作者:有松
当前,函数计算 FC 已被广泛应用在各种 AI 场景下,函数计算支持通过使用容器镜像部署 AI 推理应用,并且提供多种选项来访问训练好的模型。为了帮助开发者高效地在函数计算上部署 AI 推理应用,并快速解决不同场景下的模型存储选型问题,本文将对函数计算的 GPU 模型存储的优缺点及适用场景进行对比分析, 以期为您的模型存储决策提供帮助。
背景信息
函数的存储选型请见:存储选型 [ 1] 。其中,适宜用作 GPU 模型存储的有以下 2 种。
- 文件存储 NAS [ 2]
- 对象存储 OSS [ 3]
除此之外,GPU 函数使用自定义容器镜像部署业务,因此还可以将模型文件直接放置到容器镜像中。
每种方法都有其独特的应用场景和技术特点,选择模型存储方式时应当考虑具体需求、执行环境以及团队的工作流程。通过灵活运用这些策略,达到模型存储在效率和成本上的平衡。
模型随容器镜像分发
将训练好的模型和相关应用代码一起打包在容器镜像中,模型文件随容器镜像分发,这是最直接的方法之一。
优缺点
优点:
- 便利性:创建好镜像后,可以直接运行它进行推理而无需额外配置。
- 一致性:确保每个环境中的模型版本都是一致的,减少了由于不同环境中模型版本差异导致的问题。
缺点:
- 镜像体积:镜像可能会非常大,特别是对于大尺寸模型。
- 更新耗时:每次模型更新时都需要重新构建和分发镜像,这可能是一个耗时的过程。
说明
为了提升函数实例的冷启动速度,平台会对容器镜像进行预处理。如果镜像尺寸过大,一方面可能会超出平台对镜像大小的约束,另一方面也会导致镜像加速预处理所需时间的延长。
- 关于平台镜像大小限制,请参见 GPU 镜像大小限制是多少? [ 4]
- 关于镜像预处理和函数状态的信息,请参见自定义镜像函数状态及调用 [ 5] 。
使用场景
- 模型尺寸相对较小,例如百兆字节左右。
- 模型变更频率较低,可以考虑将模型打包在容器镜像中。
如果您的模型文件较大、迭代频繁或随镜像发布时超过平台镜像大小限制,建议模型与镜像分离。
模型放在 NAS 文件存储
函数计算平台支持将 NAS 文件系统挂载到函数实例指定目录上,应用通过访问 NAS 挂载点目录实现模型文件加载。
优缺点
优点:
- 兼容性:相比 FUSE 类文件系统,NAS 提供的 POSIX 文件接口较完整和成熟,因此应用兼容性较好。
- 容量:NAS 提供 PiB 级存储容量。
缺点:
- 依赖 VPC 网络:一方面,需要为函数配置 VPC 访问通道才能访问 NAS 挂载点,在配置时涉及的云产品权限点相对较多;另一方面,函数实例冷启动时,平台为实例建立 VPC 访问通道会产生秒级的耗时。
- 内容管理方式较单一:NAS 文件系统需要挂载才能使用,相对单一,需要建立相应的业务流程将模型文件分发到 NAS 实例上。
- 不支持双活和多 AZ,详情请见 NAS 常见问题 [ 6] 。
说明
在大量容器同时启动加载模型的场景下,容易触及 NAS 的带宽瓶颈,导致实例启动耗时增加,甚至因超时而失败。例如,定时 HPA 批量启动预留 GPU 实例、突发流量触发大量按需 GPU 实例的创建。
- 可以从控制台查看 NAS 性能监控(读吞吐)。
- 可以通过向 NAS 增加数据量的方式来提升 NAS 读写吞吐量。
