欢迎阅读 OSCHINA 编辑部出品的开源日报,每天更新一期。
# 2024.12.27
今日要闻
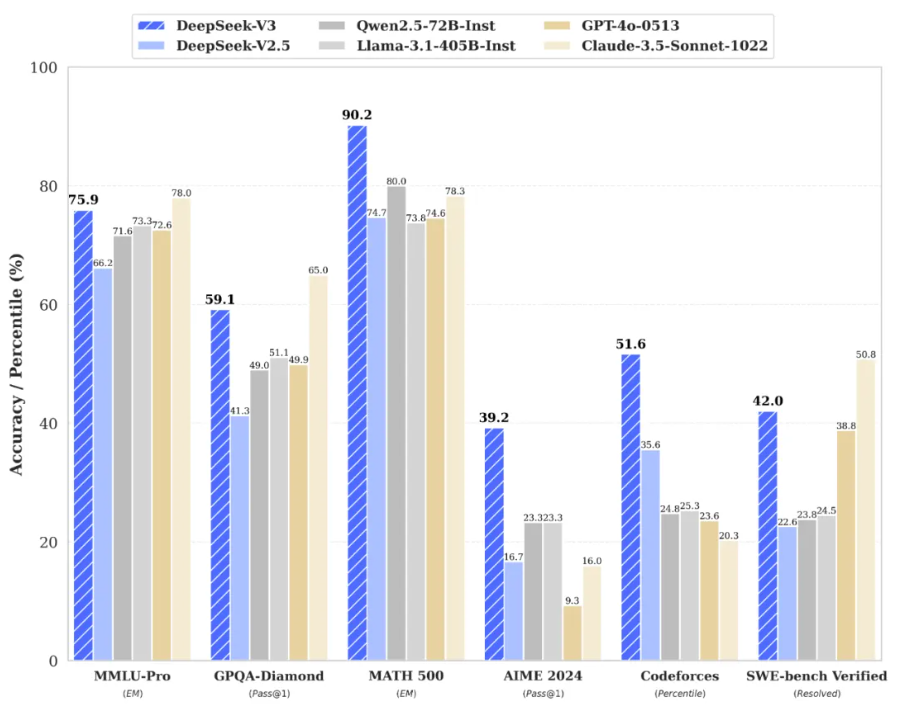
DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。
论文链接:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
![]()
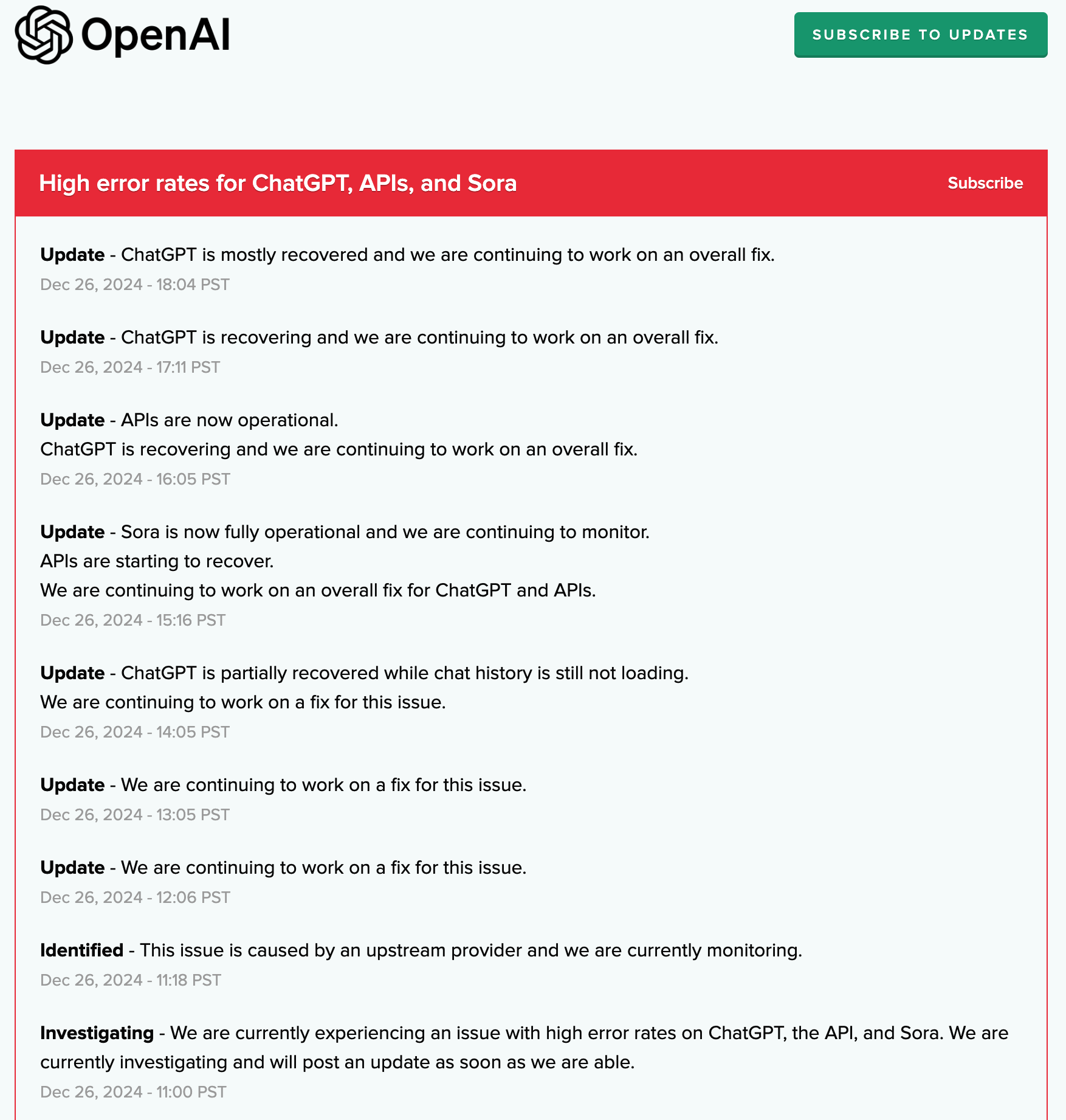
美东时间 12 月 26 日周四,OpenAI 确认,美东时间上午 11 点整,旗下服务开始发生大规模宕机。系统服务中断于北京时间 12 月 27 日凌晨 2 点 30 分左右开始,影响 ChatGPT 聊天机器人、Sora 视频生成模型以及部分 API 调用。
OpenAI 公布的状态页面显示,OpenAI 在 11 点整公布启动调查,称 ChatGPT、Sora 和和 API 都出现高错误率,11 点 18 分确认,问题出自 “上游供应商”,在监控情况。
![]()
此后,OpenAI 分别在 12 点 06 分和 13 点 05 分更新状态称,继续研究解决问题,14 点 05 分称,Chat GPT 已经部分恢复正常,聊天纪录仍未加载,OpenAI 在继续解决问题。
巧的是,在 OpenAI 发生宕机的同时,OpenAI 的独家云服务器供应商微软报告称,旗下一个数据中心出现 “电源问题”,主要影响到北美地区用户,正在调查这个问题。
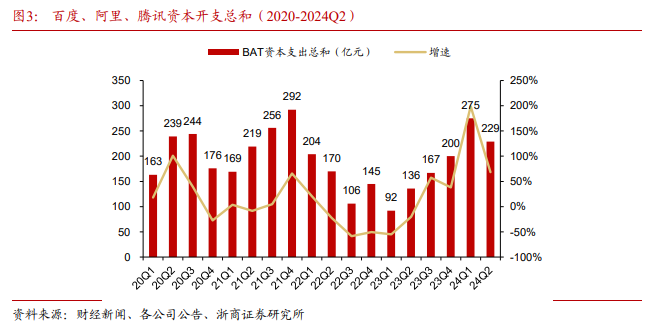
浙商证券在其报告中指出,字节跳动在 AI 上加大流量投放、扩大资本开支、大力扩张团队,研发投入显著领先同行。在资金上,字节跳动在 AI 上投入巨大,2024 年资本开支达到 800 亿元,接近百度、阿里、腾讯三家的总和(约 1000 亿元)。
![]()
2025 年,字节跳动资本开支有望达到 1600 亿元,其中约 900 亿元将用于 AI 算力的采购,700 亿元用于 IDC 基建以及网络设备。
据 The Information 报道,微软和 OpenAI 正就合作条款进行争执,其摩擦焦点主要涉及双方的云计算交易、收入分成和 IP 问题。据称,微软和 OpenAI 自大约 10 月份以来一直在洽谈 OpenAI 结构的潜在调整,会谈重点讨论了微软是否会继续获得 OpenAI 20% 的收入。
