作者:彦鸿
引言
随着 Kuberentes 等云原生技术的飞速发展,带来了研发与运维模式的变革。企业软件架构由单体服务向分布式、微服务演进。随着业务发展,多语言、多框架、多协议的微服务在企业中越来越多,软件架构复杂度越来越高,如何快速通过可观测工具快速定位出问题对研发人员至关重要。为满足全场景、端到端的应用监控需求,应用实时监控服务 ARMS 推出应用监控 eBPF 版,通过 eBPF 技术完善整个应用监控体系。应用监控 eBPF 版提供无侵入、语言无关的可观测能力。
详细产品介绍: 多语言应用监控最优选,ARMS 应用监控 eBPF 版正式发布
使用 eBPF 来进行可观测性需要进行应用层协议解析,但云上微服务软件架构中的应用层协议往往比较复杂,这也给协议解析带来了不小的挑战。传统的协议解析方式存在 CPU、内存占用高,错误率高等问题,在应用监控 eBPF 版中,我们提出一种高效的协议解析方案,实现对应用层协议的高效解析。
eBPF 技术简介
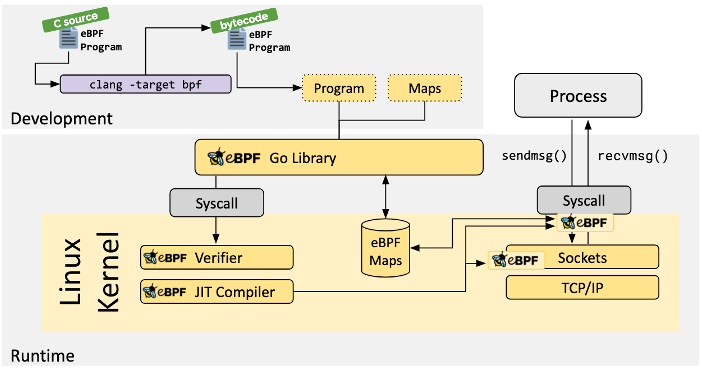
eBPF(扩展的 Berkeley 包过滤器)是一种强大的技术,允许开发人员在 Linux 内核中安全地运行预编译的程序,而不改变内核源码或加载外部模块 [ 1] 。这一独特的能力使得 eBPF 成为构建现代、灵活且高效的应用监控工具的理想选择。
![]()
图 2.1 eBPF 示意图
在可观测性方面,eBPF 优势尤为突出:
- 实时性: eBPF 能够实时捕获和分析数据,为开发者提供即时的性能反馈。
- 精确性: 通过精细的 hook 函数(hook points),eBPF 可以在系统的具体点进行监控,从而准确地收集所需数据。
- 灵活性: 开发者可以编写定制的 eBPF 程序来监控特定事件,使其能够适应各种复杂的监控需求。