采用 NAS 来存储模型文件,建议选用通用型 NAS 中的"性能型",其主要原因在于该类型 NAS 可以提供较高的初始读带宽,约 600MB/s,详情请参见通用型 NAS。
使用场景
在按量 GPU 使用场景下,需要极速的启动性能。
模型放在 OSS 对象存储
函数计算平台支持将对象存储 OSS Bucket 挂载到函数实例的指定目录,应用程序可以直接从 OSS 挂载点加载模型。
优点
说明
从实现原理上,OSS 挂载使用 FUSE 用户态文件系统机制实现。应用访问 OSS 挂载点上的文件时,平台最终将其转换为 OSS API 调用实现对数据的访问。因此 OSS 挂载还有以下特征:
- 其工作在用户态,会占用函数实例的资源配额,如 CPU、内存、临时存储等,因此建议在较大规格的 GPU 实例下使用。
- 数据的访问使用 OSS API,其吞吐和时延最终受限于 OSS API 服务,因此更适合访问数量较少的大文件(如模型加载场景),不宜用于访问大量小文件。
- 当前的实现还无法使能系统的 PageCache,相比 NAS 文件系统,这意味着单个实例内应用如果需要多次访问同一个模型文件,无法用到 PageCache 加速效果。
使用场景
- 大量实例并行加载模型,需要更高存储吞吐能力避免实例间带宽不足的情况。
- 需要本地冗余,或者多地域部署的场景。
- 访问数量较少的大文件(比如模型加载场景)。
总结对比
![]()
基于以上对比,根据 FC GPU 的不同使用模式、不同容器并发启动数量、不同模型管理需求等维度,FC GPU 上模型存储的最佳实践如下:
- 在按量 GPU 使用场景下,由于需要极速的启动性能,推荐使用【通用 NAS-性能型】。
- 在闲置 GPU 使用场景下,由于容器启动耗时不敏感,推荐使用【oss】。
- 在大并发GPU容器同时启动使用场景下,为了避免 NAS 的单点带宽瓶颈,推荐【oss accl】。
- 在多地域单元化部署使用场景下,为了减少模型管理复杂度与跨域同步难度,推荐【oss、oss accl】。
测试数据
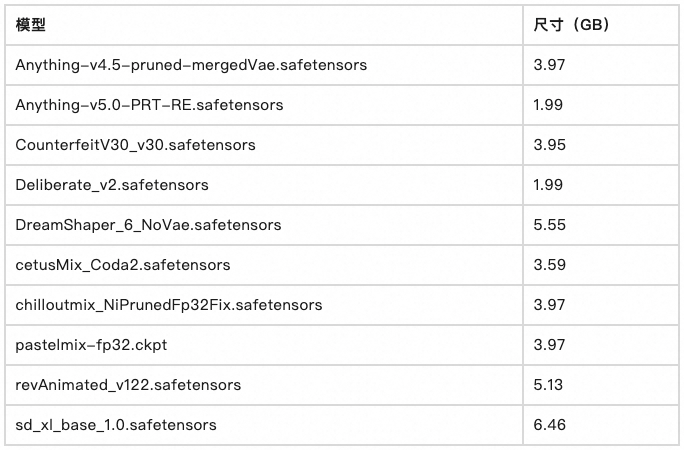
我们通过对 Stable Diffusion 模型切换耗时的测量,对比了不同模型存储方法的性能差异。本次测试的选取的模型和模型尺寸大小如下表。
![]()
![]()
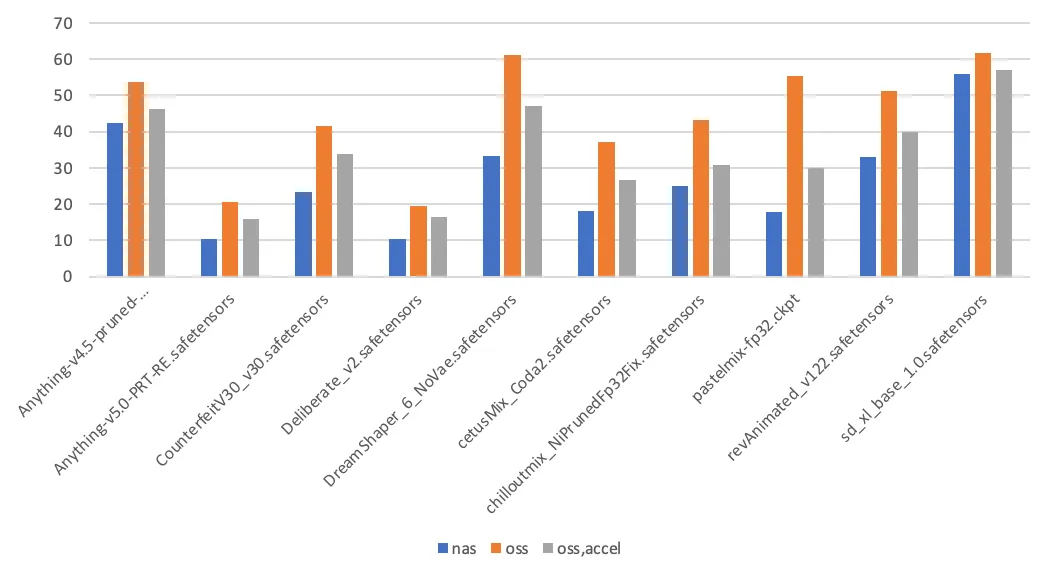
第 1 次模型切换耗时(单位:秒)
![]()
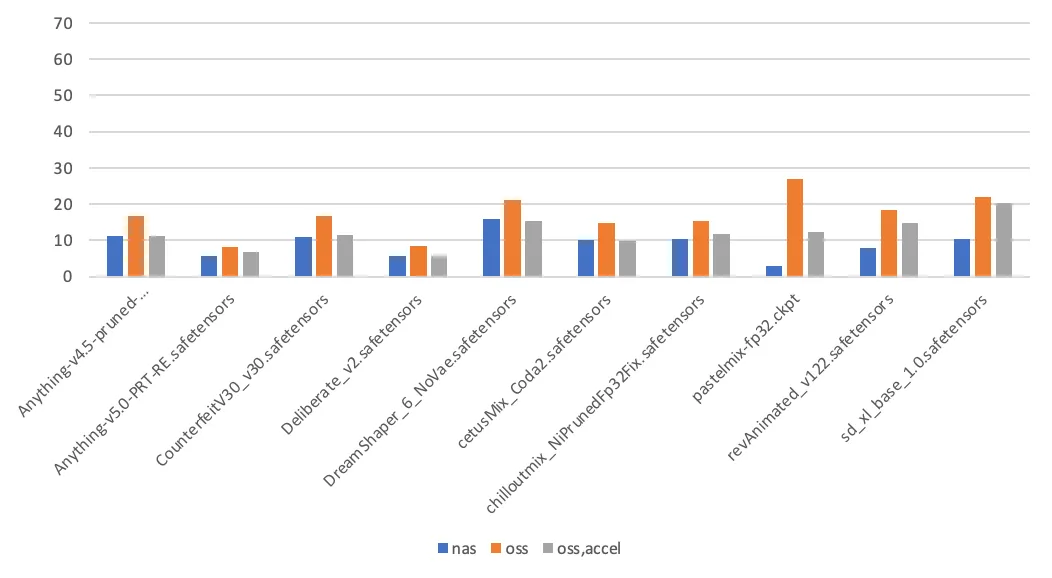
第 2 次模型切换耗时(单位:秒)
测试结论如下:
- PageCache 使能。在这个场景中,Stable Diffusion 第一次加载模型时,会读取模型文件两次,其中一次用于计算模型文件的哈希值。后续触发模型加载时,则只读取模型文件一次。第一次访问 NAS 挂载点上的文件时,会在内核填充相应的 PageCache,从而加速第二次访问。访问 OSS 挂载点不具备使能 PageCache 的特性。
- 影响耗时的其他因素。除了存储介质本身,模型加载耗时还与应用本身的实现细节相关,如应用本身的吞吐能力,读取模型文件时的 IO 模式(顺序读取、随机读取)。
相关链接:
[1] 存储选型
