streampark+flink一键整库或多表同步mysql到doris实战,此应用一旦推广起来,那么数据实时异构时,不仅可以减少对数据库的查询压力,还可以减少数据同步时的至少50%的成本,还可以减少30%的存储成本;
streampark搭建
二进制包编译构建
编译构建二进制可执行包,使用自己构建的二进制包构建Docker镜像,需要准备一台Linux的服务或者是虚拟机,可以正常上网即可,在该台机子上需要事先安装Git(拉取源码文件),Maven和java环境(JDK1.8),我采用的是是上传的源码包:incubator-streampark-2.1.0.tar.gz,然后解压源码包:
tar -zxvf incubator-streampark-2.1.0.tar.gz
解压到服务器上,然后进入到解压路径里面
执行:
到此streampark已经搭建完成,可以在web页面验证应用是否可以访问,
登录账号;
是否能创建
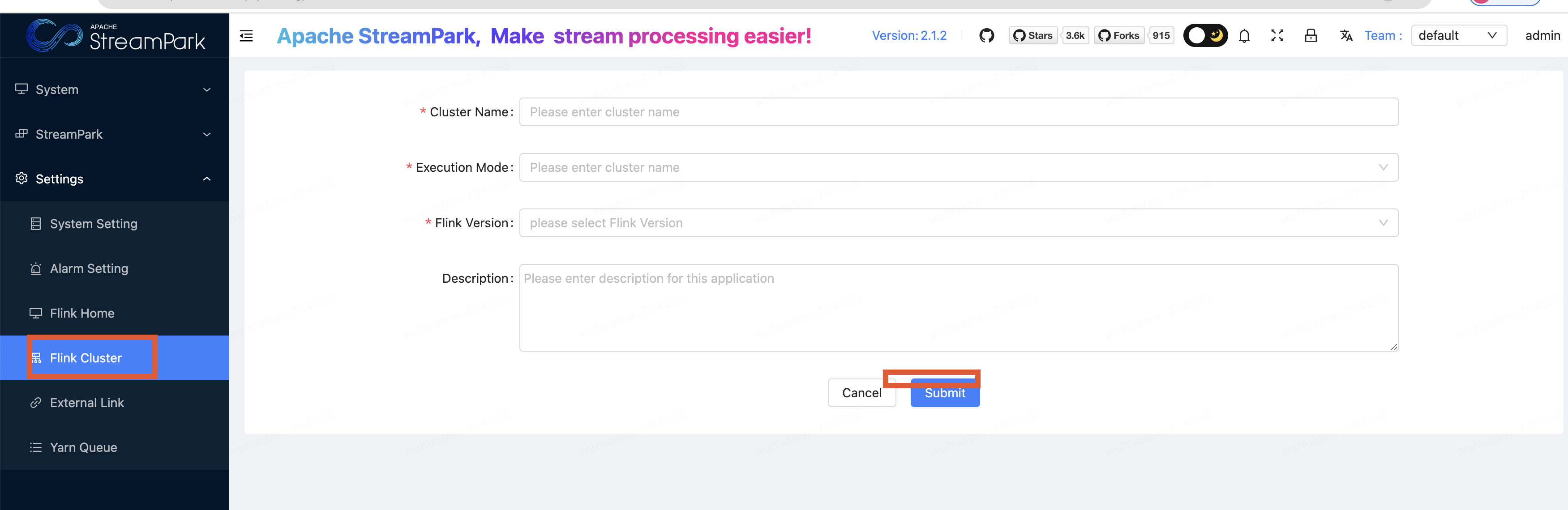
flink 搭建
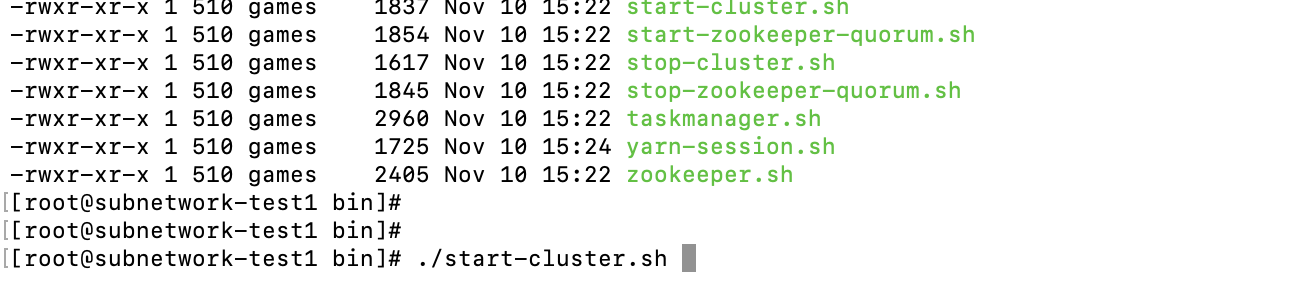