- 低开销: eBPF 程序直接在内核空间运行,避免了传统监控工具中频繁的用户空间和内核空间之间的上下文切换。
- 安全性: eBPF 程序在执行前必须通过内核的严格检查,确保不会危及系统安全。
传统的协议解析方案
![]()
图 3.1 传统协议解析方案架构图
3.1 传统方案的解析流程
基于 eBPF 来做数据抓取和协议解析的传统方案主要分为:
其中数据采集主要在内核态,数据传递介于内核态和用户态,协议解析在用户态进行。具体的,数据采集的流程为 eBPF 使用 kprobe 或 tracepoint 方式,从内核中抓取到流量事件即 event,这些事件中有控制层面的事件如从 connect、close 等系统调用处采集到的事件。也有数据层面的事件,如从 read、write 等系统调用处采集到的事件。待数据采集到内核事件后,我们需要将数据从内核态传递至用户态去做进一步的处理。在 eBPF 中,我们采用 perf buffer(一种特殊 eBPF Map)来做数据传递。数据存放到整个 perf buffer 后,在用户态进行协议解析。
3.2 传统方案中存在的问题
传统的解析方案中 CPU、内存占用过高,在高流量场景下错误率较高,主要体现在以下三个方面:
- 高内存占用: 数据采集中无法筛选协议,导致大量无关数据占满 perf buffer,引发内存过高。
- 事件丢失风险: 高 QPS 导致 perf buffer 迅速填满,处理不及时会丢失事件,特别是控制层事件可能因数据层事件过多而丢失。
- 解析效率低: 需要遍历尝试所有支持协议才能找到正确的协议,导致大量无效解析,增加 CPU 负担。
实现高效协议解析的技术探索
4.1 高效的协议解析方案流程
