此文是根据 KubeSphere 在 KubeCon China 2024 上的演讲分享整理而成。
议题简介
作为最受欢迎和强大的 Prometheus 长期存储项目之一,Thanos 被社区广泛采用。但要在生产环境中使用 Thanos,仍然需要自动化许多繁杂的运维工作。
在这次演讲中,KubeSphere 的维护者将分享他们在生产环境中使用和维护 Thanos 的经验,包括:
- 所有 Thanos 组件以 CRD 的方式定义
- Ingester、Ruler、Compactor 等组件的租户隔离机制
- 基于租户的 Ingester、Ruler 和 Compactor 等组件的自动扩展机制
- Store 基于时间分区进行扩展的机制
- 用于处理海量 Recordng/Alerting Rules 计算的全局 Ruler 分片机制
- 有租户访问控制的网关和代理机制
- 经网关代理的有 Basic Auth 认证的原生 Thanos WebUI 访问
- Thanos 组件之间的 TLS 支持
- 二层配置管理
讲师简介
-
霍秉杰:KubeSphere 可观测性团队负责人,多个可观测性开源项目包括 Whizard、Fluent Operator、Kube-Events、Notification Manager 等的发起人,热爱云原生技术,并贡献过 KEDA、Prometheus Operator、Thanos、Loki 和 Falco 等知名开源项目。
-
张军豪:青云科技高级软件工程师,负责容器平台监控、告警、FinOps 等云原生服务的研发。拥有多年行业经验,曾就职于瑞幸咖啡、海康威视等公司。对 Kubernetes、Prometheus、Thanos、容器网络等云原生技术有深入的了解,在云化容器产品的研发、实施和运维方面拥有丰富的经验。
