作者:昭飞,铖朴
问题背景
近期,某企业客户的应用需要迁移到其他机房的机器上。在迁移前夕的测试过程中,客户发现当同一个应用的多个 Pod 副本,被调度到 Kubernetes 多个不同节点上时,部分节点(慢节点)上的应用实例耗时显著高于其他节点,同时观察发现,这些慢节点都是迁移后的节点,请求在迁移前的节点上耗时均是正常的。
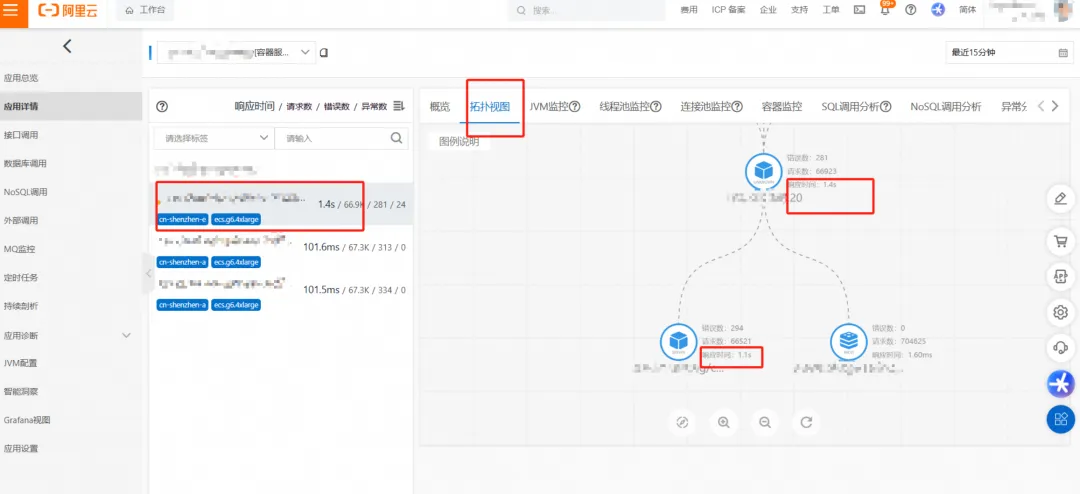
![]()
从上图中可以看到,红框中的第一个实例的平均耗时显著高于其他实例,而其所在的节点即为迁移后的节点上。此问题阻塞了客户的机房迁移进展,联系阿里云工程师需要帮助分析耗时出现差异的根因。
问题排查
梳理耗时点
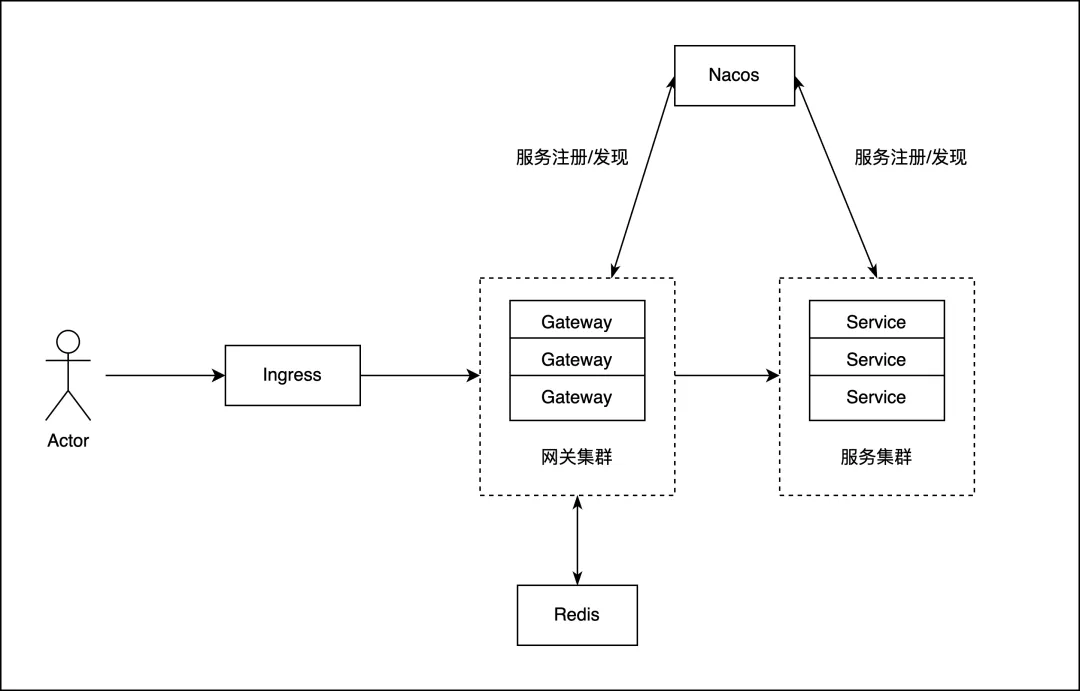
工程师在了解了需求后,首先梳理了客户系统应用的访问链路,跟进客户反馈,其问题最为严重的 Gateway 应用,部署形态大致如下:
![]()
基于上述信息,无法直接判断出具体的耗时点在哪?好在工程师发现,系统应用均接入到了阿里云 ARMS 中,想到可以通过查看调用链进一步判断耗时点。
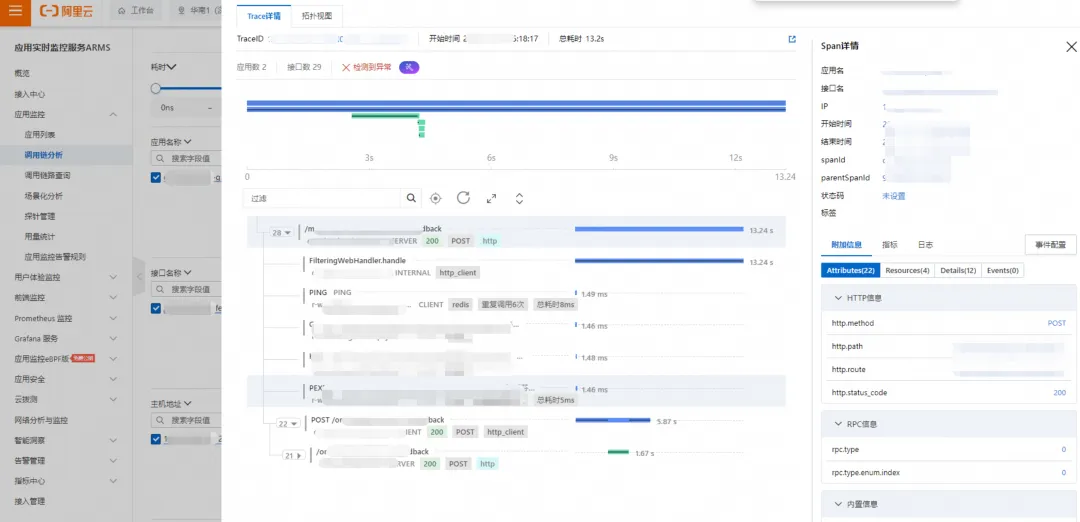
于是,在 ARMS 中查看一条慢调用记录的调用链,发现刨去 Gateway 的下游应用耗时,有 7s 多的时间消耗在了 Gateway 应用身上,这部分的耗时包含了 Gateway 应用自身的执行耗时及其调用下游的网络耗时,其中和 Gateway 应用自身相关的耗时都在 FilteringWebHandler.handle 这个自定义 filter 上:
![]()
客户通过 AOP 切面实现了 Gateway 接口的耗时统计,并记录在了日志中,过滤同一条 traceId 从日志中看,业务处理逻辑耗时都是在毫秒级别,没有达到秒级。因此,此时的调查方向转向了对网络偶发延时高的怀疑上。
抓包分析
抓包通常来说是对网络耗时分析的有效利器,下一步决定在慢节点的 Gateway pod 中进行抓包,尝试分析耗时高的原因。
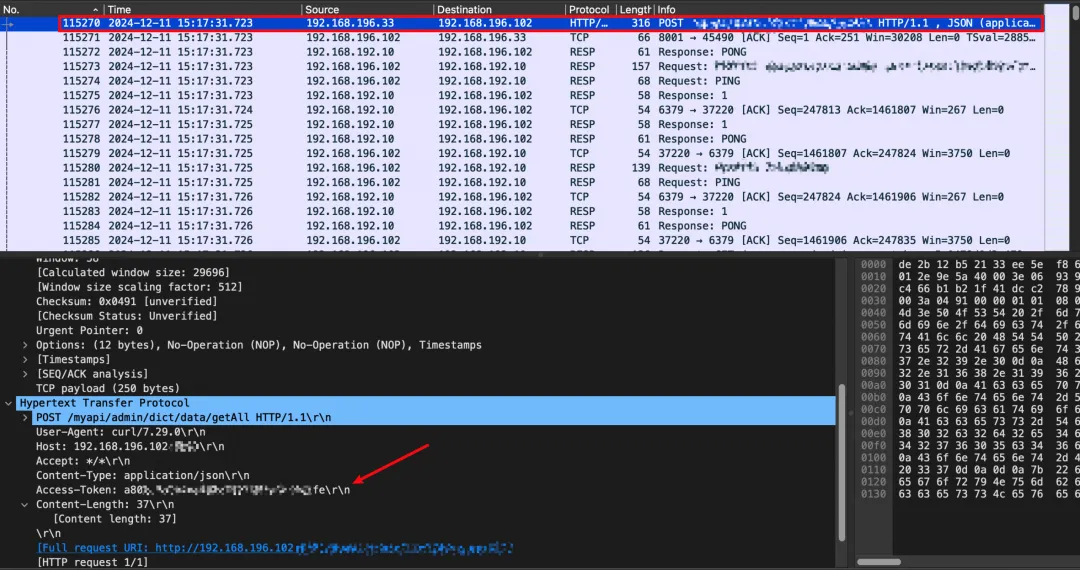
![]()
如上报文为在 Gateway pod 中抓取的 Ingress(192.168.196.33)访问 Gateway(192.168.196.102)的报文,在 15:17:31(后续简称31秒)Gateway 应用收到了Ingress的请求(序号115270报文),在 15:17:43(后续简称43秒)Gateway 应用响应回 Ingress(序号171373报文)。
![]()
如上报文为在 Gateway pod 中抓取的 Gateway(192.168.196.102)访问后端应用(192.168.196.70)的报文(根据 token 过滤,确保与上述请求在业务上为同一条请求),在 15:17:37(后续简称37秒)Gateway 向后端应用发起请求(序号140408报文),在 15:17:37(后续简称37秒)Gateway 收到了后端应用的响应(序号140528报文)。