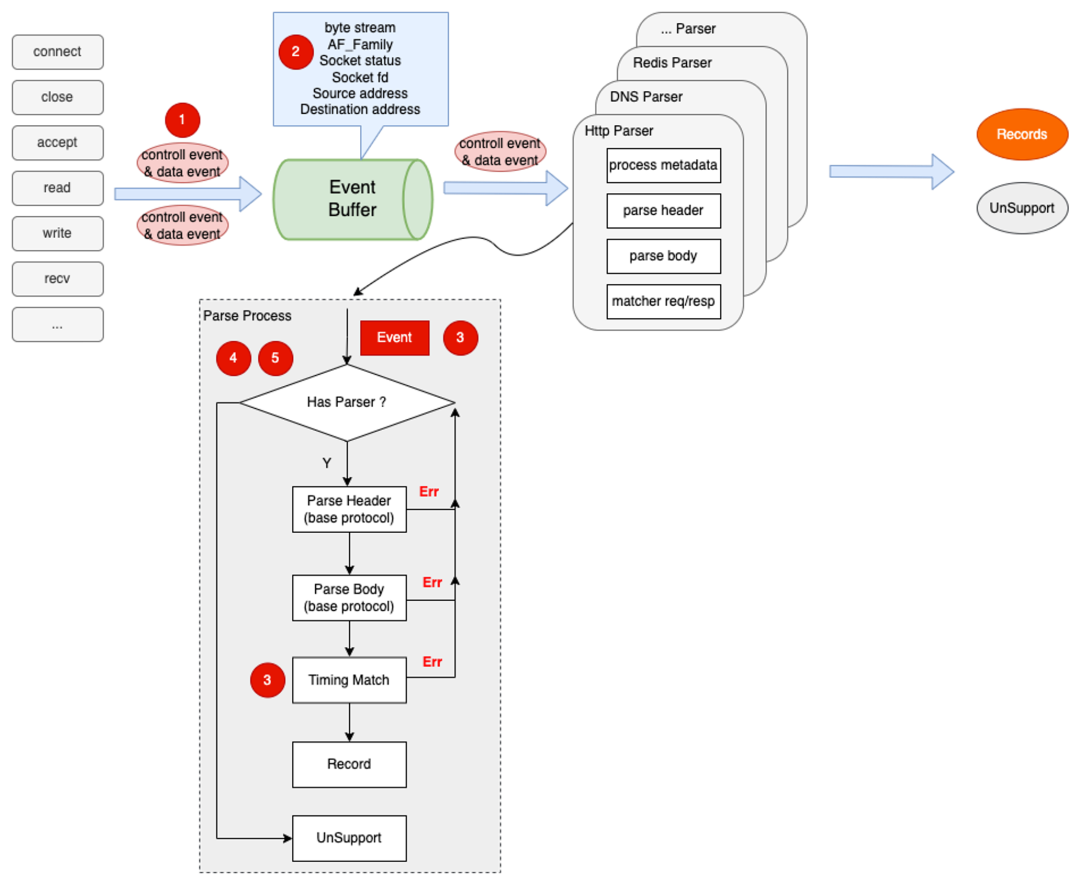
鉴于上文所述传统方案中存在的问题,本文提出一种高效的协议解析方案,本文所述方案主要分为四部分:
其中协议解析由分为:
![]()
图 4.2 本文所述协议解析框架图
如图 4.2 所示,eBPF 首先在内核态中采集到数据,根据协议帧头进行协议推断。根据协议推断的结果,可以初步判断改数据帧是否是所支持的协议。如果判断为“是”,才传递至用户态进行进一步解析,否则不进行处理。进行简单的事件过滤后,本文根据事件的类型进行事件分流。
如控制事件放到 control events perf buffer 中,数据事件放到 data event perf buffer。事件传递至用户态后控制事件将用于连接维护,数据事件根据其数据流向,分别放入发送队列和接收队列中。然后周期性的从对队列中的数据进行分帧处理,这样可以很好的解决单发多收、多发单收、多发多收等场景。从接受队列或发送队列(也可以理解为数据流)中拆解出单独的帧数据后将会通过按照内核态中推断的协议类型去匹配对应的协议解析器进行进一步解析。分别解析出请求与响应后,需要去匹配请求和响应,完成一个完成的可观测记录,即 record,后续也将通过 record 来生成可观测中的 Span。
本章后续小节将会重点讲解图 4.2 中的关键流程,即协议推断器(protocol infer)、协议解析进行详解。
4.2 协议推断(protocol infer)
顾名思义,协议推断主要用于在采集到数据包时,通过协议的协议帧头来推测是否是支持的协议类型。如果是支持的类型则将数据传递至用户态进行进一步处理。
以 MySQL5.7 协议为例:在 MySQL5.7 协议中,如果第一帧数据为 MySQL 的命令帧,如图 4.3 所示,命令帧有以下几种类型,具体见 MySQL 官方文档协议 [ 2] 。
