精彩纷呈的 OurBMC 开源大赛已告一段落,经历为期四个月的实战,各个参赛队伍也积淀了丰富的实践经验与参赛心得。本期,社区特别邀请 OurBMC 开源大赛获奖高校团队分享「走进OurBMC开源大赛,共同践行开放包容、共创共赢的开源精神」,让更多人看见开源的魅力、技术的力量。
PART.01
![]()
· 参赛背景
利用在学校里学到的专业知识和技能,解决当今服务器故障诊断与预测领域遇到的问题,为提升服务器运维效率和可靠性做出贡献。希望我们能凭借自己的的努力为国内 BMC 技术领域的发展带来新的思路和解决方案。
· 核心方案
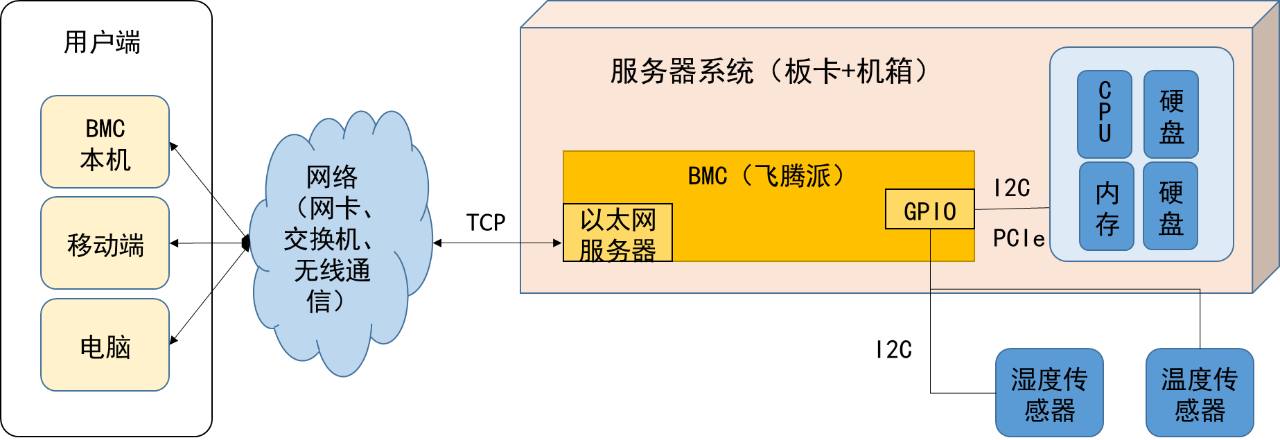
本次获奖作品 “BMC 数据可视化与故障分析平台设计”,整体架构:
![]()
首先将安装了 Linux 操作系统的飞腾派作为 BMC(Baseboard Management Controller)基板,为整个平台提供可靠的软件运行环境;其次利用 I2C 连接对端 CPU 和温度传感器,收集系统数据;最后利用 QT 研制桌面端 APP 和移动端 APP,用来实时展示系统数据,同时也可以通过可视化方式管理和控制 BMC 设备,整套平台使用方便。
· 参赛过程及心得
我们在参赛过程中遇到了一些挑战,同时也提升了自己的综合能力。在赛题解析方面,我们对涉及到服务器故障诊断与预测领域的专业知识比较陌生,花了很多时间进行了大量的文献查阅和实验验证,为后续比赛打牢基础。同时,我们也面临着如何平衡比赛和课程压力的难题。在导师的指导下,我们制定了详细的学习和工作计划,并在每个阶段都适当预留时间以保证学习工作计划和其它事务之间的平衡。总的来说,参加比赛的过程充满挑战但也充满乐趣。
· 我对社区说
开源让我们能够共同探索 BMC 技术栈,创造出更加先进和可靠的解决方案。期待在这个充满活力的社区中,开发者可以不断汲取知识,互相分享经验,共同成长。衷心期待与社区成员共同推动 BMC 技术的发展,为社区 BMC 技术发展贡献力量。
PART.02
![]()
· 参赛背景
我们在本科期间参与过集创赛飞腾命题赛道,也持续关注飞腾和 OurBMC 社区相关信息,对尚未踏足的 BMC 技术感兴趣。我们愿意和更多开发者一起探索 BMC 技术,希望在比赛期间能在 OurBMC 社区留下学习探索的足迹和 debug 脚印。
· 核心方案
本次获奖作品 “基于 BMC 技术的服务器故障诊断与预测平台设计——系统移植” 核心流程如下:首先将 OurBMC 社区的 OpenBMC 源码编译,生成适配飞腾 CPU 的 OpenBMC 操作系统;其次将 rootfs 文件系统与适配飞腾派的 uboot、内核 image kernel、设备数 dtb 一同烧录到 sd 卡中;然后在 OpenBMC 操作系统中通过 Webui-vue 实现远程 bmc 服务器数据采集与处理;最后将处理后的数据以图标形式展示在 Web 中。
· 参赛过程及心得
在参赛过程中,我们在编译和移植 OpenBMC 文件系统时遇到了困难和挑战,例如不知道如何在 Yocto 工程中使用 BitBake 工具编译文件系统;也不了解如何将 uboot、kernel、dtb、rootfs 烧录到飞腾派中;对于 OpenBMC 的启动也无从下手;同时数据采集和显示等都需要花费时间和精力去学习和探索。这些问题是挑战也是机遇,在导师指导下,我和我的搭档也做了大量文献阅读,积极向赛事技术支持团队请教,一一攻克技术难题。另外由于学业课程也比较多,我们充分利用科研任务以外的所有时间来参与比赛。技术的高难度和学业的高强度虽导致作品完成度不高,留下一点小遗憾,但最后可以成功晋级决赛并获奖也是对这段挑战和机遇的肯定。
· 我对社区说
在本次 OurBMC 开源大赛中,我们不仅看到其它参赛企业如何在 BMC 中实现了优美的 UI 界面与丰富的应用,在和参赛企业人员的交流中,也让我们对 BMC 技术栈有了更深的理解。希望能有更多的 BMC 技术开发者加入进来,一起创建我们自己的 BMC 技术栈。
首届 OurBMC 开源大赛已圆满落幕,但开源不断,创新不止,期待更多的开发者成为开源世界的英勇探索者。OurBMC 社区诚邀业界广大同仁积极参与社区建设和交流,一起为社区和 BMC 生态贡献力量,共同取得更加卓越的成就。