![]()
作者 | KyrieChen
导读
本文阐述了百度&YY互动团队在设计稿转代码方面的实践与沉淀,自研的YYF2C是Figma & AI相结合生成开发代码的一站式解决方案。文章将从遇到的痛点以及对应的方案成果来阐述,并介绍相对应的YYF2C功能点。
全文4365字,预计阅读时间11分钟。
01 背景
业务部门存在着大量的活动、后台等类型的需求。随着这些需求量日益上涨,对开发、验收与交付的效率提出了新的要求。为了应对当前痛点,我们着手与设计工具结合,借助设计工具生态的开放性来解决痛点。公司设计工具主要为Figma,因此,我们致力于建立一套基于Figma设计工具的设计标准,并打造一个能够将设计稿转化为代码的生态系统。通过一年多的建设,公司内部大量的案例实践和洗礼,YYF2C生态应运而生。
02 YYF2C
YYF2C是什么?
YYF2C是一个Figma & AI相结合生成开发代码的一站式解决方案。
YYF2C有什么?
在YYF2C生态中,有Figma插件、Chrome插件、f2c-server,VSCode插件等。其中相关的功能有:静态代码生成、轻逻辑的支持、跨平台的代码输出和定制(DSL平台)、图层标记关联组件、产物SaaS服务、替代Figma Dev Mode的图层查看、一键切图上传、变量扩展与导出等一系列功能。
03 静态代码
它的作用主要是还原Figma设计稿中静态部分,生成相对应的代码。例如设计稿中的静态的规则、表格、介绍等。这块内容也是我们第一个攻克的难点。在自研之前,我们也调研过市面上的产品,尝试以最小的成本实现我们的目的。但调研后发现,现有产品的还原度都达不到我们的需要,无法落地到我们日常需求开发中。具体在于还原度较低,需要进行大量修改。于是,自研成为了我们唯一的选择。YYF2C在静态代码的还原度上,能满足我们日常需求中对其要求。在高还原度的加持下,使得使用者利用YYF2C转换出来的代码很少需要进行大量的手动调整,许多时候甚至不需要调整。这里举几个例子,分别是图层、特效、文本层面与市面上产品之间的对比。
![图片]()
△图层
上图是YYF2C对于多图层结构的还原结果,需要说明的是我们并不是一张图片直接输出,而是最大程度根据设计师的图层结构,进行合理的分析和排布得出的结果。通过与国内外主流工具的对比发现,YYF2C在多图层还原度方面是做的比较好的。其它工具均出现了或多或少的问题,例如透明度的处理不当、图层的结构混乱、字体颜色的缺失、阴影无法兼容等问题。
![图片]()
△线性渐变
上图是YYF2C对于线性渐变的还原结果,我们能看到YYF2C是相对较好的。由于Figma对于渐变的描述是一个矩阵,我们需要分析矩阵并利用线性代数的知识将分析出渐变的角度、渐变的颜色、渐变颜色的起始位置。有趣的是,Dev Mode作为Figma官方的功能,其对于线性渐变的还原度也不尽如人意。
![图片]()
△文本
上图是YYF2C对于文本的还原结果。可以看到对于文本间距和段落间距,YYF2C的处理是相对较好的。其它工具或多或少出现了间距丢失以及间距过大的问题。
当然,还原度高也不代表能100%还原成代码,这里涉及到很多Figma渲染和浏览器渲染的差异问题,这部分也在持续的迭代和优化。这部分内容由于篇幅的原因再次不做赘述,有兴趣的小伙伴可以关注【百度Geek说】留意后续技术文章。
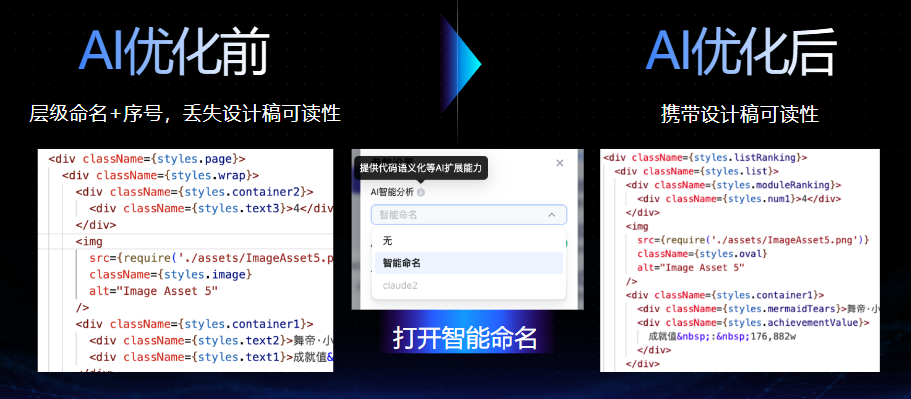
04 AI赋能语义化
通过YYF2C还原出来的静态代码默认情况下会出现类名语义化较差的问题,这一开始给用户在二次修改过程中造成了不小困扰。于是我们结合了AI的能力助力了代码优化,解决了代码可读性的问题。