![]()
图 4.3 MySQL 命令帧
但在这里,具体是不是真的是 MySQL 协议还到用户态解析时进一步确认。基于此,我们在内核中先通过简单的判读进行推断,简易的推断代码如下:
static __inline enum protocol_type_t infer_mysql(const char* buf, size_t count) {
static const uint8_t query = 0x03;
static const uint8_t connect = 0x0b;
static const uint8_t stmtPrepare = 0x16;
static const uint8_t stmtExecute = 0x17;
static const uint8_t stmtClose = 0x19;
if (buf[0] == connect || buf[0] == query || buf[0] == stmtPrepare || buf[0] == stmtExecute ||
buf[0] == stmtClose) {
return request;
}
return unknown;
}
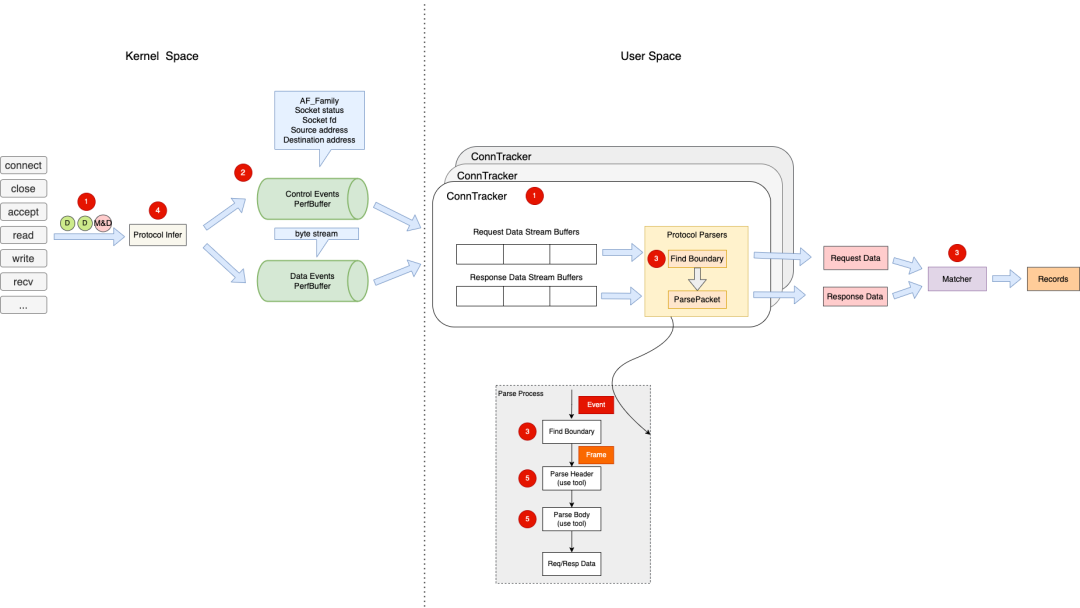
4.3 协议解析(conn tracker)
整个协议解析流程主要是在 conn tracker 组件中进行,其主要的能力有:
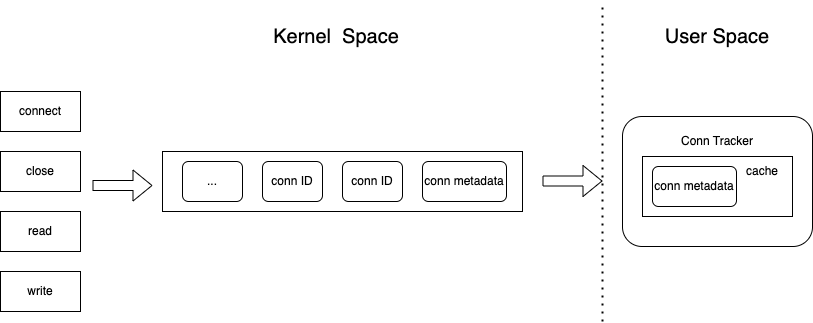