根据上述两个图片中的报文,可以梳理出请求的链路以及关键的时间节点,请求的访问链路为 Ingress(192.168.196.33) -> Gateway(192.168.196.102) -> 后端应用 (192.168.196.70),Gateway 应用在 31 秒收到了请求,37 秒向后端应用发起请求,37 秒后端应用返回了响应,43 秒 Gateway 响应回 Ingress。
通过如上的分析,可以得出 Gateway 应用和后端应用的网络之间并不存在问题,因为在 Gateway 向后端发起请求后,后端的返回耗时很低。时间主要消耗在 Gateway 31 秒收到请求,37 秒才去请求后端应用,这 6 秒的时间里。
再拆解这 6 秒内的耗时,在 31 秒 Gateway 收到 Post 请求:
![]()
在 37 秒 Gateway 连接 Redis 发送 token(使用 Post 请求里面的 Access-Token 过滤,确保与 31 秒时 Gateway 收到的请求为同一条):
![]()
此时可以说明主要的耗时都用在向 Redis 发送请求,或者连接 Redis 上。
对比耗时正常的抓包分析,在耗时高的请求中,有很多向 Redis 发起连接的请求。据此推测并发请求量大的时候,连接 Redis 操作有堆积(可能是因为迁移后引起的跨机房访问导致耗时增加),此时需要进一步排查连接 Redis 耗时高的原因。
进一步过滤 Redis 的流,发现如下特征:
- 向后连接 Redis 是长连接。
- 在 31 秒-37 秒之间,复用的长连接自身没有闲着,因此推测在 Redis 长连接上存在"等待"的问题。
6 秒耗时分析拆解
排除了以上的网络问题,耗时高的怀疑点又回到了 Gateway 应用自身上,即便客户的业务日志中记录的 Gateway 接口耗时小于 1 秒(福尔摩斯曾说过:排除了一切不可能的,剩下的再不可思议,也是真相),并且耗时长问题与 Redis 之间的连接是有关联的。
为了进一步排查这 6 秒耗时的原因,在咨询了阿里云可观测相关工程师后,其介绍了目前可观测领域的 Trace 技术主要通过 SDK 或者 Java Agent 对一些知名框架的特定方案进行埋点,统计相关耗时,但如果出现比如用户业务逻辑等这类非埋点范围内的长耗时,可能通过 Trace 技术就无法观测,针对这类 Trace 技术无能为力的场景,其推荐我们使用 ARMS 的代码热点 [ 1] 功能,该功能通过关联调用链中的 Trace 信息 提供了调用链级别的 On & Off-CPU 火焰图,可有效对 Trace 的监控盲区细节进行还原,帮助用户诊断各类常见的慢调用链问题。
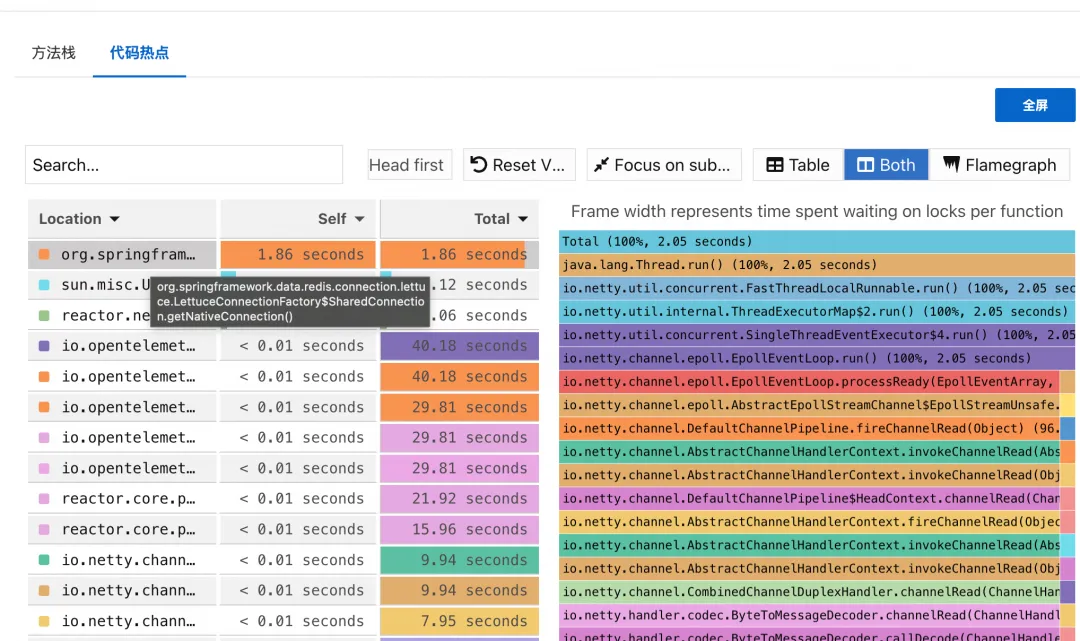
由于 Gateway 应用底层使用 Reactor 框架,请求都是异步调用,需要将 ARMS 探针升级到最新的 4.2.1 才能够支持异步调用链的代码热点功能。将测试 Gateway 应用升级到 4.2.1 后开启相关功能,再次压测复现问题,同时在主机上抓取和 Redis 之间的连接。
