前言
近年来,中国在信息技术领域持续追求自主创新和供应链安全,伴随信创上升为国家战略,一些行业也开始明确要求文件导出的格式必须为 OFD 格式。OFD 格式目前在政府、金融、税务、教育、医疗等需要文件开放、共享和长期保存的行业中广泛应用。这种趋势在未来几年内将进一步增强。
相较于 PDF,OFD 在以下方面展现了明显的优势,具体体现在:
PDF 是 Adobe 公司开发的专有格式,虽然也被广泛应用,但受制于 Adobe 公司的软件和许可。OFD 则是基于国际开放标准制定的开放式文档格式,任何人或组织都可以自由使用和开发相关软件。
PDF 主要用于文档展示和打印,功能较为单一。OFD 在文档展示、打印、编辑等方面都有更强大的功能支持。
PDF 文件通常会略大于 OFD 文件,因为 PDF 包含更多的元数据和功能,OFD 文件在保持良好的视觉效果的前提下,通常体积更小。
PDF 虽然跨平台性强,但在不同软件和系统中的表现可能会有差异,OFD 则具有更好的跨平台一致性。
PDF 文件可能包含隐藏的功能和潜在的安全隐患,OFD 则更加透明,安全性更高。
如何将 PDF 转化为 OFD?
既然导出 OFD 格式如此重要,然而目前市面上的报表工具,前端导出时通常只支持 PDF 格式。那么在这种情况下,如何实现一键在前端将报表导出为 OFD 格式呢?今天,小编将以葡萄城的嵌入式 BI 工具------Wyn 商业智能作为例子,向大家介绍如何将 PDF 转换为 OFD 格式。
![]()
首先小编先带大家一起了解下OFD文件解析的底层原理:
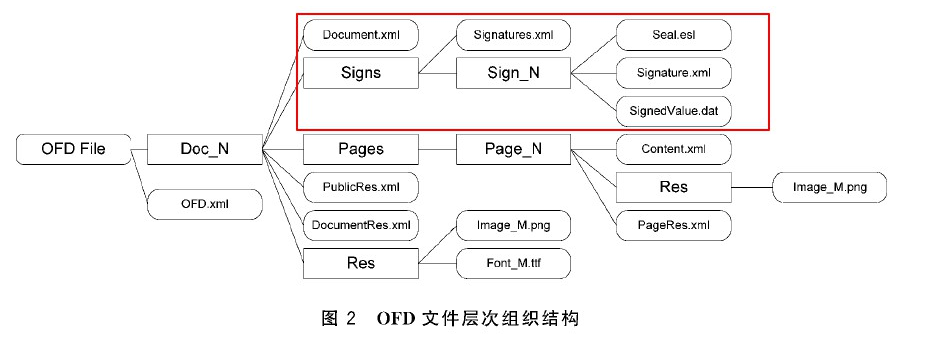
OFD 文件底层结构:
OFD 文件采用XML作为其基本结构,这意味着文件内容是以文本形式存储的,便于编辑和搜索。OFD 文件主要由以下几个部分组成:
- 文档头(Document Header):包含文档的基本信息,如标题、作者、创建日期等。
- 文档体(Document Body):包含文档的实际内容,如文字、图片、表格等。
- 资源文件(Resource Files):包括文档中使用到的图片、字体、样式等资源。
- 元数据(Metadata):提供有关文档内容的额外信息,如关键词、摘要等。
![]()
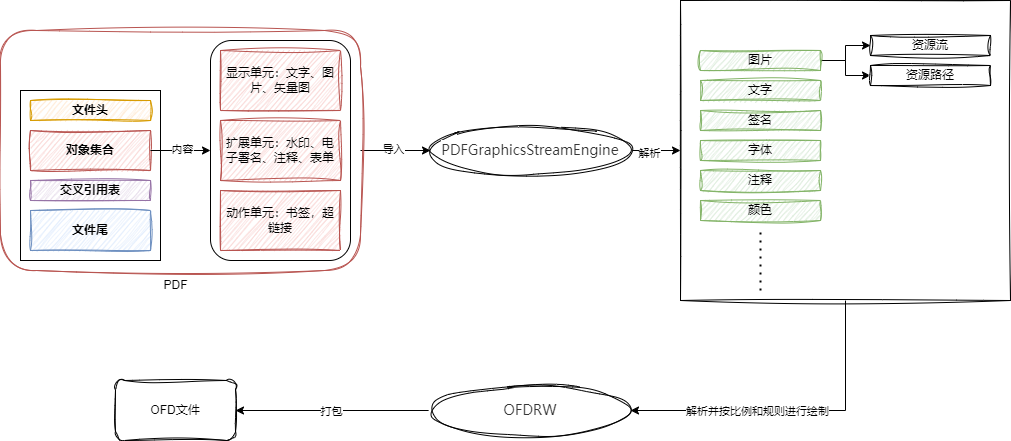
PDF 转换为 OFD 的流程:
![]()
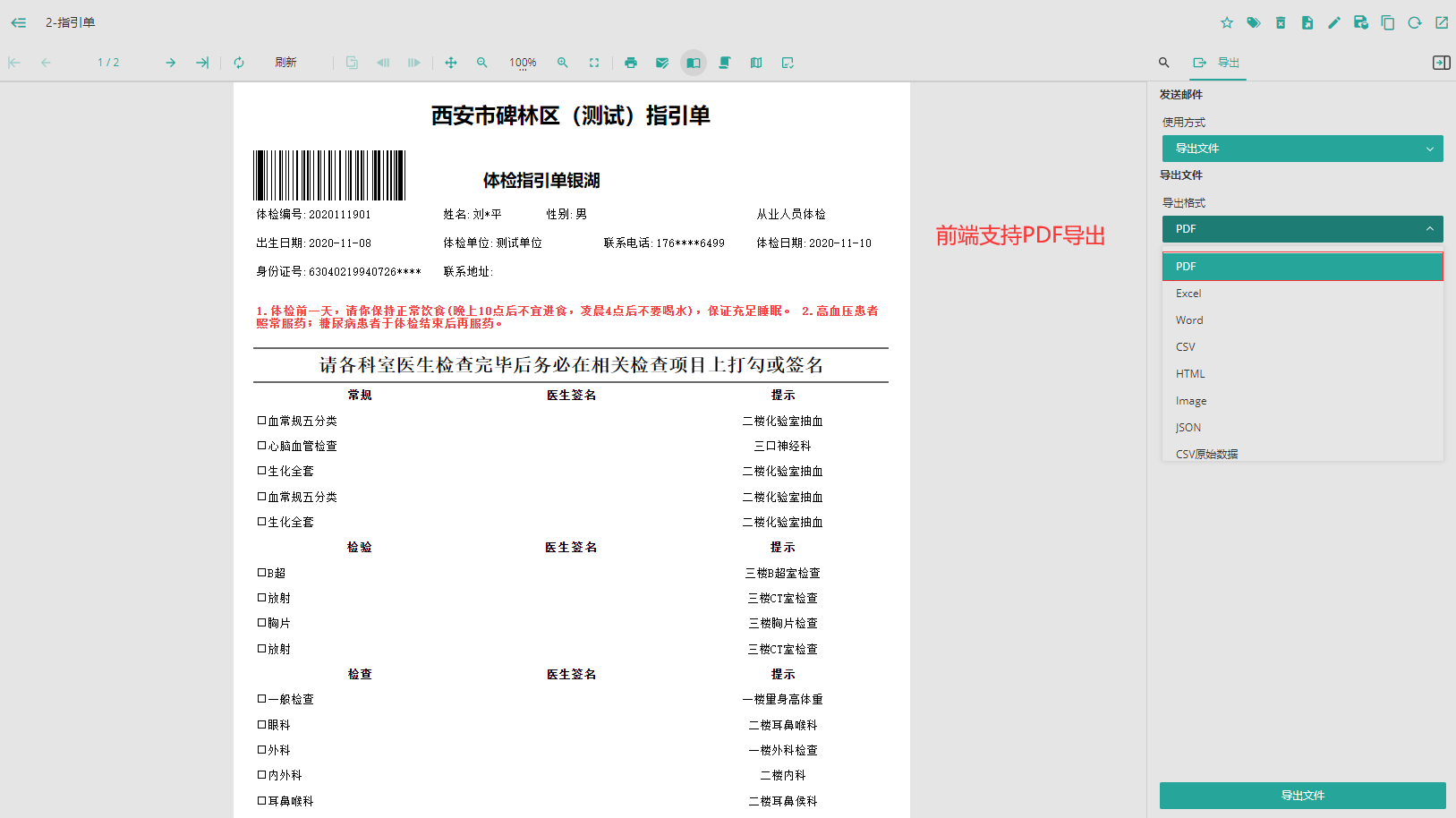
首先,通过使用 Wyn 报表工具,可以轻松设计出符合需求的报表样式。这些报表样式可以包含各种元素,例如表格、图表、图片、文本、超链接等等。设计完成后,可以直接在 Web 端进行预览,同时还支持将报表导出为PDF 格式。这样的设计流程和功能使得报表的创建和预览变得更加便捷和直观。
![]()
