MoE(Mixture-of-Experts),混合专家架构,已是 GPT4 公开的秘密...
今天,DeepSeek 团队率先开源国内首个 MoE 大模型 DeepSeekMoE,全新架构,免费商用。
自研全新 MoE 架构,多尺度(2B->16B->145B)模型效果均领先:
· DeepSeekMoE 2B 可接近 MoE 模型的理论上限 2B Dense 模型性能(即相同Attention/FFN 参数配比的 2B Dense模型),仅用了17.5%计算量
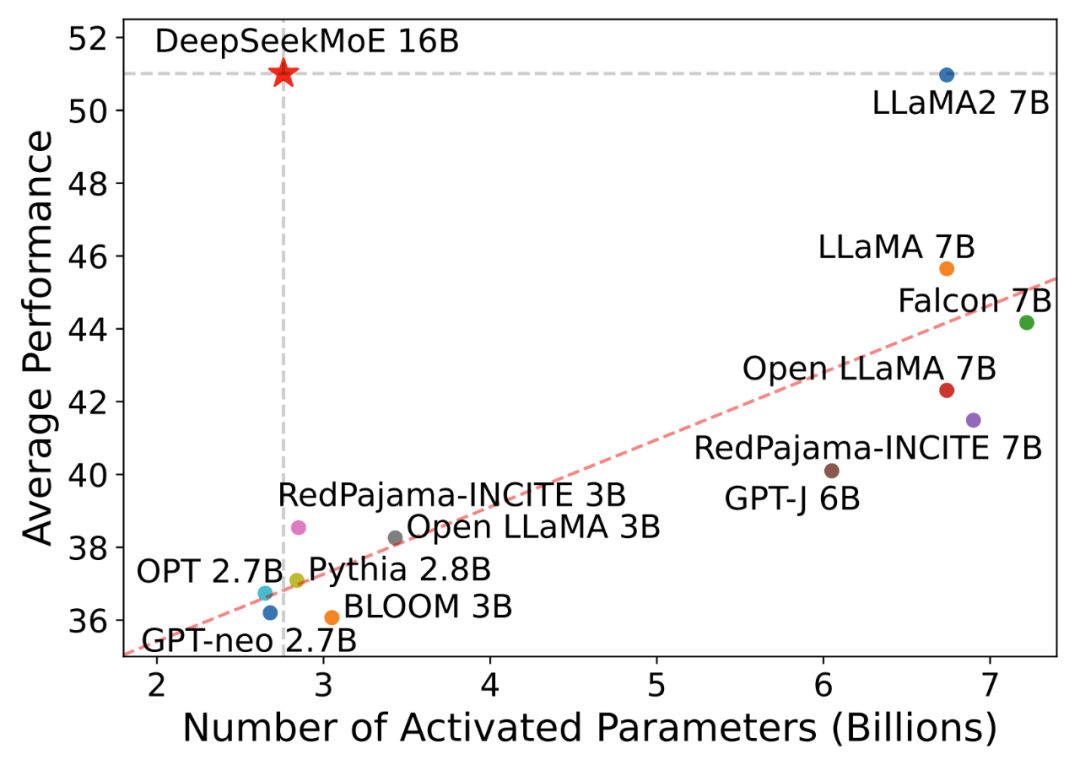
· DeepSeekMoE 16B 性能比肩 LLaMA2 7B 的同时,仅用了40%计算量(如下图),也是本次主力开源模型,40G 显存可单卡部署
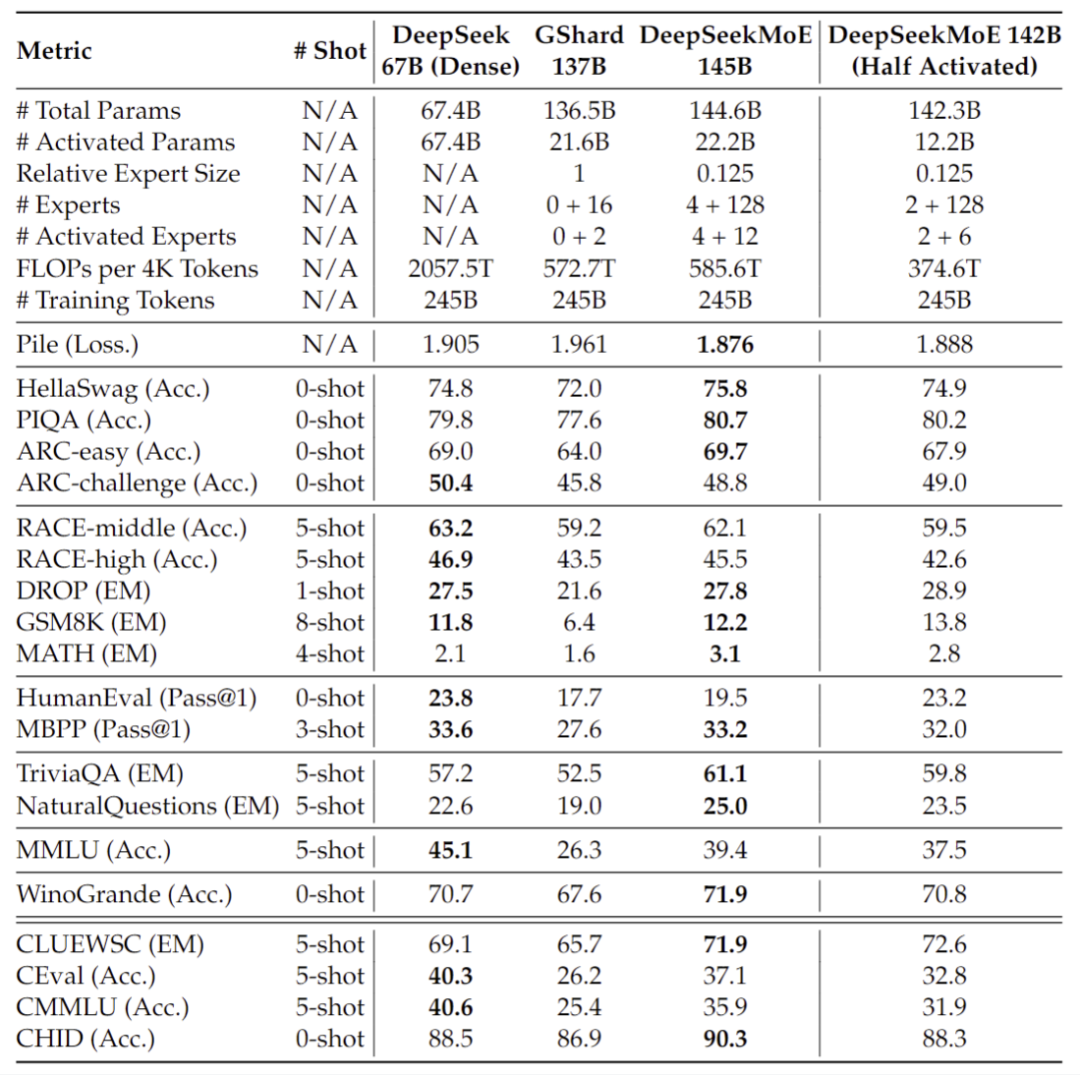