![图片]()
05 轻逻辑代码
在完成静态部分的还原转码后就能够解决一部分问题。但是一个需求中静态部分的内容的占比是有限的,对于日常需求常见的都会有一些逻辑,例如按钮的点击、文本的动态生成、列表的动态展示,甚至是模块划分和父子组件的生成等。我们将上述部分称之为轻逻辑。如何更好的使用YYF2C静态还原带来的便利性,与轻逻辑相结合,成为了我们要考虑的问题。于是,我们提出了一系列高阶用法,这些高阶用法需要用户对制定图层附上标签(Layer Tag),标签能让YY F2C知道该图层需要调用什么轻逻辑的能力。标签目前有:
-
bg:
背景标签,主要用来表示该图层可以直接视作背景或图片,将以png格式的图片导出。用于解决复杂特效图层,减少分析成本。
-
var:
打上该标签的图层会在生成阶段为图层创建React组件的属性(Properties),使该图层(JSX片段)拥有二次开发的能力。
-
列表list与item:
list 和 item 标签主要用来处理列表中组件重复的使用场景。使用 list 标识列表的父组件,item 标识列表中需要抽象出来的子组件。
-
subComp:
该标签会将标识的图层下的所有图层作为子组件,更好的进行代码拆分。
-
slot:
slot 标签标识过的节点slot-name,会在生成阶段创建4个属性nameSlot、nameCss、nameProp、nameText,默认使用一张背景图片做占位,nameSlot 作为组件替换插槽位置。
-
module:
module 标签的用法与subComp一致,唯一的不同是module会将子组件抽取到单独的目录。
-
tab相关的tabList、tabPanel、tabSlider:
tabs是一组标签组,用于标记类选项卡组件的界面,tabs包含三种标签:
tabList用于标识可以点击切换节点的父容器;
tabPanel用于标记要切换内容的panel节点;
tabSlider 可选标记,用于标记的滑块节点。
下面快速介绍一下tag标识如何使用以及使用的效果,具体使用可以参考官网文档。
![图片]()
06 组件标记
对于成熟的业务组来说,有许多功能早就以组件的形式沉淀。对于一个常用的功能,在有组件可用的情况下,不可能使用YYF2C重新生成。并且对于组件样式参数在设计稿上获取和传递,成为了制约我们的开发效率。于是如何与先有组件结合,甚至与设计组件结合,成为了我们要面对的问题。
以下是F2C组件标记原理的简单示意图:
![图片]()
通过组件标记,我们目前实现了手Y的RN组件库、百轲管理后台组件库以及多业务活动组件的代码生成,极大扩展了F2C的使用场景。
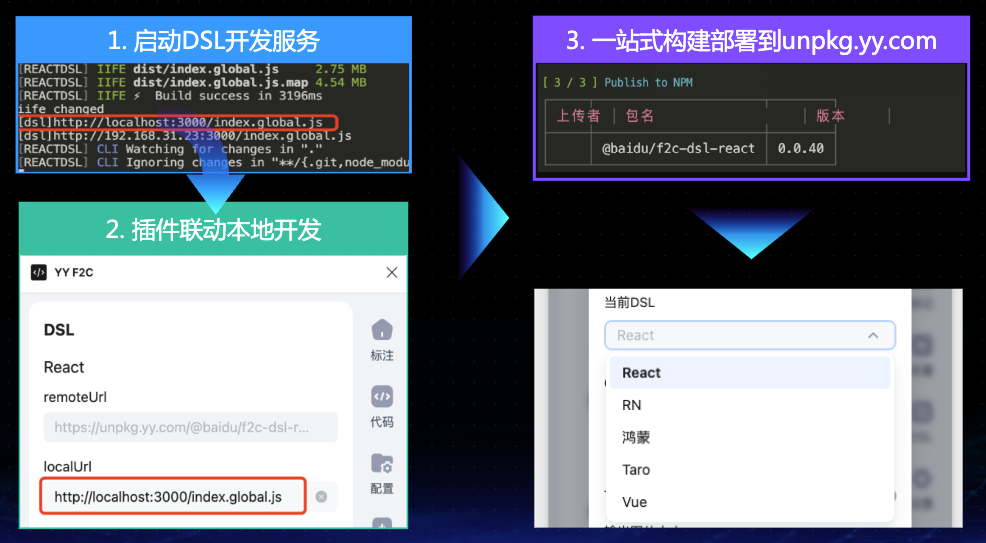
07 多语言(DSL)
DSL(Domain-specific language)的全程是领域特定语言。在F2C转码过程中,我们把设计语言通过转换器实现转译为特定代码语言这个过程中的转换器实现,简称为DSL。
F2C通过DSL包开发和独立部署解决不同语言代码生成的开发问题。
![图片]()
F2C通过DSL包与Figma插件约定数据规范,实现了不同DSL在Figma插件中定制GUI和转码行为的能力。
![图片]()
08 SAAS服务
公司内部有许多低代码平台,本质是运用沉淀组件更好更快的迭代产品的需求。与组件一样,样式参数在设计稿上获取和传递,依旧比较繁琐。YYF2C可以快递高效的获取到组件的样式参数,那如何与低代码平台结合,成为了我们要面对的问题。
