引言
随着大数据技术的发展,数据集成和数据流处理需求日益增长。Apache SeaTunnel 作为一款开源的数据集成框架,不仅支持多种数据源和目标,还提供了灵活的 API 来满足各种复杂的业务需求。
本文将深入解析 Apache SeaTunnel 的 API,帮助开发者更好地理解其使用场景和实现方式。
从接口定义来看SeaTunnel
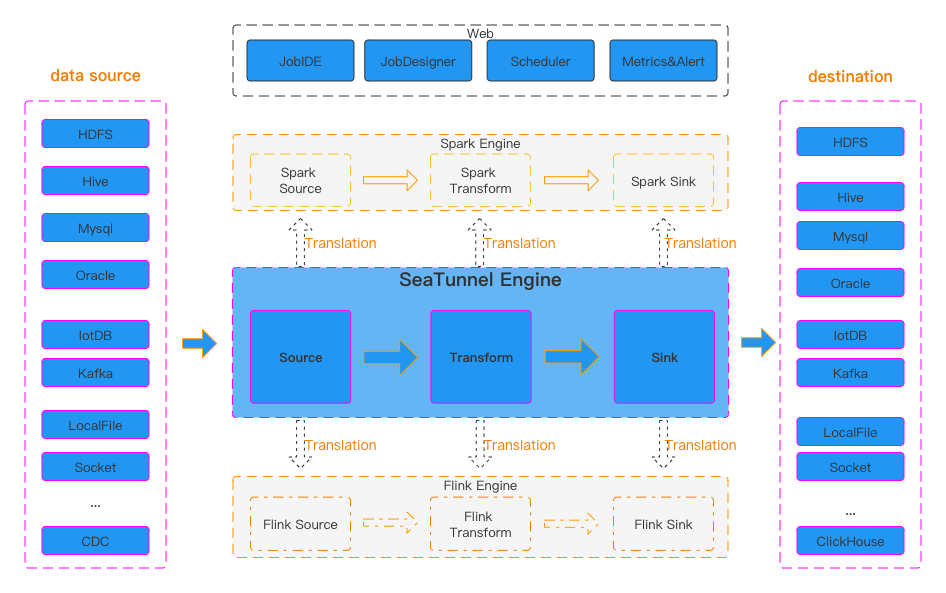
从官网的这个图中, 可以看到在SeaTunnel中, 定义了以下几种类型:
- 数据源 API(Source API):用于定义数据的输入源。
- 数据转换 API(Transform API):用于处理和转换数据。
- 数据目标 API(Sink API):用于定义数据的输出目标。
三种类型/算子
![]()
所以我想先从接口的定义上来看下Apache SeaTunnel的设计理念.
SeaTunnelSource
SeaTunnelSource是数据读取的接口定义, 在这个接口中, 定义了如何从某个数据源中抽取数据.