· DeepSeekMoE 145B 上的早期实验进一步证明该MoE架构明显领先于 Google 的 MoE 架构 GShard,仅用 28.5%(甚至 18.2%)计算量即可匹配 67B Dense 模型的性能
在Open LLM Leaderboard上的效果(纵轴)
模型下载: https://huggingface.co/deepseek-ai
微调代码:https://github.com/deepseek-ai/DeepSeek-MoE
技术报告:https://github.com/deepseek-ai/DeepSeek-MoE/blob/main/DeepSeekMoE.pdf
![]() 图2:DeepSeekMoE 16B模型已开放下载
图2:DeepSeekMoE 16B模型已开放下载
无需申请即可商用
![]() 图3: DeepSeekMoE 技术报告
图3: DeepSeekMoE 技术报告
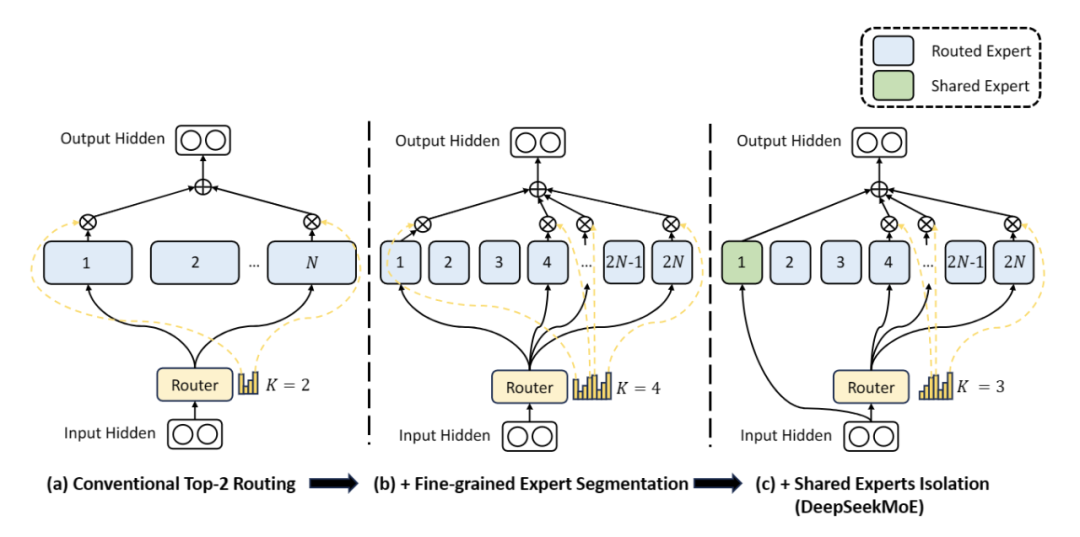
DeepSeekMoE在框架上做了两大创新:
