1 背景
2023 年 11 月发布的 PikiwiDB(Pika)【下文简称 Pika】 v3.5.2 开始支持混合存储,旨在通过缓存热点数据提升查询速度。
Pika v3.5.2 的热数据缓存只实现了对热点 Key 的点查(如get/hget),在后续的 v3.5.3 和 v3.5.4 修复若干 bug 后,对热数据的点查目前已经非常稳定。然而并未支持批量查询(如 mget/hmget etc)。
![]()
近期业务侧(360 AI 推荐)反馈批量查询速度比较慢,在 40core CPU/256GiB 内存/2TiB SATA SSD 规格机器上数据量超过 100GiB 时,Pika v3.3.6 30% 批量查询延迟超过 35ms【下文称之为失败率】。业务考虑升级 Pika 到 v3.5.4 版本,使用热数据缓存以提升性能。但由于 Pika 热数据缓存尚未支持批量查询,性能并未改善。
为了满足业务需求,Pika 团队开发了批量查询热数据缓存功能,显著提升了批量查询性能,降低了查询延迟和失败率。
2 原理
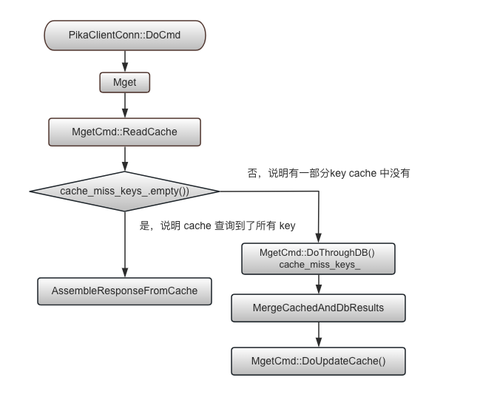
以 MGET 命令为例,批量查询热数据缓存采用以下策略:
- 命中缓存: 首先查询 RedisCache,获取缓存中的数据。
- 穿透磁盘: 对于未命中缓存的 key,从 RocksDB 中获取相应值。
- 合并结果: 将缓存和 RocksDB 中获取的数据按照原有顺序合并。
- 更新缓存: 将合并后的数据返回给用户,并将 RocksDB 查询到的值更新到 RedisCache。
这种优化方案能够有效减少磁盘 IO 操作,提高系统的访问效率和性能。查询及更新数据的流程图如下所示:
![image]()
3 效果
在 16core CPU/20GiB 内存/500GiB SATA SSD 规格虚机上,启用批量查询功能后, 缓存使用量和命中率情况如下:
10.192.52.235:25482> info cache
# Cache
cache_status:Ok
cache_db_num:8
cache_keys:12262599
cache_memory:5368709641
cache_memory_human:5120M
hits:34677314
all_cmds:68966333
hits_per_sec:38352
read_cmd_per_sec:68074
hitratio_per_sec:56.34%
hitratio_all:50.28%
load_keys_per_sec:0
waitting_load_keys_num:0
启用批量查询缓存优化功能后,批量命中率为 56%。
![]()
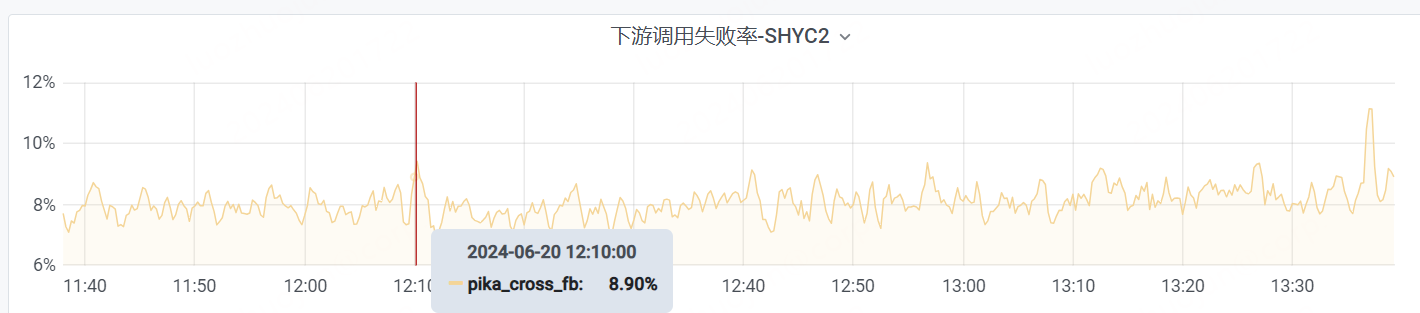
启用批量查询优化功能后,失败率降低到 8.9%。相比于 v3.3.6 的 31.7% 的失败率,失败率降低了 20%。
![]()
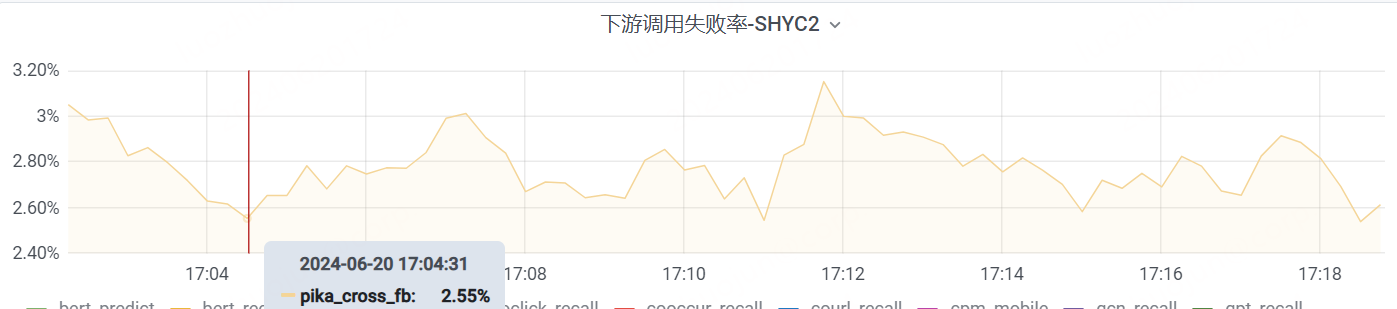
为了进一步降低失败率,使用 NVMe 盘替换 SATA SSD 盘后,失败率进一步降低到 2.55%,失败率降低 30% 左右。
可见,在实际应用场景中,批量查询热数据缓存功能显著提升了批量查询性能,降低了查询延迟和失败率:批量命中率为 56%,失败率最终降低到 2.55%。相比之下,未启用该功能时,批量命中率仅为 30%,失败率高达 31.7%。
4 后续
Pika 缓存批量查询已经提交到 PR 2694,近期即将发版的 v3.5.5 和 v4.0.0 将包含该功能,敬请关注。
目前, 首批支持的批量查询命令为 MGET,可用于高效地检索多个字符串键的值,还需要在 hashtable/list/zset 等复合数据类型中支持 HMGET/LRANGE/ZRANGE/ZREVRANGE/ZRANGEBYSCORE/ZREVRANGEBYSCORE/ZSCAN 等命令。相关 issue 任务 issue 2752 已经建立,欢迎对批量查询功能感兴趣的开发者参与讨论和贡献代码,共同打造更加强大高效的 Pika!
5 社区
PikiwiDB (Pika) 开源社区热烈欢迎您的参与和支持。如果您有任何问题、意见或建议,请扫码添加 PikiwiDB 小助手【微信号: PikiwiDB】为好友,它会拉您加入官方微信群。