public interface SeaTunnelSource<T, SplitT extends SourceSplit, StateT extends Serializable>
extends Serializable,
PluginIdentifierInterface,
SeaTunnelPluginLifeCycle,
SeaTunnelJobAware {
/**
* 返回当前Source的类型,是[有界批数据]还是[无界流数据]
*/
Boundedness getBoundedness();
/**
* 此方法后面将弃用
* 后面将使用Catalog来表示数据,可以添加更多的元数据来描述数据
*/
default SeaTunnelDataType<T> getProducedType() {
return (SeaTunnelDataType) getProducedCatalogTables().get(0).getSeaTunnelRowType();
}
/**
* 当前SeaTunnel是支持多表读取的, 所以这里会返回一个list类型的结构
* 每个catalog则是对读取的表的元数据信息
*/
default List<CatalogTable> getProducedCatalogTables() {
throw new UnsupportedOperationException(
"getProducedCatalogTables method has not been implemented.");
}
/**
* 创建 Reader,Reader是真正去读取数据的类
*/
SourceReader<T, SplitT> createReader(SourceReader.Context readerContext) throws Exception;
/**
* 这两个方法是创建/恢复 SplitEnumerator
*/
SourceSplitEnumerator<SplitT, StateT> createEnumerator(
SourceSplitEnumerator.Context<SplitT> enumeratorContext) throws Exception;
SourceSplitEnumerator<SplitT, StateT> restoreEnumerator(
SourceSplitEnumerator.Context<SplitT> enumeratorContext, StateT checkpointState)
throws Exception;
/**
* 这两个方法一般不会修改, 如果需要对Enumerator自定义序列化方式可以重写
*/
default Serializer<SplitT> getSplitSerializer() {
return new DefaultSerializer<>();
}
default Serializer<StateT> getEnumeratorStateSerializer() {
return new DefaultSerializer<>();
}
}
从这个接口中可以看到有两个主要的方法
createReadercreateEnumerator createEnumerator方法创建的SourceSplitEnumerator作用是对要抽取的数据进行任务拆分. createReader方法创建的SourceReader则会依据这些拆分的任务进行实际的任务读取
首先来看下SourceSplitEnumerator的代码
SourceSplitEnumerator
public interface SourceSplitEnumerator<SplitT extends SourceSplit, StateT> extends AutoCloseable, CheckpointListener {
void open();
void run() throws Exception;
@Override
void close() throws IOException;
void addSplitsBack(List<SplitT> splits, int subtaskId);
int currentUnassignedSplitSize();
void handleSplitRequest(int subtaskId);
void registerReader(int subtaskId);
StateT snapshotState(long checkpointId) throws Exception;
default void handleSourceEvent(int subtaskId, SourceEvent sourceEvent) {}
interface Context<SplitT extends SourceSplit> {
int currentParallelism();
Set<Integer> registeredReaders();
void assignSplit(int subtaskId, List<SplitT> splits);
default void assignSplit(int subtaskId, SplitT split) {
assignSplit(subtaskId, Collections.singletonList(split));
}
void signalNoMoreSplits(int subtask);
void sendEventToSourceReader(int subtaskId, SourceEvent event);
MetricsContext getMetricsContext();
EventListener getEventListener();
}
}
SourceSplitEnumerator接口中定义了一些方法以及一个内部类Context 先看下自身的一些方法. 可以看到有3个跟生命周期相关的方法,open(), run()和close()。这几个方法就需要连接器自己去根据相关的实现来做一下资源的创建或关闭动作.