为此我们搭建了基于YYF2C产物的SAAS服务(暂时对内),他的作用是将YYF2C生成的产物,包括:设计稿源代码、组件标记获取到的组件属性以及相关的资源图,上传至服务器并标识该次上传。用户若想使用这次上传的内容,则可以通过对外接口以及上传标识获取到产物,将产物作用于自身平台。
![图片]()
目前公司内部已经有多个业务接入该服务,其中不乏接入后业务产品运营可以直接通过低代码平台完成设计稿并自动上线的案例,对于接入方整体的提效约有15%左右。
09 替代Dev Mode
从2024年开始,Figma的Dev Mode开始收费。这让我们使用者获取图层标注信息的便利性大大下降,对此社区有很多通过window.figma接口获取信息的chrome插件供我们使用。但是2024年3月19日开始,Figma移除了view-only模式下的window.figma接口,这彻底堵死了用户在view-only模式下获取图层标注的能力(截止编写该文时Figma官方答应会加回接口,但是时间未定)。
为了降低此事对公司内部开发者的影响。我们在YY F2C Figma插件v2版本添加了图层查看功能。
![图片]()
并且推出Chrome插件,以应对view-only模式下的问题。
![图片]()
△chrome插件
两者不同之处在于,图层查看功能需要用户有编辑权限,展示的内容更为丰富。Chrome插件不需要用户有编辑权限,展示的内容则较为简单。通过这两个工具的加持,我们能基本将Dev Mode收费带来便利性下降的影响降到最低。
10 未来
AI:目前YY F2C对AI的使用局限于语义化,如今市面上已经有许多大模型AI实现了图片转代码功能,并且也有很多产品能直接优化我们的代码。这也许为我们指明了一个方向。
多平台:目前公司内部主要以Figma设计工具为主,但是市面上诸如MasterGo、即时设计等产品也有许多人在使用。那么对于这些用户,我们后续会考虑兼容其插件生态体系。为更多用户提供能力。
持续优化功能模块:提高还原度、提升DSL接入便利性、开放自定义图片上传、开放自定义产物上传、拥抱和吸纳更多建议和意见。
和更多团队伙伴合作:在团队内部,YY F2C 已经落地了多个项目,目前正在和更多团队伙伴合作,希望 YY F2C 能够成为更多团队的标配。
如何获得F2C:
Figma F2C插件:
https://www.figma.com/community/plugin/1248187540929489451/yy-f2c
Chrome插件:
https://chromewebstore.google.com/detail/figma-node-inspect/gmcgpjgoiidajfjhdooaajaeonnmikfc
F2C VSCode插件:
https://marketplace.visualstudio.com/items?itemName=ron0115.f2c-vscode
F2C官网:
https://f2c.yy.com/
视频教程:
https://b23.tv/GLow6GP
如何和我们交流:
github:https://github.com/yylive/F2C/issues
点击此处查看原文,欢迎大家沟通、交流。
—————— END——————
推荐阅读:
如何实现埋点日志精准监控
从打点平台谈打点治理
手把手教你用Spring Boot搭建AI原生应用
Baidu Comate帮开发者“代码搬砖”,2天搞定原先3周工作量
用 Baidu Comate 实现研发提效,百度营销服务团队打造“轻舸”加速营销智能化