前端支持 PDF 导出只是第一步,为了实现从 PDF 转换为 OFD,还需要前端提供导出 PDF 的 API 接口,以便前端能够获取到 PDF 文件的流数据。幸运的是,Wyn 提供了丰富的 API 接口,使得前端可以通过接口直接实现PDF 的导出功能。这样的设计使得 PDF 转换为 OFD 变得更加便捷和可行。
PDF 转 OFD 的实现步骤
前端导出PDF文件的API接口:
http://localhost:51980/api/v2/reporting/export-templates/{exportTemplateId}
后端进行PDF文件解析的方法
- 继承 PDFGraphicsStreamEngine 类,便于分析 PDF 数据图层和资源归类
public class OFDPageDrawer extends PDFGraphicsStreamEngine {
}
- 重写构造方法,分析 PDF 每页的资源,并初始化 OFD 生成器
/**
构造器,调用super(page),这个操作的目的是将page资源准备好,并且添加对应的操作符,
当下一次调用processPage或者processPageContentStream时执行对应的操作符对应的操作
@param idx
@param page
@param ofdCreator
@param scale
@throws IOException
*/
protected OFDPageDrawer(int idx, PDPage page, OFDCreator ofdCreator, float scale)
throws IOException {
super(page);
this.page = page;
this.ofdCreator = ofdCreator;
ctLayer = this.ofdCreator.createLayer();
this.scale = scale;
}
- 重写 drawImage 方法收集整理 PDF 中分析出来的图片资源
/**
作用:将 PDF 图像对象转换为 OFD 格式进行绘制。此方法包括:
*
将图像写入字节流并保存。
根据当前变换矩阵计算图像在页面上的位置和大小。
创建 OFD 图像对象并设置其相关属性,然后添加到当前层中。
*
@param pdImage
@throws IOException
*/
@Override
public void drawImage(PDImage pdImage) throws IOException {
ByteArrayOutputStream bosImage = new ByteArrayOutputStream();
String suffix = "png";
ImageIO.write(pdImage.getImage(), suffix, bosImage);
