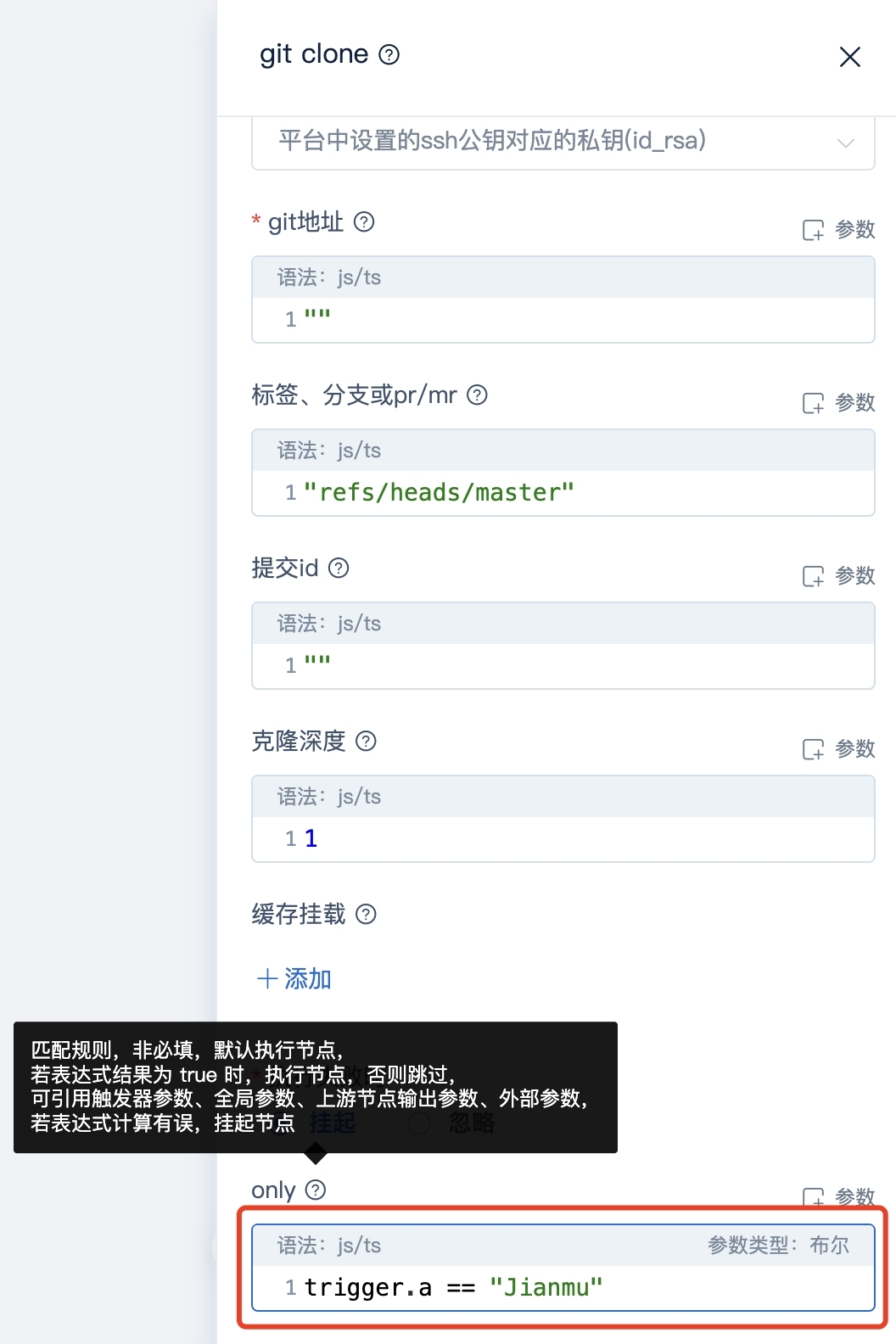
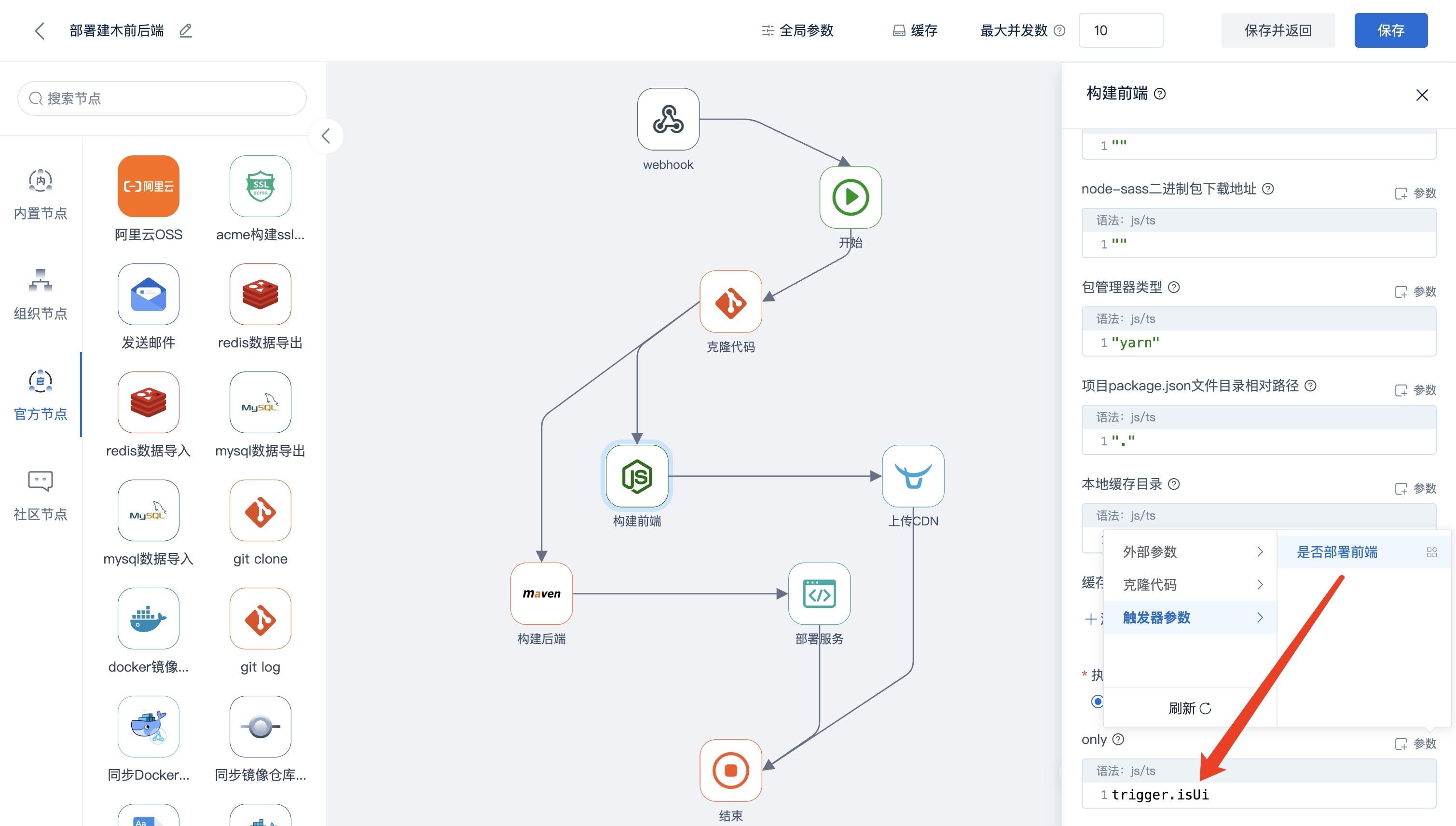
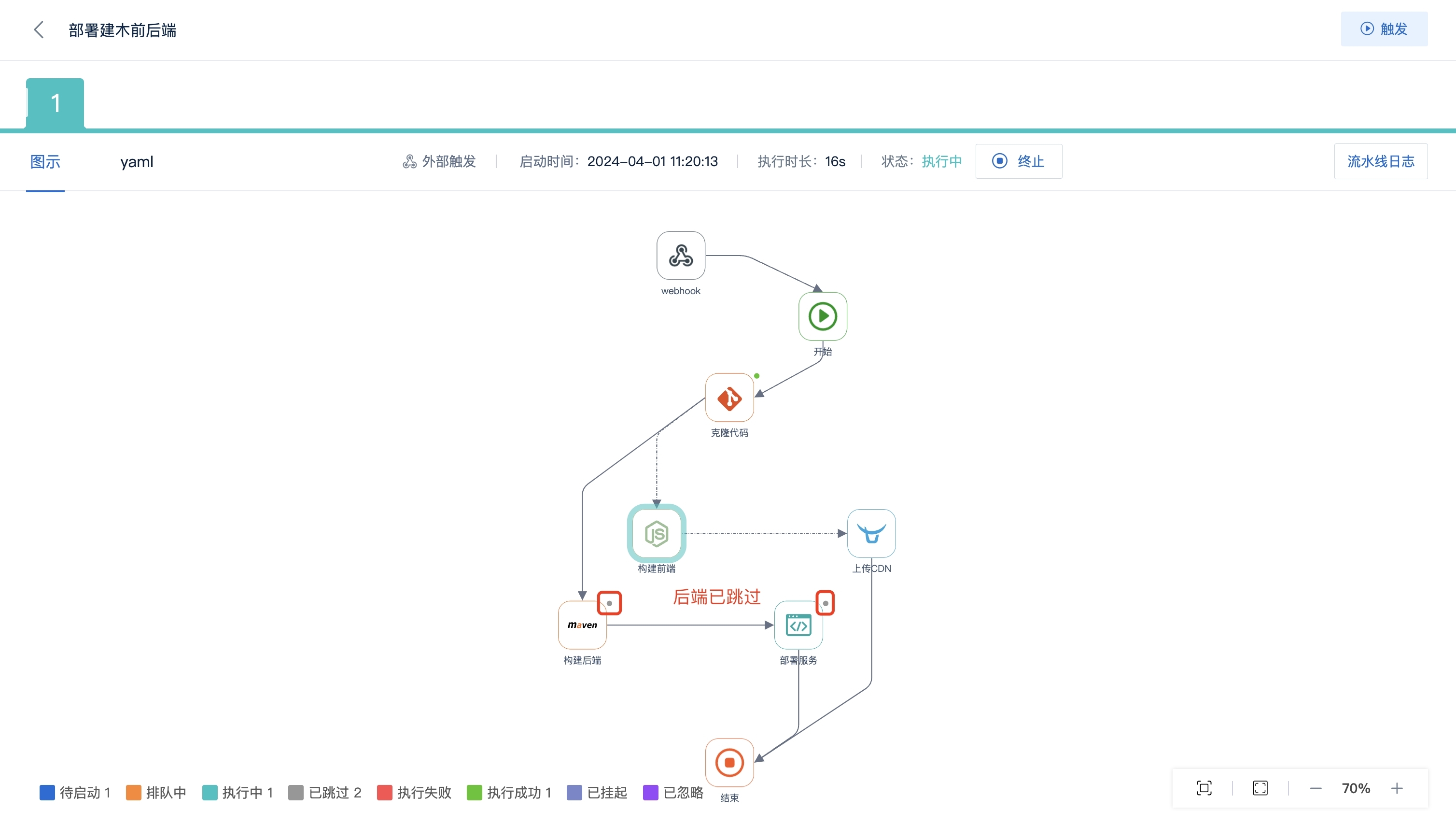
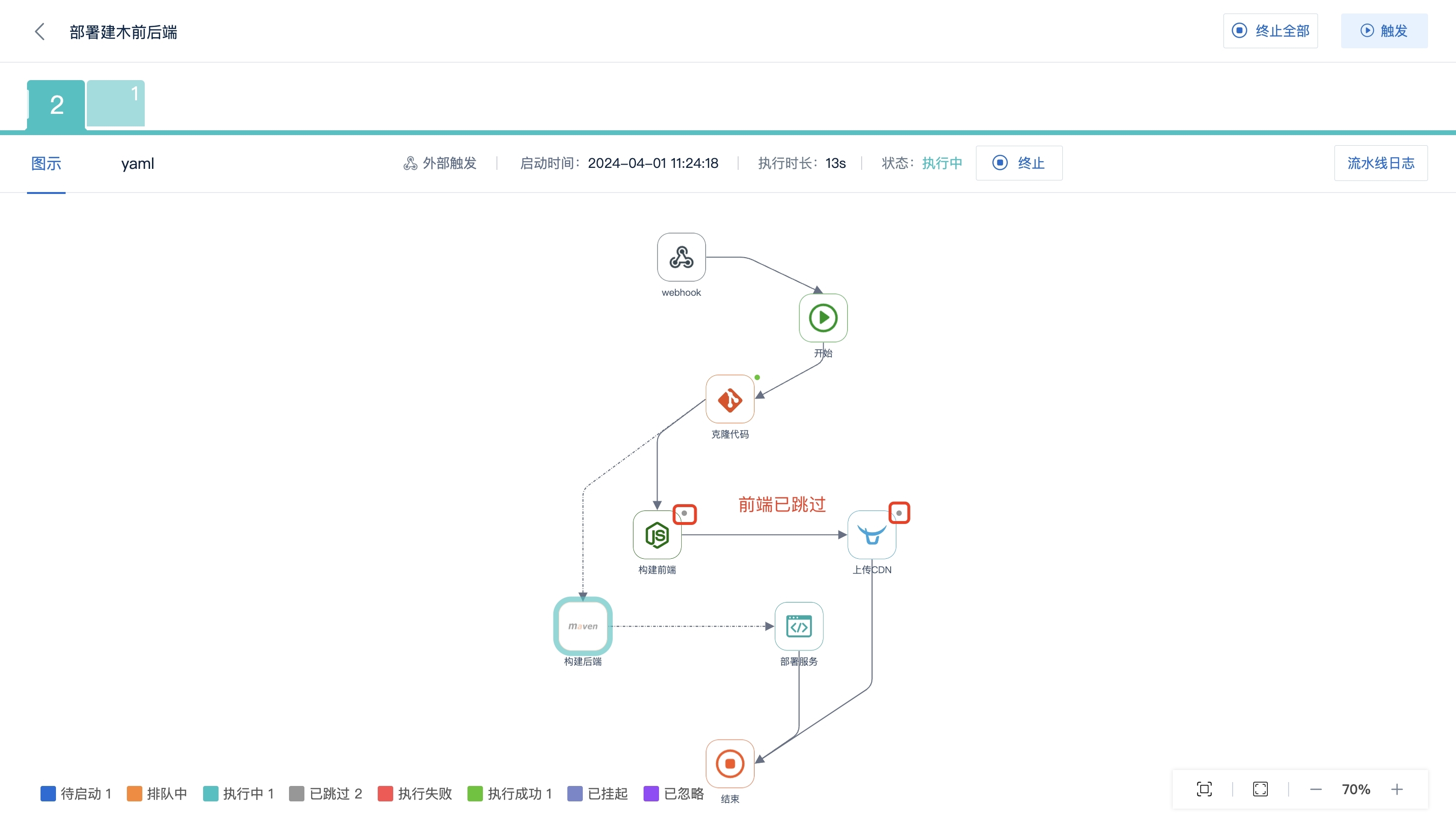

AutoMQ 如何实现分区持续重平衡?
01 引言 在一个线上 Kafka 集群中,流量的波动、Topic 的创建和删除、Broker 的消亡和启动都随时可能发生,而这些变化可能导致流量在集群各个节点间分布不均,从而导致资源浪费、影响业务稳定。此时则需要主动将 Topic 的不同分区在各个节点间移动,以达到平衡流量和数据的目的。 当前,Apache Kafka 仅提供了分区迁移工具,但具体的迁移计划则需要运维人员自行决定,而对于动辄成百上千个节点规模的 Kafka 集群来说,人为监控集群状态并制定一个完善的分区迁移计划几乎是不可能完成的任务,为此,社区也有诸如 Cruise Control for Apache Kafka这类第三方外置插件用于辅助生成迁移计划。但由于 Apache Kafka 的重平衡过程中涉及到大量变量的决策(副本分布、Leader 流量分布、节点资源利用率等等),以及重平衡过程中由于数据同步带来的资源抢占和小时甚至天级的耗时,现有解决方案复杂度较高、决策时效性较低,在实际执行重平衡策略时,还需依赖运维人员的审查和持续监控,无法真正解决 Apache Kafka 数据重平衡带来的问题。 02 AutoMQ...