· 细粒度专家 划分 :不同于传统MoE直接从与标准FFN大小相同的N个专家里选择激活K个专家 (如Mistral 7B*8 采取8个专家选2专家) ,我们把N个专家粒度划分更细,如上图4(b), 在保证激活参数量 不变 的情况下 ,从mN个专家中选择激活mK个专家 (如DeepSeekMoE 16B 采取64个专家选8个专家) ,如此可以更加灵活地组合多个专家
· 共享 专家分离 :我们把激活专家区分为共享专家(Shared Expert)和独立路由专家(Routed Expert),如上图4(c),此举有利于将共享和通用的知识压缩进公共参数,减少独立路由专家参数之间的知识冗余
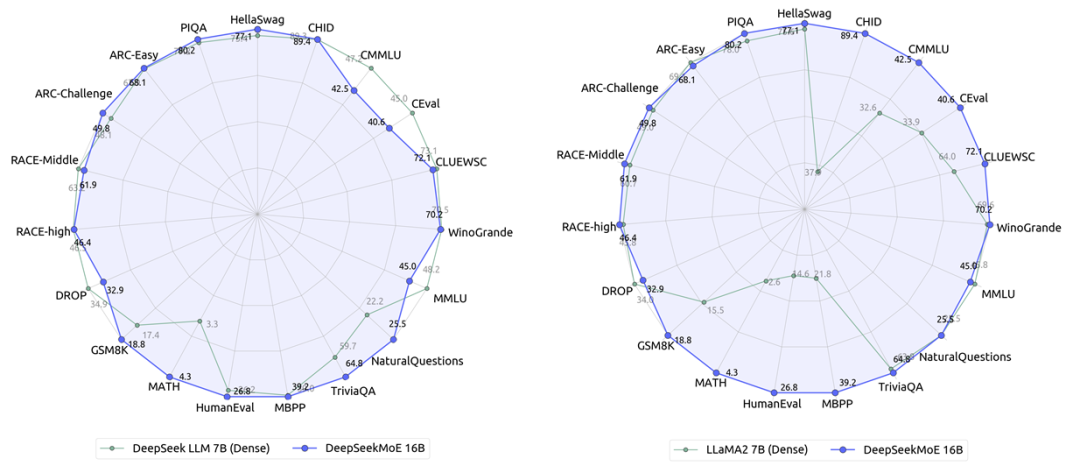
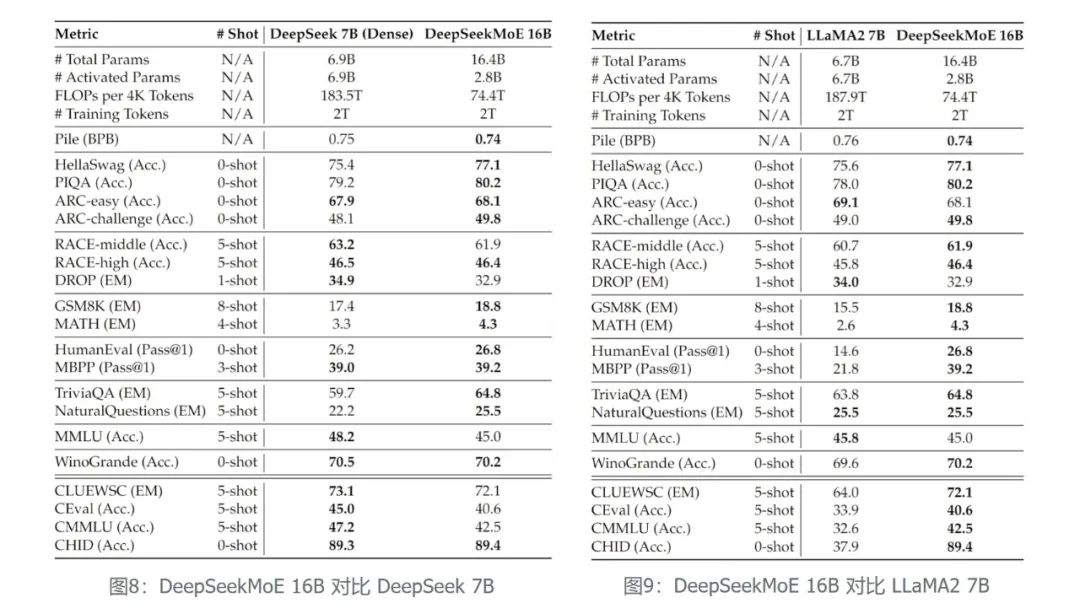
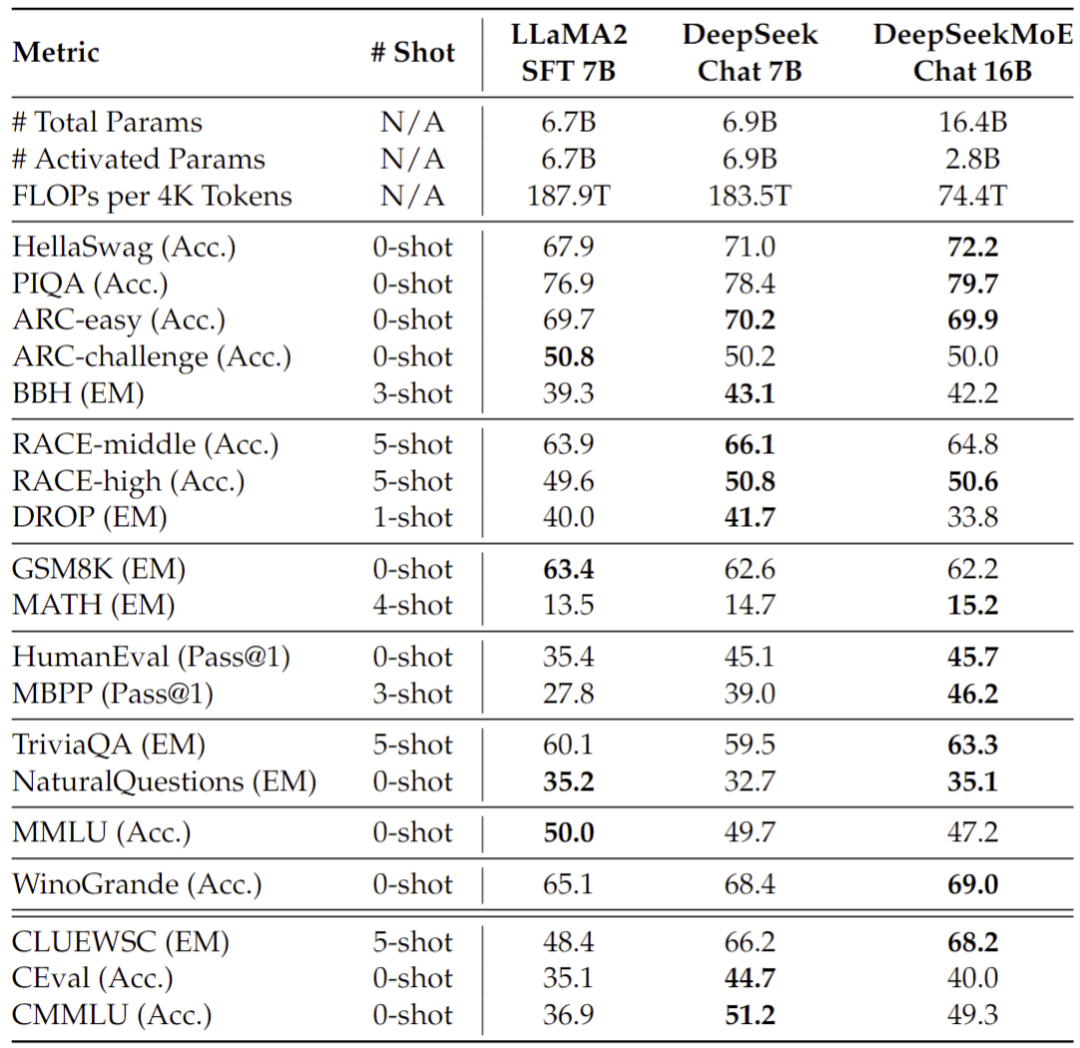
