
Docker容器编排技术解析与实践
本文全面探索了容器编排技术的核心概念、工具和高级应用,包括Docker Compose、Kubernetes等主要平台及其高级功能如网络和存储管理、监控、安全等。此外,文章还探讨了这些技术在实际应用中的案例,提供了对未来趋势的洞见。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人

一、容器编排介绍
容器编排是现代云原生应用管理的核心,它涉及在大规模的环境中自动化部署、管理、扩展和网络配置容器。随着微服务架构的兴起和应用的复杂性增加,容器编排成为了实现高效、可靠和动态服务管理的关键技术。
容器编排的概念和重要性
容器编排的概念源自于需要在大量的物理或虚拟机上有效管理成百上千个容器的需求。容器本身虽然轻量级且快速,但在复杂的生产环境中,手动管理这些容器的部署和生命周期是不切实际的。容器编排通过自动化这些过程,提供了如下几个关键优势:
- 高效的资源利用:通过智能调度,编排工具能够确保容器在最合适的主机上运行,优化资源的使用。
- 快速扩展和恢复:应对突然的流量峰值或服务故障,容器编排能够快速扩展或重新部署服务。
- 自动化和一致性:编排工具保证了部署的一致性,减少了人为错误,使得部署过程更加自动化和可重复。
- 服务发现和负载均衡:容器之间的网络配置和通信通过编排工具自动管理,提高了整体的应用性能。
容器编排的发展趋势
近年来,随着技术的快速发展,容器编排已经从最初的单一服务自动化,发展为支持复杂应用的全面解决方案。例如,Kubernetes 不仅支持基础的部署和扩展,还提供了服务网格(如Istio),以支持微服务之间复杂的通信和安全需求。此外,GitOps的兴起,将Git仓库作为应用部署的真理来源,使得容器编排更加透明和易于管理。
容器编排的实际应用案例
在实际应用中,容器编排已经成为许多成功项目的基石。例如,Netflix的容器化平台 Spinnaker,利用容器编排技术支持了他们庞大的微服务架构,实现了快速的服务部署和高效的资源管理。在金融领域,Goldman Sachs 通过Kubernetes管理他们的交易系统,不仅提高了系统的稳定性,还加快了新功能的上线速度。
二、容器编排工具概览
在容器编排领域,有几个关键的工具和平台已经成为行业的标准。这些工具不仅提供了基础的容器管理功能,还引入了高级特性,如自动扩展、服务发现和自我修复能力。我们将探讨其中最重要的几个工具:Docker Compose、Kubernetes 和 Docker Swarm,了解它们的基本概念、特性和适用场景。
Docker Compose
Docker Compose 是一个用于定义和运行多容器Docker应用程序的工具。通过Compose,用户可以使用YAML文件来配置应用服务。然后,只需一个简单的命令,就可以创建并启动所有服务。Docker Compose 特别适合于开发环境和小型项目,因为它简化了多容器应用的构建和管理过程。
特点
- 易于使用:通过一个YAML文件管理整个应用的服务。
- 开发友好:适合在开发环境中快速部署和测试。
- 轻量级:不需要额外的基础设施或复杂的配置。
应用案例
例如,一个开发团队可以使用Docker Compose来搭建他们的本地开发环境,包括应用服务器、数据库和缓存服务。这使得整个团队能够在一个一致的环境中工作,减少了“在我的机器上运行正常”的问题。
Kubernetes
 Kubernetes(K8s)是目前最流行的开源容器编排系统,用于自动部署、扩展和管理容器化应用程序。由Google开发,并由Cloud Native Computing Foundation(CNCF)维护。
Kubernetes(K8s)是目前最流行的开源容器编排系统,用于自动部署、扩展和管理容器化应用程序。由Google开发,并由Cloud Native Computing Foundation(CNCF)维护。
特点
- 高度可扩展:可以管理大规模的容器部署。
- 强大的生态系统:支持广泛的工作负载类型、服务发现和负载均衡。
- 自动化运维:包括自动扩展、自我修复和滚动更新。
应用案例