registerReader(int subtaskId)方法 reader主动向split enumerator进行注册handleSplitRequest(int subtaskId) reader主动向split enumerator进行请求,获取自己将要执行的抽取任务.
(但看了代码实现,这种方式比较少,大部分还是enumerator主动向reader推送任务)addSplitsBack(List<SplitT> splits, int subtaskId) 则是当某个reader出现异常后,需要将它运行的任务重新分配,此时需要将它运行的任务重新添加回队列中,后面进行重新分配到其他节点进行容错。
而在Context接口定义中有两个关键方法
assignSplit(int subtaskId, List<SplitT> splits) split enumerator主动向某个reader推送任务signalNoMoreSplits(int subtaskId) split enumerator告诉某个reader,它后面将不会再有其他任务被分配。
SourceReader
public interface SourceReader<T, SplitT extends SourceSplit>
extends AutoCloseable, CheckpointListener {
void open() throws Exception;
@Override
void close() throws IOException;
void pollNext(Collector<T> output) throws Exception;
List<SplitT> snapshotState(long checkpointId) throws Exception;
void addSplits(List<SplitT> splits);
void handleNoMoreSplits();
default void handleSourceEvent(SourceEvent sourceEvent) {}
interface Context {
int getIndexOfSubtask();
Boundedness getBoundedness();
void signalNoMoreElement();
void sendSplitRequest();
void sendSourceEventToEnumerator(SourceEvent sourceEvent);
MetricsContext getMetricsContext();
EventListener getEventListener();
}
}
在Reader接口定义中, 也有一个内部类Context
首先来看下我们来看下几个主要方法:
pollNext(Collector<T> output) 抽取数据的主要方法,在这个方法中每个连接器都会实现从自己相应的数据源中抽取数据,转换成seatunnel的内部数据结构SeaTunnelRow,然后再添加到Collector中addSplits(List<SplitT> splits) reader接收split enumerator分配给自己的任务后的相关处理snapshotState(long checkpointId) 这个方法是做checkpoint时会被调用, 需要reader记录一些状态, 从而可以进行后续的容错
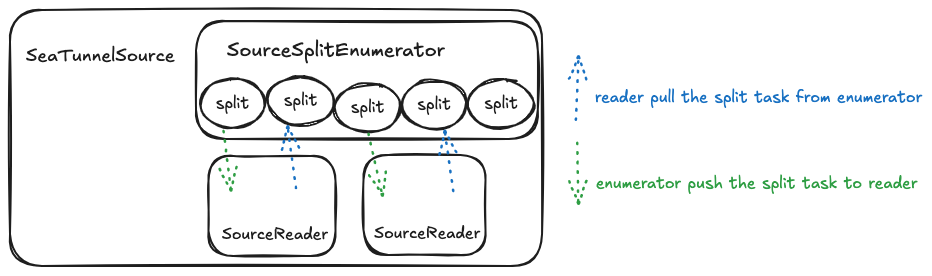
用一张图来总结一下
![]()
在这里的一个Split表示对数据源数据读取拆分的一个任务,可以是一个Hive表的一个分区,可以是一个Kafka的分区,也可以是JDBC查询语句的拆分,总之核心思想是将一个数据的读取拆分成多个互相不影响的读取任务,从而可以交给不同的reader实例去执行,从而加快查询速度。
举个例子:在批处理下可以将数据拆分为N份,使得数据抽取可以并行执行,达到提升速度的目的。
而对于流式处理, 有两种方式, 一个是将数据拆分为有限的无界数据流(例如Kafka根据分区进行拆分, 一个分区一个任务,每个任务都是无界的数据流)。
另外一种方式是生成无限的有界数据流(同样以Kafka为例, 每次抽取某个分区中的一部分数据, 无限次生成任务定义)。
至于一个数据读取任务最终会被切分成多少个Split以及如何实现切分,则是每个连接器的自己实现,每个连接器可以根据实际读取的分区或者参数来决定。
接下来看下Transform的相关代码!
SeaTunnelTransform
public interface SeaTunnelTransform<T>
extends Serializable, PluginIdentifierInterface, SeaTunnelJobAware {
default void open() {}
default void setTypeInfo(SeaTunnelDataType<T> inputDataType) {
throw new UnsupportedOperationException("setTypeInfo method is not supported");
}
// 获取Transform处理之后的数据结构
CatalogTable getProducedCatalogTable();
// 从这里可以看出,SeaTunnel里面的Transform是仅支持map操作的
// 对于Join这种多个数据源的操作是不支持的
T map(T row);
default void close() {}
}
在transform中就一个关键的方法T map(T row),就是对原有的一条数据进行map处理,得到一条新数据。新数据的结构则是与getProducedCatalogTable()一致。
这个代码是基于2.3.6版本, 目前社区也正在做Transform的多表读取,写入功能 目前仅支持map这种一对一的算子, 我看社区也在讨论是否支持flatMap这种一对多的算子, 从而可以在同步过程中进行一些数据展开的操作.
再来看下Sink的代码!
