主从延迟调优思路
1、什么是主从延迟?
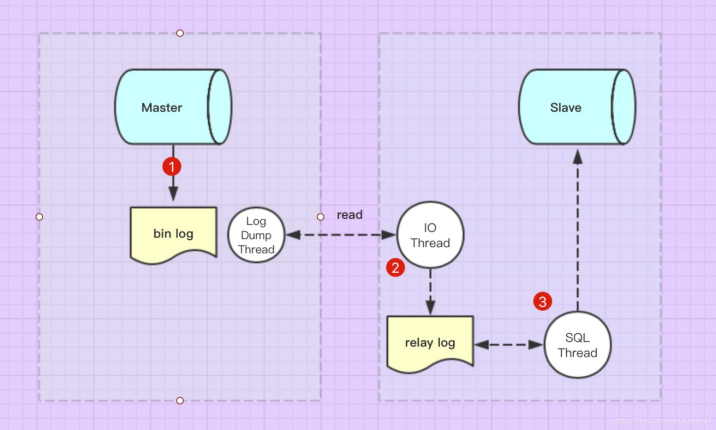
本质是从库的回放跟不上主库,回放阶段的延迟
![]()
2、主从延迟常见的原因有哪些?
1、大事务,从库回放时间较长,导致主从延迟
2、主库写入过于频繁,从库回放跟不上
3、参数配置不合理
4、主从硬件差异
5、网络延迟
6、表没有主键或者索引大量频繁的更新
7、一些读写分离的架构,从库的压力比较大
3、解决主从延迟有哪些方法
1、对于大事务,拆分成小事务
2、开启并行复制
3、升级从库硬件
4、尽量都有主键
4、什么是并行复制,参数有哪些?
回顾MySQL并行复制的路程
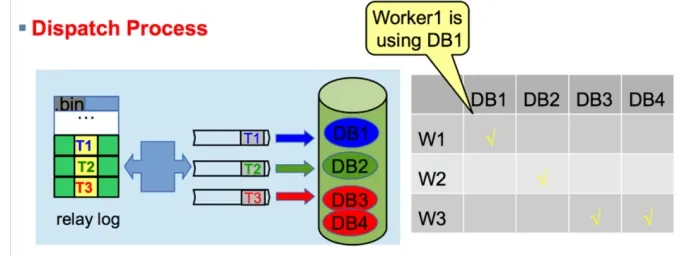
MySQL5.6 是基于数据库级别的并行复制
slave-parallel-type=DATABASE(不同库的事务,没有锁冲突)
![]()
MySQL5.7 基于group commit的并行复制
slave-parallel-type=LOGICAL_CLOCK : Commit-Parent-Based模式(同一组的事务[last-commit相同]没有锁冲突. 同一组,肯定没有冲突,否则没办法成为同一组)
上面是从库的配置,并行复制依赖于主库的组提交(注意区分组复制)
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
以上参数都依赖于主库业务繁忙的情况下,如果业务不频繁,就会很尴尬
binlog_group_commit_sync_no_delay_count:这个参数设置成2个
比如只有一个线程执行一个事务,第二个事务在24h之后执行,那么这个事务需要等待24h才能提交,十分坑
binlog_group_commit_sync_delay
假如设置成200ms,只有一个线程执行一个事务,本来10ms可以提交,还必须等待200ms才可以
线上一般是两个都设置,举个例子,就像是小船运人过河
假设我们的参数这么设置:
binlog_group_commit_sync_delay=200;
binlog_group_commit_sync_no_delay_count=2
要么满足200ms直接走,要么满足2个人直接走,这么人性化了很多,但是在业务不繁忙的情况下依然尴尬
![]()
MySQL8.0 基于write-set的并行复制
基于主键的冲突检测(binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION, 修改的row的主键或非空唯一键没有冲突,即可并行)
事务检测算法:transaction_write_set_extraction = XXHASH64
MySQL会有一个变量来存储已经提交的事务HASH值,所有已经提交的事务所修改的主键(或唯一键)的值经过hash后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系
这里说的变量,可以通过这个设置大小:binlog_transaction_dependency_history_size
这样的粒度,就到了 row 级别了,就是此时并行的粒度更加精细,并行的速度会更快,某些情况下,说slave的并行度超越master也不为过(master是单线程的写,slave也可以并行回放)
简单来说就是基于行去并行回放,rc级别下不同的行不会有锁冲突
组提交的表现:
看主库binlog的last_committed值是否一致,一致就可以并行回放,不一致只能串行
![]()
5、实战分析
5.1 查看线上主从延迟
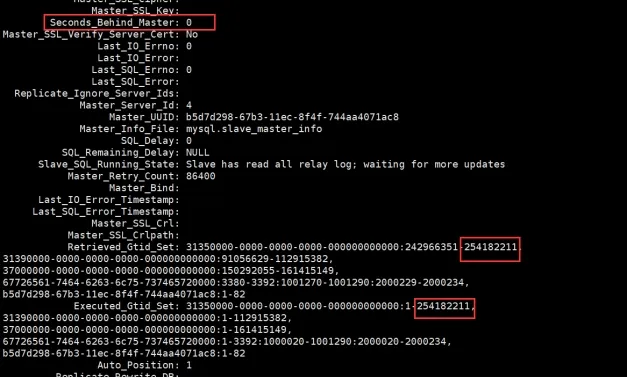
Seconds_Behind_Master: 48828
可见延迟很高,接近14个小时,此时主库也在不断的写数据,大概是6分钟一个binlog,一个为500M
5.2 查看当前的复制配置
查看从库配置:
greatsql> show variables like '%slave%para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 128 |
+------------------------+---------------+
2 rows in set (0.02 sec)
延迟现象:
从库一直在追,说明不是大事务,但是Seconds_Behind_Master延迟一直在增长
Retrieved_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:242966351-253068975,
00000000-0000-0040-0095-5fff003b4b99:91056629-110569633,