执行:
到此flink特搭建完毕;
web是否可以访问:
上述两个应用搭建成功之后,一定要检查对应的应用的涉及到的端口网络权限是否都开启,如果没有开启的话,那么后续执行的任务的时候,不会成功;
创建同步mysql到doris任务:
此任务是mysql表数据自动同步到doris的任务,首先需要mysql和doris数据库的相关配置都知道,其次是配置任务中的相关jar都有,在同步过程中,doris中对应的mysql表ddl是会自动创建的,不需要人工介入,可以节约同步几十上百张表时人工建表的字段映射的大量时间;
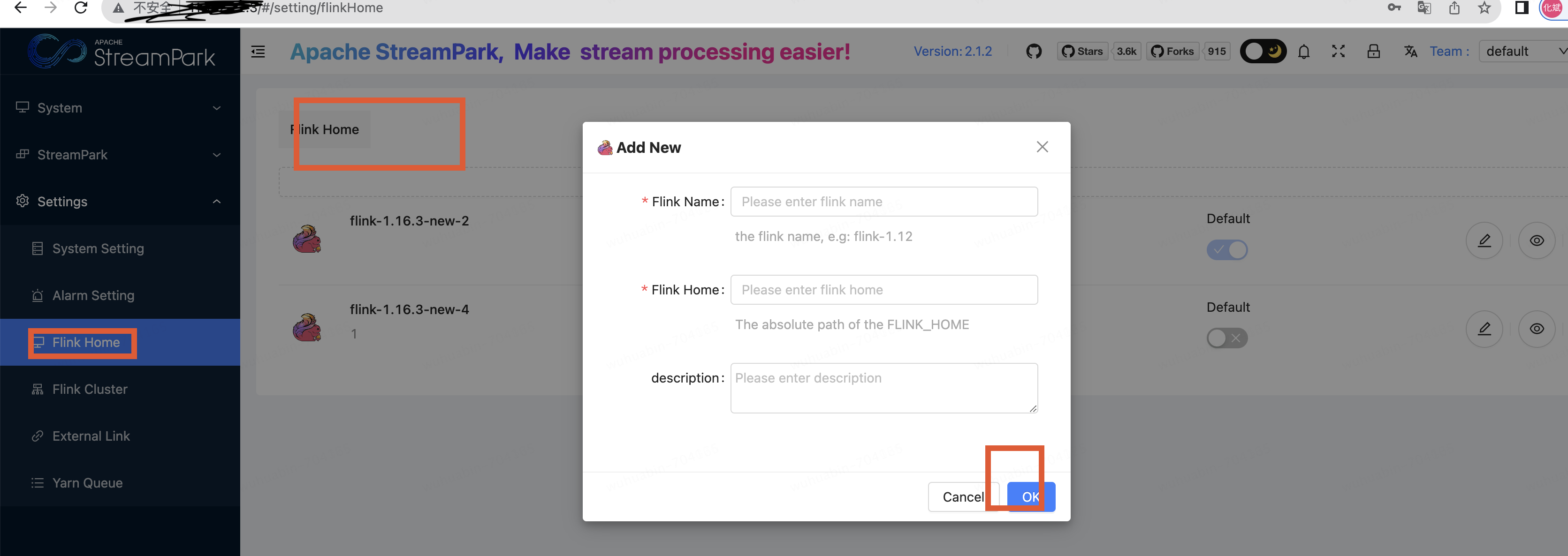
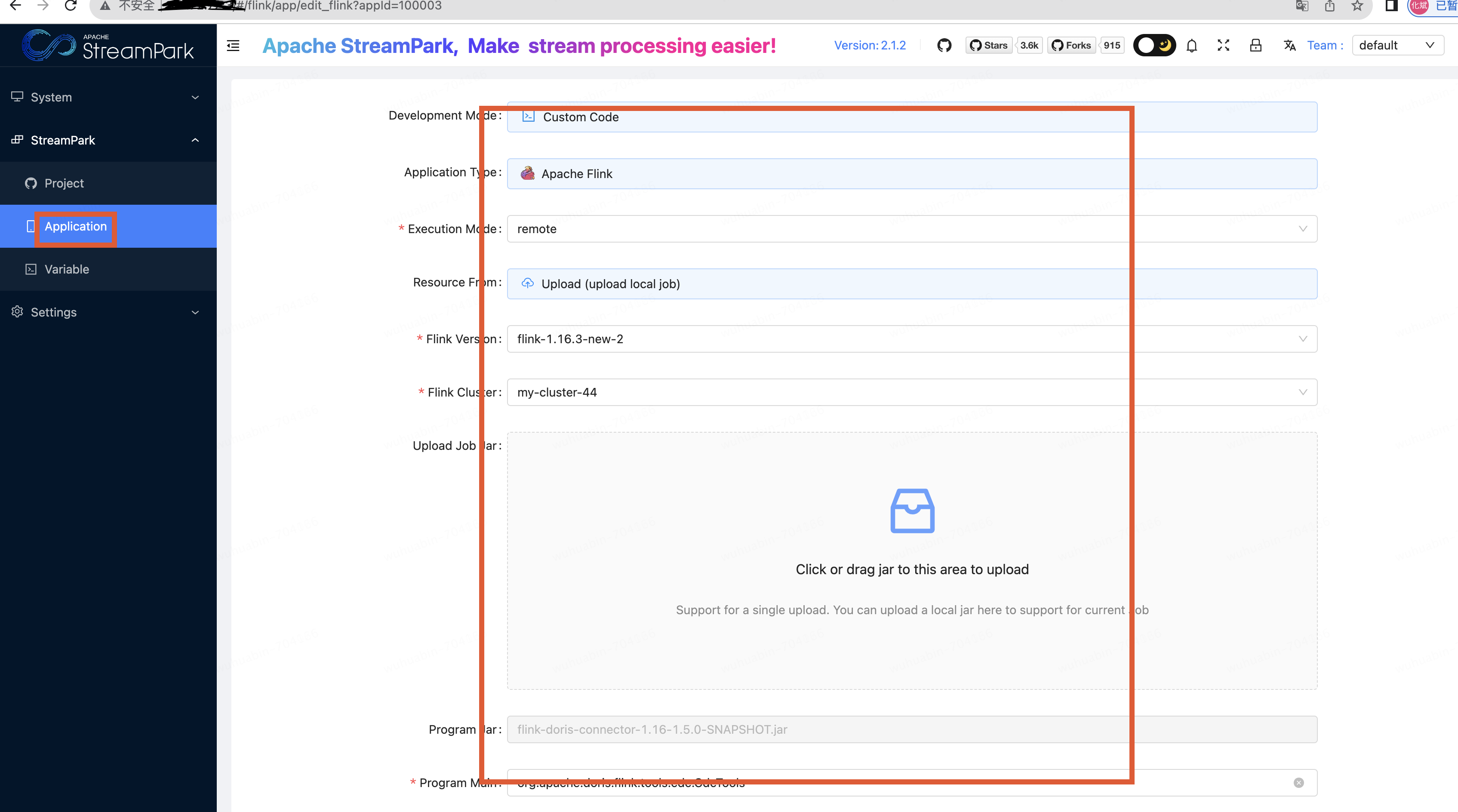
streampark中创建任务
创建完任务,执行启动
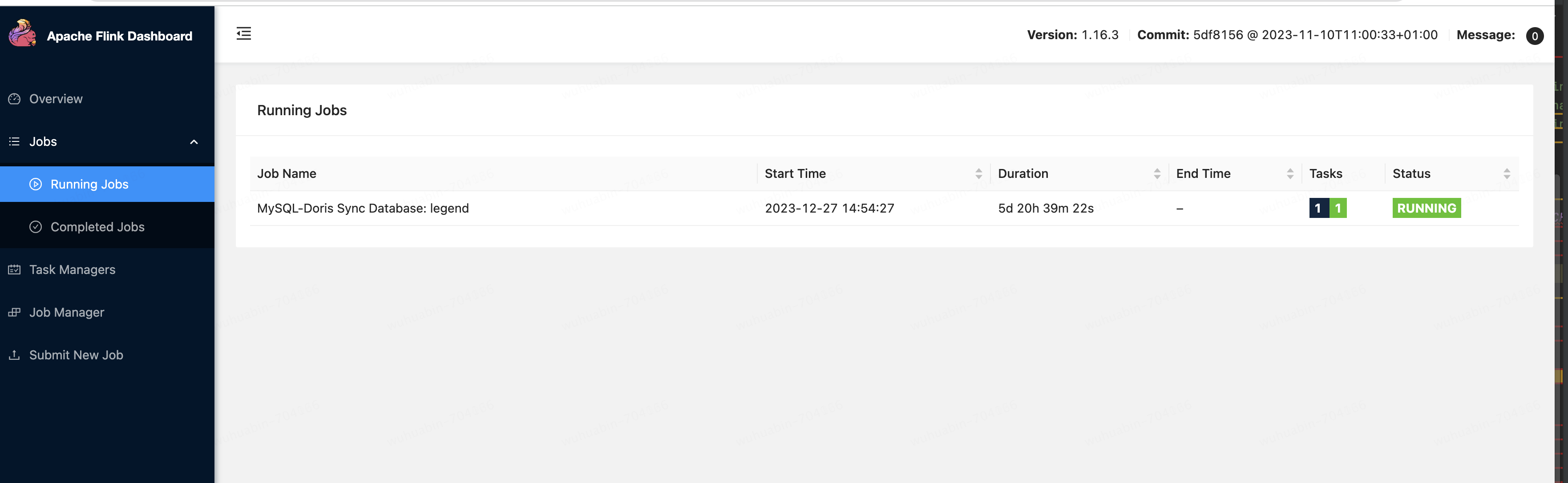
服务中指令启动同步任务
在flink目录执行此脚本,
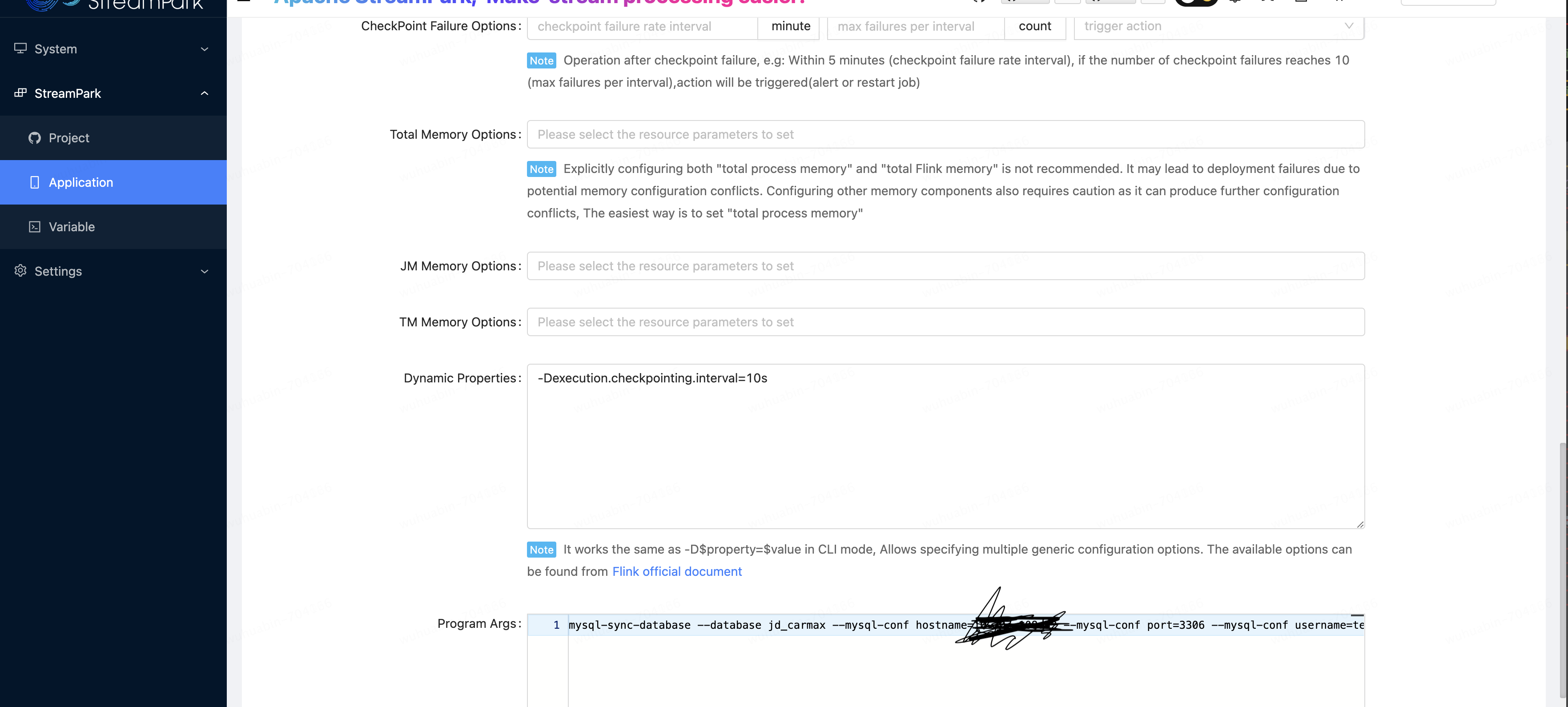