SeaTunnelSink
public interface SeaTunnelSink<IN, StateT, CommitInfoT, AggregatedCommitInfoT>
extends Serializable,
PluginIdentifierInterface,
SeaTunnelPluginLifeCycle,
SeaTunnelJobAware {
@Deprecated
// 这两个方法也都被标记为废弃, 后续都将使用Catalog来进行表示
default void setTypeInfo(SeaTunnelRowType seaTunnelRowType) {
throw new UnsupportedOperationException("setTypeInfo method is not supported");
}
@Deprecated
default SeaTunnelDataType<IN> getConsumedType() {
throw new UnsupportedOperationException("getConsumedType method is not supported");
}
/**
* 创建/恢复 SinkWriter,Writer是真正执行数据写入的类
*/
SinkWriter<IN, CommitInfoT, StateT> createWriter(SinkWriter.Context context) throws IOException;
default SinkWriter<IN, CommitInfoT, StateT> restoreWriter(
SinkWriter.Context context, List<StateT> states) throws IOException {
return createWriter(context);
}
default Optional<Serializer<StateT>> getWriterStateSerializer() {
return Optional.empty();
}
default Optional<SinkCommitter<CommitInfoT>> createCommitter() throws IOException {
return Optional.empty();
}
default Optional<Serializer<CommitInfoT>> getCommitInfoSerializer() {
return Optional.empty();
}
default Optional<SinkAggregatedCommitter<CommitInfoT, AggregatedCommitInfoT>>
createAggregatedCommitter() throws IOException {
return Optional.empty();
}
default Optional<Serializer<AggregatedCommitInfoT>> getAggregatedCommitInfoSerializer() {
return Optional.empty();
}
}
在Sink中,有几个关键的方法:
-
createWriter(SinkWriter.Context context) 创建Writer实例,与Source类似,数据的实际写入是由Writer来写入。
-
createCommitter() 可选,在需要二阶段提交时,创建一个SinkCommitter,由SinkCommitter来完成二阶段提交, 此方式也不再推荐, 推荐使用createAggregatedCommitter()来进行二阶段提交。
-
createAggregatedCommitter() 可选,与SinkCommitter类似,都是在提交阶段进行二阶段提交使用。
不同的点在于SinkAggregatedCommitter是单一实例去执行,不会存在多实例,将所有的提交任务集中到一个地方执行。所以如果连接器需要二阶段提交, 推荐使用createAggregatedCommitter()来创建
SinkWriter
public interface SinkWriter<T, CommitInfoT, StateT> {
void write(T element) throws IOException;
default void applySchemaChange(SchemaChangeEvent event) throws IOException {}
Optional<CommitInfoT> prepareCommit() throws IOException;