在全球范围内,许多大型企业(如Spotify、华为和IBM)都使用Kubernetes来支持他们的生产环境。Kubernetes不仅提高了这些公司的运维效率,还为他们提供了无与伦比的系统稳定性和可扩展性。
Docker Swarm
Docker Swarm 是 Docker 的原生集群管理工具。它使用Docker API,因此已经熟悉Docker的用户会发现Swarm易于上手和使用。
特点
- Docker原生:紧密集成在Docker生态系统中。
- 简单易用:对于小型到中型项目而言,Swarm提供了足够的功能。
- 轻量级:不需要额外的安装,只需要Docker。
应用案例
对于那些已经在使用Docker并且需要更简单的解决方案来扩展他们的应用到多个主机的团队,Docker Swarm提供了一个理想的选择。例如,一个中小型企业可以使用Swarm来管理他们的几个服务,而无需投入更多资源来学习和部署Kubernetes。
三、Docker Compose全解
Docker Compose 是一个用于定义和运行多容器Docker应用程序的工具。它允许用户使用YAML文件来声明式地定义服务、网络和卷,从而在Docker环境中轻松构建、测试和部署应用程序。
Docker Compose 的基本概念
1. 服务(Service)
- 定义:服务是Docker Compose中的核心概念,它代表一个应用的组成部分(例如,数据库、前端、后端)。
- 特性:每个服务都可以定义其容器镜像、端口映射、卷挂载和依赖关系。
2. 网络(Network)
- 定义:Compose允许定义网络来实现容器间的通信。
- 特性:支持不同的网络类型,如桥接或覆盖网络,确保容器之间的隔离和安全通信。
3. 卷(Volume)
- 定义:卷用于数据持久化和共享。
- 特性:可以被多个容器共享,用于存储数据库文件、配置文件等。
Docker Compose 文件结构
YAML文件是Docker Compose的核心,其中定义了所有相关的服务、网络和卷配置。
示例
version: "3.9" # 使用的Compose文件版本 services: web: image: "my-web-app:latest" # 定义使用的镜像 ports: - "5000:5000" # 端口映射 networks: - webnet # 网络配置 redis: image: "redis:alpine" networks: - webnet networks: webnet: 高级功能
1. 服务扩展(Scale)
- 描述:自动增加或减少服务的实例数量。
- 用途:在高流量时期动态扩展服务实例,以应对负载。
2. 健康检查(Healthcheck)
- 描述:监控服务的运行状态。
- 用途:确保服务正常运行,对故障实例进行自动重启。
3. 环境变量(Environment Variables)
- 描述:设置和管理服务运行时的环境变量。
- 用途:配置数据库连接、API密钥等敏感信息。
Docker Compose 在实际应用中的应用
在微服务架构中,Docker Compose被广泛用于本地开发和测试环境。它允许开发人员在本地复现生产环境,确保应用的每个组件都能在一个隔离且一致的环境中运行。
应用示例
假设一个团队正在开发一个包含前端、后端和数据库的Web应用。使用Docker Compose,他们可以定义三个服务:一个用于前端的Node.js应用,一个用于后端的Python API,以及一个PostgreSQL数据库。每个服务都可以在其专用容器中运行,并且通过定义的网络相互通信。这样,整个团队可以在相同的配置下工作,减少环境差异带来的问题。
总结
Docker Compose提供了一个简单而强大的工具,用于管理和编排多容器应用。它的易用性和灵活性使其成为开发和小规模部署环境的理想选择。通过深入了解Compose的各种功能和最佳实践,开发团队可以显著提升其开发效率和应用质量。
四、Kubernetes全解
Kubernetes,通常称为K8s,是当前最流行的开源容器编排平台。它为自动化部署、扩展和管理容器化应用程序提供了一个健壮的框架。
Kubernetes的核心概念
1. Pod
- 定义:Pod是Kubernetes中最小的可部署单元,通常包含一个或多个容器。