此前有消息称,微软正在接触更多大模型供应商,以降低旗下软件对于 OpenAI 的依赖。
Ruby 语言以在圣诞节这天发布重大更新闻名,今年的圣诞节当然也不例外,它释出了 Ruby 3.4。主要新特性包括:引入 it 用于引用一个没有变量名称的区块参数;默认解析器 Prism;socket 库支持 RFC 8305“Happy Eyeballs V2”;改进 YJIT just-in-time 代码性能,等等。
详情:https://www.ruby-lang.org/en/news/2024/12/25/ruby-3-4-0-released/
今日观察
社交观察
这几天刷推很明显的感觉到英文技术社区对中国AI产业的进步速度处于一种半震动半懵逼的状态,应激来源主要是两个,一个是宇树(Unitree)的轮足式机器狗B2-W,另一个是开源MoE模型DeepSeek-V3。
如果说宇树是在硬件上引起了一波怀疑现实的热度,那么DeepSeek则在软件的原生地盘,把大模型厂商都给硬控住了。
我最早对梁文锋有印象,是「西蒙斯传」里有他写的序,西蒙斯是文艺复兴科技公司的创始人,用算法模型去做自动化投资的开创者,梁文锋当时管着600亿人民币的量化私募,写序属于顺理成章的给行业祖师爷致敬。
交待这个背景,是想说,梁文锋的几家公司,从量化交易做到大模型开发,并不是一个金融转为科技的过程,而是数学技能在两个应用场景之间的切换,投资的目的是预测市场,大模型的原理也是预测Token。
一则小故事,数学家伯努利看到一篇匿名数学论文,马上认出是牛顿的手笔:从爪子判断这是一头雄狮。
阅读完DeepSeek V3技术报告有一种类似的感觉,在DeepSeek论文里看到了早期Google和OpenAI的影子:追求实效、狂野的想象力、扎实的工程交付能力(想象力都能验证和兑现)三方面的统一。从MLA,MoE 稳定训练技术到推理部署,乃至最后对硬件迭代方向的建议,让海外同行也respect ,属实厉害。
- 微博 老师木
Andrej Karpathy:DeepSeek(中国人工智能公司)今天表现得游刃有余,发布了一款前沿级LLM的开放权重模型,并且该模型的训练预算极其紧张(2048 个 GPU 运行 2 个月,耗资 600 万美元)。
