入⼤模型,通过 Prompt 与 GraphRAG 增强智能检索落地智能⾦融问答系统。
- 打造智能营销系统:将 Doris 作为知识库做实现精准营销,节约人力并且降低⼈为决策误差,深度挖掘数据潜在价值。
最后,衷⼼感谢 SelectDB 与 Apache Doris 社区伙伴的相携相伴,我们也会基于 Doris 进⾏离线 / 实时湖仓构建中持续挖掘,力求找到更优的问题解决方案,并回馈至社区。