- 特点:Pod中的容器共享存储、网络和运行配置。
2. Service
- 定义:Service是定义如何访问一组具有相同功能的Pod的抽象方式。
- 特点:确保网络访问的稳定性和负载均衡。
3. Deployment
- 定义:Deployment为Pod和ReplicaSet(Pod的集合)提供声明式的更新能力。
- 特点:支持滚动更新和版本回滚。
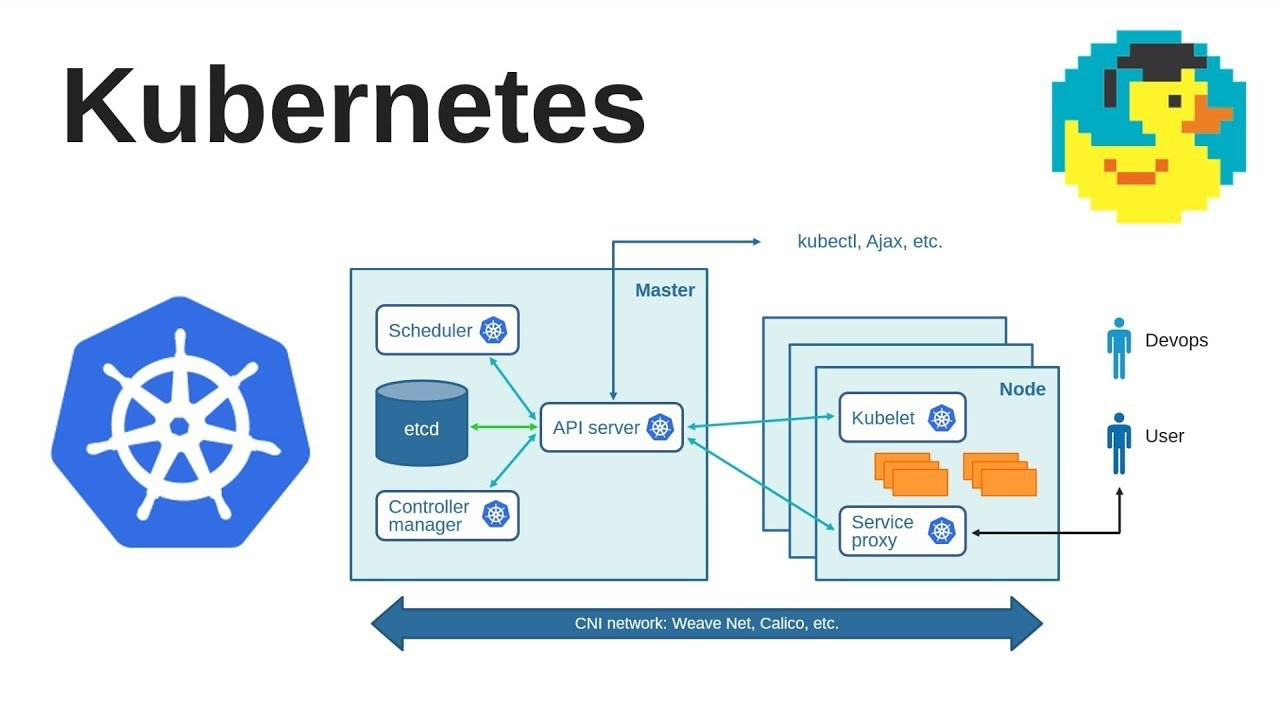
Kubernetes的架构组件
1. 控制平面(Control Plane)
- 功能:管理集群状态,如调度、响应Pod生命周期事件等。
- 组件:包括API服务器、调度器、控制器管理器等。
2. 节点(Node)
- 功能:运行应用程序容器。
- 组件:包括Kubelet、Kube-proxy和容器运行时。
3. 存储(Storage)
- 功能:提供持久存储解决方案。
- 组件:支持多种存储选项,如本地存储、公有云存储等。
Kubernetes的高级特性
1. 自动扩缩容(Auto-Scaling)
- 描述:根据负载自动增加或减少Pod数量。
- 应用:保证应用在不同负载下的性能和成本效率。
2. 服务发现和负载均衡
- 描述:自动配置网络,使得服务能够互相发现和负载均衡。
- 应用:简化了微服务架构中服务间通信的复杂性。
3. 自动化部署和回滚
- 描述:通过声明式配置自动管理应用部署和回滚。
- 应用:提高部署的可靠性和频率,降低部署失败的风险。
Kubernetes在实际应用中的应用
Kubernetes已经成为微服务架构的事实标准。它能够支持从小型初创企业到大型企业的不同规模应用。
应用示例
假设一个在线零售平台,需要管理其多个微服务(如订单处理、支付处理、用户认证等)。使用Kubernetes,这些服务可以被部署为独立的Pod或Deployment,并通过Service进行互联。随着用户数量的增长,Kubernetes可以自动扩展服务,确保应用的可靠性和性能。
Kubernetes的未来趋势
Kubernetes不断发展,正在融合更多的云原生技术,如服务网格、Serverless架构等。未来,Kubernetes可能会进一步简化应用部署和管理的复杂性,使得它不仅仅是容器编排工具,而是整个云原生应用生态系统的核心。
五、高级容器编排技术
在现代的容器化生态系统中,随着应用和部署的复杂性增加,高级容器编排技术成为了不可或缺的组成部分。这些技术不仅提升了容器管理的效率和灵活性,还确保了系统的可靠性和安全性。
网络管理
容器网络管理是确保容器间正确、安全通信的重要部分。在复杂的容器化环境中,网络管理包括但不限于以下方面:
1. 网络模型
- 概念:容器网络模型定义了容器如何在网络中交互。
- 技术:如CNI(Container Network Interface)、Flannel、Calico。
2. 服务网格
- 概念:服务网格管理微服务间的通信,提供负载均衡、服务发现等功能。
- 技术:如Istio、Linkerd。
- 应用:服务网格使得微服务间的复杂通信变得透明和可控。
存储管理
在容器编排中,存储管理保证了数据的持久性和一致性。高级存储管理技术包括:
1. 持久化存储
- 概念:为容器提供持久化的存储解决方案。
- 技术:如Persistent Volumes (PV) 和 Persistent Volume Claims (PVC) 在Kubernetes中的应用。
2. 存储编排
- 概念:自动管理存储资源的分配和生命周期。
- 技术:如Rook、Portworx。
容器监控和日志管理
为了确保容器化环境的健康和性能,监控和日志管理是必不可少的。
1. 监控
- 概念:实时监控容器和集群的性能指标。
- 工具:如Prometheus、Grafana。
2. 日志管理
- 概念:集中收集、存储和分析容器日志。
- 工具:如ELK Stack(Elasticsearch, Logstash, Kibana)、Fluentd。
容器安全性
容器安全性是容器编排中一个重要且日益受到关注的领域,包括:
1. 容器安全扫描
- 概念:检测容器镜像中的安全漏洞。
- 工具:如Clair、Trivy。
2. 运行时安全
- 概念:保护运行中容器免受攻击。