在相同语料下训练了2万亿token,DeepSeekMoE 16B 模型(实际激活参数量为2.8B)性能匹敌DeepSeek 7B Dense 模型(左下图),而同时节省了60%的计算量。
与目前Dense模型的开源代表LLaMA2相比,DeepSeekMoE 16B 在大部分数据集上的性能依旧领先LLaMA2 7B(右下图),但仅用了40%计算量。
DeepSeekMoE包含三个模型规模:2B->16B->145B。
DeepSeekMoE 2B (性能验证)
我们首先基于 2B 总参数的规模,对 DeepSeekMoE 的架构进行了充分的探索和研究:
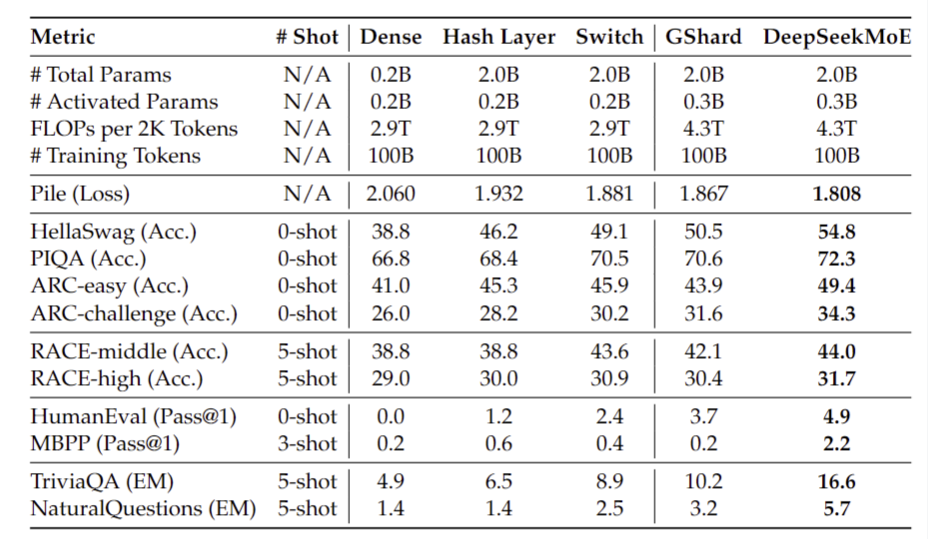
· 相同总参数量的对比下,DeepSeekMoE 大幅优于相同总参数下的其他MoE架构
![]() 图5:DeepSeekMoE 2B 对比相同参数MoE模型
图5:DeepSeekMoE 2B 对比相同参数MoE模型
