![llama3.png]()
简介:
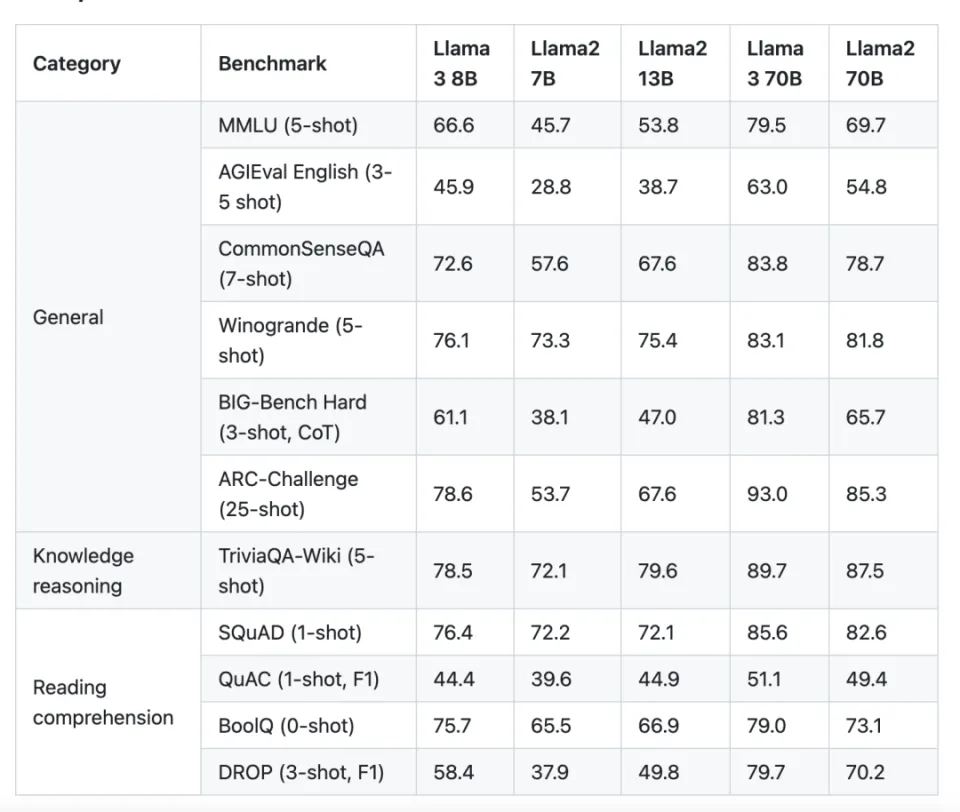
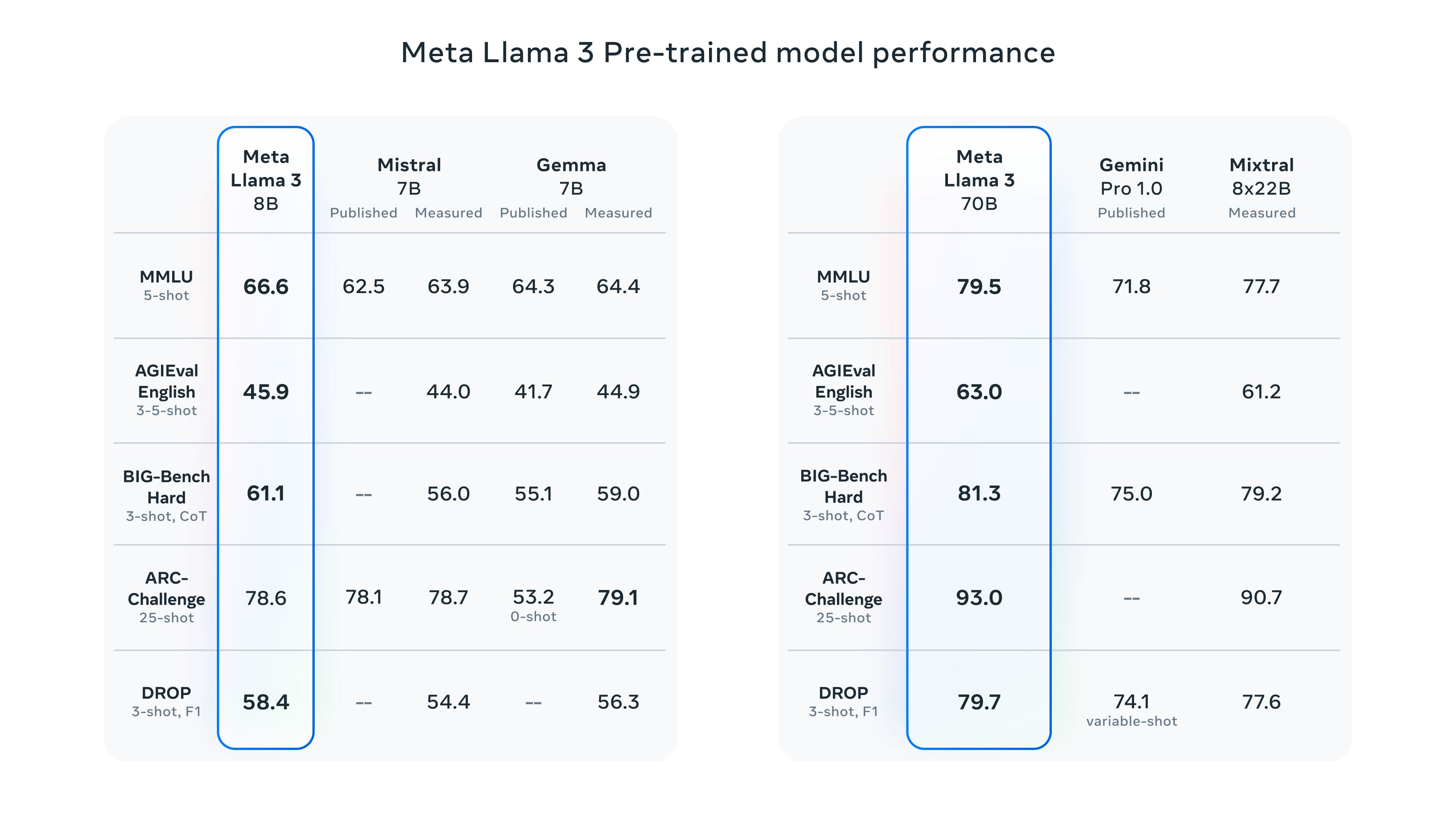
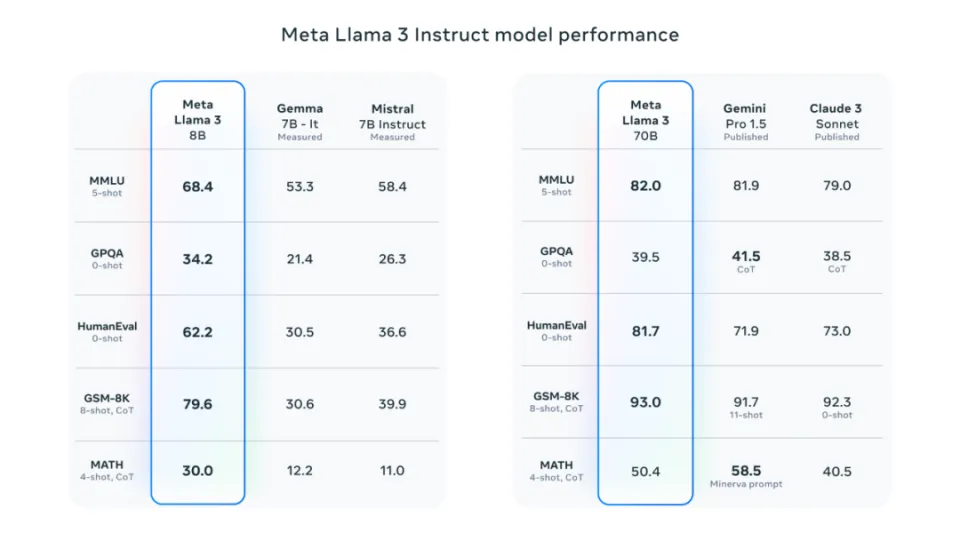
Llama 是由 Meta(前身为 Facebook)的人工智能研究团队开发并开源的大型语言模型(LLM),它对商业用途开放,对整个人工智能领域产生了深远的影响。继之前发布的、支持4096个上下文的Llama 2模型之后,Meta 进一步推出了性能更卓越的 Meta Llama 3系列语言模型,包括一个8B(80亿参数)模型和一个70B(700亿参数)模型。Llama 3 70B 的性能媲美 Gemini 1.5 Pro,全面超越 Claude 大杯,而 400B+ 的模型则有望与 Claude 超大杯和新版 GPT-4 Turbo 掰手腕
在各种测试基准中,Llama 3系列模型展现了其卓越的性能,它们在实用性和安全性评估方面与市场上其他流行的闭源模型相媲美,甚至在某些方面有所超越。Meta Llama 3系列的发布,不仅巩固了其在大型语言模型领域的竞争地位,而且为研究人员、开发者和企业提供了强大的工具,以推动语言理解和生成技术的进一步发展。
项目地址:
https://github.com/meta-llama/llama3
llama2和llama3的差异
![llama3and3diff.webp]()