![]()
通过 ARMS 代码热点的火焰图数据结果,引发接口调用耗时长的瓶颈终于付出水面,在一个 2s 多的请求中 getNativeConnection() 独占了 1.86s,此方法是 Lettuce 框架用于获取应用与 Redis 之间的连接的方法。同时通过 netstate 命令查看压测期间慢节点的连接情况,看到大量的连接请求有堆积的情况(recvq,sendq),并注意到 6379 Redis 端口的交互只有一条连接,因此可以判断问题出来了应用 Redis 连接池设置出现了问题。
反馈相关问题给客户后,客户查看 Gateway 应用中 Redis 连接池的配置,发现设置了连接的 min-idle、max-idle 以及 max-active,但是没有配置 enabled 参数,查看 enabled 参数的默认配置,仅有在加载了 org.apache.commons.pool2.ObjectPool 这个类的情况下才会被置为 true。因此需要添加上 enabled=true 的配置,并引入 pool2 的依赖。
protected boolean isPoolEnabled(Pool pool) {
Boolean enabled = pool.getEnabled();
return (enabled != null) ? enabled : COMMONS_POOL2_AVAILABLE;
}
private static final boolean COMMONS_POOL2_AVAILABLE = ClassUtils.isPresent("org.apache.commons.pool2.ObjectPool",
RedisConnectionConfiguration.class.getClassLoader());
至此,该现象的原因就可解释了,客户相关连接池未有效配置,压测期间并发请求量大,所有请求均需要复用一条连接,导致获取 Redis 连接的请求排队,请求处理慢。
问题延续
增加了连接池的配置后,慢节点上的应用耗时有了部分下降(平均 1.3s 降至 680ms),但整体耗时仍然显著高于正常节点。此时可以说明增加了连接池的配置对于耗时高的问题确有缓解,但仍需继续解决耗时差异的问题。
接下来,我们开始怀疑连接池大小相关参数设置是否合理,通过检查连接池配置,初步查看未发现明显异常。
spring.redis.lettuce.pool.max-active=64
spring.redis.lettuce.pool.enabled=true
spring.redis.lettuce.pool.min-idle=16
spring.redis.lettuce.pool.max-idle=32
spring.redis.lettuce.pool.max-wait=100