作为参考,这种级别的能力通常需要近16,000个GPU的集群,而目前正在投入使用的GPU数量则接近10万个。例如,Llama 3 405B 使用了 3080 万 GPU 小时,而 DeepSeek-V3 看起来是一个更强的模型,仅使用了 280 万 GPU 小时(计算量减少了约 11 倍)。如果该模型还能通过氛围检查(例如LLM竞技场排名正在进行中,我的一些快速测试到目前为止进展顺利),这将在资源限制下展现出非常令人印象深刻的研究和工程成果。
这是否意味着你不需要大型 GPU 集群来应对前沿LLMs?不,但你必须确保不浪费现有资源,这看起来是一个很好的示范,表明在数据和算法方面仍有很多工作要做。
- 微博 i陆三金
![]()
- 微博 蚁工厂
贾扬清转了这个帖子认同DeepSeek的技术能力,说他在2019年就和DeepSeek做过技术交流,当时提了技术建议是 “你们不需要复杂的云虚拟化,只需要容器和一个高效的调度器。 你们需要真正快速、互联的专业网络,比如 RoCE 或 Infiniband。 你们需要一个通用的存储方案,比如 NFS,不需要太花哨,但必须足够快。 让 AI 开发者满意,而不是让 SRE(站点可靠性工程师)满意。” 而DeepSeek的人表示他们已经在这么做有一段时间了。
- 微博 蚁工厂
媒体观察
在2024年的全球科技版图上,中国机器人产业扬帆启航,加速“出海”。从餐饮配送到工业制造,从医疗辅助到智能家居,从消费服务到物流仓储,中国机器人的身影无处不在,正以优越的性能和创新的技术,为全球智能制造和产业升级贡献中国方案和中国智慧。
- 人民日报海外版
视频生成、语音交互等AI应用近年来持续火热,在2024年已让越来越多用户得到高效便捷的体验。更令业界瞩目的是,2024年各传统行业开始拥抱AI技术,将行业数据、计算模型赋予具备深度学习能力的AI,在工业生产领域开启规模化应用的路径。
- 经济参考报
脑机接口一度承载了人们对赛博格的绝大部分想象,但是这两年脑机接口的进步似乎并不是预想中的快,尤其是在 AI 日新月异的进步衬托下。
这其中当然有很多复杂的原因。脑机接口本身就是一个典型的交叉学科,涉及到了电极材料、芯片封装、医疗器械、算法,是一个非常复杂的全系统。更为关键的是,伦理问题使得脑机接口的每一次试验都必须十分慎重。彭雷提到,他们往往需要一年时间来准备一场试验。
- 极客公园
现在,作为 Google DeepMind 首席 AGI 科学家,Legg 将 AGI 定义为“至少可以在人们通常可以完成的认知任务中与人类能力相匹配的东西”。Hassabis 对于某个实体(不一定是谷歌)何时能实现 AGI 留了很大的余地,一边说,“10 年后有 50% 的机会”,又一边说,“如果它发生得更早,我也不会感到惊讶。”