PDF 下载:在公众号【KubeSphere云原生】后台回复关键词 20240823,即可下载。
以下是正文。
Thanos
Prometheus 目前已经是一个云原生监控领域的事实标准,但它同样有一些企业级需求没有解决,它是一个单实例单副本的,没有高可用,也不可扩展。自从 Prometheus 开源后,出现了很多社区项目来解决这个问题。
Thanos 就是其中一个项目,功能强大且在社区比较受欢迎。
Thanos 有一些独特的功能,比如它能够把 Prometheus 的数据上传到对象存储,这样就可以极低成本存储更长时间范围的监控数据,同时也支持从对象存储查询监控数据。Thanos 兼容 Prometheus,支持快速查询长时间范围内的数据。
Thanos 的部署模式
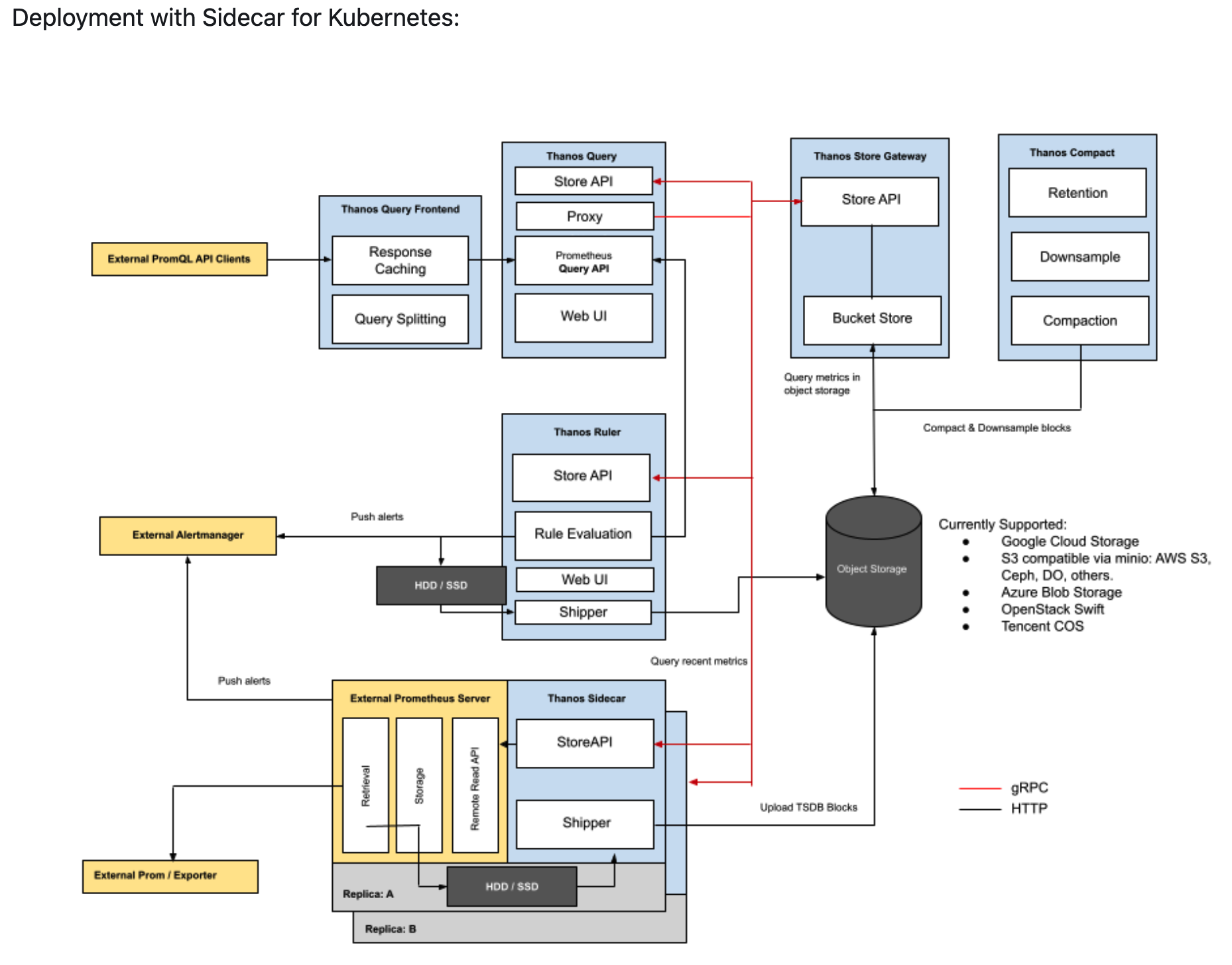
- 基于 Sidecar 的分布式模式
![]()
在各集群的 Prometheus Pod 中创建一个 Thanos Sidecar,Thanos Sidercar 会把 Prometheus 的数据发送到对象存储,达到持久化存储的目的。Thanos 的其他组件,比如 Query 或 Store Gateway,能够在对象存储中查询数据。
在这种模式中,Thanos 接收数据的部分是可扩展的,对用户来说,他们只需要考虑 Query 或 Store Gateway 这些组件的可扩展性。
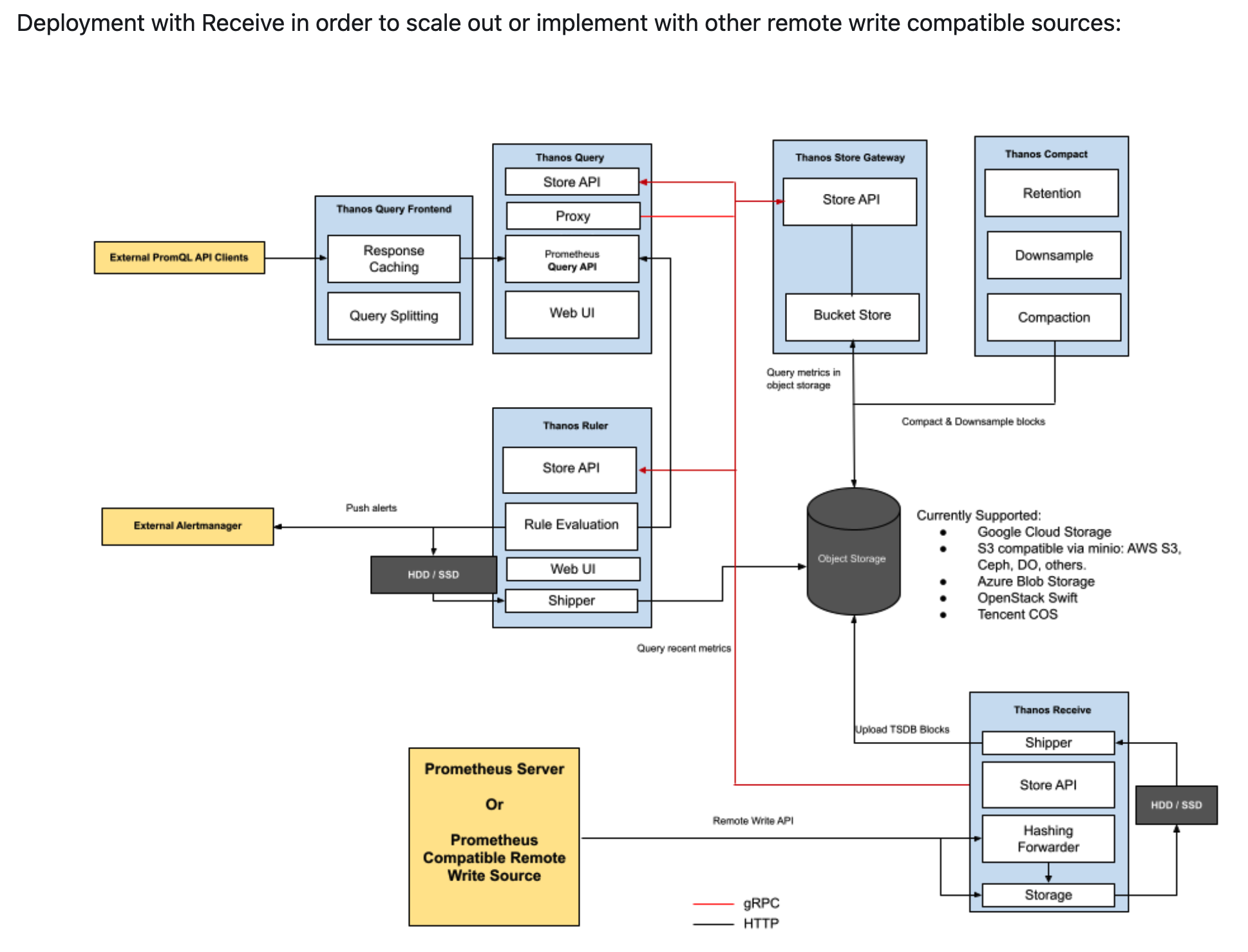
- 中心化存储
![]()
以 agent 模式运行 Prometheus,把 Prometheus Agent 抓取到的数据通过 remote write 写到 Thanos 的 Ingester,再由 Ingester 将接收到的数据上传到对象存储中。