String name = String.format("%s.%s", bcMD5(bosImage.toByteArray()), suffix);
ofdCreator.putImage(name, bosImage.toByteArray(), suffix);
// 根据当前变换矩阵计算图像在页面上的位置和大小,实际上就是将PDF中该图像的属性信息转换成OFD中的形式
Matrix ctmNew = this.getGraphicsState().getCurrentTransformationMatrix();
float imageXScale = ctmNew.getScalingFactorX();
float imageYScale = ctmNew.getScalingFactorY();
double x = ctmNew.getTranslateX() * scale;
double y = (page.getCropBox().getHeight() - ctmNew.getTranslateY() - imageYScale) * scale;
double w = imageXScale * scale;
double h = imageYScale * scale;
ImageObject imageObject = new ImageObject(ofdCreator.getNextRid());
imageObject.setBoundary(x, y, w, h);
imageObject.setResourceID(new ST_RefID(ST_ID.getInstance(ofdCreator.getImageMap().get(name))));
imageObject.setCTM(ST_Array.getInstance(String.format("%.0f 0 0 %.0f 0 0", w, h)));
setImageClip(imageObject, x, y, w, h);
ctLayer.add(imageObject);
}
- 通过继承 PDFGraphicsStreamEngine 类分析得到的文字内容重绘
public void addPageContent(int idx, CT_Layer ctLayer, float width, float height) {
PageDir pageDirInv = new PageDir();// 资源归类
pageDirInv.setIndex(idx);
org.ofdrw.core.basicStructure.pageObj.Page pageInv = new org.ofdrw.core.basicStructure.pageObj.Page();
CT_PageArea areaInv = new CT_PageArea();// ofd可视区域(PDF的裁剪区)