https://www.alibabacloud.com/help/zh/functioncompute/fc-3-0/product-overview/selection-of-function-storage
[2] 文件存储 NAS
https://www.alibabacloud.com/help/zh/functioncompute/fc-3-0/user-guide/configure-a-nas-file-system-1
[3] 对象存储 OSS
https://www.alibabacloud.com/help/zh/functioncompute/fc-3-0/user-guide/configure-an-oss-file-system-1
[4] GPU 镜像大小限制是多少?
https://www.alibabacloud.com/help/zh/functioncompute/fc-3-0/support/faq-about-gpu-accelerated-instances-1?spm=a2c63.p38356.help-menu-search-2508973.d_9#section-wzb-j8z-3cp
[5] 自定义镜像函数状态及调用
https://www.alibabacloud.com/help/zh/functioncompute/fc-3-0/user-guide/states-of-custom-container-functions
[6] NAS 常见问题
https://www.alibabacloud.com/help/zh/nas/product-overview/faq-2#section-uru-2sy-5hd
[7] OSS 使用限制及性能指标
https://help.aliyun.com/zh/oss/product-overview/limits
[8] OSS 加速器
https://help.aliyun.com/zh/oss/user-guide/overview-77/
[9] 常用工具
https://help.aliyun.com/zh/oss/developer-reference/common-tools/
[10] 跨区域复制
https://help.aliyun.com/zh/oss/user-guide/cross-region-replication-overview/
[11] 链接
https://www.alibabacloud.com/help/zh/nas/product-overview/billing-of-general-purpose-nas-file-systems
[12] 链接
https://www.aliyun.com/price/product?spm=a2c4g.11186623.0.0.46047158ja7nw5#/nas/detail/nas_bag
[13] 链接
https://help.aliyun.com/zh/oss/product-overview/billing-overview/
[14] 链接
https://www.aliyun.com/price/product?spm=a2c4g.11186623.0.0.46047158ja7nw5#/oss/detail/oss