这种模式用户需要关心更多的 Thanos 组件的扩展性包括 Router, Ingestor, Ruler, Store Gateway, Compactor 等,以接收、查询海量数据。
如何定制和部署 Thanos
Thanos 社区提供了两种方式。
- kube-thanos
kube-thanos 是一个 Thanos 社区维护的项目,允许用户通过 jsonnet 的方式对 Thanos 的部署做定制,然后用 yaml 的方式部署各种组件。
缺点:
- jsonnet 对开发者友好,对用户不够友好,而且目前应用不够广泛
- kube-thanos 的 sample deployment 不是一个生产可用的部署
- 仅有一个查询实例、路由实例、摄取实例和存储实例,每个实例各有一个副本。
- 没有 compactor 和 query 前端的组件
- hashring 仅包括默认的软租户
- ...
- Thanos Helm Chart
这是 Bitnami 提供的 Thanos Helm Chart,用于在 Kubernetes 环境中简化 Thanos 的部署和管理。
缺点:
- values 过于冗长,要求用户对 Thanos 的各种组件要非常了解,使用有门槛
- Thanos 有状态组件通过 CPU/内存(HPA)进行扩展,此方式可能会导致数据丢失
- 没有与租户相关的设置
- hashring 需要用户手动配置,比较繁琐
使 Thanos 达到生产就绪状态,还需要什么?
- 更轻松地创建和维护 Thanos 组件和配置,例如 CRDs
- 租户配置可以更简单,无需手动配置 hashring
- Thanos 纳管多个 Kubernetes 集群
- 为每个租户计算 Recording Rules,并将计算后的指标加上该租户的标签后再写入 Thanos Ingester