- 工具:如Falco、Sysdig。
自动化和策略驱动管理
容器编排的自动化和策略驱动管理提供了更高层次的控制和效率。
1. 自动化部署
- 技术:如GitOps,使用Git仓库作为唯一的真理来源,实现自动化的应用部署。
2. 策略驱动管理
- 技术:如OPA (Open Policy Agent),为云原生环境提供统一的策略执行。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
如有帮助,请多关注 TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

TorchAcc:基于 TorchXLA 的分布式训练框架
本文旨在探讨阿里云 TorchAcc,这是一个基于 PyTorch/XLA 的大模型分布式训练框架。 过去十年 AI 领域的显著进步,关键在于训练技术的革新和模型规模的快速攀升。尽管大模型展现了堪比人类的理解力,但其训练却对算力提出了极高的要求。唯有配备充足的计算资源,方能在海量数据上有效训练大模型,确保其在有限时间内实现优质收敛。 图片来源于 GTC 2024大会China AI Day 线上专场的演讲《TorchAcc:基于TorchXLA的分布式训练框架》 根据上图左侧图表显示,过去五年,大模型规模的增长态势尤为突出,平均每两年大小翻 15 倍;而对于 Transformer 为代表的语言模型以及多模态模型而言,其规模膨胀速度更加惊人,每隔两年以 750 倍剧增。对比之下,右侧图表揭示了一个明显的矛盾点:不论是单个 GPU 的计算能力抑或是 GPU 显存容量的发展速度,都无法跟上模型规模如此急剧的扩张步伐。这一现实状况直接催生了对分布式训练的迫切需求。分布式训练不再局限于以往单纯的数据并行模式,而是在此基础上,更加重视并采取模型并行策略,以弥补单个计算单元算力与存储提升速度相对于...
- 下一篇
国产数据库,是研发们的“离职创业咖啡店”吗?
上周,《国产数据库圈,为啥那么多水货?》的讨论热度甚高,今天我们总结了一下直播嘉宾李令辉的看法,认同的不妨点个赞吧~ 分享嘉宾: 李令辉 云原生数据库 ClapDB 创始人,前乘法云 CTO,美洽 CTO,滴滴出行首席架构师。 目前致力于基于云上的基础设施新范式,提供新时代的分析型数据服务。 ClapDB 是一款重头开始基于云原生架构设计和实现的数据库,充分利用现代云原生技术优势。采用 C++ 开发,期望给予更高的性能,让您可以在任意规模的数据下轻松快速得到分析的结果。 01 数据库创业,不能只为跟风 大部分的数据厂商,往往是之前在互联网大厂或者其他大厂做数据库研发的同行,可能年纪到了,遇到了职业天花板或晋升瓶颈,或者有一些想法在原来的工作单位无法施展,就拿投资去做一个可能和原厂差不多,或者有一些改进的项目。 因为大家的初衷和借鉴的产品都很雷同,所以做出来的数据库也都大差不差。现在,国内挂名做数据库的企业,可能有上千家。但在我看来,可能就三到四种: 第一种是基于 MySQL 魔改的,第二种是基于 PostgreSQL 魔改的,第三种基于 PostgreSQL 的 Greenplum ...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- CentOS7编译安装Gcc9.2.0,解决mysql等软件编译问题
- CentOS8安装MyCat,轻松搞定数据库的读写分离、垂直分库、水平分库
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- CentOS7安装Docker,走上虚拟化容器引擎之路
- Linux系统CentOS6、CentOS7手动修改IP地址
- CentOS6,CentOS7官方镜像安装Oracle11G
- 设置Eclipse缩进为4个空格,增强代码规范
- Docker安装Oracle12C,快速搭建Oracle学习环境
- Windows10,CentOS7,CentOS8安装MongoDB4.0.16
- SpringBoot2初体验,简单认识spring boot2并且搭建基础工程
 微信收款码
微信收款码 支付宝收款码
支付宝收款码