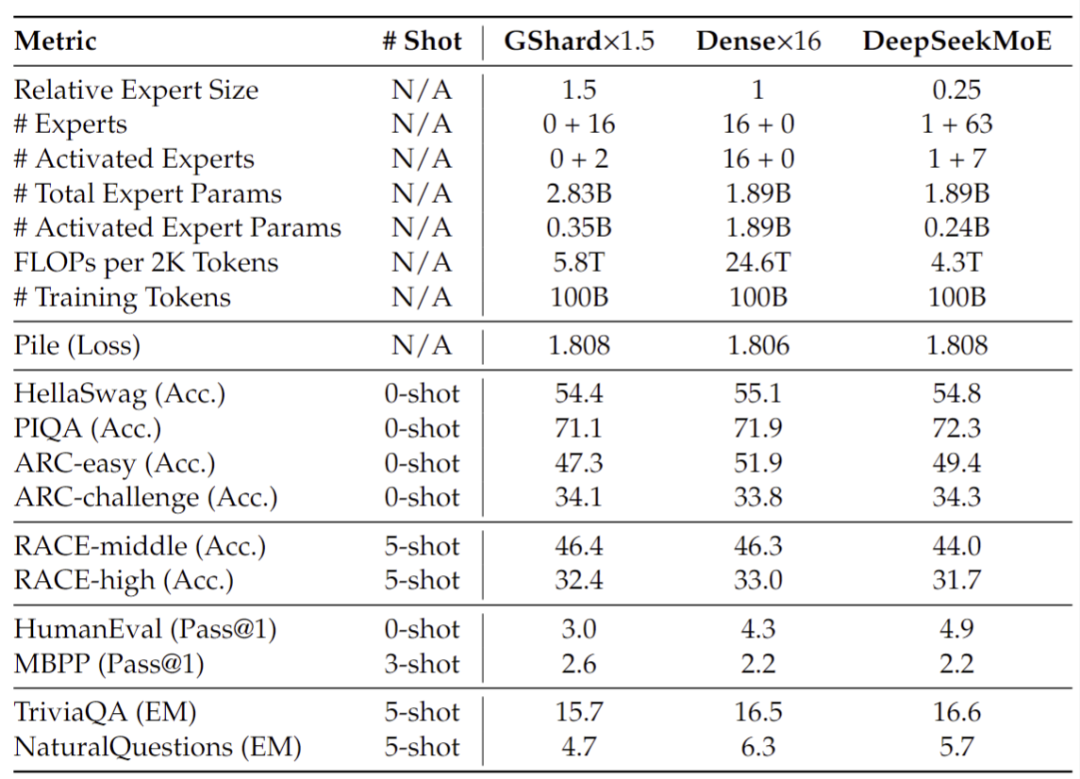
· 与更大规模(总参数量或者计算量)的模型相比,DeepSeekMoE 2B 能匹配 GShard 2.8B (1.5 倍专家参数量和专家计算量)的性能,同时能非常接近MoE模型的理论性能上限,即相同Attention/FFN总参数量下 2B Dense 模型的性能
![]() 图6:DeepSeekMoE 2B 模型性能上限分析
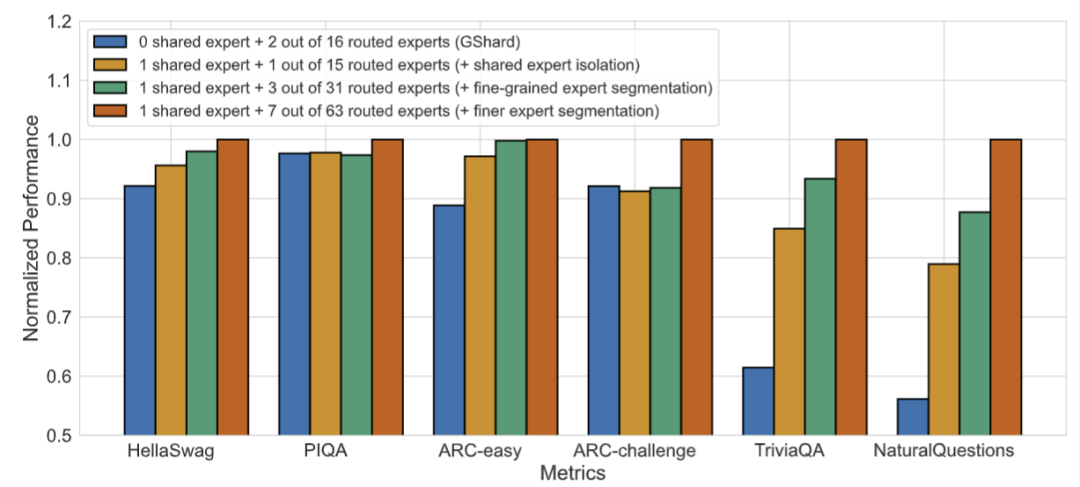
· 消融实验进一步证明了共享专家分离和细粒度专家划分两个策略的有效性
图6:DeepSeekMoE 2B 模型性能上限分析
· 消融实验进一步证明了共享专家分离和细粒度专家划分两个策略的有效性
![]() 图7:DeepSeekMoE两大创新的消融实验
图7:DeepSeekMoE两大创新的消融实验