如果你有十个甚至上百个集群怎么办?
- 使用单个 Ingester 接收来自所有集群的数据是不可行的:
- Ingester 的能力不比单个 Prometheus 实例强
- Ingester 必须可扩展,以处理数十个甚至上百个集群的规模
- Compactor、Store、Ruler 也必须可扩展,以处理数十个甚至上百个集群的规模
- 每当有集群添加或移除时,自动配置 Thanos,减轻运维负担
为了更好地应对以上问题和挑战,KubeSphere 可观测性团队于 2021 年开始开发 Thanos 的企业发行版 Whizard,并于 2024 香港 KubeCon 正式宣布开源。
Whizard
首先是 Whizard 的整体架构,节点和应用的 Metrics 数据由 Agent(Prometheus) 通过 remote-write 方式写入 Gateway,经由 Gateway 准入接收后,由 Router 根据 hashring 路由到指定 Ingester,Ingester 缓存并处理数据,然后定期将数据写入对象存储中,至此数据写入完成。查询时,Query 在 Ingester 中查询近期数据,在 Store 中查询更长时间对象存储中存储的数据,QueryFrontend 进行查询缓存。
![Whizard 架构图]()
- 所有 Thanos 组件都在 CRD 中定义
- 引入了新的 Whizard CRDs:服务/网关/存储/租户
- 引入租户及基于租户的自动扩缩容
- 为 Ruler 引入基于 RuleGroup 的分片机制
- 为 Store 引入基于时间的分片
- Gateway 和 Whizard Proxy 用于租户读写控制
- 查询优化
- 安全增强:
- 基本认证访问 Thanos WebUI