具体的,在长连接场景下每次数据传输的基本元数据信息,如 source ip、 source port、dest ip、dest port 等信息总是相同的。如图 4.4 所示,如果我们能够在用户态维护其连接信息,那这部分连接相关的元数据信息就不必每次都放入 perf buffer 中,只用传递连接 ID 即可,进一步降低网络带宽。
![]()
图 4.4 conn tracker 连接维护图
其次有部分协议,如 MySQL 协议,有部分 MySQL 相关信息,如版本号,编码等信息只在初次建立连接时候会发送包信息,如果用户态没有维护连接信息,则这部分元数据信息将无法解析。
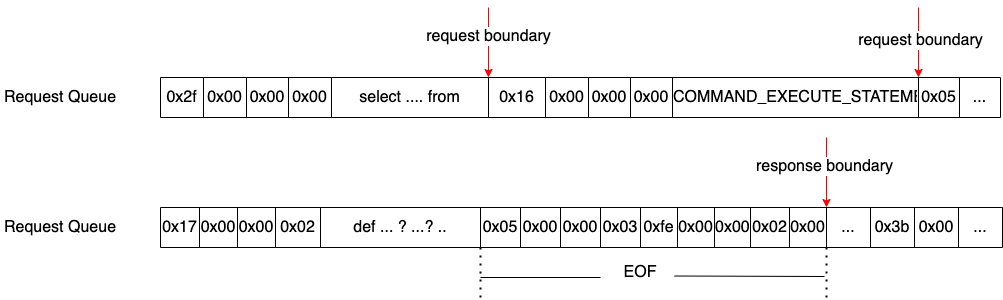
上文提到的内核中采集到的数据会放置接收队列、发送队列两个队列中,也可以理解为数据流。从整个数据流中分解出每一帧的数据是进行协议解析的前提。基本思路是根据每种协议的结束帧标识来做判断,如 MySQL 响应的 EOF 帧信息。图 4.5 所示为 MySQL 协议分帧示意图。
![]()
图 4.5 MySQL 协议分帧示意图
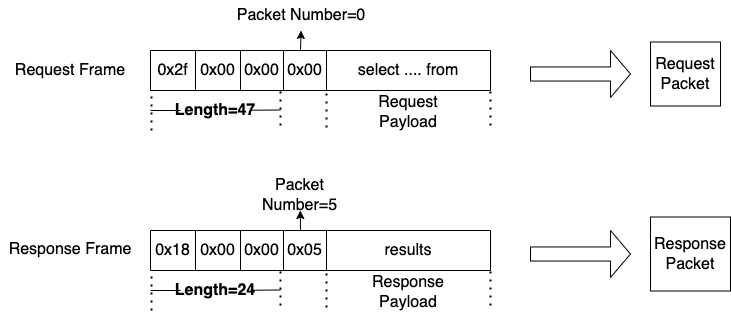
分解出每一帧的数据后,就按照各个协议进行协议解析即可。
![]()
图 4.6 MySQL 协议解析示意图
在可观测中,我们需要有一个完整的请求-响应记录。以 MySQL 协议为例,由于 MySQL 协议是按照时间序有序的,请求的时间序和响应的时间序能进行对应,响应总是以 EOF 结束,EOF 帧为以下形式。
![]()
图 4.7 MySQL Response 结束帧(EOF)
参考 MySQL 官方文档 [ 2] 。
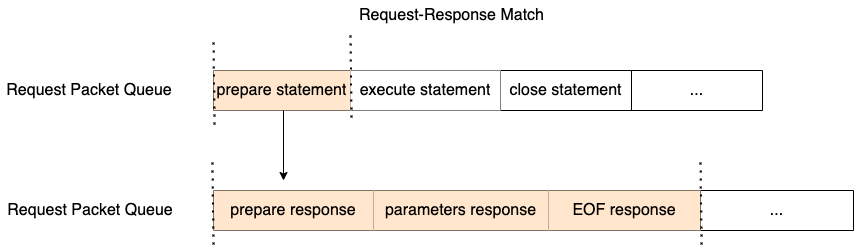
![]()
图 4.8 MySQL 请求-响应匹配示意图
总结