default List<StateT> snapshotState(long checkpointId) throws IOException {
return Collections.emptyList();
}
void abortPrepare();
void close() throws IOException;
interface Context extends Serializable {
int getIndexOfSubtask();
default int getNumberOfParallelSubtasks() {
return 1;
}
MetricsContext getMetricsContext();
EventListener getEventListener();
}
}
可以看到SinkWriter的结构与SourceReader结构有些类似, 来看下一些关键方法:
-
write(T element) 当接收到一条上游数据时, 写入到目标数据库的实现;
-
applySchemaChange(SchemaChangeEvent event) 当上游数据的表结构变动后, 下游如何进行相应的实现, 例如增删字段, 修改字段名称. 但这个跟具体的实现有关;
-
prepareCommit() 当需要二阶段提交时, 生成此次需要提交的信息, 该信息将交给SinkCommitter/SinkAggregatedCommitter来进行二阶段提交. 这个方法的调用, 是在做checkpoint时会被调用, 也就是每次checkpoint时才会提交刚刚产生的信息到目标端连接器;
-
snapshotState() 当做checkpoint时, 存储writer的一些状态, 从而可以进行后续的容错;
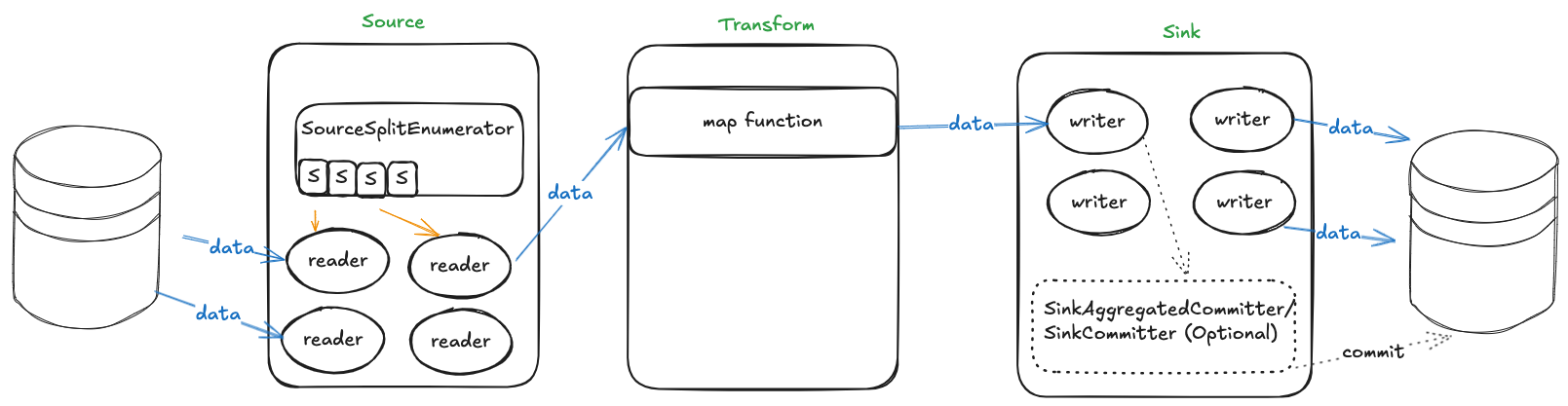
用图小结
![image.png]()
当需要对某个数据源进行读取时,会先由SourceSplitEnumerator来进行任务的切分,再由SourceReader来执行拆分的数据读取任务,读取是需要将原始数据转换为SeaTunnel内部的SeaTunnelRow,然后传递给下游,交由Transform进行数据转换,转换完成后交由SinkWriter实现将SeaTunnelRow的数据写入到相应的连接器中,在写入过程中如果需要二阶段提交,则需要额外实现SinkCommitter的相关类。
Collector
在上面的几个章节, 已经将source, transform, sink的功能描述了一下.
但source,transform, sink之间的数据传递是如何实现的呢, 如果一个source有多个下游, 消息是如何全部分发给多个下游的呢? 这个地方就是由Collector接口来定义的.
从数据流转的方向上, 仅会有source到下游或者transform到下游传递数据, 所以可以看到有两个Collector的接口定义, 分别在source和transform包下。
先来看下source中Collector的定义:
public interface Collector<T> {
void collect(T record);
default void markSchemaChangeBeforeCheckpoint() {}
default void collect(SchemaChangeEvent event) {}
default void markSchemaChangeAfterCheckpoint() {}
Object getCheckpointLock();
default boolean isEmptyThisPollNext() {
return false;
}
default void resetEmptyThisPollNext() {}
}
而transform中的Collector定义就相对简单了
public interface Collector<T> {
void collect(T record);
void close();
}
Collector将多个算子进行解耦, 每个算子仅需关心如何处理数据, 而无需关心结果数据需要发送给谁.
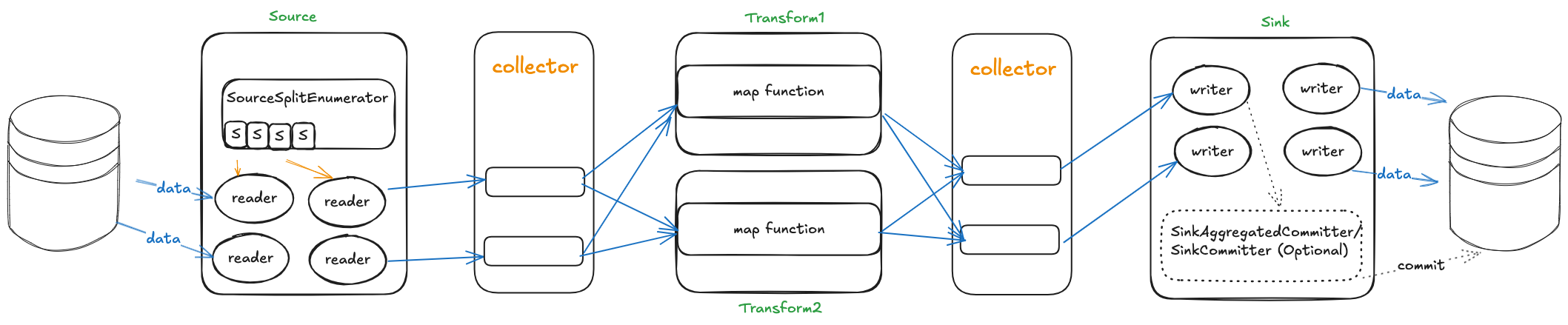
对上面的图再更新一下大致是这样(多加了一个Transform来显示多下游的场景)
![image.png]()
在分布式系统中, 每个任务都使用单独的线程来运行, 那么多个线程之间的数据传递就存在两种情况, 一个是同进程之间的传递, 另外就是跨进程之间的传递也就是Shuffle.