- 所有 Thanos 组件的 TLS 配置
- 服务与组件的两层配置管理
所有组件的 CRD 定义:
-
Thanos 的 CRDs:
- Router
- Ingester
- Ruler
- Query/QueryFrontend
- Store
- Compactor
-
Whizard 的 CRDs:
- Service
- Tenant
- Gateway
- Storage
Service
Service 包含了各个组件的默认/全局配置信息:
- TenantHeader/DefaultTenantId/TenantLabelName
- Gateway
- Router
- Ingester
- Query/QueryFrontend
- Ruler
- Compactor
- Store
- Storage
- RemoteWrites/RemoteQuery
如果 Thanos 的组件如 Ingester、Compactor、Ruler 等是基于租户的扩展机制自动创建出来的,这些组件会加载 Service 中指定的该组件的默认配置后启动服务。
Tenant
- 为 Thanos 定义一个租户(解决 hashring 的配置问题)
- Tenant.status 表示与该租户相关的资源,包括:
Gateway
该组件是 Whizard 流量入口,可以对租户请求进行准入控制。
- 处理所有读写请求
- 支持 TLS 配置
- 支持基本认证配置
- 支持经过 Basic Auth 认证后访问原生 Thanos WebUI
- 支持经过 OAuth2-Proxy 代理认证后访问原生 Thanos WebUI
Storage
定义 Thanos 的对象存储设置。
Router