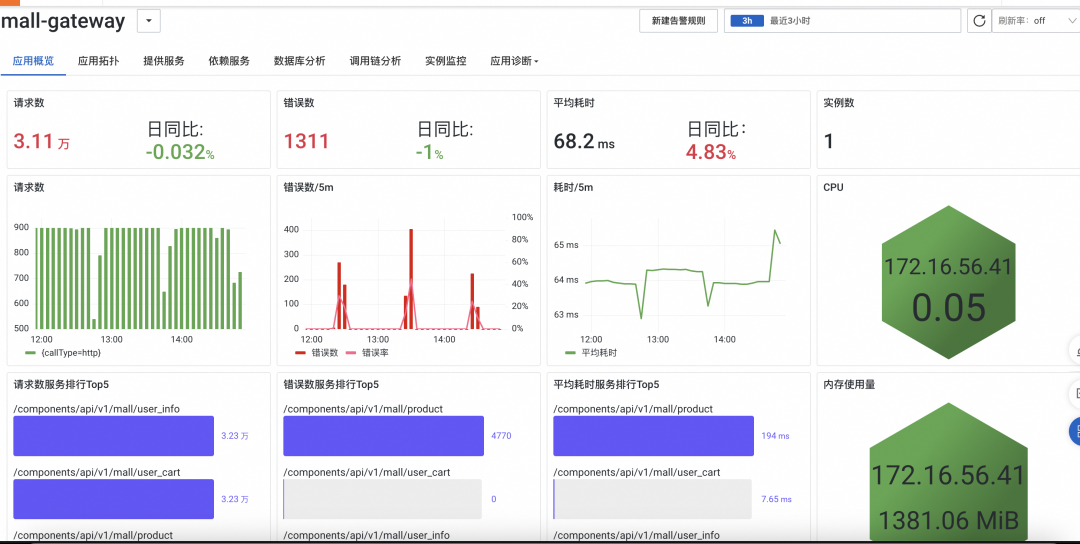
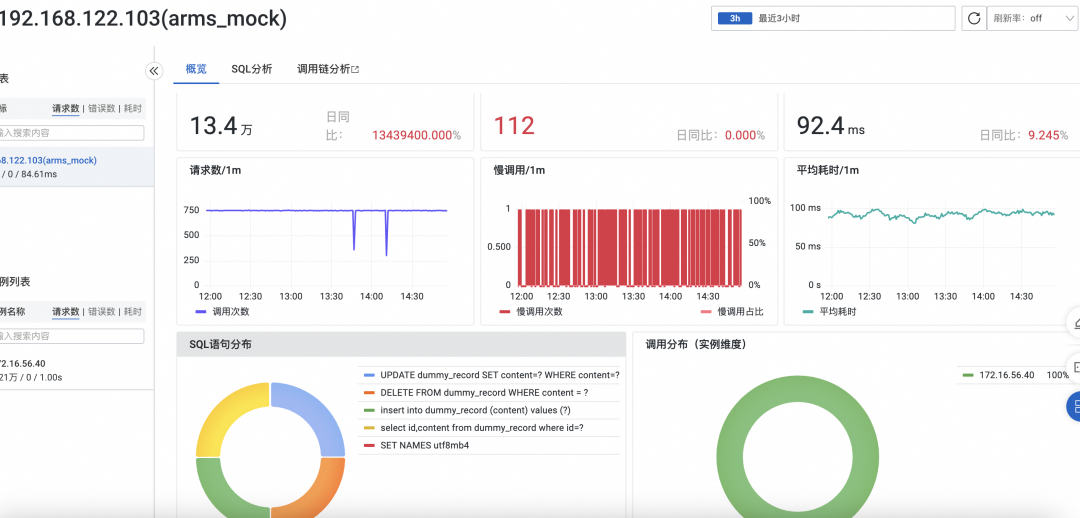
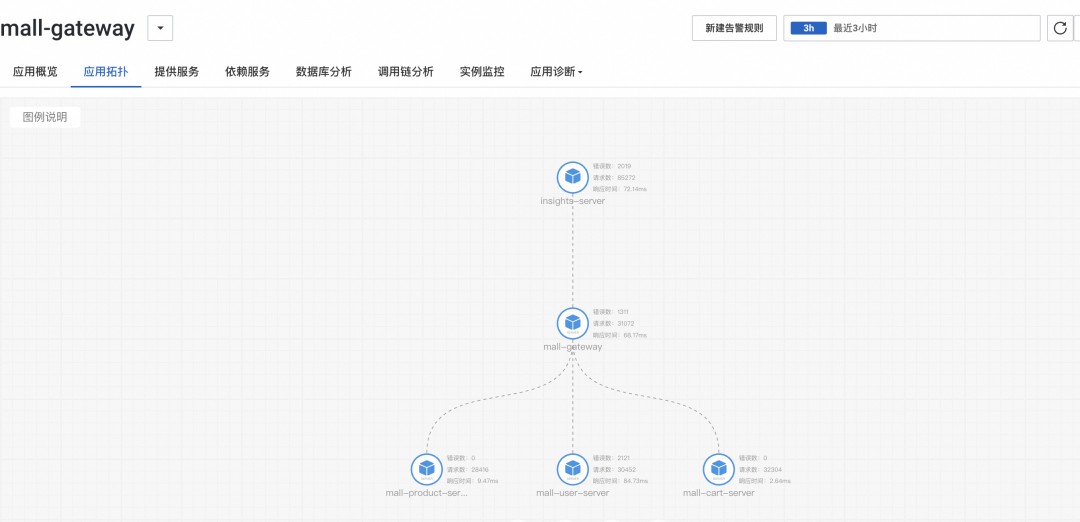
基于 eBPF 因其高性能,低开销,无侵入等特点近年来成为可观测性的研究热点。基于 eBPF 来进行应用监控必须进行协议解析。当前传统的协议解析方案存在 CPU、内存开销大,错误率高等问题。基于此本文提出一种高效的协议解析框架,并在阿里云应用实时监控服务 ARMS “应用监控 eBPF 版” [ 1] 中正式发布。成功接入后将会出现如下的应用监控展示大盘,以下是展示示意图。
使用的测试项目 github 地址:alibabacloud-microservice-demo [ 3]
![]()
图 5.1 应用监控 eBPF 版-概览
![]()
图 5.2 应用监控 eBPF 版-数据库分析
![]()
图 5.2 应用监控 eBPF 版-应用拓扑
具体接入流程见下方链接,仅需一分钟即可无死角监控您的应用。详细情况可进钉钉群(群号:35568145)进行交流。
目前,应用监控 eBPF 版处于免费使用阶段,并于近期将会推出网络监控、数据库分析、CPU Profiling [ 1] 等能力。欢迎开发者体验与使用。点击阅读原文,立即体验。
参考链接:
[1] 多语言应用监控最优选,ARMS 应用监控 eBPF 版正式发布
[2] https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_com_init_db.html
[3] https://github.com/aliyun/alibabacloud-microservice-demo