- 学术头条
这一年,AI成为大国角力的新战场。中美两国,不约而同都大力推进人工智能的发展。在国内,“人工智能+”引领了全年的大模型落地潮,央国企成为先行力量。而大洋彼岸,“硅谷七姐妹”领涨美股,AI卖铲人英伟达从年初笑到年尾。
- 数智前线
从互联网萌芽到移动时代,从BAT鼎立到新兴力量崛起,中国科技产业的发展历程告诉我们:唯有与时俱进,方能立于不败之地。对于字节跳动而言,豆包的市场表现或许只是一个开始,如何在全球AI竞技场上为中国科技企业赢得更多话语权,才是其面临的真正考验。
- 投资者网
今日推荐
开源项目
![]()
https://github.com/thanos-io/thanos
Thanos 是一组可以组成具有长期存储期限的高可用指标系统的组件,可以将其无缝添加到现有 Prometheus 部署之上。
每日一博
在研发小型项目时,传统的 Vue、React 显得太 “笨重”。本文主要针对开发小型项目的场景,谈谈 Vite+Svelte 是如何让项目变得 “小巧灵动”,并横向对比 Svelte 和 Vue 的性能表现,对二者的加载流程做详细分析。
![]()
开源之声
用户观点
- 观点 1:其实最炸场的是它的训练成本,只有同级别的十分之一甚至更低,简直是工程奇迹
- 观点 2:国内的大模型一发表就是啥都最牛逼,真正一用啥也不是
- 观点 3:deepseek和qwen确实是厉害的,宣传上很谦虚了。其他的差不多就像你说的那样
- 观点 4:想知道大家在 jb 家软件或者 vscode 上,用什么 AI 插件自定义 api 接口的?
- 观点 6:中国在基础研究领悟滞后,但在应用开发方面确实算遥遥领先
- 观点 7:600b 对比300b?牛逼
- 观点 8:毫不夸张地说,Deepseek 是国产开源之光。
- 观点 9:我前天试用了一下chat,感觉除了推理以外很一般,今天再看看
- 观点 10:但是deepseek提供的api速度太慢了,模型提升了api速度提升了吗
- 观点 1:名是统信的,活是深度的。
- 观点 3:肯定是wine,而且人家根本没打算隐藏,不得不说,这里工作量可真是爆炸!
- 观点 4:能把wine玩好,也是挺厉害了
- 观点 5:干脆win内核参考edge,用linux😂
---END---
![]()