定义 Thanos Receive Router 的设置,该组件的功能是根据 Hashring 配置将对应租户的数据路由到指定的 Ingester 中。
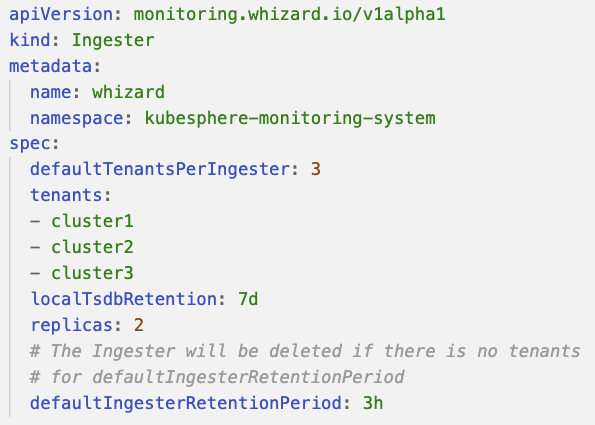
Ingester
定义 Thanos Receive Ingester 的设置,该组件的功能是处理和接收租户的数据,并存储到对象存储中。
![]()
如图所示,DefaultTenantsPerIngester 配置项表示当前 Ingester 包含的租户数量上限,tenants 标明了当前有哪些租户位于这个 Ingester 上。图中的租户数量配置的上限是 3 个,就说明最多能容纳 3 个租户,如果需要新增租户,就会新建一个 Ingester 来进行负载。
当租户删除时,需要考虑 Ingester 的资源回收,我们配置了 DefaultIngesterRetentionPeriod。图中的配置为 3 个小时,因为通常 Thanos 每两个小时进行一次数据落盘并推送到对象存储,配置为 3 小时,就能保证当前租户的数据能够被完整的落盘以及上传,达到资源的安全回收。
Ruler
定义 Thanos Ruler 的设置,该组件的功能是计算规则。
Ruler 有两种模式,一种是用于特定租户的 Ruler,用于计算该租户的 Recording Rules,将结果重新写回到该租户的数据中;另一种则是全局 Ruler,用于计算全部租户的 Alerting Rules,并将结果推送给 AlertManager。
全局 Ruler 承担了所有租户的 Alerting Rules,压力较大时,可以使用 Shards 字段进行分片,每个分片是一个 Ruler 的 Statefulset,通过分片来提升 Ruler 的并发性能。
Compactor
定义 Thanos Compactor 的设置,该组件的功能为压缩与降采样。