bin/flink run -Dexecution.checkpointing.interval=10s -Dparallelism.default=1 -c org.apache.doris.flink.tools.cdc.CdcTools /opt/streampark_workspace/workspace/100003/streampark-flinkjob_wuhuabiun.jar mysql-sync-database --database jd_carmax --mysql-conf hostname= ..... --mysql-conf port=3306 --mysql-conf username=.... --mysql-conf password=... --mysql-conf database-name=jd_carmax --including-tables ".*" --sink-conf fenodes=....:2004 --sink-conf username=wuhuabin --sink-conf password=.... --sink-conf jdbc-url=jdbc:.... :2000 --sink-conf sink.label-prefix=label --table-conf replication_num=3
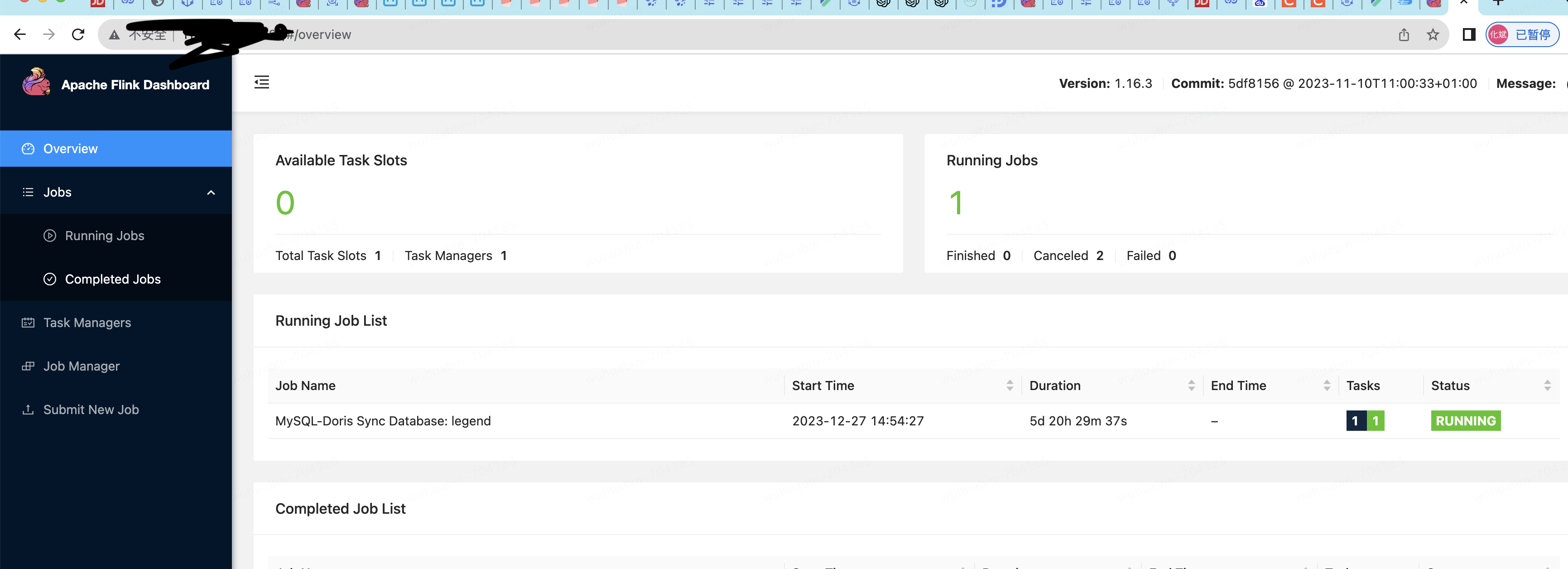
执行完之后,在flink ui中能看到对应的任务:
doris数据验证
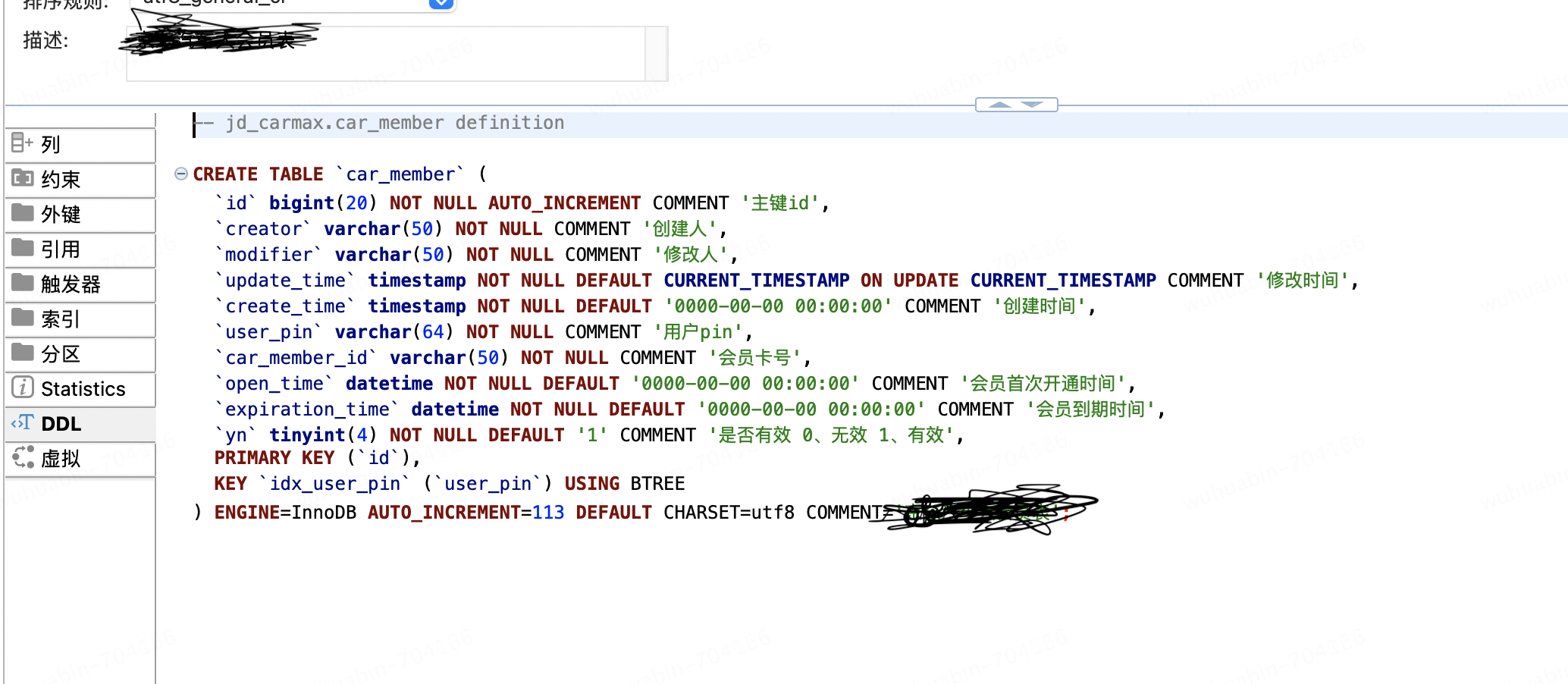
表ddl验证
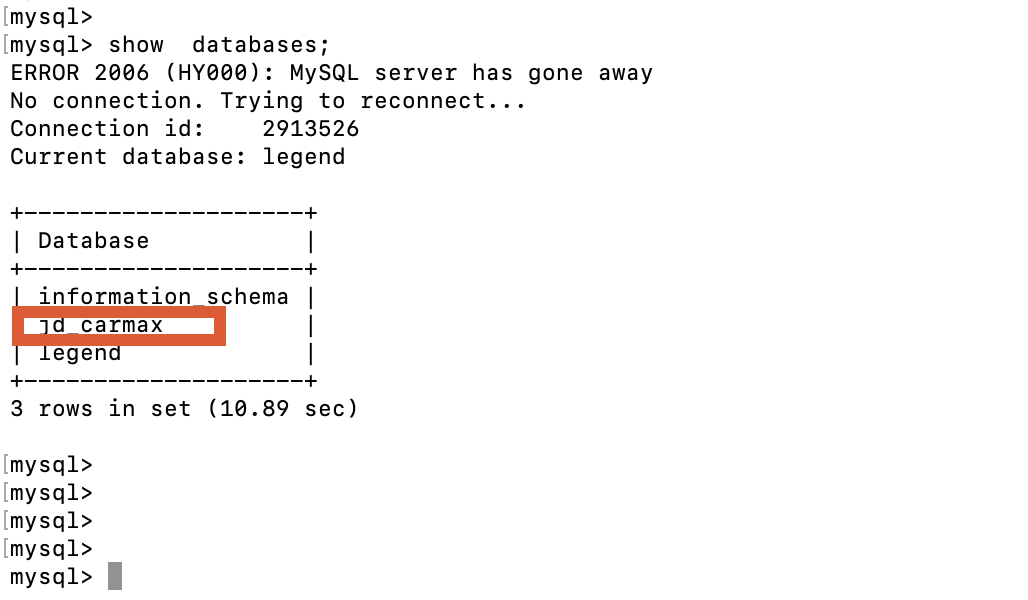