此外,我们还验证了 DeepSeekMoE 相比于 GShard,有更好的专家化程度,体现在更少的专家知识冗余和更精准的专家知识命中上,具体请参见技术报告的第4.5节。
基于在 2B 规模上建立的对模型架构的认知,我们训练了总参数量为16.4B的 DeepSeekMoE 16B 模型,并将其开源以促进研究社区的发展。
开源模型效果如下:
· 在仅用40%计算量的前提下,DeepSeekMoE 16B 能达到与 DeepSeek 7B(左图) 和 LLaMA2 7B(右图)相匹配的性能,在知识密集性任务上,DeepSeekMoE 16B 的优势尤其突出
· 我们同时还对 DeepSeekMoE 16B 进行了 SFT 以构建一个对话模型,评测显示,其同样能够与基于 DeepSeek 7B 和 LLaMA2 7B 构建的对话模型性能相匹配
![]() 图10:DeepSeekMoE 16B SFT后模型效果对比
图10:DeepSeekMoE 16B SFT后模型效果对比
DeepSeekMoE 145B (持续研究)
我们正在持续研究更大规模的 DeepSeekMoE 模型,基于 200B 语料训练得到的初步实验结果显示,DeepSeekMoE 145B 依旧保持对 GShard 137B 的极大领先优势,同时能够以 28.5%(甚至18.2%) 的计算量达到与 DeepSeek 67B Dense 模型相匹配的性能。
![]() 图11 : DeepSeekMoE 145B 早期实验结果
图11 : DeepSeekMoE 145B 早期实验结果
NOTE:DeepSeekMoE 145B 正在持续开发中,在未来,我们同样会将其开源给研究社区。
本文由 H ugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注微信公众号:
如果你有与开源 AI、 Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系:
https://hf.link/tougao