

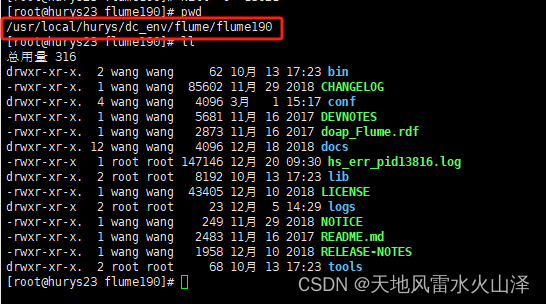
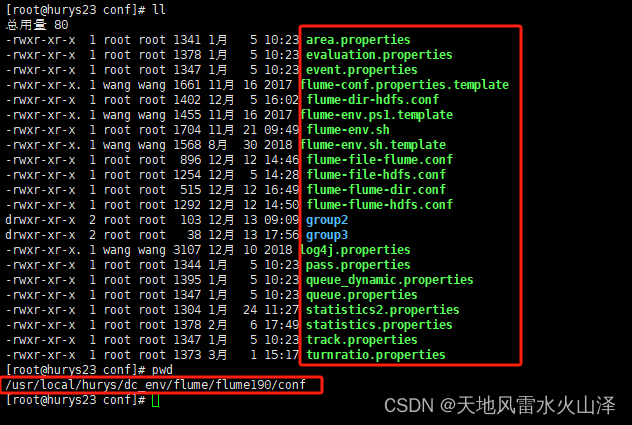
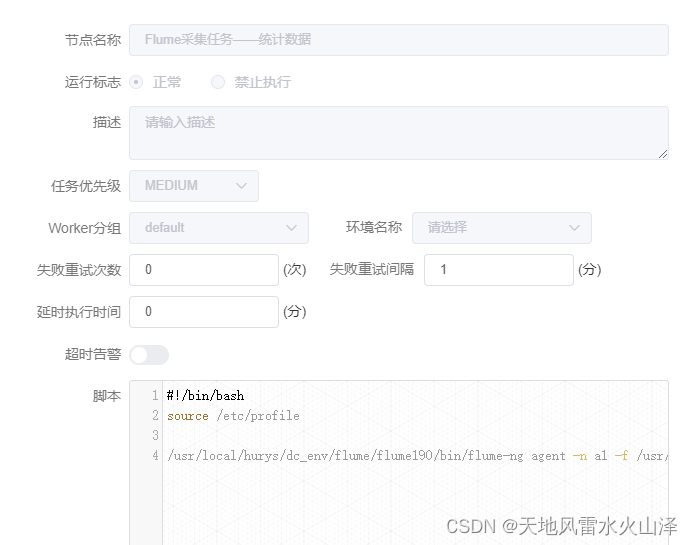

 可以看到,Flume采集Kafka数据成功写入到HDFS中,成功实现用Apache DolphinScheduler执行Flume任务的目的!
可以看到,Flume采集Kafka数据成功写入到HDFS中,成功实现用Apache DolphinScheduler执行Flume任务的目的!
12 个监控指标确保 API 策略成功
原文作者:Andrew Stiefel of F5 原文链接:12 个监控指标确保 API 策略成功 转载来源:NGINX 开源社区 NGINX 唯一中文官方社区 ,尽在nginx.org.cn 随着公司采用API 优先的设计实践来构建现代应用,衡量这些 API 的运行性能和价值成为当务之急。构建一个可明确定义 API 指标并将其与关键绩效指标 (KPI) 挂钩的框架是确保 API 策略成功的最重要步骤之一。 通常情况下,KPI 与具体目标紧密相关。它们有着明确的时间框架,并与 API 策略需要交付的成果相匹配。相比之下,API 指标是重要的数据点。并非所有指标都是 KPI,但每个 KPI 都基于指标。 那么您应该如何着手呢?首先,您需要从一开始就明确 API 策略的目标,然后再选择与该目标匹配的指标。切记每个团队需要根据对自身的重要性和对业务的必要性衡量并跟踪不同的指标。 概括地说,公司可跟踪三大类 API 指标,并且不同类别的指标反映不同的问题: 运维指标——API 是否提供您所需的稳定性、可靠性和性能? 采纳指标——开发人员是否采纳使用您的 API? 产品指标——API 正如何支...