再次压测,查看与 Redis 之间的连接,验证连接池配置是否生效。通过 netstate 可以查看到发起压测请求后,和 Redis 之间的连接数达到了 17 个,Lettuce 有一个额外连接用于初始化连接,此时可以发现 Lettuce 的连接数配置是生效的,并且连接池并没有达到瓶颈,可以排除连接数配置的问题。
再次查看耗时高接口的代码热点,发现耗时主要集中在 LettuceConnectionFactory.validateConnection() 方法上。同时通过在压测期间,获取问题现场的 jstack,可以发现有大量的 Reactor 线程阻塞在了同一个 monitor 上。
查看 LettuceConnectionFactory.validateConnection() 的源码,可以发现,在验证 Redis 连接有效性的时候会先加锁,直到验证完成后才会释放锁。
void validateConnection() {
synchronized (this.connectionMonitor) {
boolean valid = false;
if (connection != null && connection.isOpen()) {
try {
if (connection instanceof StatefulRedisConnection) {
((StatefulRedisConnection) connection).sync().ping();
}
if (connection instanceof StatefulRedisClusterConnection) {
((StatefulRedisClusterConnection) connection).sync().ping();
}
valid = true;
} catch (Exception e) {
log.debug("Validation failed", e);
}
}
if (!valid) {
log.info("Validation of shared connection failed. Creating a new connection.");
resetConnection();
this.connection = getNativeConnection();
}
}
}
在高并发连接的场景下,由于 Lettuce 的线程安全特性,会导致部分线程等待获取 validateConnection 的锁,从而导致性能的下降。这也进一步解释了为什么连接池大小一直都处于 min-idle,Gateway Reactor 的线程会因锁的争抢,导致 Redis 连接池无法得到充分利用。
查看客户的 Gateway 应用的代码,可以发现在业务代码中有调用 LettuceConnectionFactory.setValidateConnection(true),删掉此部分相关代码后,再次压测,rt 从 680ms 降至 380ms,与迁移前节点基本持平,至此问题解决。
问题排查小结
对上述排查过程进行小结,相关问题的原因及处理办法如下:
-