与 Ingester 类似,Compactor 也包含 DefaultTenantsPerCompactor 参数,基于租户数量进行自动伸缩。
Store
定义 Store 的设置:
TimeRanges 定义 store 的时间分片策略。每个时间分片分别对应一个 StatefulSet 工作负载,他们分别加载不同的时间间隔的对象存储数据,我们可以根据查询习惯,历史数据命中较低,可以按照如图所示进行配置,近期的范围间隔小,更久的范围间隔更大点。
![]()
Query
- 定义 Query 的设置:
- PromqlEngine:选择使用的 PromQL 引擎,默认为最快的 Thanos 引擎
- Stores:定义外部查询源
- 对于数据 < 36 小时,查询在 Ingester 上的本地数据
- 对于数据 ≥ 36 小时,通过 Store 查询对象存储上的数据
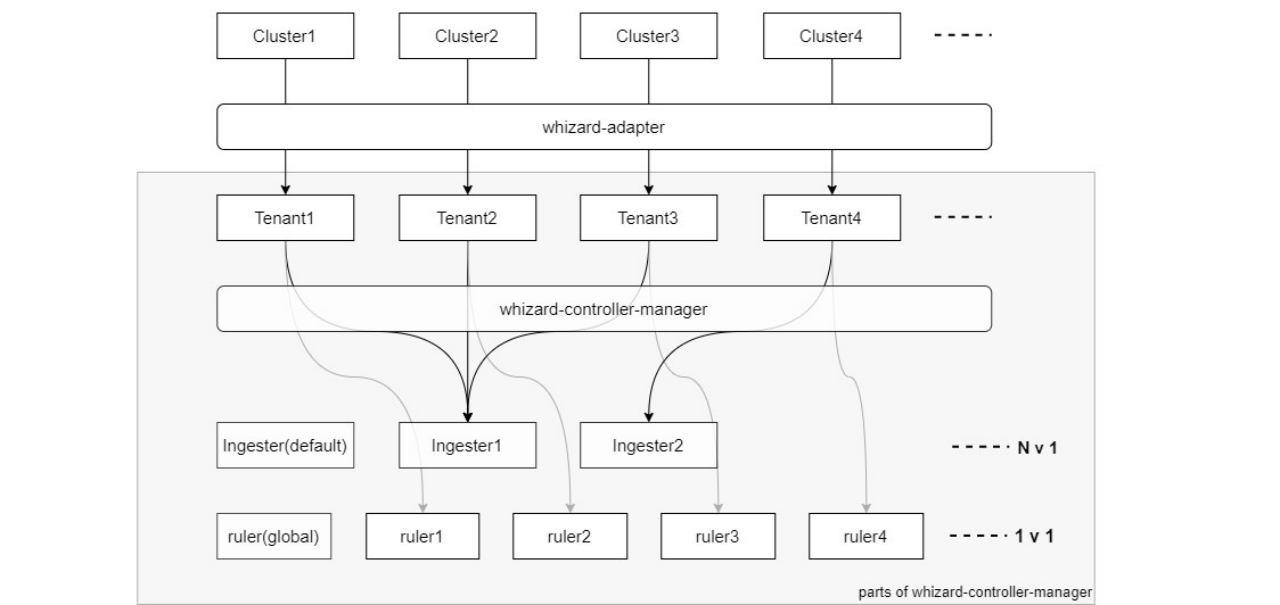
基于租户的组件自动扩缩容
- 每个 KubeSphere Cluster 都会由 whizard-adapter 映射为 Whizard Tenant
- 每个 Ingester 默认可以接收并处理 3 个 Tenant 的数据
- 每个 Compactor 默认可以压缩 10 个 Tenant 的块
- 每个 Tenant 有一个专用的 Ruler 来评估该租户的记录规则
![]()
使用 RuleGroup 替代 PrometheuesRule
下图是一个 RuleGroup 的展示,我们可通过这个很方便的去进行可视化以及编辑管理。
![]()
期望 Thanos 继续增强的功能
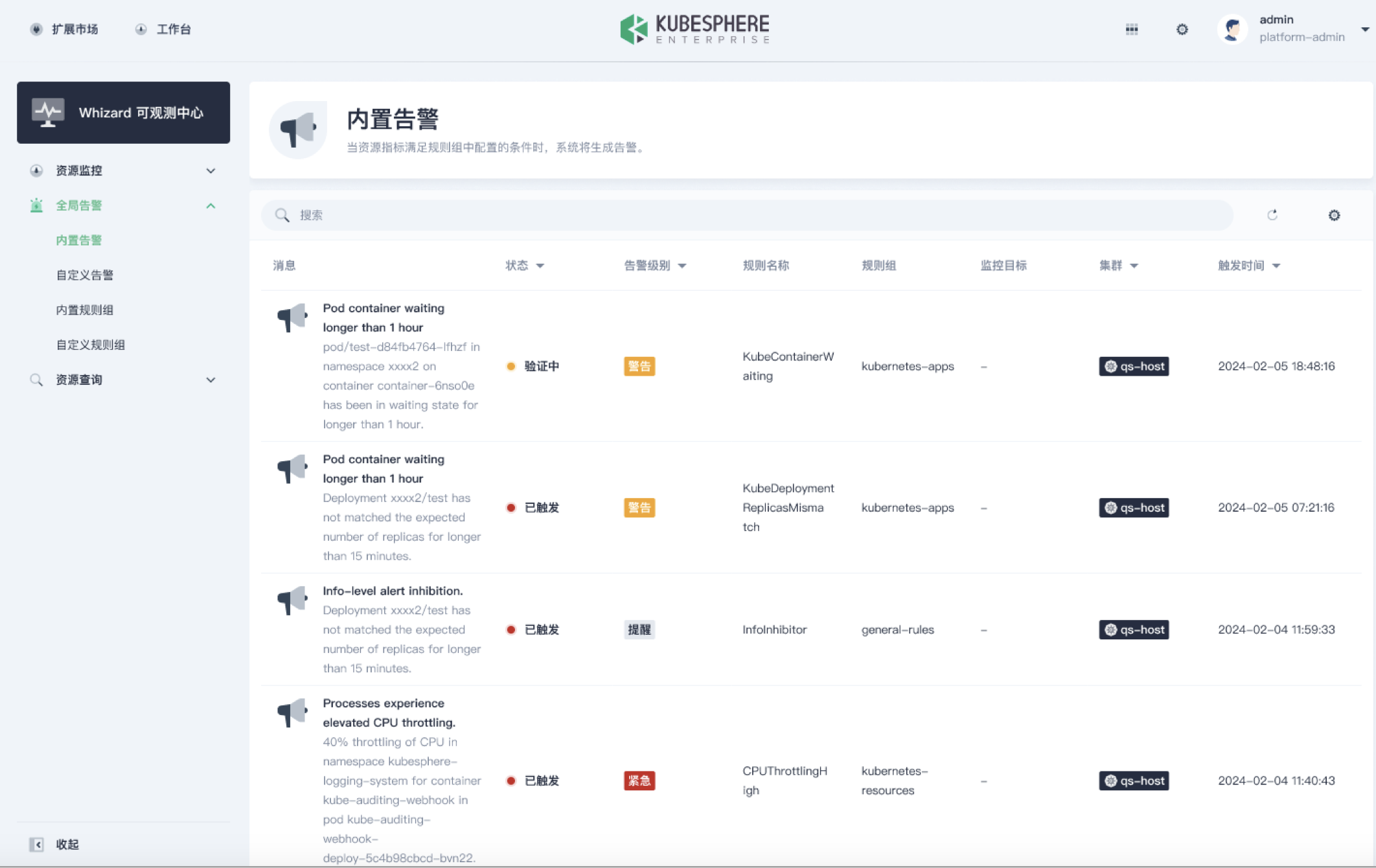
Whizard 在 KubeSphere 中的生产应用