而SeaTunnel的定位是一个数据传输工具, 数据产生之后, 并不需要对数据进行计算, 数据的传输可以仅在进程之间传递. 不需要做shuffle. 从而提升性能以及减少由shuffle带来的其他问题.
所以在SeaTunnel中, Collector的实现就是实现一个进程内跨线程的数据管道.
同样, 由于这样的设计, 之前在issue区看到有人想实现多个source并行读取, 单个sink写入的功能也就无法实现了. 如果需要想实现单点写入的功能, 那么就需要连接器实现SinkAggregatedCommitter来进行单点的二阶段提交(至于具体是否是单节点写入, 也需要看连接器的具体实现).
Factory
在新的设计中,所有连接器都是通过Factory工厂类来进行创建的。
TableSourceFactoryTableTransformFactoryTableSinkFactory 他们均实现了Factory接口,而他们本身也是接口,需要各个连接器去具体实现。
里面有这么几个方法
public interface Factory {
String factoryIdentifier();
OptionRule optionRule();
}
public interface TableSourceFactory extends Factory {
default <T, SplitT extends SourceSplit, StateT extends Serializable>
TableSource<T, SplitT, StateT> createSource(TableSourceFactoryContext context) {
throw new UnsupportedOperationException(
"The Factory has not been implemented and the deprecated Plugin will be used.");
}
Class<? extends SeaTunnelSource> getSourceClass();
}
public interface TableTransformFactory extends Factory {
default <T> TableTransform<T> createTransform(TableTransformFactoryContext context) {
throw new UnsupportedOperationException(
"The Factory has not been implemented and the deprecated Plugin will be used.");
}
}
public interface TableSinkFactory<IN, StateT, CommitInfoT, AggregatedCommitInfoT> extends Factory {
default TableSink<IN, StateT, CommitInfoT, AggregatedCommitInfoT> createSink(
TableSinkFactoryContext context) {
throw new UnsupportedOperationException(
"The Factory has not been implemented and the deprecated Plugin will be used.");
}
@Deprecated
default List<String> excludeTablePlaceholderReplaceKeys() {
return Collections.emptyList();
}
}
在这几个接口定义中, 有两个公共方法
factoryIdentifier() 进行连接器标识, 每个连接器应该唯一optionRule() 声明该连接器所需要的参数,哪些是必填, 哪些是选填, 哪些一起填会存在冲突等等, 在创建连接器时会先对配置参数来进行校验.
当参数验证通过后, 会调用相应的方法来创建相应的连接器SeaTunnelSource/SeaTunnelTransform/SeaTunnelSink
总结
Apache SeaTunnel 的 API 提供了强大的数据集成能力,能够灵活应对不同的业务场景。通过这几个关键API的定义, 我们可以看到, Apache SeaTunnel是将数据同步进行了高度抽象, 并且可以灵活的对各个连接器进行组装, 各个连接器之间是没有依赖的.
希望开发者能够更加深入地理解 SeaTunnel API,并在实际项目中高效地利用这些 API 进行数据处理和集成。
本文由 白鲸开源科技 提供发布支持!