llama3和GPT4的差异
| 指标 |
Llama 3 |
GPT-4 |
| 模型规模 |
70B、400B+ |
100B、175B、500B |
| 参数类型 |
Transformer |
Transformer |
| 训练目标 |
Masked Language Modeling、Perplexity |
Masked Language Modeling、Perplexity |
| 训练数据 |
Books、WebText |
Books、WebText |
| 性能 |
SOTA(问答、文本摘要、机器翻译等) |
SOTA(问答、文本摘要、机器翻译等) |
| 开源 |
是 |
否 |
Llama 3 的亮点
-
面向所有人开放:Meta 通过开源 Llama 3 的轻量版本,让前沿的 AI 技术变得触手可及。无论是开发者、研究人员还是对 AI 技术好奇的小伙伴,都可以自由地探索、创造和实验。 Llama 3 提供了易于使用的 API,方便研究人员和开发者使用。
-
模型规模大:Llama 3 400B+ 模型的参数规模达到了 4000 亿,属于大型语言模型。
-
即将融入各种应用: Llama 3 目前已经赋能 Meta AI,Meta AI体验地址:https://www.meta.ai/
![llama3-pre-trained.png]()
![llama3-8b-70b.webp]()
![llam3-15T-tokens.png]()
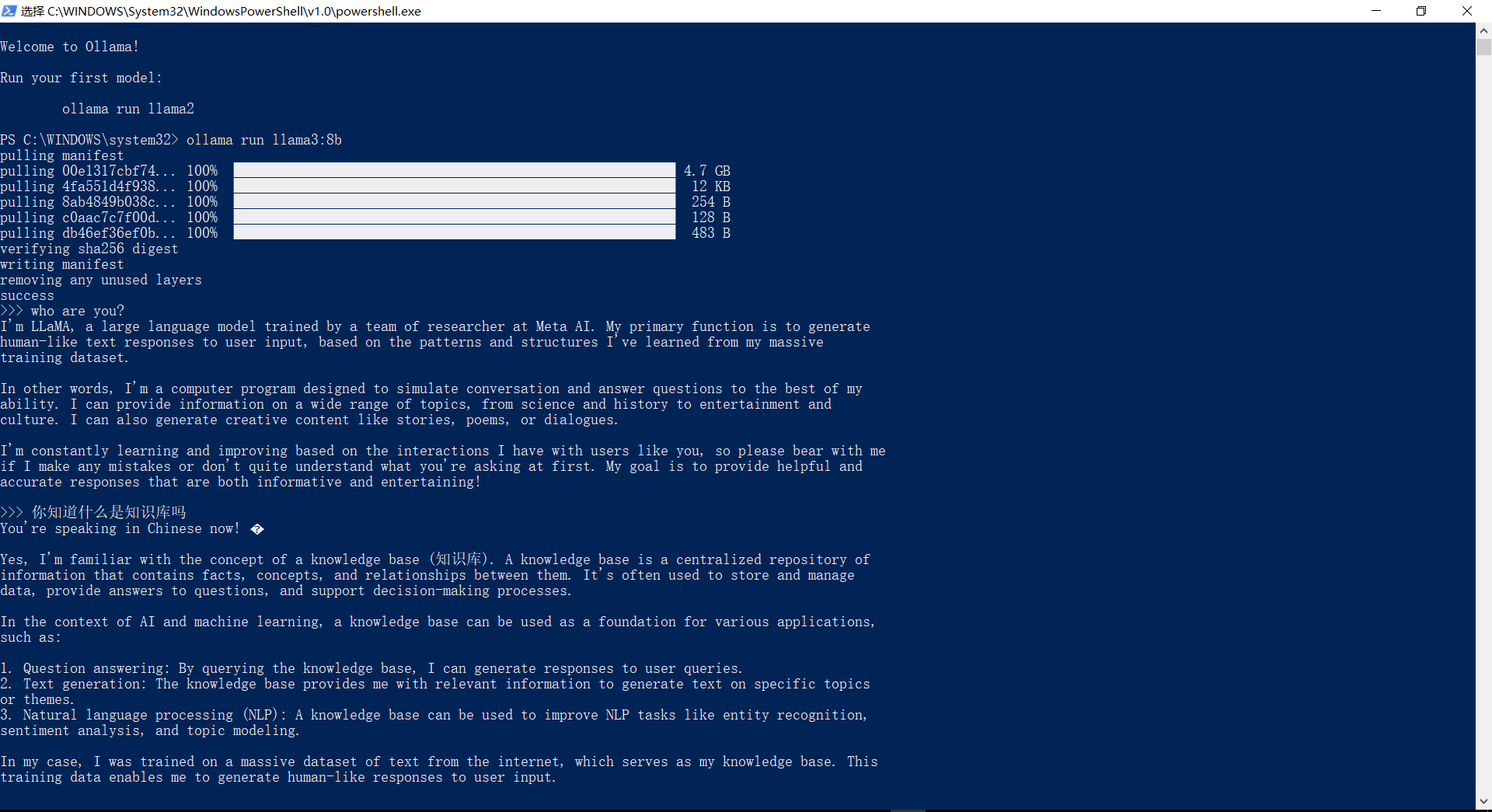
在 Windows 上使用 Ollama,运行Llama3模型
访问https://ollama.com/download/windows页面,下载OllamaSetup.exe安装程序。
安装后,根据自身电脑配置,选择对应模型参数安装(运行 7B 至少需要 8GB 内存,运行 13B 至少需要 16GB 内存)
我这里运行的是Llama3:8b,可以看出,中文还是有点问题
![ollama3.png]()
| Model |
Parameters |
Size |
Download |
| Llama 3 |
8B |
4.7GB |
ollama run llama3 |
| Llama 3 |
70B |
40GB |
ollama run llama3:70b |
| Mistral |
7B |
4.1GB |
ollama run mistral |
| Dolphin Phi |
2.7B |
1.6GB |
ollama run dolphin-phi |
| Phi-2 |
2.7B |
1.7GB |
ollama run phi |
| Neural Chat |
7B |
4.1GB |
ollama run neural-chat |
| Starling |
7B |
4.1GB |
ollama run starling-lm |
| Code Llama |
7B |
3.8GB |
ollama run codellama |
| Llama 2 Uncensored |
7B |
3.8GB |
ollama run llama2-uncensored |
| Llama 2 13B |
13B |
7.3GB |
ollama run llama2:13b |
| Llama 2 70B |
70B |
39GB |
ollama run llama2:70b |
| Orca Mini |
3B |
1.9GB |
ollama run orca-mini |
| LLaVA |
7B |
4.5GB |
ollama run llava |
| Gemma |
2B |
1.4GB |
ollama run gemma:2b |
| Gemma |
7B |
4.8GB |
ollama run gemma:7b |
| Solar |
10.7B |
6.1GB |
ollama run solar |
Hugging Face 使用
访问:https://huggingface.co/chat/ 然后切换Models
Replicate 使用
8B 模型:https://replicate.com/meta/meta-llama-3-8b
70B 模型:https://replicate.com/meta/meta-llama-3-70b
本文是转载文章 珩小派,版权归原作者所有。建议访问原文,转载本文请联系原作者。