登录doris数据库;
mysql表的ddl:
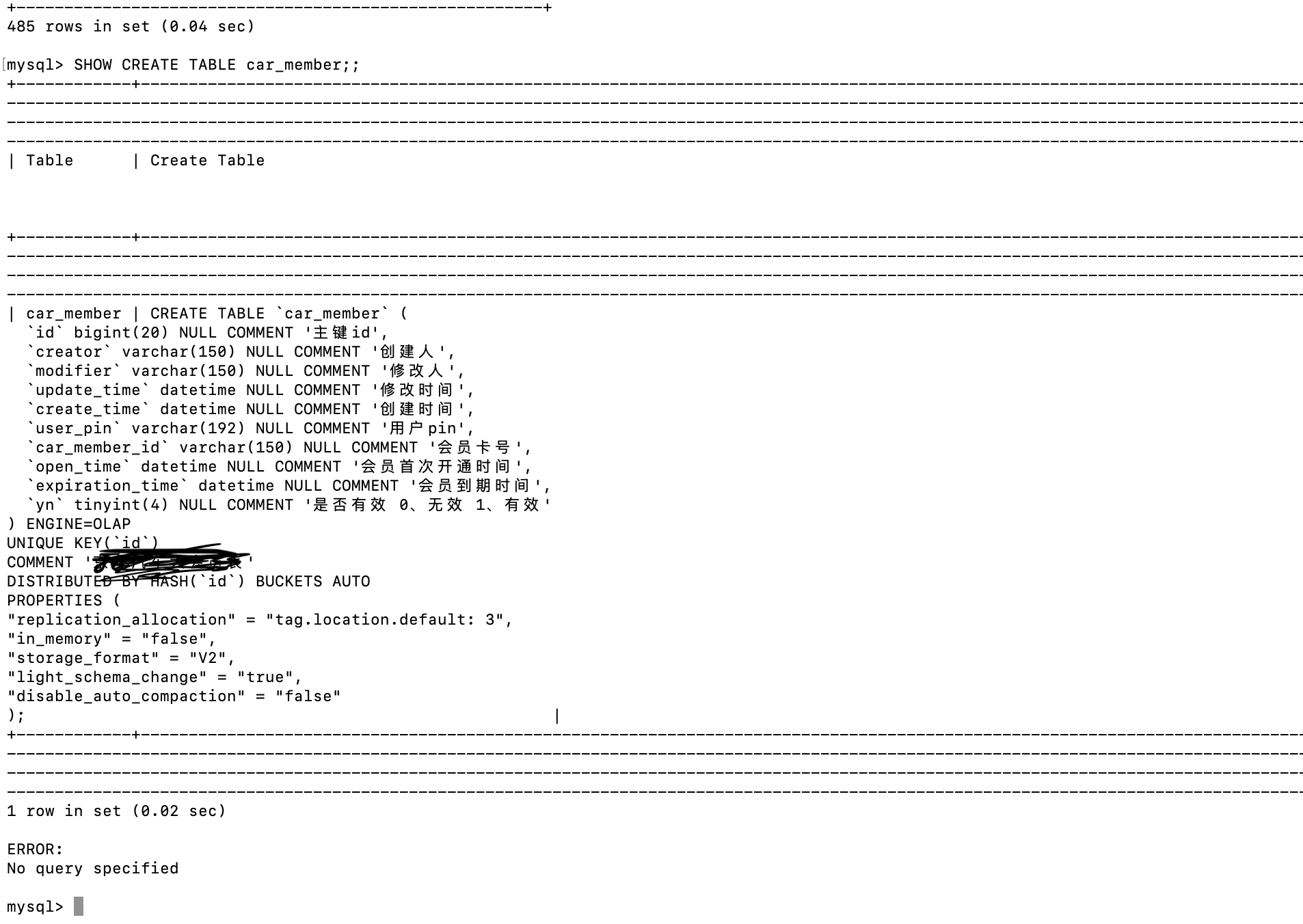
查询doris是否把表ddl都同步成功,
mysql表ddl和doris中的表ddl一致;
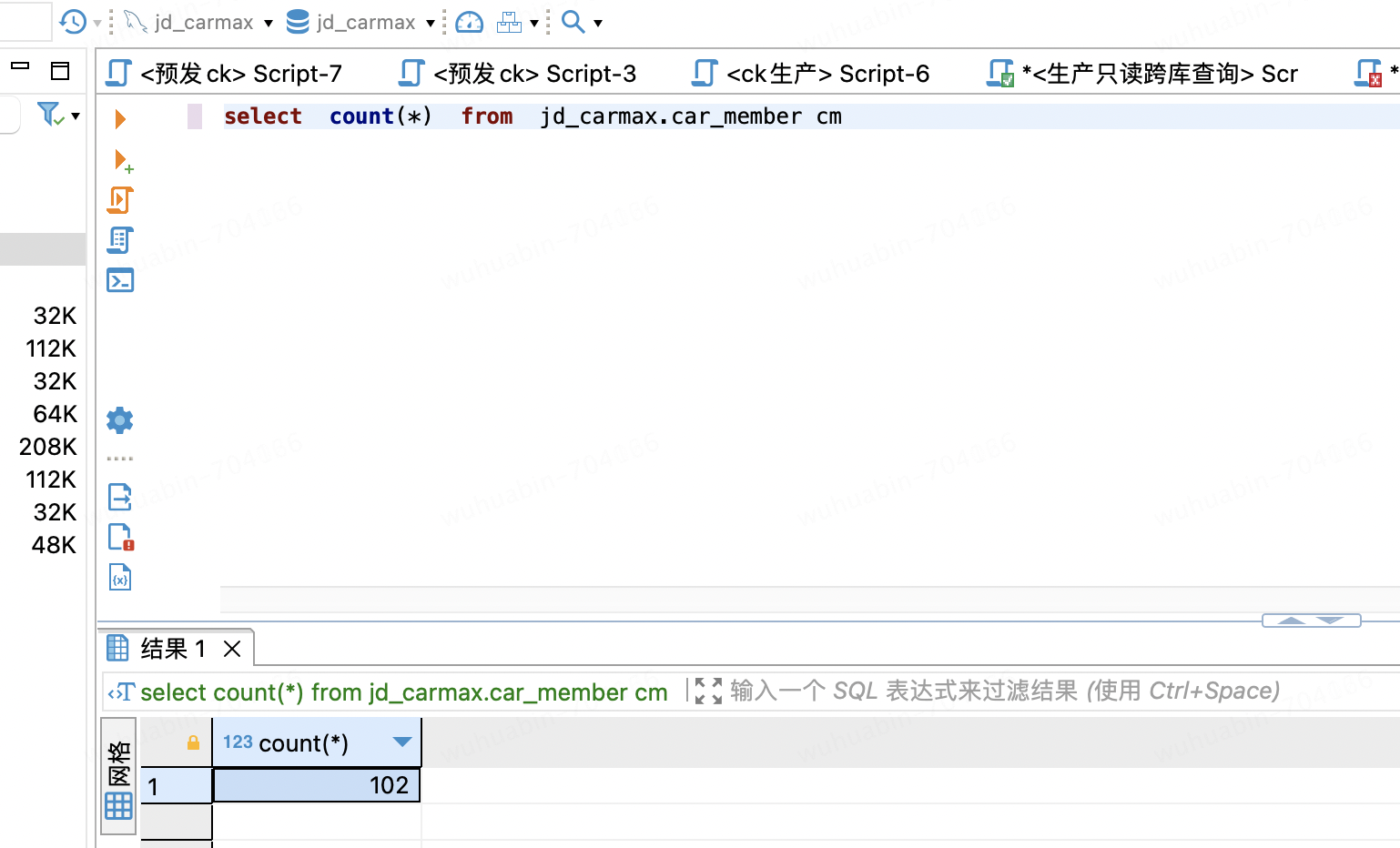
表数据量验证
doris表数据量
mysql表数据量:
至此,自运维mysql一键同步到doris的实战到此;
作者:京东零售 吴化斌
来源:京东云开发者社区 转载请注明来源