![]()
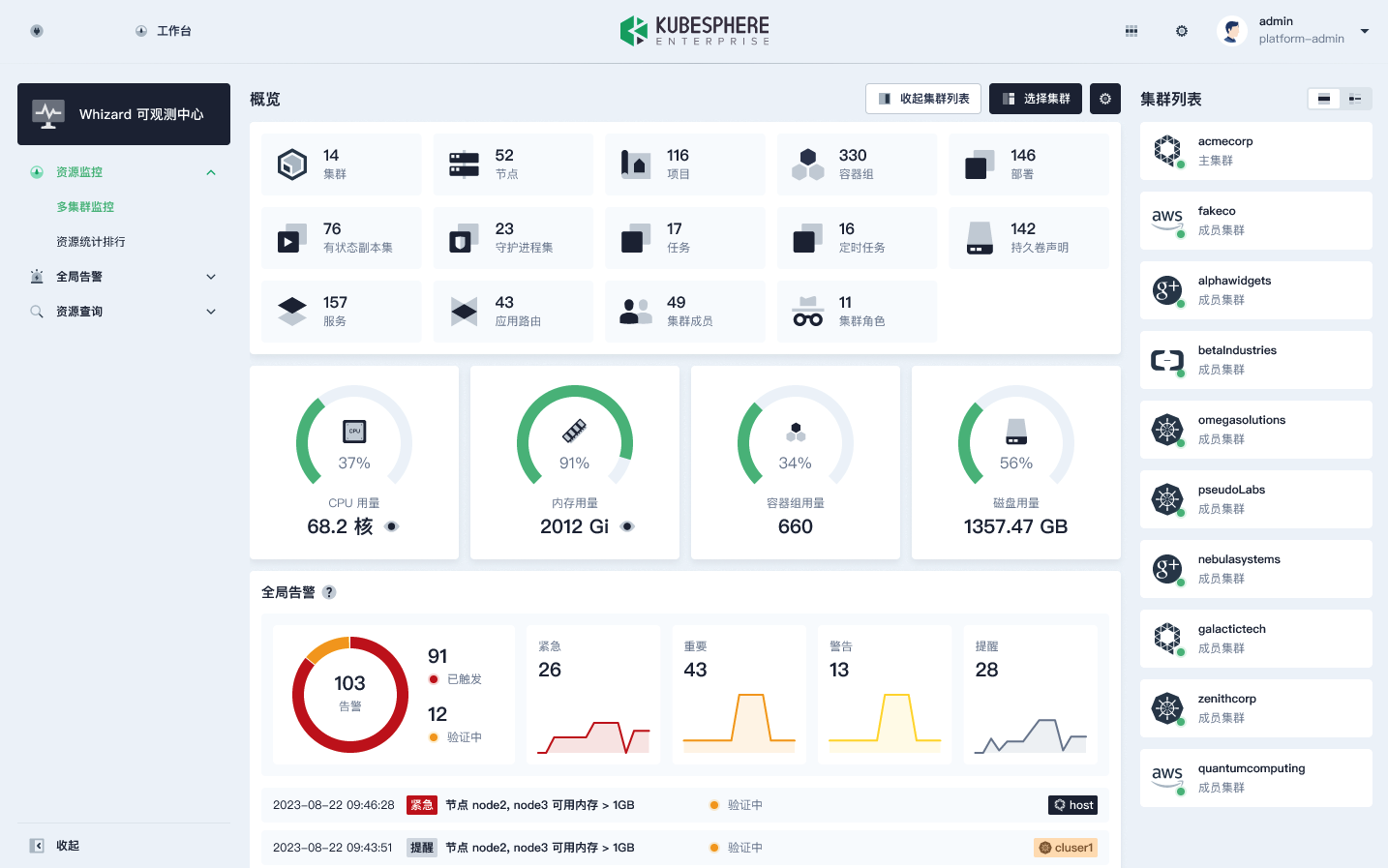
如图所示,我们可以看到右侧是一些集群的列表,这些集群对应的就是上文所说的 Whizard 的 Tenant;中间区域展示的则是所有集群的情况,比如使用的核数、节点数、项目数、容器组数,都可以从 Thanos 中查询到。
![]()
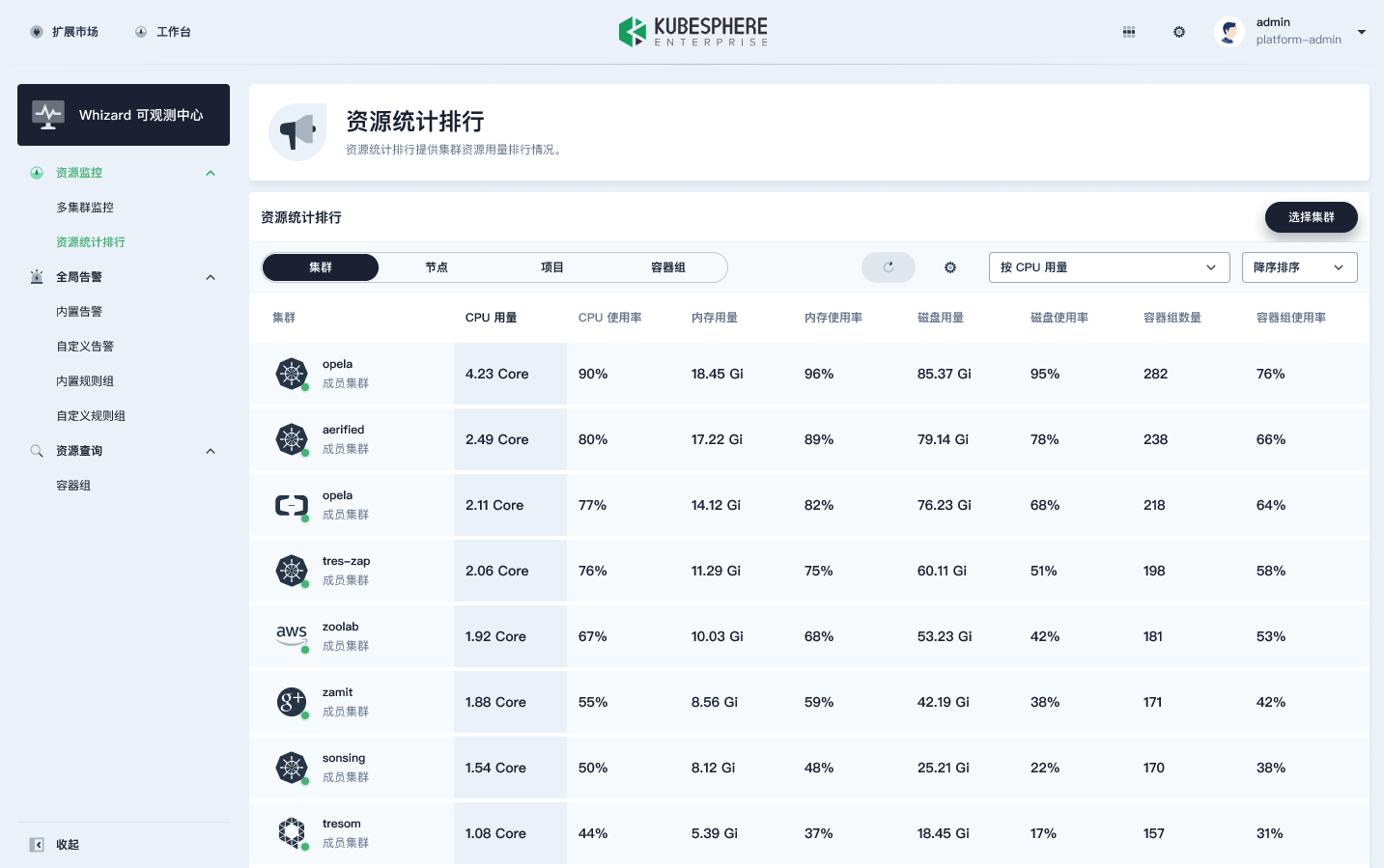
此外,在 Whizard 中,用户还可以跨集群对所有的集群进行资源统计排行,同时还可以看到所有的节点、项目和容器组。这样就比单实例的 Prometheus 多了一个集群的维度。
![]()
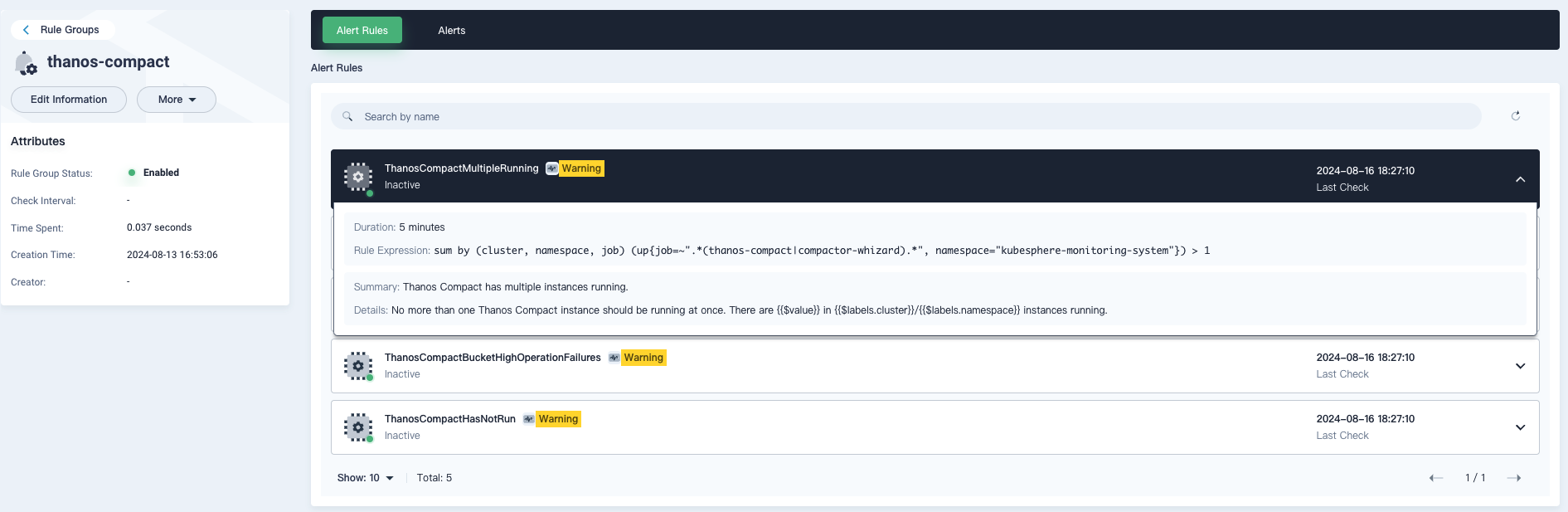
如上图所示是一个全局告警的展示,倒数第二列有一个集群的一列,这个也是通过 Thanos 全局的 Ruler 来计算出来的一个告警。
![]()
该功能是跨集群查询资源:在全部集群中,查询一个 pod 的 IP,属于哪个节点。
Roadmap
KubeSphere Enterprise v3.x 基于 Whizard 开发的 Whizard 可观测中心将在 KubeSphere Enterprise v4.x 后续版本中演进为 WhizardTelemetry 可观测平台:
- 支持更多的可观测性信号:日志、Tracing、事件、审计、通知、Continuous Profiling 等
- 提供更多的可观测性功能:事件/日志告警、FinOps 成本管理、报表等
- 支持 OpenTelemetry
- 基于 eBPF 技术提供无侵入的可观测性支持
- 大型语言模型应用的可观测性
- AI Infra 的可观测性
本文由博客一文多发平台 OpenWrite 发布!