应用在使用 Lettuce Redis 连接池时,未引入 org.apache.commons.pool2 的依赖,也未显式设置 enabled 参数,仅设置了 max、min 等参数,实际线程池配置未开启生效。需要引入 org.apache.commons.pool2 的依赖开启线程池。
-
应用设置了在每次获取 Redis 连接前,需要先验证 Redis 连接的有效性(validateConnection),而 validateConnection 方法会先对当前连接持有锁后再检测,导致部分线程阻塞在获取当前连接的锁上,降低了和 Redis 间的并发度,无法充分利用 Redis 线程池的大小。在业务代码中删除 LettuceConnectionFactory.setValidateConnection(true)。
一些思考
- 同样都是没有设置 Redis 连接池,为什么迁移前没出现耗时高的问题,迁移后却出现了问题?
- 在"梳理耗时点"章节中可以看到,在慢节点上的 Redis 请求耗时为 1.x ms,在迁移前节点上的 Redis 请求耗时为 0.xms,请求 Redis 的耗时相差了 5-10 倍,此部分的耗时差异是由于迁移后应用访问 Redis 出现了跨机房调用,此部分的延迟增加是在合理范围内。在压测的并发量下,迁移前节点访问 Redis 的速度极快,Redis 的请求可以在单条连接中得到迅速的响应,未造成 Redis 请求的排队。而在迁移后,节点访问 Redis 的耗时出现了 5-10 倍的增加,应用访问 Redis 在单条连接中出现请求堆积,放大了延迟增加的影响。
- 为什么要设置 validateConnection,是否有其他的方法可以校验 Redis 连接的活性?
-
设置 validateConnection 为 true,主要解决的是应用与 Redis 之间的连接长时间处于空闲状态后,空闲连接被连接池回收,但应用无法感知的问题。在客户的应用场景中,与 Redis 时刻处于频繁交互的状态,因此可以将 validateConnection 设置为 false。
-
如果需要校验 Redis 连接的有效性,可以采取定时任务的方式来校验连接的活性,而非在每次 getNativeConnection 的时候校验。
@Scheduled(cron = "0/2 * * * * *") public void task() { if (RedisConnectionFactory instanceof LettuceConnectionFactory) { LettuceConnectionFactory f = (LettuceConnectionFactory) RedisConnectionFactory; f.validateConnection(); } }
相关链接:
[1] 代码热点
https://help.aliyun.com/zh/arms/application-monitoring/user-guide/use-code-hotspots-to-diagnose-code-level-problems