areaInv.setPhysicalBox(0, 0, width, height);
pageInv.setArea(areaInv);
Content contentInv = new Content();// 内容
contentInv.addLayer(ctLayer);
pageInv.setContent(contentInv);
pageDirInv.setContent(pageInv);
docDir.getPages().add(pageDirInv);
}
- 将收集到的资源进行打包生成 OFD 文件
/**
打包OFD文件包二进制数据
*
@param virtualFileMap
@return
@throws IOException
*/
public static void zip(Map<String, byte[]> virtualFileMap,OutputStream output) throws IOException {
ZipArchiveOutputStream zaos = new ZipArchiveOutputStream(output);
for (Map.Entry<String, byte[]> entry : virtualFileMap.entrySet()) {
zaos.putArchiveEntry(new ZipArchiveEntry(entry.getKey()));
zaos.write(entry.getValue());
zaos.closeArchiveEntry();
}
zaos.finish();
}
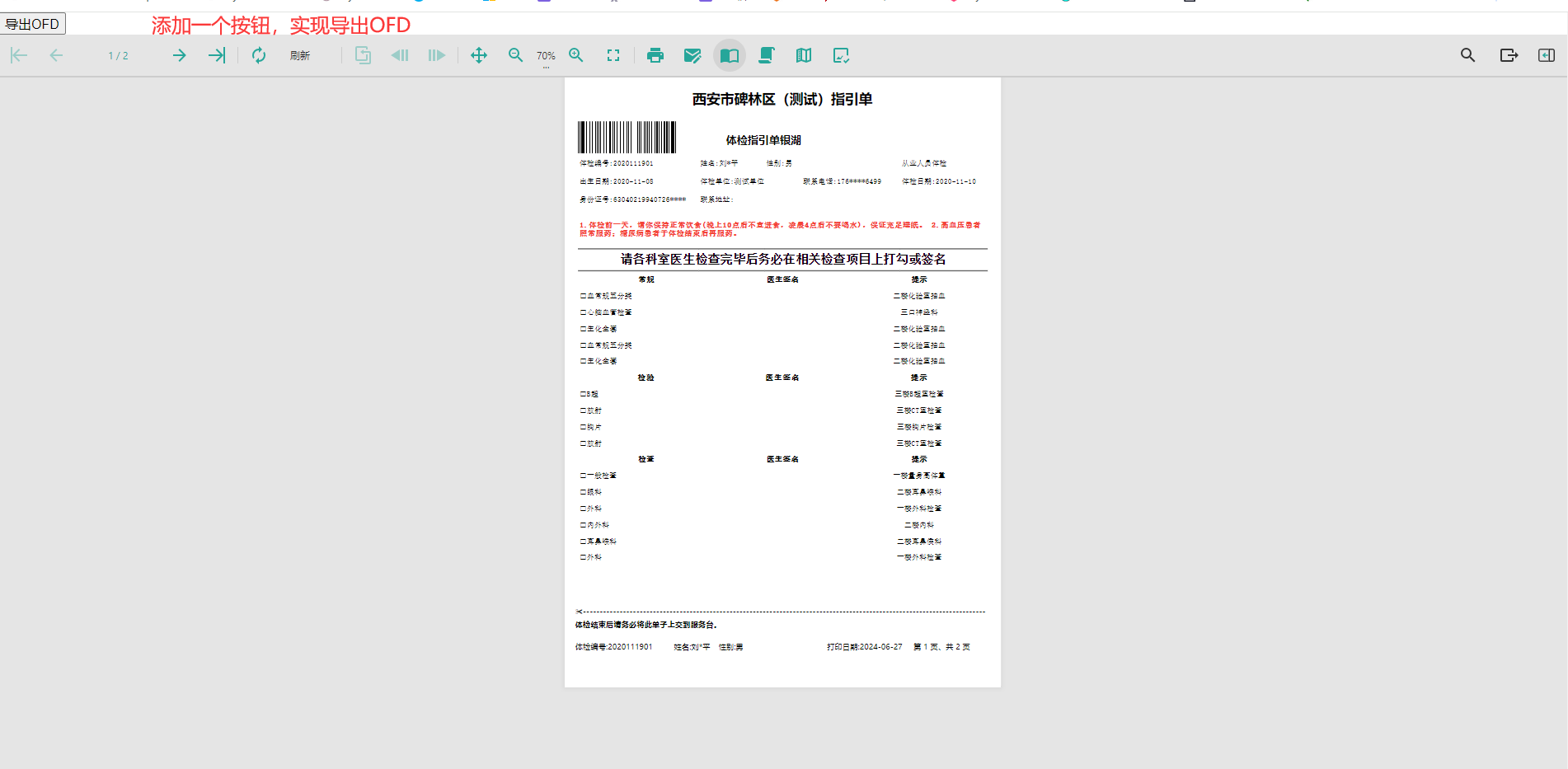
最终效果展示:
![]()
完整代码的链接:
GcExcelTestArea.rar
总结
在当今时代,对于国产化的支持,OFD(Office Open XML for Developers)变得越来越重要。本文首先介绍了OFD 文件的底层结构,并阐述了 OFD 相对于 PDF 的优势。接着,介绍如何通过葡萄城的嵌入式 BI 工具------Wyn 商业智能,进行报表设计和导出 PDF 。同时,还展示了如何使用 Wyn 商业智能的 API 接口将 PDF 转换为 OFD,除此之外,在企业级复杂系统中,除了 OFD 之外,Wyn还同时支持Word、Excel、图片、Text、JSON等多种格式的导出。
通过本文的介绍,我们可以清楚地看到,将 PDF 转换为 OFD 不再是一个困扰。借助 Wyn 强大的功能和丰富的 API 接口支持,能够轻松高效地实现文档格式转换。这一解决方案为用户提供了便捷、灵活的操作方式,满足了行业对 OFD 格式的要求。
扩展链接:
创意展示:打造数据大屏的炫酷天气预报插件
聊一聊数字孪生与3D可视化
探秘移动端BI:发展历程与应用前景解析