00000000-0000-005c-0ced-7bae003b4b99:150292055-160253193,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Executed_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:1-252250235,
00000000-0000-0040-0095-5fff003b4b99:1-109120315,
00000000-0000-005c-0ced-7bae003b4b99:1-159504296,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Auto_Position: 1
此时怀疑并没有并行复制,主库可能没设置组提交(只是一个猜想)
5.3 进一步验证,查看主库的binlog
查看主库的参数配置:还是为组提交的规则
greatsql> show variables like '%binlog_transac%';
+--------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------+----------+
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
+--------------------------------------------+----------+
4 rows in set (0.02 sec)
再看其组提交的配置:表示没有开组提交
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
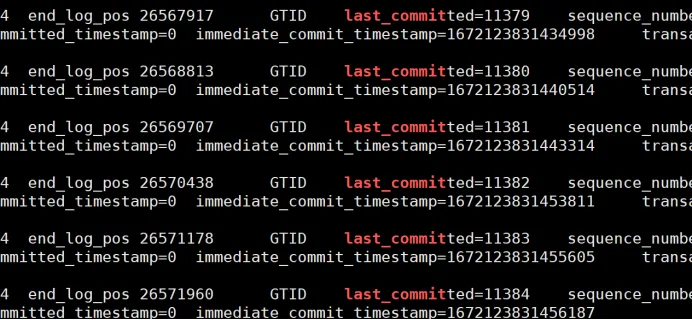
进一步验证,看其binlog,发现果然last_committed都不一样,表示不能并行
![]()
5.4 主库设置参数,再次解析其binlog
将binlog_transaction_dependency_tracking改为WRITESET模式
greatsql> show variables like '%transaction%';
+----------------------------------------------------------+-----------------+
| Variable_name | Value |
+----------------------------------------------------------+-----------------+
| binlog_direct_non_transactional_updates | OFF |
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
| kill_idle_transaction | 300 |
| performance_schema_events_transactions_history_long_size | 10000 |
| performance_schema_events_transactions_history_size | 10 |
| replica_transaction_retries | 10 |
| session_track_transaction_info | OFF |
| slave_transaction_retries | 10 |
| transaction_alloc_block_size | 8192 |
| transaction_allow_batching | OFF |
| transaction_isolation | REPEATABLE-READ |
| transaction_prealloc_size | 4096 |
| transaction_read_only | OFF |
| transaction_write_set_extraction | XXHASH64 |
+----------------------------------------------------------+-----------------+
17 rows in set (0.00 sec)
再次查看其binlog,看到有很多都可以并行回放
![]()
5.5 优化完成
即使主库在大批量的写入,但延迟正在慢慢缩减,追上只是时间问题,今天就是0了
![]()
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
![image]()
社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。